









首先列出参考文献:Additive Logistic Regression: a Statistical View of Boosting还是J. Friedman的文章。
这里主要讲LogitBoost,discrete adaboost和real adaboost相对LogitBoost和gentle adaboost比较简单,我之前的博客也有介绍,详见AdaBoost算法学习,相信你能看懂。gentle adaboost以后再做介绍。
LogitBoost、discrete adaboost、real adaboost、gentle adaboost大致都属于adaboost体系。上面4中boost算法,其大体结构都是比较相似的,但是还是有区别的。
首先是关于损失函数(或代价函数),通常见到比较多的是均方误差和似然函数,而上面的算法中,Discrete AdaBoost、Real AdaBoost和Gentle AdaBoost算法都是采用对数损失函数,具体形式如下:
J(F) = ,其直观上表达的意义就是分类错误个数越多,损失就越大。
Friedman在文章中证明上面三个adaboost都是用加性logistic regression通过Newton-like方法去最小化损失函数。
而Logit Boost算法则采用最大化对数似然函数来推导的。
第二点是具体优化方法,Discrete AdaBoost与Real AdaBoost主要通过Newton-like的方法来优化,而Gentle AdaBoost与Logit Boost都是采用类似牛顿迭代的方式优化的。
首先从logistic regression分类说起

x是向量,y是标签。我们用logistic regression来分类

在使用logistic变换后概率pk如下表示

所以我们要学习参数beta。
考虑用最大化对数似然函数求解

整理后,损失函数如下:
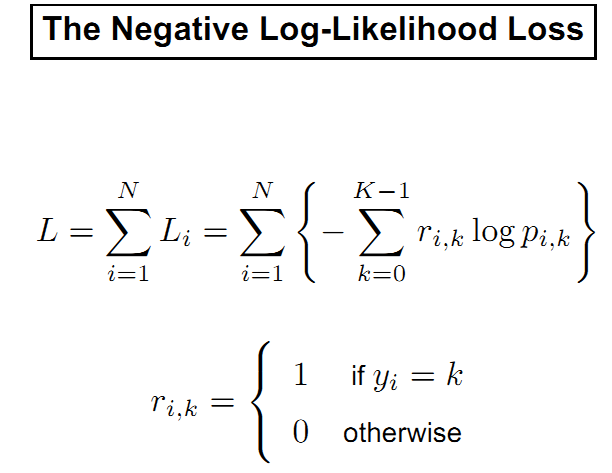
要最小化损失函数,考虑两种方法。
一种是牛顿法,它考虑了loss function的一阶和二阶导数。
另一种是梯度下降法,它只考虑了loss function的一阶导数。
下面是原始LogitBoost算法

其中:
,F即我们要学习的函数。
约束条件是:
之所以要有约束是限制自由度为K-1,以得到唯一的解。
损失函数如下:

K是类别数,N是样本数,v是shrinkage,即学习率,可设为1.
注意到Zi,k在pi,k接近0或1时,Zi,k会趋向无穷,所以Friedman在论文里做了限制,Zmax的取值范围是[2,4]。
现在我们要用带权的Zi,k去拟合xi。我们用回归树去拟合
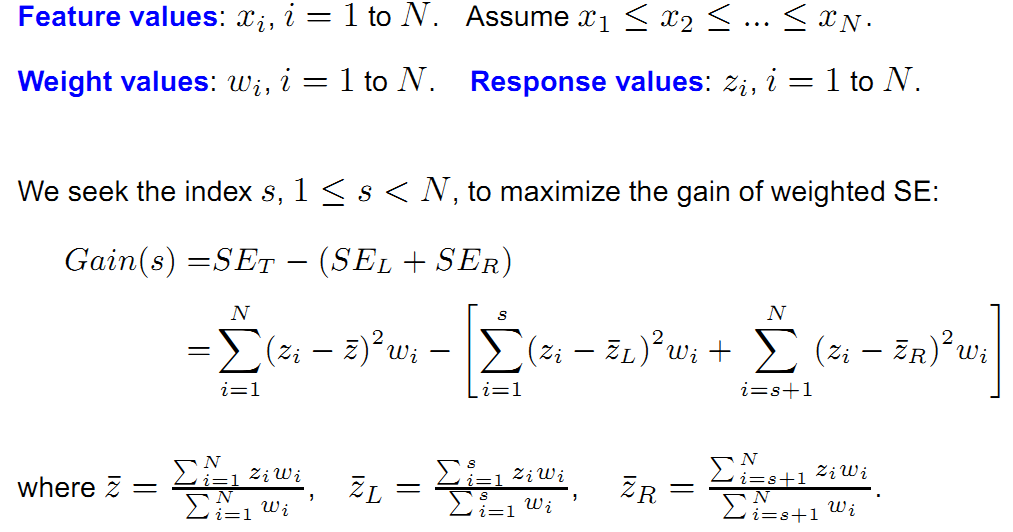
化简后得到
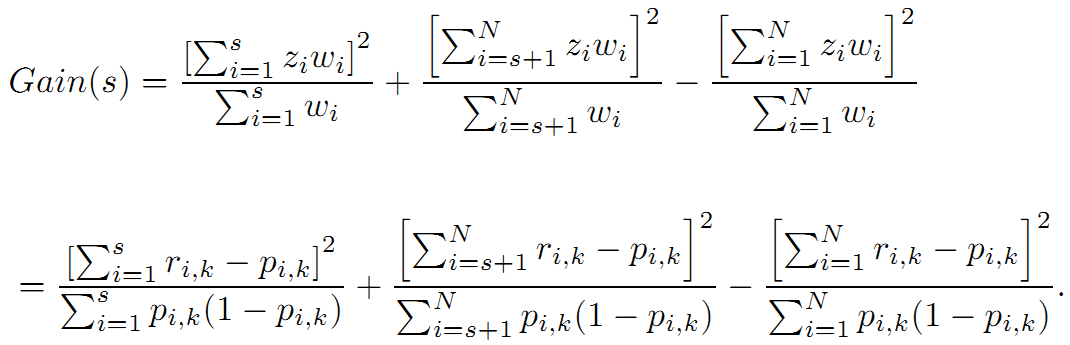
这就和上面的联系起来了。
所以有
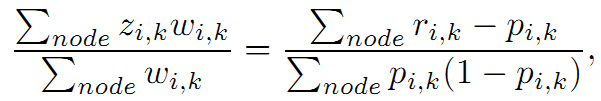
对损失函数L在F上求偏导

你会发现LogitBoost就是利用L的一阶和二阶导数进行优化。
我们重新整理一下LogitBoost算法

下面是weka里LogitBoost的核心函数,就是参照Friedman的论文实现的。
/**
* Builds the boosted classifier
*
* @param data the data to train the classifier with
* @throws Exception if building fails, e.g., can't handle data
*/
public void buildClassifier(Instances data) throws Exception {
m_RandomInstance = new Random(m_Seed);
int classIndex = data.classIndex();
if (m_Classifier == null) {
throw new Exception("A base classifier has not been specified!");
}
if (!(m_Classifier instanceof WeightedInstancesHandler) &&
!m_UseResampling) {
m_UseResampling = true;
}
// can classifier handle the data?
getCapabilities().testWithFail(data);
if (m_Debug) {
System.err.println("Creating copy of the training data");
}
// remove instances with missing class
data = new Instances(data);
data.deleteWithMissingClass();
// only class? -> build ZeroR model
if (data.numAttributes() == 1) {
System.err.println(
"Cannot build model (only class attribute present in data!), "
+ "using ZeroR model instead!");
m_ZeroR = new weka.classifiers.rules.ZeroR();
m_ZeroR.buildClassifier(data);
return;
}
else {
m_ZeroR = null;
}
m_NumClasses = data.numClasses();
m_ClassAttribute = data.classAttribute();
// Create the base classifiers
if (m_Debug) {
System.err.println("Creating base classifiers");
}
m_Classifiers = new Classifier [m_NumClasses][];
for (int j = 0; j < m_NumClasses; j++) {
m_Classifiers[j] = AbstractClassifier.makeCopies(m_Classifier,
getNumIterations());
}
// Do we want to select the appropriate number of iterations
// using cross-validation?
int bestNumIterations = getNumIterations();
if (m_NumFolds > 1) {
if (m_Debug) {
System.err.println("Processing first fold.");
}
// Array for storing the results
double[] results = new double[getNumIterations()];
// Iterate throught the cv-runs
for (int r = 0; r < m_NumRuns; r++) {
// Stratify the data
data.randomize(m_RandomInstance);
data.stratify(m_NumFolds);
// Perform the cross-validation
for (int i = 0; i < m_NumFolds; i++) {
// Get train and test folds
Instances train = data.trainCV(m_NumFolds, i, m_RandomInstance);
Instances test = data.testCV(m_NumFolds, i);
// Make class numeric
Instances trainN = new Instances(train);
trainN.setClassIndex(-1);
trainN.deleteAttributeAt(classIndex);
trainN.insertAttributeAt(new Attribute("'pseudo class'"), classIndex);
trainN.setClassIndex(classIndex);
m_NumericClassData = new Instances(trainN, 0);
// Get class values
int numInstances = train.numInstances();
double [][] trainFs = new double [numInstances][m_NumClasses];
double [][] trainYs = new double [numInstances][m_NumClasses];
for (int j = 0; j < m_NumClasses; j++) {
for (int k = 0; k < numInstances; k++) {
trainYs[k][j] = (train.instance(k).classValue() == j) ?
1.0 - m_Offset: 0.0 + (m_Offset / (double)m_NumClasses);
}
}
// Perform iterations
double[][] probs = initialProbs(numInstances);
m_NumGenerated = 0;
double sumOfWeights = train.sumOfWeights();
for (int j = 0; j < getNumIterations(); j++) {
performIteration(trainYs, trainFs, probs, trainN, sumOfWeights);
Evaluation eval = new Evaluation(train);
eval.evaluateModel(this, test);
results[j] += eval.correct();
}
}
}
// Find the number of iterations with the lowest error
double bestResult = -Double.MAX_VALUE;
for (int j = 0; j < getNumIterations(); j++) {
if (results[j] > bestResult) {
bestResult = results[j];
bestNumIterations = j;
}
}
if (m_Debug) {
System.err.println("Best result for " +
bestNumIterations + " iterations: " +
bestResult);
}
}
// Build classifier on all the data
int numInstances = data.numInstances();
double [][] trainFs = new double [numInstances][m_NumClasses];
double [][] trainYs = new double [numInstances][m_NumClasses];
for (int j = 0; j < m_NumClasses; j++) {
for (int i = 0, k = 0; i < numInstances; i++, k++) {
trainYs[i][j] = (data.instance(k).classValue() == j) ?
1.0 - m_Offset: 0.0 + (m_Offset / (double)m_NumClasses);
}
}
// Make class numeric
data.setClassIndex(-1);
data.deleteAttributeAt(classIndex);
data.insertAttributeAt(new Attribute("'pseudo class'"), classIndex);
data.setClassIndex(classIndex);
m_NumericClassData = new Instances(data, 0);
// Perform iterations
double[][] probs = initialProbs(numInstances);
double logLikelihood = logLikelihood(trainYs, probs);
m_NumGenerated = 0;
if (m_Debug) {
System.err.println("Avg. log-likelihood: " + logLikelihood);
}
double sumOfWeights = data.sumOfWeights();
for (int j = 0; j < bestNumIterations; j++) {
double previousLoglikelihood = logLikelihood;
performIteration(trainYs, trainFs, probs, data, sumOfWeights);
logLikelihood = logLikelihood(trainYs, probs);
if (m_Debug) {
System.err.println("Avg. log-likelihood: " + logLikelihood);
}
if (Math.abs(previousLoglikelihood - logLikelihood) < m_Precision) {
return;
}
}
}
/**
* Gets the intial class probabilities.
*
* @param numInstances the number of instances
* @return the initial class probabilities
*/
private double[][] initialProbs(int numInstances) {
double[][] probs = new double[numInstances][m_NumClasses];
for (int i = 0; i < numInstances; i++) {
for (int j = 0 ; j < m_NumClasses; j++) {
probs[i][j] = 1.0 / m_NumClasses;
}
}
return probs;
}
/**
* Computes loglikelihood given class values
* and estimated probablities.
*
* @param trainYs class values
* @param probs estimated probabilities
* @return the computed loglikelihood
*/
private double logLikelihood(double[][] trainYs, double[][] probs) {
double logLikelihood = 0;
for (int i = 0; i < trainYs.length; i++) {
for (int j = 0; j < m_NumClasses; j++) {
if (trainYs[i][j] == 1.0 - m_Offset) {
logLikelihood -= Math.log(probs[i][j]);
}
}
}
return logLikelihood / (double)trainYs.length;
}
/**
* Performs one boosting iteration.
*
* @param trainYs class values
* @param trainFs F scores
* @param probs probabilities
* @param data the data to run the iteration on
* @param origSumOfWeights the original sum of weights
* @throws Exception in case base classifiers run into problems
*/
private void performIteration(double[][] trainYs,
double[][] trainFs,
double[][] probs,
Instances data,
double origSumOfWeights) throws Exception {
if (m_Debug) {
System.err.println("Training classifier " + (m_NumGenerated + 1));
}
// Build the new models
for (int j = 0; j < m_NumClasses; j++) {
if (m_Debug) {
System.err.println("\t...for class " + (j + 1)
+ " (" + m_ClassAttribute.name()
+ "=" + m_ClassAttribute.value(j) + ")");
}
// Make copy because we want to save the weights
Instances boostData = new Instances(data);
// Set instance pseudoclass and weights
for (int i = 0; i < probs.length; i++) {
// Compute response and weight
double p = probs[i][j];
double z, actual = trainYs[i][j];
if (actual == 1 - m_Offset) {
z = 1.0 / p;
if (z > Z_MAX) { // threshold
z = Z_MAX;
}
} else {
z = -1.0 / (1.0 - p);
if (z < -Z_MAX) { // threshold
z = -Z_MAX;
}
}
double w = (actual - p) / z;
// Set values for instance
Instance current = boostData.instance(i);
current.setValue(boostData.classIndex(), z);
current.setWeight(current.weight() * w);
}
// Scale the weights (helps with some base learners)
double sumOfWeights = boostData.sumOfWeights();
double scalingFactor = (double)origSumOfWeights / sumOfWeights;
for (int i = 0; i < probs.length; i++) {
Instance current = boostData.instance(i);
current.setWeight(current.weight() * scalingFactor);
}
// Select instances to train the classifier on
Instances trainData = boostData;
if (m_WeightThreshold < 100) {
trainData = selectWeightQuantile(boostData,
(double)m_WeightThreshold / 100);
} else {
if (m_UseResampling) {
double[] weights = new double[boostData.numInstances()];
for (int kk = 0; kk < weights.length; kk++) {
weights[kk] = boostData.instance(kk).weight();
}
trainData = boostData.resampleWithWeights(m_RandomInstance,
weights);
}
}
// Build the classifier
m_Classifiers[j][m_NumGenerated].buildClassifier(trainData);
}
// Evaluate / increment trainFs from the classifier
for (int i = 0; i < trainFs.length; i++) {
double [] pred = new double [m_NumClasses];
double predSum = 0;
for (int j = 0; j < m_NumClasses; j++) {
pred[j] = m_Shrinkage * m_Classifiers[j][m_NumGenerated]
.classifyInstance(data.instance(i));
predSum += pred[j];
}
predSum /= m_NumClasses;
for (int j = 0; j < m_NumClasses; j++) {
trainFs[i][j] += (pred[j] - predSum) * (m_NumClasses - 1)
/ m_NumClasses;
}
}
m_NumGenerated++;
// Compute the current probability estimates
for (int i = 0; i < trainYs.length; i++) {
probs[i] = probs(trainFs[i]);
}
}
/**
* Returns the array of classifiers that have been built.
*
* @return the built classifiers
*/
public Classifier[][] classifiers() {
Classifier[][] classifiers =
new Classifier[m_NumClasses][m_NumGenerated];
for (int j = 0; j < m_NumClasses; j++) {
for (int i = 0; i < m_NumGenerated; i++) {
classifiers[j][i] = m_Classifiers[j][i];
}
}
return classifiers;
}
/**
* Computes probabilities from F scores
*
* @param Fs the F scores
* @return the computed probabilities
*/
private double[] probs(double[] Fs) {
double maxF = -Double.MAX_VALUE;
for (int i = 0; i < Fs.length; i++) {
if (Fs[i] > maxF) {
maxF = Fs[i];
}
}
double sum = 0;
double[] probs = new double[Fs.length];
for (int i = 0; i < Fs.length; i++) {
probs[i] = Math.exp(Fs[i] - maxF);
sum += probs[i];
}
Utils.normalize(probs, sum);
return probs;
}
/**
* Calculates the class membership probabilities for the given test instance.
*
* @param instance the instance to be classified
* @return predicted class probability distribution
* @throws Exception if instance could not be classified
* successfully
*/
public double [] distributionForInstance(Instance instance)
throws Exception {
// default model?
if (m_ZeroR != null) {
return m_ZeroR.distributionForInstance(instance);
}
instance = (Instance)instance.copy();
instance.setDataset(m_NumericClassData);
double [] pred = new double [m_NumClasses];
double [] Fs = new double [m_NumClasses];
for (int i = 0; i < m_NumGenerated; i++) {
double predSum = 0;
for (int j = 0; j < m_NumClasses; j++) {
pred[j] = m_Shrinkage * m_Classifiers[j][i].classifyInstance(instance);
predSum += pred[j];
}
predSum /= m_NumClasses;
for (int j = 0; j < m_NumClasses; j++) {
Fs[j] += (pred[j] - predSum) * (m_NumClasses - 1)
/ m_NumClasses;
}
}
return probs(Fs);
}















 143
143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









