







文章目录
介绍
深度学习语义分割(Semantic Segmentation)是一种计算机视觉任务,它旨在将图像中的每个像素分类为预定义类别之一。与物体检测不同,后者通常只识别和定位图像中的目标对象边界框,语义分割要求对图像的每一个像素进行分类,以实现更精细的理解。这项技术在自动驾驶、医学影像分析、机器人视觉等领域有着广泛的应用。
深度学习语义分割的关键特点
- 像素级分类:对于输入图像的每一个像素点,模型都需要预测其属于哪个类别。
- 全局上下文理解:为了正确地分割复杂场景,模型需要考虑整个图像的内容及其上下文信息。
- 多尺度处理:由于目标可能出现在不同的尺度上,有效的语义分割方法通常会处理多种分辨率下的特征。
主要架构和技术
-
全卷积网络 (FCN):
- FCN是最早的端到端训练的语义分割模型之一,它移除了传统CNN中的全连接层,并用卷积层替代,从而能够接受任意大小的输入并输出相同空间维度的概率图。
-
跳跃连接 (Skip Connections):
- 为了更好地保留原始图像的空间细节,一些模型引入了跳跃连接,即从编码器部分直接传递特征到解码器部分,这有助于恢复细粒度的结构信息。
-
U-Net:
- U-Net是一个专为生物医学图像分割设计的网络架构,它使用了对称的收缩路径(下采样)和扩展路径(上采样),以及丰富的跳跃连接来捕捉局部和全局信息。
-
DeepLab系列:
- DeepLab采用了空洞/膨胀卷积(Atrous Convolution)来增加感受野而不减少特征图分辨率,并通过多尺度推理和ASPP模块(Atrous Spatial Pyramid Pooling)增强了对不同尺度物体的捕捉能力。
-
PSPNet (Pyramid Scene Parsing Network):
- PSPNet利用金字塔池化机制收集不同尺度的上下文信息,然后将其融合用于最终的预测。
-
RefineNet:
- RefineNet强调了高分辨率特征的重要性,并通过一系列细化单元逐步恢复细节,确保输出高质量的分割结果。
-
HRNet (High-Resolution Network):
- HRNet在整个网络中保持了高分辨率的表示,同时通过多尺度融合策略有效地整合了低分辨率但富含语义的信息。
数据集和评价指标
常用的语义分割数据集包括PASCAL VOC、COCO、Cityscapes等。这些数据集提供了标注好的图像,用于训练和评估模型性能。
评价语义分割模型的标准通常包括:
- 像素准确率 (Pixel Accuracy):所有正确分类的像素占总像素的比例。
- 平均交并比 (Mean Intersection over Union, mIoU):这是最常用的评价指标之一,计算每个类别的IoU(交集除以并集),然后取平均值。
- 频率加权交并比 (Frequency Weighted IoU):考虑每个类别的出现频率,对mIoU进行加权。
总结
随着硬件性能的提升和算法的进步,深度学习语义分割已经取得了显著的进展。现代模型不仅能在速度上满足实时应用的需求,还能提供非常精确的分割结果。未来的研究可能会集中在提高模型效率、增强跨域泛化能力以及探索无监督或弱监督的学习方法等方面。
U2Net(Unified Network for Multi-Level Feature Aggregation and Segmentation)
U2Net(Unified Network for Multi-Level Feature Aggregation and Segmentation)是一种先进的语义分割网络架构,由中国科学院自动化研究所的研究人员提出。它在传统的 U-Net 基础上进行了多项创新,旨在解决多尺度特征聚合和细粒度结构分割的问题。U2Net 的设计特别适用于资源受限的环境,如移动设备或嵌入式系统,因为它不仅具有高精度,而且模型非常轻量化。
U2Net 的核心特点
-
双重编码器-解码器结构
- U2Net 采用了两套平行的编码器-解码器路径,一套用于捕捉全局上下文信息(Global Context),另一套则专注于局部细节(Local Details)。这样的设计可以更全面地理解图像内容,同时保持对细小物体边界的敏感性。
-
RSU(Recurrent Squeeze Unit)模块
- RSU 是 U2Net 的关键组件之一,它通过递归的方式多次应用挤压操作(squeeze operation),从而增强特征表示能力。每个 RSU 包含多个卷积层,它们之间存在内部跳跃连接,有助于缓解梯度消失问题,并促进不同层次特征之间的交流。
-
渐进式上采样策略
- 在解码阶段,U2Net 使用了一种渐进式的上采样方法,逐步恢复空间分辨率。与一次性大幅上采样的方法相比,这种方法可以在每一级都融合来自编码器的多尺度特征,确保了输出结果的空间一致性。
-
多层级特征融合
- U2Net 强调从低层到高层的多层次特征融合,利用了丰富的上下文信息来改进最终的分割效果。这种跨层级的信息交互使得模型能够更好地处理复杂场景中的各种对象。
-
轻量化设计
- 尽管性能强大,U2Net 却是一个极其紧凑的模型,参数量较少且计算成本低。这使得它非常适合部署在移动端或其他计算资源有限的平台上。
-
端到端训练
- 整个 U2Net 模型可以作为一个整体进行端到端的训练,无需预训练或者分阶段训练,简化了开发流程并提高了适应特定任务的能力。
U2Net 的工作原理
- 输入层:接收任意大小的输入图像。
- 主干网络(Backbone):基于 ResNet 或其他高效的基础架构,负责初步特征提取。
- 双重编码器路径:
- 全局编码器:逐渐降低空间分辨率,提取高层次语义特征。
- 局部编码器:保留较高分辨率,强调细节捕捉。
- RSU 模块:分布在编码器和解码器中,强化特征表达。
- 渐进式解码器路径:逐步恢复空间分辨率,每一步都结合来自两个编码器路径的特征。
- 多层级特征融合:在不同的解码阶段整合来自各个层级的信息。
- 输出层:生成每个像素点的类别预测值,其通道数等于类别的数量。
应用与优势
U2Net 已经被广泛应用于多种计算机视觉任务,包括但不限于:
- 医学图像分割:如肿瘤、器官等的精确分割。
- 自然场景分割:例如道路、行人、车辆等元素的识别。
- 遥感图像分析:土地覆盖分类、变化检测等领域。
- 实时视频处理:由于其高效的特性,U2Net 可以实现实时的帧间分割。
总之,U2Net 以其独特的双重编码器-解码器结构、RSU 模块以及渐进式上采样策略,为语义分割任务提供了新颖而有效的解决方案,尤其是在需要兼顾精度和效率的情况下。
SOD任务是将图片中最吸引人的目标和区域分割出来,只分前景和背景,简单来说是个二分类任务。

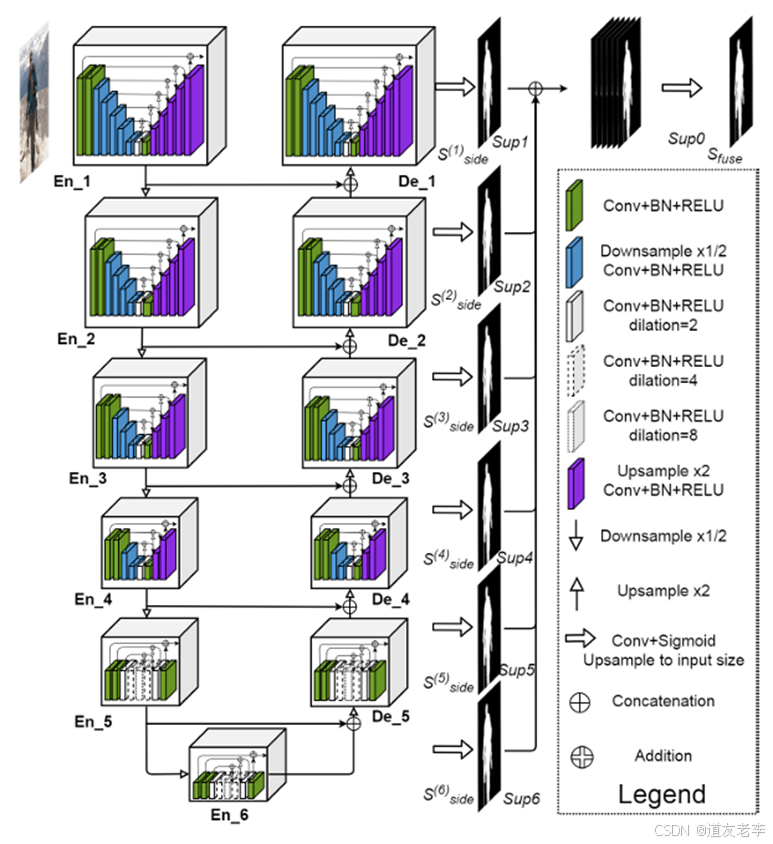
在Encoder阶段, 每通过一个block都会下采样2倍(maxpool), 在Decoder阶段,每通过一个block都会上采样2倍(bilinear)
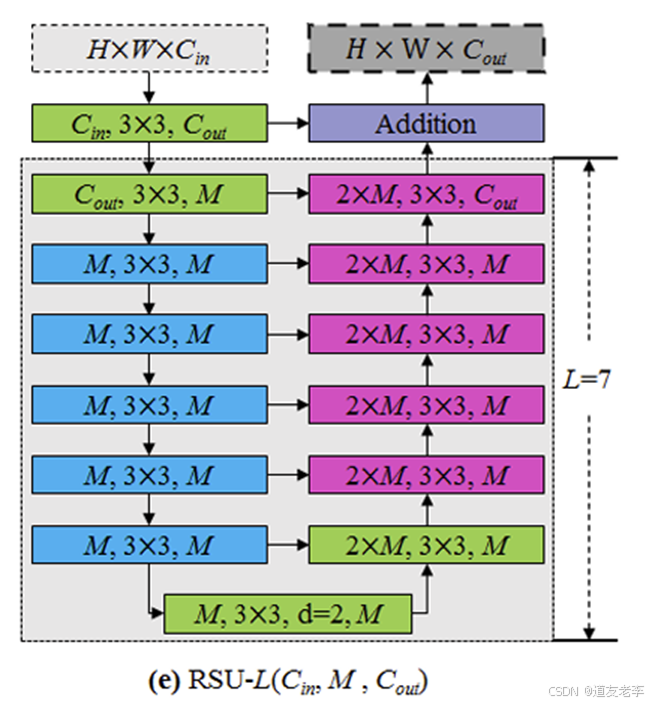

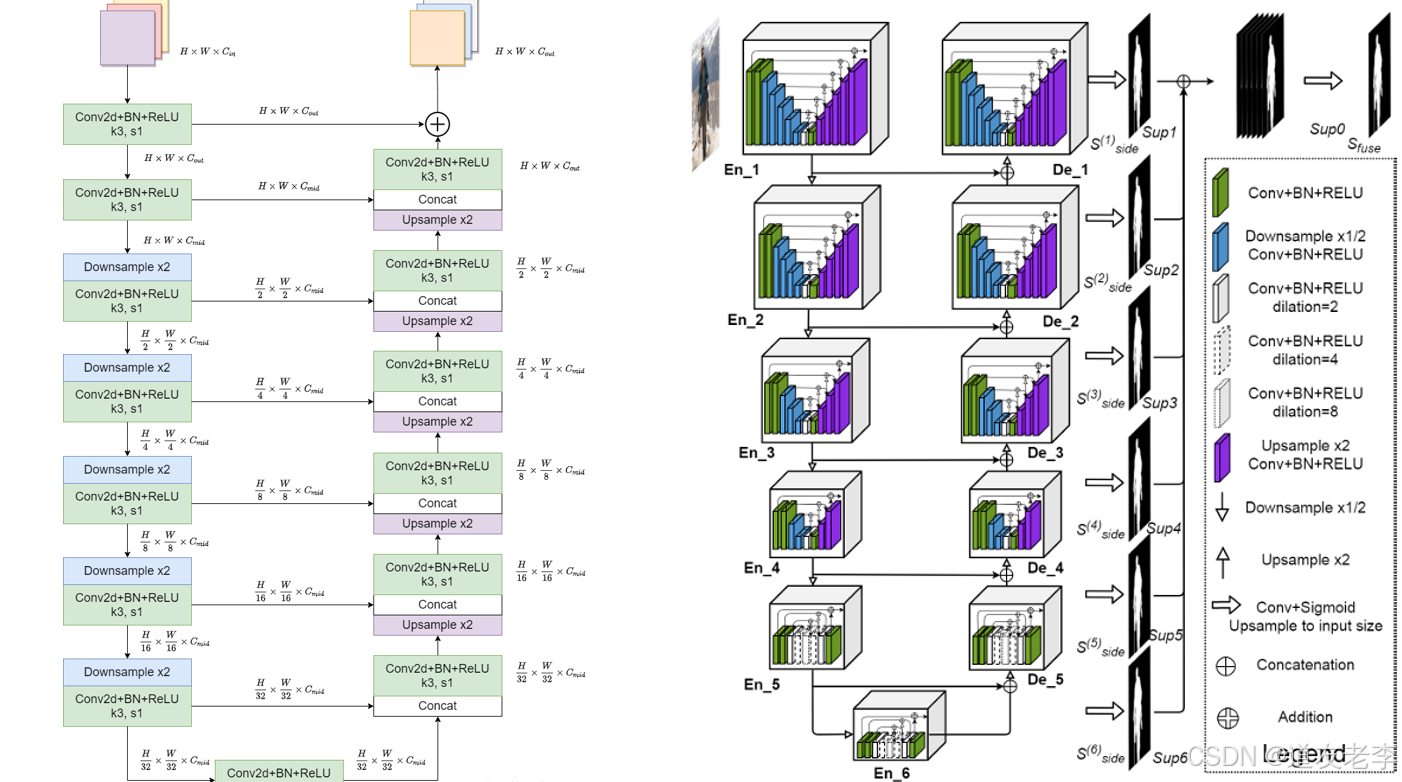
网络结构
损失计算
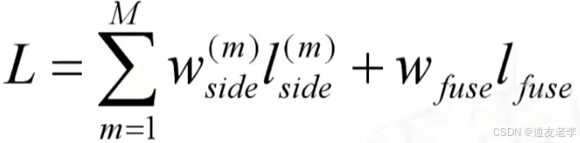
- l:代表二值交叉熵损失
- w:代表每个损失的权重
评价指标
F-measure
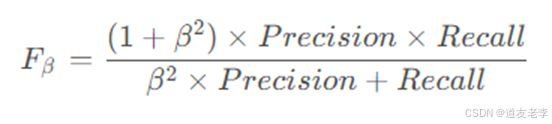
MAE
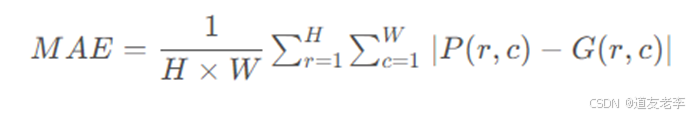
项目代码
DUTS数据集介绍
DUTS数据集官方下载地址:http://saliencydetection.net/duts/
如果下载不了,可以通过我提供的百度云下载,链接: https://pan.baidu.com/s/1nBI6GTN0ZilqH4Tvu18dow 密码: r7k6
其中DUTS-TR为训练集,DUTS-TE是测试(验证)集,数据集解压后目录结构如下:
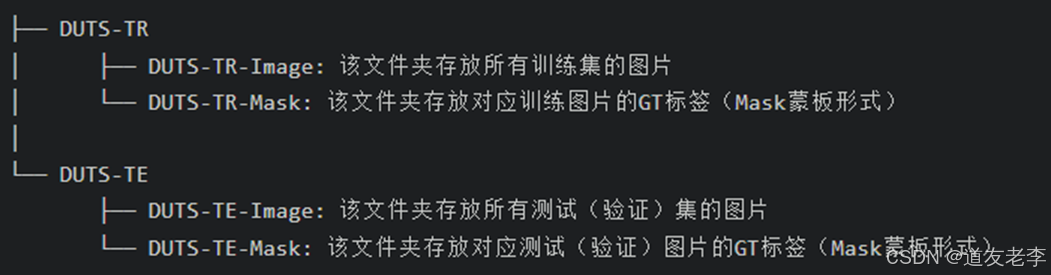
- 注意训练或者验证过程中,将
--data-path指向DUTS-TR所在根目录
官方权重
从官方转换得到的权重:
u2net_full.pth下载链接: https://pan.baidu.com/s/1ojJZS8v3F_eFKkF3DEdEXA 密码: fh1vu2net_lite.pth下载链接: https://pan.baidu.com/s/1TIWoiuEz9qRvTX9quDqQHg 密码: 5stj
u2net_full在DUTS-TE上的验证结果(使用validation.py进行验证):
MAE: 0.044
maxF1: 0.868
注:
- 这里的maxF1和原论文中的结果有些差异,经过对比发现差异主要来自post_norm,原仓库中会对预测结果进行post_norm,但在本仓库中将post_norm给移除了。
如果加上post_norm这里的maxF1为0.872,如果需要做该后处理可自行添加,post_norm流程如下,其中output为验证时网络预测的输出:
ma = torch.max(output)
mi = torch.min(output)
output = (output - mi) / (ma - mi)
- 如果要载入官方提供的权重,需要将
src/model.py中ConvBNReLU类里卷积的bias设置成True,因为官方代码里没有进行设置(Conv2d的bias默认为True)。
因为卷积后跟了BN,所以bias是起不到作用的,所以在项目中默认将bias设置为False。
训练记录(u2net_full)
训练最终在DUTS-TE上的验证结果:
MAE: 0.047
maxF1: 0.859
训练过程详情可见results.txt文件,训练权重下载链接: https://pan.baidu.com/s/1df2jMkrjbgEv-r1NMaZCZg 密码: n4l6
训练方法
- 确保提前准备好数据集
- 若要使用单GPU或者CPU训练,直接使用train.py训练脚本
- 若要使用多GPU训练,使用
torchrun --nproc_per_node=8 train_multi_GPU.py指令,nproc_per_node参数为使用GPU数量 - 如果想指定使用哪些GPU设备可在指令前加上
CUDA_VISIBLE_DEVICES=0,3(例如我只要使用设备中的第1块和第4块GPU设备) CUDA_VISIBLE_DEVICES=0,3 torchrun --nproc_per_node=2 train_multi_GPU.py
src文件目录
- model.py
from typing import Union, List
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvBNReLU(nn.Module):
def __init__(self, in_ch: int, out_ch: int, kernel_size: int = 3, dilation: int = 1):
super().__init__()
padding = kernel_size // 2 if dilation == 1 else dilation
self.conv = nn.Conv2d(in_ch, out_ch, kernel_size, padding=padding, dilation=dilation, bias=False)
self.bn = nn.BatchNorm2d(out_ch)
self.relu = nn.ReLU(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.relu(self.bn(self.conv(x)))
class DownConvBNReLU(ConvBNReLU):
def __init__(self, in_ch: int, out_ch: int, kernel_size: int = 3, dilation: int = 1, flag: bool = True):
super().__init__(in_ch, out_ch, kernel_size, dilation)
self.down_flag = flag
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.down_flag:
x = F.max_pool2d(x, kernel_size=2, stride=2, ceil_mode=True)
return self.relu(self.bn(self.conv(x)))
class UpConvBNReLU(ConvBNReLU):
def __init__(self, in_ch: int, out_ch: int, kernel_size: int = 3, dilation: int = 1, flag: bool = True):
super().__init__(in_ch, out_ch, kernel_size, dilation)
self.up_flag = flag
def forward(self, x1: torch.Tensor, x2: torch.Tensor) -> torch.Tensor:
if self.up_flag:
x1 = F.interpolate(x1, size=x2.shape[2:], mode='bilinear', align_corners=False)
return self.relu(self.bn(self.conv(torch.cat([x1, x2], dim=1))))
class RSU(nn.Module):
def __init__(self, height: int, in_ch: int, mid_ch: int, out_ch: int):
super().__init__()
assert height >= 2
self.conv_in = ConvBNReLU(in_ch, out_ch)
encode_list = [DownConvBNReLU(out_ch, mid_ch, flag=False)]
decode_list = [UpConvBNReLU(mid_ch * 2, mid_ch, flag=False)]
for i in range(height - 2):
encode_list.append(DownConvBNReLU(mid_ch, mid_ch))
decode_list.append(UpConvBNReLU(mid_ch * 2, mid_ch if i < height - 3 else out_ch))
encode_list.append(ConvBNReLU(mid_ch, mid_ch, dilation=2))
self.encode_modules = nn.ModuleList(encode_list)
self.decode_modules = nn.ModuleList(decode_list)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x_in = self.conv_in(x)
x = x_in
encode_outputs = []
for m in self.encode_modules:
x = m(x)
encode_outputs.append(x)
x = encode_outputs.pop()
for m in self.decode_modules:
x2 = encode_outputs.pop()
x = m(x, x2)
return x + x_in
class RSU4F(nn.Module):
def __init__(self, in_ch: int, mid_ch: int, out_ch: int):
super().__init__()
self.conv_in = ConvBNReLU(in_ch, out_ch)
self.encode_modules = nn.ModuleList([ConvBNReLU(out_ch, mid_ch),
ConvBNReLU(mid_ch, mid_ch, dilation=2),
ConvBNReLU(mid_ch, mid_ch, dilation=4),
ConvBNReLU(mid_ch, mid_ch, dilation=8)])
self.decode_modules = nn.ModuleList([ConvBNReLU(mid_ch * 2, mid_ch, dilation=4),
ConvBNReLU(mid_ch * 2, mid_ch, dilation=2),
ConvBNReLU(mid_ch * 2, out_ch)])
def forward(self, x: torch.Tensor) -> torch.Tensor:
x_in = self.conv_in(x)
x = x_in
encode_outputs = []
for m in self.encode_modules:
x = m(x)
encode_outputs.append(x)
x = encode_outputs.pop()
for m in self.decode_modules:
x2 = encode_outputs.pop()
x = m(torch.cat([x, x2], dim=1))
return x + x_in
class U2Net(nn.Module):
def __init__(self, cfg: dict, out_ch: int = 1):
super().__init__()
assert "encode" in cfg
assert "decode" in cfg
self.encode_num = len(cfg["encode"])
encode_list = []
side_list = []
for c in cfg["encode"]:
# c: [height, in_ch, mid_ch, out_ch, RSU4F, side]
assert len(c) == 6
encode_list.append(RSU(*c[:4]) if c[4] is False else RSU4F(*c[1:4]))
if c[5] is True:
side_list.append(nn.Conv2d(c[3], out_ch, kernel_size=3, padding=1))
self.encode_modules = nn.ModuleList(encode_list)
decode_list = []
for c in cfg["decode"]:
# c: [height, in_ch, mid_ch, out_ch, RSU4F, side]
assert len(c) == 6
decode_list.append(RSU(*c[:4]) if c[4] is False else RSU4F(*c[1:4]))
if c[5] is True:
side_list.append(nn.Conv2d(c[3], out_ch, kernel_size=3, padding=1))
self.decode_modules = nn.ModuleList(decode_list)
self.side_modules = nn.ModuleList(side_list)
self.out_conv = nn.Conv2d(self.encode_num * out_ch, out_ch, kernel_size=1)
def forward(self, x: torch.Tensor) -> Union[torch.Tensor, List[torch.Tensor]]:
_, _, h, w = x.shape
# collect encode outputs
encode_outputs = []
for i, m in enumerate(self.encode_modules):
x = m(x)
encode_outputs.append(x)
if i != self.encode_num - 1:
x = F.max_pool2d(x, kernel_size=2, stride=2, ceil_mode=True)
# collect decode outputs
x = encode_outputs.pop()
decode_outputs = [x]
for m in self.decode_modules:
x2 = encode_outputs.pop()
x = F.interpolate(x, size=x2.shape[2:], mode='bilinear', align_corners=False)
x = m(torch.concat([x, x2], dim=1))
decode_outputs.insert(0, x)
# collect side outputs
side_outputs = []
for m in self.side_modules:
x = decode_outputs.pop()
x = F.interpolate(m(x), size=[h, w], mode='bilinear', align_corners=False)
side_outputs.insert(0, x)
x = self.out_conv(torch.concat(side_outputs, dim=1))
if self.training:
# do not use torch.sigmoid for amp safe
return [x] + side_outputs
else:
return torch.sigmoid(x)
def u2net_full(out_ch: int = 1):
cfg = {
# height, in_ch, mid_ch, out_ch, RSU4F, side
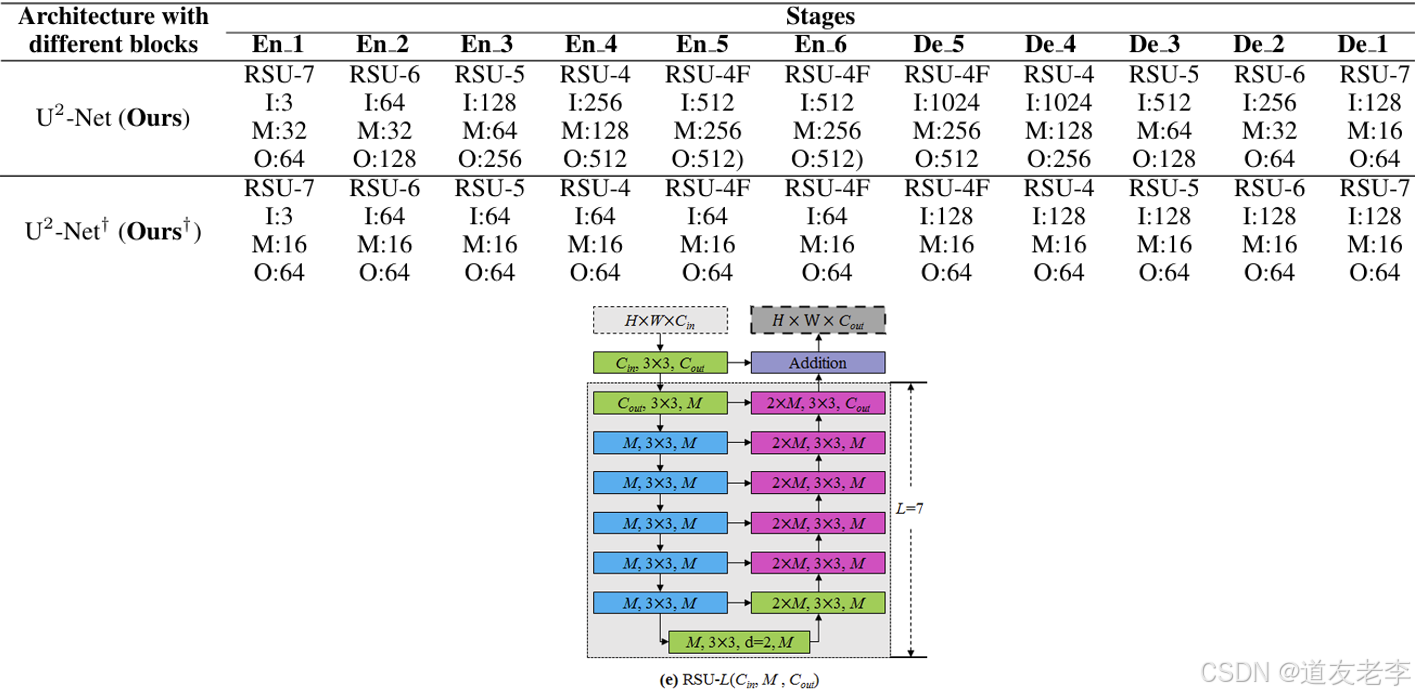
"encode": [[7, 3, 32, 64, False, False], # En1
[6, 64, 32, 128, False, False], # En2
[5, 128, 64, 256, False, False], # En3
[4, 256, 128, 512, False, False], # En4
[4, 512, 256, 512, True, False], # En5
[4, 512, 256, 512, True, True]], # En6
# height, in_ch, mid_ch, out_ch, RSU4F, side
"decode": [[4, 1024, 256, 512, True, True], # De5
[4, 1024, 128, 256, False, True], # De4
[5, 512, 64, 128, False, True], # De3
[6, 256, 32, 64, False, True], # De2
[7, 128, 16, 64, False, True]] # De1
}
return U2Net(cfg, out_ch)
def u2net_lite(out_ch: int = 1):
cfg = {
# height, in_ch, mid_ch, out_ch, RSU4F, side
"encode": [[7, 3, 16, 64, False, False], # En1
[6, 64, 16, 64, False, False], # En2
[5, 64, 16, 64, False, False], # En3
[4, 64, 16, 64, False, False], # En4
[4, 64, 16, 64, True, False], # En5
[4, 64, 16, 64, True, True]], # En6
# height, in_ch, mid_ch, out_ch, RSU4F, side
"decode": [[4, 128, 16, 64, True, True], # De5
[4, 128, 16, 64, False, True], # De4
[5, 128, 16, 64, False, True], # De3
[6, 128, 16, 64, False, True], # De2
[7, 128, 16, 64, False, True]] # De1
}
return U2Net(cfg, out_ch)
def convert_onnx(m, save_path):
m.eval()
x = torch.rand(1, 3, 288, 288, requires_grad=True)
# export the model
torch.onnx.export(m, # model being run
x, # model input (or a tuple for multiple inputs)
save_path, # where to save the model (can be a file or file-like object)
export_params=True,
opset_version=11)
if __name__ == '__main__':
# n_m = RSU(height=7, in_ch=3, mid_ch=12, out_ch=3)
# convert_onnx(n_m, "RSU7.onnx")
#
# n_m = RSU4F(in_ch=3, mid_ch=12, out_ch=3)
# convert_onnx(n_m, "RSU4F.onnx")
u2net = u2net_full()
convert_onnx(u2net, "u2net_full.onnx")
- train_utils
跟之前的一样
根目录
- my_dataset.py
import os
import cv2
import torch.utils.data as data
class DUTSDataset(data.Dataset):
def __init__(self, root: str, train: bool = True, transforms=None):
assert os.path.exists(root), f"path '{root}' does not exist."
if train:
self.image_root = os.path.join(root, "DUTS-TR", "DUTS-TR-Image")
self.mask_root = os.path.join(root, "DUTS-TR", "DUTS-TR-Mask")
else:
self.image_root = os.path.join(root, "DUTS-TE", "DUTS-TE-Image")
self.mask_root = os.path.join(root, "DUTS-TE", "DUTS-TE-Mask")
assert os.path.exists(self.image_root), f"path '{self.image_root}' does not exist."
assert os.path.exists(self.mask_root), f"path '{self.mask_root}' does not exist."
image_names = [p for p in os.listdir(self.image_root) if p.endswith(".jpg")]
mask_names = [p for p in os.listdir(self.mask_root) if p.endswith(".png")]
assert len(image_names) > 0, f"not find any images in {self.image_root}."
# check images and mask
re_mask_names = []
for p in image_names:
mask_name = p.replace(".jpg", ".png")
assert mask_name in mask_names, f"{p} has no corresponding mask."
re_mask_names.append(mask_name)
mask_names = re_mask_names
self.images_path = [os.path.join(self.image_root, n) for n in image_names]
self.masks_path = [os.path.join(self.mask_root, n) for n in mask_names]
self.transforms = transforms
def __getitem__(self, idx):
image_path = self.images_path[idx]
mask_path = self.masks_path[idx]
image = cv2.imread(image_path, flags=cv2.IMREAD_COLOR)
assert image is not None, f"failed to read image: {image_path}"
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # BGR -> RGB
h, w, _ = image.shape
target = cv2.imread(mask_path, flags=cv2.IMREAD_GRAYSCALE)
assert target is not None, f"failed to read mask: {mask_path}"
if self.transforms is not None:
image, target = self.transforms(image, target)
return image, target
def __len__(self):
return len(self.images_path)
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
batched_imgs = cat_list(images, fill_value=0)
batched_targets = cat_list(targets, fill_value=0)
return batched_imgs, batched_targets
def cat_list(images, fill_value=0):
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
batch_shape = (len(images),) + max_size
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
if __name__ == '__main__':
train_dataset = DUTSDataset("./", train=True)
print(len(train_dataset))
val_dataset = DUTSDataset("./", train=False)
print(len(val_dataset))
i, t = train_dataset[0]
- validation.py
import os
from typing import Union, List
import torch
from torch.utils import data
from src import u2net_full
from train_utils import evaluate
from my_dataset import DUTSDataset
import transforms as T
class SODPresetEval:
def __init__(self, base_size: Union[int, List[int]], mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.ToTensor(),
T.Resize(base_size, resize_mask=False),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
assert os.path.exists(args.weights), f"weights {args.weights} not found."
val_dataset = DUTSDataset(args.data_path, train=False, transforms=SODPresetEval([320, 320]))
num_workers = 4
val_data_loader = data.DataLoader(val_dataset,
batch_size=1, # must be 1
num_workers=num_workers,
pin_memory=True,
shuffle=False,
collate_fn=val_dataset.collate_fn)
model = u2net_full()
pretrain_weights = torch.load(args.weights, map_location='cpu')
if "model" in pretrain_weights:
model.load_state_dict(pretrain_weights["model"])
else:
model.load_state_dict(pretrain_weights)
model.to(device)
mae_metric, f1_metric = evaluate(model, val_data_loader, device=device)
print(mae_metric, f1_metric)
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch u2net validation")
parser.add_argument("--data-path", default="./", help="DUTS root")
parser.add_argument("--weights", default="./u2net_full.pth")
parser.add_argument("--device", default="cuda:0", help="training device")
parser.add_argument('--print-freq', default=10, type=int, help='print frequency')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
main(args)
- transforms.py
import random
from typing import List, Union
from torchvision.transforms import functional as F
from torchvision.transforms import transforms as T
class Compose(object):
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, image, target=None):
for t in self.transforms:
image, target = t(image, target)
return image, target
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = F.to_tensor(target)
return image, target
class RandomHorizontalFlip(object):
def __init__(self, prob):
self.flip_prob = prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
image = F.hflip(image)
target = F.hflip(target)
return image, target
class Normalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, image, target):
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target
class Resize(object):
def __init__(self, size: Union[int, List[int]], resize_mask: bool = True):
self.size = size # [h, w]
self.resize_mask = resize_mask
def __call__(self, image, target=None):
image = F.resize(image, self.size)
if self.resize_mask is True:
target = F.resize(target, self.size)
return image, target
class RandomCrop(object):
def __init__(self, size: int):
self.size = size
def pad_if_smaller(self, img, fill=0):
# 如果图像最小边长小于给定size,则用数值fill进行padding
min_size = min(img.shape[-2:])
if min_size < self.size:
ow, oh = img.size
padh = self.size - oh if oh < self.size else 0
padw = self.size - ow if ow < self.size else 0
img = F.pad(img, [0, 0, padw, padh], fill=fill)
return img
def __call__(self, image, target):
image = self.pad_if_smaller(image)
target = self.pad_if_smaller(target)
crop_params = T.RandomCrop.get_params(image, (self.size, self.size))
image = F.crop(image, *crop_params)
target = F.crop(target, *crop_params)
return image, target
- convert_weight.py
import re
import torch
from src import u2net_full, u2net_lite
layers = {"encode": [7, 6, 5, 4, 4, 4],
"decode": [4, 4, 5, 6, 7]}
def convert_conv_bn(new_weight, prefix, ks, v):
if "conv" in ks[0]:
if "weight" == ks[1]:
new_weight[prefix + ".conv.weight"] = v
elif "bias" == ks[1]:
new_weight[prefix + ".conv.bias"] = v
else:
print(f"unrecognized weight {prefix + ks[1]}")
return
if "bn" in ks[0]:
if "running_mean" == ks[1]:
new_weight[prefix + ".bn.running_mean"] = v
elif "running_var" == ks[1]:
new_weight[prefix + ".bn.running_var"] = v
elif "weight" == ks[1]:
new_weight[prefix + ".bn.weight"] = v
elif "bias" == ks[1]:
new_weight[prefix + ".bn.bias"] = v
elif "num_batches_tracked" == ks[1]:
return
else:
print(f"unrecognized weight {prefix + ks[1]}")
return
def convert(old_weight: dict):
new_weight = {}
for k, v in old_weight.items():
ks = k.split(".")
if ("stage" in ks[0]) and ("d" not in ks[0]):
# encode stage
num = int(re.findall(r'\d', ks[0])[0]) - 1
prefix = f"encode_modules.{num}"
if "rebnconvin" == ks[1]:
# ConvBNReLU module
prefix += ".conv_in"
convert_conv_bn(new_weight, prefix, ks[2:], v)
elif ("rebnconv" in ks[1]) and ("d" not in ks[1]):
num_ = int(re.findall(r'\d', ks[1])[0]) - 1
prefix += f".encode_modules.{num_}"
convert_conv_bn(new_weight, prefix, ks[2:], v)
elif ("rebnconv" in ks[1]) and ("d" in ks[1]):
num_ = layers["encode"][num] - int(re.findall(r'\d', ks[1])[0]) - 1
prefix += f".decode_modules.{num_}"
convert_conv_bn(new_weight, prefix, ks[2:], v)
else:
print(f"unrecognized key: {k}")
elif ("stage" in ks[0]) and ("d" in ks[0]):
# decode stage
num = 5 - int(re.findall(r'\d', ks[0])[0])
prefix = f"decode_modules.{num}"
if "rebnconvin" == ks[1]:
# ConvBNReLU module
prefix += ".conv_in"
convert_conv_bn(new_weight, prefix, ks[2:], v)
elif ("rebnconv" in ks[1]) and ("d" not in ks[1]):
num_ = int(re.findall(r'\d', ks[1])[0]) - 1
prefix += f".encode_modules.{num_}"
convert_conv_bn(new_weight, prefix, ks[2:], v)
elif ("rebnconv" in ks[1]) and ("d" in ks[1]):
num_ = layers["decode"][num] - int(re.findall(r'\d', ks[1])[0]) - 1
prefix += f".decode_modules.{num_}"
convert_conv_bn(new_weight, prefix, ks[2:], v)
else:
print(f"unrecognized key: {k}")
elif "side" in ks[0]:
# side
num = 6 - int(re.findall(r'\d', ks[0])[0])
prefix = f"side_modules.{num}"
if "weight" == ks[1]:
new_weight[prefix + ".weight"] = v
elif "bias" == ks[1]:
new_weight[prefix + ".bias"] = v
else:
print(f"unrecognized weight {prefix + ks[1]}")
elif "outconv" in ks[0]:
prefix = f"out_conv"
if "weight" == ks[1]:
new_weight[prefix + ".weight"] = v
elif "bias" == ks[1]:
new_weight[prefix + ".bias"] = v
else:
print(f"unrecognized weight {prefix + ks[1]}")
else:
print(f"unrecognized key: {k}")
return new_weight
def main_1():
from u2net import U2NET, U2NETP
old_m = U2NET()
old_m.load_state_dict(torch.load("u2net.pth", map_location='cpu'))
new_m = u2net_full()
# old_m = U2NETP()
# old_m.load_state_dict(torch.load("u2netp.pth", map_location='cpu'))
# new_m = u2net_lite()
old_w = old_m.state_dict()
w = convert(old_w)
new_m.load_state_dict(w, strict=True)
torch.random.manual_seed(0)
x = torch.randn(1, 3, 288, 288)
old_m.eval()
new_m.eval()
with torch.no_grad():
out1 = old_m(x)[0]
out2 = new_m(x)
assert torch.equal(out1, out2)
torch.save(new_m.state_dict(), "u2net_full.pth")
def main():
old_w = torch.load("u2net.pth", map_location='cpu')
new_m = u2net_full()
# old_w = torch.load("u2netp.pth", map_location='cpu')
# new_m = u2net_lite()
w = convert(old_w)
new_m.load_state_dict(w, strict=True)
torch.save(new_m.state_dict(), "u2net_full.pth")
if __name__ == '__main__':
main()
- train.py
import os
import time
import datetime
from typing import Union, List
import torch
from torch.utils import data
from src import u2net_full
from train_utils import train_one_epoch, evaluate, get_params_groups, create_lr_scheduler
from my_dataset import DUTSDataset
import transforms as T
class SODPresetTrain:
def __init__(self, base_size: Union[int, List[int]], crop_size: int,
hflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.ToTensor(),
T.Resize(base_size, resize_mask=True),
T.RandomCrop(crop_size),
T.RandomHorizontalFlip(hflip_prob),
T.Normalize(mean=mean, std=std)
])
def __call__(self, img, target):
return self.transforms(img, target)
class SODPresetEval:
def __init__(self, base_size: Union[int, List[int]], mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.transforms = T.Compose([
T.ToTensor(),
T.Resize(base_size, resize_mask=False),
T.Normalize(mean=mean, std=std),
])
def __call__(self, img, target):
return self.transforms(img, target)
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
batch_size = args.batch_size
# 用来保存训练以及验证过程中信息
results_file = "results{}.txt".format(datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
train_dataset = DUTSDataset(args.data_path, train=True, transforms=SODPresetTrain([320, 320], crop_size=288))
val_dataset = DUTSDataset(args.data_path, train=False, transforms=SODPresetEval([320, 320]))
num_workers = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8])
train_data_loader = data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True,
collate_fn=train_dataset.collate_fn)
val_data_loader = data.DataLoader(val_dataset,
batch_size=1, # must be 1
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
model = u2net_full()
model.to(device)
params_group = get_params_groups(model, weight_decay=args.weight_decay)
optimizer = torch.optim.AdamW(params_group, lr=args.lr, weight_decay=args.weight_decay)
lr_scheduler = create_lr_scheduler(optimizer, len(train_data_loader), args.epochs,
warmup=True, warmup_epochs=2)
scaler = torch.cuda.amp.GradScaler() if args.amp else None
if args.resume:
checkpoint = torch.load(args.resume, map_location='cpu')
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
args.start_epoch = checkpoint['epoch'] + 1
if args.amp:
scaler.load_state_dict(checkpoint["scaler"])
current_mae, current_f1 = 1.0, 0.0
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
mean_loss, lr = train_one_epoch(model, optimizer, train_data_loader, device, epoch,
lr_scheduler=lr_scheduler, print_freq=args.print_freq, scaler=scaler)
save_file = {"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
"lr_scheduler": lr_scheduler.state_dict(),
"epoch": epoch,
"args": args}
if args.amp:
save_file["scaler"] = scaler.state_dict()
if epoch % args.eval_interval == 0 or epoch == args.epochs - 1:
# 每间隔eval_interval个epoch验证一次,减少验证频率节省训练时间
mae_metric, f1_metric = evaluate(model, val_data_loader, device=device)
mae_info, f1_info = mae_metric.compute(), f1_metric.compute()
print(f"[epoch: {epoch}] val_MAE: {mae_info:.3f} val_maxF1: {f1_info:.3f}")
# write into txt
with open(results_file, "a") as f:
# 记录每个epoch对应的train_loss、lr以及验证集各指标
write_info = f"[epoch: {epoch}] train_loss: {mean_loss:.4f} lr: {lr:.6f} " \
f"MAE: {mae_info:.3f} maxF1: {f1_info:.3f} \n"
f.write(write_info)
# save_best
if current_mae >= mae_info and current_f1 <= f1_info:
torch.save(save_file, "save_weights/model_best.pth")
# only save latest 10 epoch weights
if os.path.exists(f"save_weights/model_{epoch-10}.pth"):
os.remove(f"save_weights/model_{epoch-10}.pth")
torch.save(save_file, f"save_weights/model_{epoch}.pth")
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print("training time {}".format(total_time_str))
def parse_args():
import argparse
parser = argparse.ArgumentParser(description="pytorch u2net training")
parser.add_argument("--data-path", default="./", help="DUTS root")
parser.add_argument("--device", default="cuda", help="training device")
parser.add_argument("-b", "--batch-size", default=16, type=int)
parser.add_argument('--wd', '--weight-decay', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)',
dest='weight_decay')
parser.add_argument("--epochs", default=360, type=int, metavar="N",
help="number of total epochs to train")
parser.add_argument("--eval-interval", default=10, type=int, help="validation interval default 10 Epochs")
parser.add_argument('--lr', default=0.001, type=float, help='initial learning rate')
parser.add_argument('--print-freq', default=50, type=int, help='print frequency')
parser.add_argument('--resume', default='', help='resume from checkpoint')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='start epoch')
# Mixed precision training parameters
parser.add_argument("--amp", action='store_true',
help="Use torch.cuda.amp for mixed precision training")
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
if not os.path.exists("./save_weights"):
os.mkdir("./save_weights")
main(args)
- predict.py
import os
import time
import cv2
import numpy as np
import matplotlib.pyplot as plt
import torch
from torchvision.transforms import transforms
from src import u2net_full
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
def main():
weights_path = "./u2net_full.pth"
img_path = "./test.png"
threshold = 0.5
assert os.path.exists(img_path), f"image file {img_path} dose not exists."
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(320),
transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
])
origin_img = cv2.cvtColor(cv2.imread(img_path, flags=cv2.IMREAD_COLOR), cv2.COLOR_BGR2RGB)
h, w = origin_img.shape[:2]
img = data_transform(origin_img)
img = torch.unsqueeze(img, 0).to(device) # [C, H, W] -> [1, C, H, W]
model = u2net_full()
weights = torch.load(weights_path, map_location='cpu')
if "model" in weights:
model.load_state_dict(weights["model"])
else:
model.load_state_dict(weights)
model.to(device)
model.eval()
with torch.no_grad():
# init model
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
pred = model(img)
t_end = time_synchronized()
print("inference time: {}".format(t_end - t_start))
pred = torch.squeeze(pred).to("cpu").numpy() # [1, 1, H, W] -> [H, W]
pred = cv2.resize(pred, dsize=(w, h), interpolation=cv2.INTER_LINEAR)
pred_mask = np.where(pred > threshold, 1, 0)
origin_img = np.array(origin_img, dtype=np.uint8)
seg_img = origin_img * pred_mask[..., None]
plt.imshow(seg_img)
plt.show()
cv2.imwrite("pred_result.png", cv2.cvtColor(seg_img.astype(np.uint8), cv2.COLOR_RGB2BGR))
if __name__ == '__main__':
main()



















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











