






1、引言
随着AI驱动应用领域的快速发展,LangGraph正逐渐成为构建智能多智能体系统(MAS)的前沿框架。由LangChain团队开发的LangGraph是一个开源库,旨在为大语言模型(LLM)提供一种有状态、结构化的工作流构建方式。与传统的基于Actor的模型相比,LangGraph引入了共享状态机制,从而增强了智能体间的协作和控制能力,打破了信息孤岛的局面。

LangGraph通过其创新的设计理念和强大的功能集,为开发者提供了一个前所未有的平台,用于创建高效、可靠且易于维护的AI驱动应用。
2 、LangGraph与传统Actor模型相比:有何不同
在传统的基于Actor的模型中,每个Actor通常遵循以下原则运作:
- 维护其自身的私有状态。
- 通过消息传递实现异步通信。
- 独立工作,不直接访问其他Actor的状态。
- 这种方法虽然简化了线程管理,但也导致了智能体之间的信息隔离问题。
例如,在Akka、Akka.NET或Microsoft Orleans等框架中,这种基于Actor的设计模式被广泛应用。然而,当涉及到复杂的多步骤推理和实时协作时,这些框架可能显得不够灵活。
3、 LangGraph的独特之处
LangGraph突破了传统Actor模型的限制,提出了一个更为先进的共享状态机制,允许智能体之间进行更紧密的合作:
1、动态协作
- 智能体能够通过交换实时更新来协同工作,这使得它们可以针对不断变化的情况做出响应。
2、上下文追踪
- LangGraph支持持久化的上下文跟踪,这对于对话式AI和持续性的业务流程尤为重要。这意味着即使在长时间运行的任务中,智能体也能保持一致的理解和决策能力。
3、透明度
- 在LangGraph的支持下,系统的决策过程更加透明。智能体不再盲目地发送和接收消息,而是参与到结构化的执行流中,这样就能更好地支持多步骤推理和AI驱动的决策制定过程。
此外,LangGraph还提供了对复杂工作流的强大支持,包括但不限于循环、分支逻辑以及人机交互等特性,使其成为构建高度互动和智能化应用程序的理想选择。通过这种方式,LangGraph不仅提升了单个智能体的功能性,而且极大地促进了整个系统的灵活性和可扩展性。
4 、LangGraph的主要特点
4.1 有状态的记忆管理(短期记忆和长期记忆)
LangGraph 提供了内置的记忆管理系统,使应用程序能够在交互过程中保持状态。这种记忆管理分为短期记忆和长期记忆两种形式:
- 短期记忆(Short-Term Memory):允许聊天机器人记住当前会话中的交互历史,从而使得对话更加自然流畅。例如,在一次客户服务的对话中,短期记忆可以帮助机器人记住用户的查询内容,并在后续的回答中引用这些信息。
- 长期记忆(Long-Term Memory):通过与外部数据库的集成实现持久化存储,这对于需要长时间保存用户数据的应用场景至关重要,如客户支持系统或个性化推荐引擎。长期记忆可以包含用户的偏好、历史记录以及其他有助于提升用户体验的信息。
4.2 人在环(Human-in-the-Loop,HITL)支持
LangGraph 的一个重要特性是其对人工干预的支持,这使得它非常适合那些需要精确度和验证的应用场景,比如法律咨询、医疗保健以及金融服务等。
- 暂停和恢复工作流程:允许人工审核员在关键决策点暂停自动化流程,并根据实际情况做出调整。
- 批准或修改 AI 决策:为用户提供了一个机制来检查并可能修正由AI生成的结果,确保最终输出符合预期标准。
- 增强信任和问责制:通过保持人类控制,增加了系统的透明度和可靠性,尤其是在高风险领域尤为重要。
4.3 实时流媒体支持
实时数据处理能力是LangGraph的一大亮点,适用于各种即时响应需求的应用场景:
- 对话式AI和聊天机器人:保证即时响应,让用户感受到流畅的交流体验。
- 实时数据分析:对于依赖于事件驱动架构的应用程序来说,持续更新的数据流能够提供最新的分析结果。
4.4 调试和可观察性
调试复杂的AI系统通常具有挑战性,但LangGraph为此提供了多种工具来简化这一过程:
- 完全的执行路径追踪:帮助开发者了解数据在整个工作流中的流动情况。
- 断点设置:可以在特定节点上暂停执行,以便检查状态变化。
- 集成Python调试工具:为开发者提供了熟悉且高效的调试环境。
4.5 LangSmith集成用于监控
LangGraph与LangSmith无缝整合,提供了强大的日志记录和性能监控功能,以优化工作流程:
- 监控错误并优化工作流程:及时发现并解决潜在问题。
- 实时模型交互分析:深入了解模型的行为模式。
- 提升系统效率:通过对详细分析的支持,改进整体系统表现。
4.6 异步执行以实现可扩展性
为了应对高并发量和长时间运行的任务,LangGraph支持异步执行模式:
- 非阻塞任务处理:即使面对长时间运行的任务也不会影响其他操作的进行。
- 并发用户交互:支持多个用户同时与系统交互而不会产生瓶颈。
- 处理大规模流量:设计考虑到了高负载情况下仍能保持良好性能的要求。
4.7 防止重复消息发送
为了避免由于快速连续输入而导致的消息重叠问题,LangGraph特别设计了一种机制来防止这种情况发生,这对于确保聊天机器人的回复一致性和准确性非常有用。
注意:此特性目前仅LangGraph Cloud云平台支持;本地框架还不支持。
5、 LangGraph的核心组件
为了深入理解LangGraph的工作原理,我们需要了解它的几个关键组成部分:
5.1 Node(节点)
节点是LangGraph中最基本的计算单元,通常表现为一个Python函数。每个节点接收当前的状态作为输入,执行特定的操作后返回更新后的状态。
- 示例用例包括API调用、数据转换或是业务逻辑的执行。
5.2 Edge(边)
边定义了节点之间的逻辑关系,决定了工作流的执行顺序。基于条件逻辑,边可以引导流程走向不同的方向。
- 示例用例包括将用户查询导向适当的智能体或是处理聊天机器人中的不同对话分支。
5.3 State(共享上下文)
状态是在节点之间传递的数据结构,通常是Python字典或类的形式。它可以携带会话历史、用户偏好或者其他必要的数据。
- 在实际应用中,状态可以用来存储对话历史记录或是跟踪自动化流程中的进度。
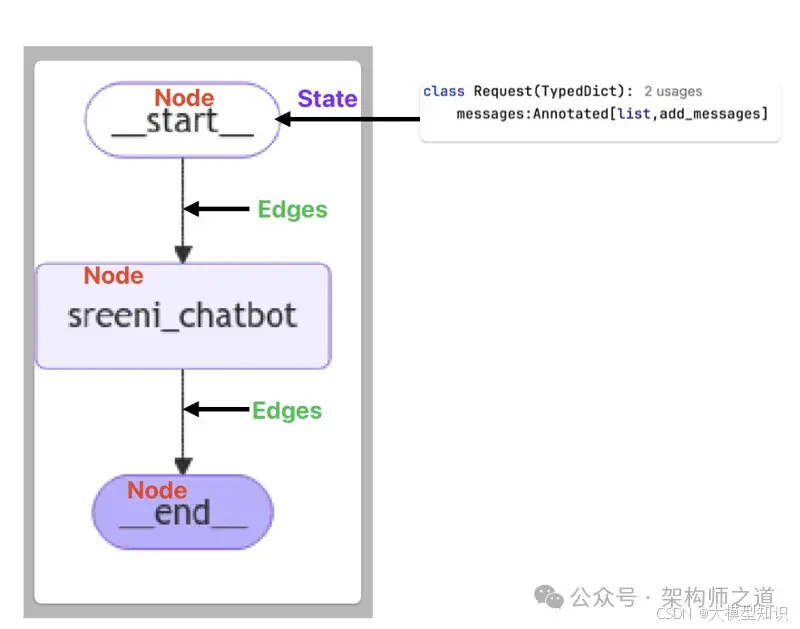
6 、使用LangGraph构建简单聊天机器人
from langgraph.graph import StateGraph, START, END, add_messages
from dotenv import load_dotenv
from langchain_openai.chat_models import AzureChatOpenAI
from typing_extensions import TypedDict, Annotated
from langchain.schema import AIMessage, HumanMessage
# 加载环境变量(例如API密钥)
load_dotenv()
# 初始化Azure OpenAI聊天模型,设置特定参数
llm = AzureChatOpenAI(
azure_deployment="gpt-4o-mini", # 指定部署名称
api_version="2024-08-01-preview", # 使用的API版本
temperature=0, # 控制随机性(0使其确定性更强)
max_tokens=None, # 不限制token数量
timeout=None, # 不设置超时
max_retries=2# 在失败时最多重试2次
)
# 定义一个数据结构来存储对话消息
classRequest(TypedDict):
messages: Annotated[list, add_messages] # 用于存储聊天消息的列表
# 定义聊天函数
defchat(state: Request):
# 调用LLM生成响应
response = llm.invoke(state["messages"])
return {"messages": response}
# 创建LangGraph状态图,使用Request作为状态
graph = StateGraph(Request)
# 将聊天函数添加为图中的一个节点
graph.add_node("sreeni_chatbot", chat)
# 定义图的流程:开始 → 聊天 → 结束
graph.add_edge(START, "sreeni_chatbot")
graph.add_edge("sreeni_chatbot", END)
# 编译工作流
workflow = graph.compile()
# 生成工作流图的可视化表示
image = workflow.get_graph().draw_mermaid_png()
# 将生成的图保存为图片
withopen("sreeni_chatbot.png", "wb") as file:
file.write(image)
# 持续聊天循环
whileTrue:
query = input("Enter your query? ") # 获取用户输入
if query.lower() in ["quit", "exit"]: # 退出条件
print("bye bye")
exit(0)
# 调用工作流,传入用户输入
response = workflow.invoke({"messages": [{"role": "user", "content": query}]})
# 提取AI的响应并打印
ai_response = next((msg.content for msg in response["messages"] ifisinstance(msg, AIMessage)), None)
print(ai_response)
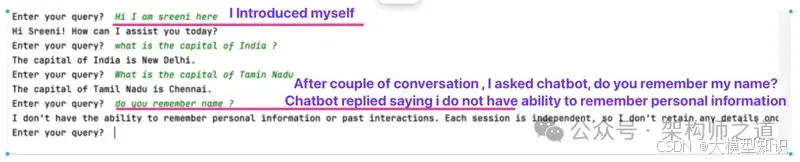
到目前为止,一切顺利。但当你问:“Do you remember my name?(你还记得我的名字吗)”时,聊天机器人却回答道:“I don’t have the ability to remember personal information or past interactions. Each session is independent, so I don’t retain any details once our conversation ends. How can I assist you today?(我无法记住个人信息或过去的互动。每次会话都是独立的,一旦我们的对话结束,我就不会保留任何细节。今天我能为你做些什么呢)”。此时,很明显聊天机器人没有记忆,它将每次查询都视为全新的互动。对于简单的问答来说,这没问题,但对于需要保留上下文的对话式AI来说,这就不够理想了。
为了让聊天机器人更加智能和富有上下文感知能力,我们需要引入记忆。在这种情况下,我们将使用基于内存的方法实现短期记忆。这将允许聊天机器人在会话期间记住细节,但一旦应用程序重新启动,所有记忆都将被擦除。让我们探索如何整合这一功能,让聊天机器人的互动变得更加自然!
7 、为聊天机器人添加检查点记忆
为了给聊天机器人添加记忆,我们需要从langgraph.checkpoint.memory模块导入MemorySaver类。然后,创建该类的实例,并将其作为检查点(checkpoint)添加到编译工作流中。
from typing import Annotated
from langgraph.graph import StateGraph, START, END, add_messages
from dotenv import load_dotenv
from langchain_openai.chat_models import AzureChatOpenAI
from typing_extensions import TypedDict
from langgraph.checkpoint.memory import MemorySaver
# 加载环境变量(例如API密钥)
load_dotenv()
# 初始化Azure OpenAI聊天模型,设置特定参数
llm = AzureChatOpenAI(
azure_deployment="gpt-4o-mini", # 指定部署名称
api_version="2024-08-01-preview", # 使用的API版本
temperature=0, # 控制随机性(0使其确定性更强)
max_tokens=None, # 不限制token数量
timeout=None, # 不设置超时
max_retries=2# 在失败时最多重试2次
)
# 定义一个数据结构来存储对话消息
classRequest(TypedDict):
msgs: Annotated[list, add_messages] # 用于存储聊天消息的列表
# 创建LangGraph状态图,使用Request作为状态
graph = StateGraph(Request)
# 定义一个带有上下文的聊天处理函数
defchat_with_context(state: Request):
msg = state["msgs"] # 提取现有消息
response = llm.invoke(msg) # 调用LLM生成响应
state["msgs"] = response.content # 将响应内容更新到状态中
return {"msgs": state["msgs"]} # 返回更新后的状态
# 将函数添加为图中的一个节点
graph.add_node("sreeni_chatbot", chat_with_context)
# 定义图的流程:开始 → 聊天 → 结束
graph.add_edge(START, "sreeni_chatbot")
graph.add_edge("sreeni_chatbot", END)
# 初始化内存中的状态持久化(短期记忆)
memory = MemorySaver()
# 编译工作流,并启用检查点记忆
workflow = graph.compile(checkpointer=memory)
# 生成工作流图的可视化表示
image = workflow.get_graph().draw_mermaid_png()
# 将生成的图保存为图片
withopen("sreeni_chatbot.png", "wb") as file:
file.write(image)
# 配置用于跟踪用户会话的参数
config = {"configurable": {"thread_id": "1"}}
# 持续聊天循环
whileTrue:
query = input("Enter your query or question? ") # 获取用户输入
if query.lower() in ["quit", "exit"]: # 退出条件
print("bye bye")
exit(0)
# 调用工作流,传入用户输入并维护会话状态
response = workflow.invoke({"msgs": [{"role": "user", "content": query}]}, config=config)
# 打印聊天机器人的响应
print(response["msgs"][-1].content)

在本文中,我们探索了如何使用LangGraph创建简单的聊天机器人,并通过LangGraph的MemorySaver为聊天机器人添加短期记忆。这使得聊天机器人能够在会话中保留上下文,从而实现更自然、更具上下文感知能力的互动。然而,由于采用的是内存中的方法,一旦应用程序重新启动,记忆就会被重置。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 4639
4639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









