







 本文深入解析word2vec原理,涵盖词向量的概念、稀疏与密集向量的区别、CBOW及skip-gram模型的工作机制,以及Hierarchical Softmax的优化策略。
本文深入解析word2vec原理,涵盖词向量的概念、稀疏与密集向量的区别、CBOW及skip-gram模型的工作机制,以及Hierarchical Softmax的优化策略。
word2vec 是 Google 于 2013 年开源推出的一个用于获取词向量(word vector)的工具包,它简单、高效,因此引起了很多人的关注。我在看了@peghoty所写的《word2vec中的数学以后》(个人觉得这是很好的资料,各方面知识很全面,不像网上大部分有残缺),为了加深理解,自己用Python实现了一遍。贴在我的github上
系列所有帖子
自己动手写word2vec (一):主要概念和流程
自己动手写word2vec (二):统计词频
自己动手写word2vec (三):构建Huffman树
自己动手写word2vec (四):CBOW和skip-gram模型
1.单词的向量化表示
所谓的word vector,就是指将单词向量化,将某个单词用特定的向量来表示。将单词转化成对应的向量以后,就可以将其应用于各种机器学习的算法中去。一般来讲,词向量主要有两种形式,分别是稀疏向量和密集向量。
所谓稀疏向量,又称为one-hot representation,就是用一个很长的向量来表示一个词,向量的长度为词典的大小N,向量的分量只有一个1,其他全为0,1的位置对应该词在词典中的索引[1]。举例来说,如果有一个词典[“面条”,”方便面”,”狮子”],那么“面条”对应的词向量就是[1,0,0],“方便面”对应的词向量就是[0,1,0]。这种表示方法不需要繁琐的计算,简单易得,但是缺点也不少,比如长度过长(这会引发维数灾难),以及无法体现出近义词之间的关系,比如“面条”和“方便面”显然有非常紧密的关系,但转化成向量[1,0,0]和[0,1,0]以后,就看不出两者有什么关系了,因为这两个向量相互正交。当然了,用这种稀疏向量求和来表示文档向量效果还不错,清华的长文本分类工具THUCTC使用的就是此种表示方法
至于密集向量,又称distributed representation,即分布式表示。最早由Hinton提出,可以克服one-hot representation的上述缺点,基本思路是通过训练将每个词映射成一个固定长度的短向量,所有这些向量就构成一个词向量空间,每一个向量可视为该空间上的一个点[1]。此时向量长度可以自由选择,与词典规模无关。这是非常大的优势。还是用之前的例子[“面条”,”方便面”,”狮子”],经过训练后,“面条”对应的向量可能是[1,0,1,1,0],而“方便面”对应的可能是[1,0,1,0,0],而“狮子”对应的可能是[0,1,0,0,1]。这样“面条”向量乘“方便面”=2,而“面条”向量乘“狮子”=0 。这样就体现出面条与方便面之间的关系更加紧密,而与狮子就没什么关系了。这种表示方式更精准的表现出近义词之间的关系,比之稀疏向量优势很明显。可以说这是深度学习在NLP领域的第一个运用(虽然我觉得并没深到哪里去)
回过头来看word2vec,其实word2vec做的事情很简单,大致来说,就是构建了一个多层神经网络,然后在给定文本中获取对应的输入和输出,在训练过程中不断修正神经网络中的参数,最后得到词向量。
2.word2vec的语言模型
所谓的语言模型,就是指对自然语言进行假设和建模,使得能够用计算机能够理解的方式来表达自然语言。word2vec采用的是n元语法模型(n-gram model),即假设一个词只与周围n个词有关,而与文本中的其他词无关。这种模型构建简单直接,当然也有后续的各种平滑方法[2],这里就不展开了。
现在就可以引出其他资料中经常提到的CBOW模型和skip-gram模型了。其实这两个模型非常相似,核心部分代码甚至是可以共用的。CBOW模型能够根据输入周围n-1个词来预测出这个词本身,而skip-gram模型能够根据词本身来预测周围有哪些词。也就是说,CBOW模型的输入是某个词A周围的n个单词的词向量之和,输出是词A本身的词向量;而skip-gram模型的输入是词A本身,输出是词A周围的n个单词的词向量(对的,要循环n遍)。
3.基于Hierarchical Softmax的模型
理论上说,无论是CBOW模型还是skip-gram模型,其具体的实现都可以用神经网络来完成。问题在于,这样做的计算量太大了。我们可以简略估计一下。首先定义一些变量的含义[3]:
(1) n : 一个词的上下文包含的词数,与n-gram中n的含义相同
(2) m : 词向量的长度,通常在10~100
(3) h : 隐藏层的规模,一般在100量级
(4) N :词典的规模,通常在1W~10W
(5) T : 训练文本中单词个数
以CBOW为例,输入层为n-1个单词的词向量,长度为m(n-1),隐藏层的规模为h,输出层的规模为N。那么前向的时间复杂度就是o(m(n-1)h+hN) = o(hN) 这还是处理一个词所需要的复杂度。如果要处理所有文本,则需要o(hNT)的时间复杂度。这个是不可接受的。同时我们也注意到,o(hNT)之中,h和T的值相对固定,想要对其进行优化,主要还是应该从N入手。而输出层的规模之所以为N,是因为这个神经网络要完成的是N选1的任务。那么可不可以减小N的值呢?答案是可以的。解决的思路就是将一次分类分解为多次分类,这也是Hierarchical Softmax的核心思想。举个栗子,有[1,2,3,4,5,6,7,8]这8个分类,想要判断词A属于哪个分类,我们可以一步步来,首先判断A是属于[1,2,3,4]还是属于[5,6,7,8]。如果判断出属于[1,2,3,4],那么就进一步分析是属于[1,2]还是[3,4],以此类推,如图中所示的那样。这样一来,就把单个词的时间复杂度从o(h*N)降为o(h*logN),更重要的减少了内存的开销。
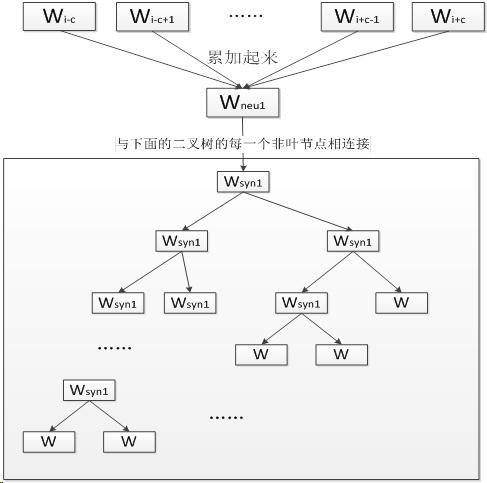
从上面可以看到从输入到输出,中间是一个树形结构,其中的每一个节点都完成一个二分类(logistic分类)问题。那么就 存在一个如何构建树的问题。这里采用huffman树,因为这样构建的话,出现频率越高的词所经过的路径越短,从而使得所有单词的平均路径长度达到最短。
4.word2vec的大概流程
至此,word2vec中的主要组件都大概提到过一遍,现在应该把它们串起来,大概了解一下word2vec的运行流程。
(1) 分词 / 词干提取和词形还原。 中文和英文的nlp各有各的难点,中文的难点在于需要进行分词,将一个个句子分解成一个单词数组。而英文虽然不需要分词,但是要处理各种各样的时态,所以要进行词干提取和词形还原。
(2) 构造词典,统计词频。这一步需要遍历一遍所有文本,找出所有出现过的词,并统计各词的出现频率。
(3) 构造树形结构。依照出现概率构造Huffman树。如果是完全二叉树,则简单很多,后面会仔细解释。需要注意的是,所有分类都应该处于叶节点,像下图显示的那样[4]
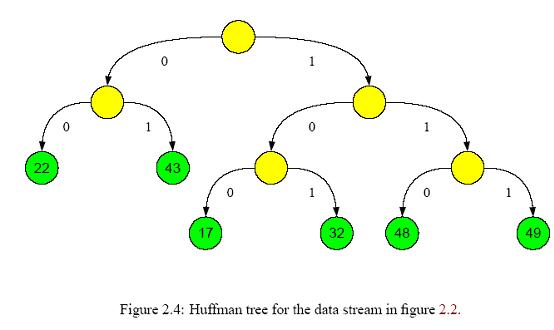
(4)生成节点所在的二进制码。拿上图举例,22对应的二进制码为00,而17对应的是100。也就是说,这个二进制码反映了节点在树中的位置,就像门牌号一样,能按照编码从根节点一步步找到对应的叶节点。
(5) 初始化各非叶节点的中间向量和叶节点中的词向量。树中的各个节点,都存储着一个长为m的向量,但叶节点和非叶结点中的向量的含义不同。叶节点中存储的是各词的词向量,是作为神经网络的输入的。而非叶结点中存储的是中间向量,对应于神经网络中隐含层的参数,与输入一起决定分类结果。
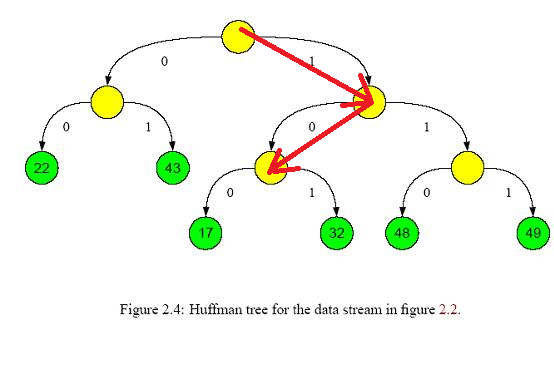
(6) 训练中间向量和词向量。对于CBOW模型,首先将词A附近的n-1个词的词向量相加作为系统的输入,并且按照词A在步骤4中生成的二进制码,一步步的进行分类并按照分类结果训练中间向量和词向量。举个栗子,对于绿17节点,我们已经知道其二进制码是100。那么在第一个中间节点应该将对应的输入分类到右边。如果分类到左边,则表明分类错误,需要对向量进行修正。第二个,第三个节点也是这样,以此类推,直到达到叶节点。因此对于单个单词来说,最多只会改动其路径上的节点的中间向量,而不会改动其他节点。
参考文献
[1]word2vec中的数学,p14
[2]统计自然语言处理,宗成庆,第五章
[3]word2vec中的数学,p13
[4]Huffman树词条

















 834
834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









