







PP-LCNet: A Lightweight CPU Convolutional Neural Network
最近看了一个新的分享,在图像分类的任务上表现良好,具有很高的实践意义。
Abstract|摘要
本文提出了一种名为PP-LCNet的轻量级网络,该网络基于MKLDNN加速策略,旨在提高轻量级模型在多种任务上的性能。本文介绍了能够在几乎不增加延迟的情况下提升网络准确度的技术。通过这些改进,PP-LCNet的准确度显著优于具有相同推理时间的先前网络结构。如图1所示,它的性能优于当前大多数前沿模型。在计算机视觉的后续任务(如目标检测、语义分割等)中,它也展现出卓越的性能。所有实验都是基于PaddlePaddle平台实现的。相关的代码和预训练模型可以在PaddleClas上获取。

1. Introduction|介绍
在近几年中,卷积神经网络(CNNs)成为了计算机视觉领域中众多应用的核心工具,涵盖了诸如图像分类[1, 2]、目标检测[3]、注意力预测[4]、目标跟踪[5]、动作识别[6]、语义分割[7, 8]、显著目标检测[9]以及边缘检测[10]等多个方面。
随着模型特征提取能力的提升以及模型参数和运算量(FLOPs)的增加,基于ARM架构的移动设备和基于x86架构的CPU设备上实现快速推理变得越来越具挑战性。在这种情况下,尽管已经提出了许多适用于移动设备的优秀网络模型,但由于MKLDNN框架的限制,这些网络在支持MKLDNN的Intel CPU上的运行速度并不理想。本文针对这一问题,重新审视了基于Intel CPU设计的轻量级模型的构建要素。特别关注以下三个基本问题:
- 如何在保持低延迟的同时,增强网络学习强大特征表示的能力。
- 哪些关键因素有助于提升CPU上轻量级模型的准确度。
- 如何有效地融合不同的设计策略,以在CPU上构建高效的轻量级模型。
我们的主要贡献在于总结了一系列可以在不延长推理时间的前提下提高准确度的方法,并探讨了如何将这些方法有效结合,以实现准确度与速度之间的最佳平衡。基于这些研究,提出了一些设计轻量级卷积神经网络(CNNs)的通用原则,为其他研究者在CPU设备上构建高效CNNs提供了新的视角。此外,这些研究还可以为神经网络架构搜索领域的研究者提供新的思路,帮助他们在构建搜索空间时更快速地发掘更优的模型。
2. Related Works|相关工作
为了提升模型的性能,目前的研究主要采用两种方法:一种是基于人工设计的卷积神经网络(CNN)架构,另一种是基于神经架构搜索(NAS)[11]。
- 人工设计架构方面
- VGG[12]提出了一种简单而有效的构建深层网络的策略:堆叠相同维度的块。
- GoogLeNet[13]则创新地设计了Inception块,包括四个并行操作:1×1卷积、3×3卷积、5×5卷积和最大池化,使得卷积神经网络更加轻量级。
- MobileNetV1[14]通过深度可分卷积和逐点卷积替代了标准卷积,大幅降低了参数和运算量。
- MobileNetV2[15]进一步提出了倒置块,减少了FLOPs的同时提升了性能。
- ShuffleNetV1/V2[16,17]通过通道混洗减少网络结构的冗余。
- GhostNet[18]则提出了一种新颖的Ghost模块,用更少的参数生成更多的特征图,从而提升模型的整体性能。
- 在神经架构搜索方面
- 通过自适应地针对特定任务进行系统化搜索,取代了传统的手动设计网络架构。
- 如**EfficientNet[19]、MobileNetV3[20]、FBNet[21]、DNANet[22]、OFANet[23]**等,都采用了与MobileNetV2[15]相似的搜索空间。
- MixNet[24]则提出了一种创新方法,通过在一个层中混合不同核大小的深度可分卷积。
尽管NAS生成的网络依赖于如BottleNeck[25]、Inverted-block[15]等手动设计的块,但我们的方法可以减少搜索空间并提高搜索效率,从而可能在未来工作中进一步提升整体性能。
3. Approach|方法
尽管许多轻量级网络在基于ARM架构的设备上能实现快速推理,但在启用MKLDNN等加速策略的Intel CPU上,这些网络的性能却很少被考虑。许多用于提升模型准确度的方法在ARM设备上可能不会显著增加推理时间,但在Intel CPU设备上则可能不同。我们总结了一些能够在几乎不增加推理时间的情况下提升模型性能的方法,这些方法将在下文中详细阐述。我们采用了MobileNetV1[14]中提出的深度可分卷积(DepthSepConv)作为基本模块。这个模块不包含如短路shortcut等操作,因此避免了额外的操作,如拼接concat或逐元素elementwise-add相加,这些操作不仅会降低模型的推理速度,而且在小型模型上也不会提高准确度。此外,这个模块已被Intel CPU加速库深度优化,其推理速度可以超过其他轻量级模块,如倒置块inverted或ShuffleNet块。我们将这些模块堆叠起来,形成了一个类似于MobileNetV1[14]的BaseNet。通过将BaseNet与现有的一些技术相结合,我们构建了一个更强大的网络,即PP-LCNet。
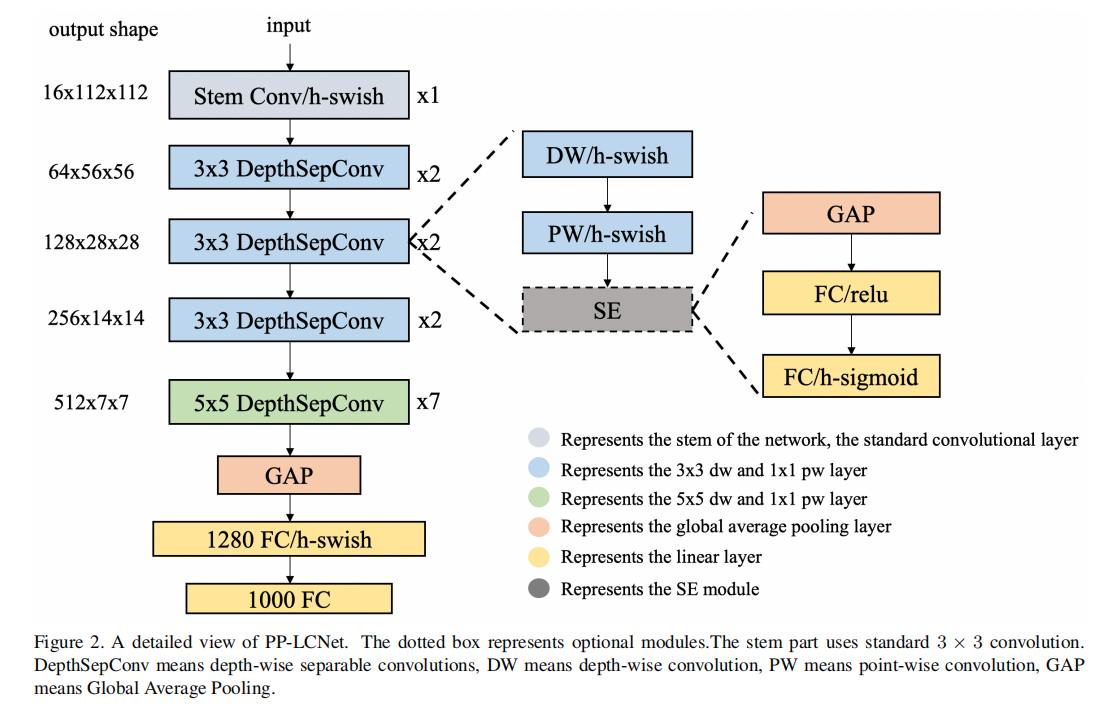
3.1 Better activation function|更好的激活函数
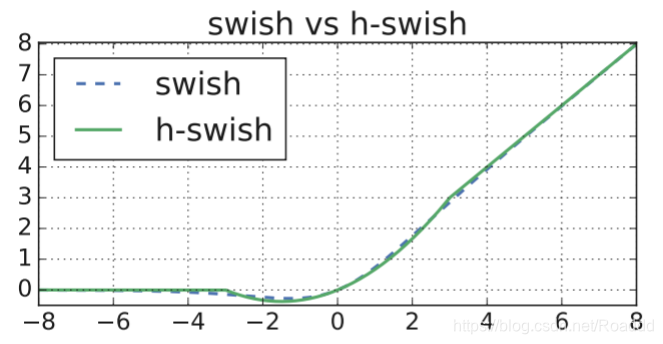
众所周知,激活函数的质量往往决定了网络的性能。自从网络的激活函数从Sigmoid改为ReLU以来,网络的性能得到了显著提升。近年来,越来越多的激活函数超越了ReLU。在EfficientNet[19]使用Swish激活函数取得了更好的性能后,MobileNetV3[20]的作者将其升级为H-Swish,以避免大量的指数运算。随后,许多轻量级网络也开始采用这种激活函数。我们也将在BaseNet中使用的激活函数从ReLU替换为H-Swish,从而大幅提升了性能,而推理时间几乎没有变化。
Swish 激活函数已经被证明是一种比 ReLU 更佳的激活函数,但是相比 ReLU,它的计 算更复杂,因为有 sigmoid 函数。为了能够在移动设备上应用 swish 并降低它的计算开销, 提出了 h-swish
- swish激活函数
s w i s h ( x ) = x ∗ δ ( x ) swish(x) = x * \delta(x) swish(x)=x∗δ(x)
- h-swish激活函数
h s w i s h ( x ) = x ∗ R e L U 6 ( x + 3 ) 6 hswish(x) = x* \frac {ReLU6(x+3)} {6} hswish(x)=x∗6ReLU6(x+3)
- 图像
3.2 SE modules at appropriate positions|合适位置放置SE模块
自SE模块[26]提出以来,它已被广泛应用于众多网络中。这个模块帮助SENet[26]赢得了2017年ImageNet[27]分类竞赛。它在为网络通道赋予更好的特征方面表现出色,并且其速度改进版本也被许多轻量级网络,如MobileNetV3[20]所采用。然而,在Intel CPU上,SE模块[26]会增加推理时间,所以我们不能在整个网络中使用它。实际上,我们进行了大量实验并发现,当SE模块[26]位于网络的末端时,它的效果更好。因此,只在网络尾部的块中添加了SE模块[26]。这使得准确度与速度之间达到了更好的平衡。与MobileNetV3[20]类似,SE模块[26]的两层激活函数分别是ReLU和HSigmoid。

3.3 Larger convolution kernels|更大的卷积核
卷积核的大小对网络性能有着显著的影响。在MixNet[24]中,作者研究了不同大小卷积核对网络性能的影响,并最终在网络的同一层中混合了不同大小的卷积核。然而,这样的混合会减慢模型的推理速度,所以我们尝试在单层中只使用一种大小的卷积核,并确保在低延迟和高准确度的情况下使用大卷积核。实验发现,类似于SE模块[26]的位置,仅在网络尾部使用5×5卷积核替换3×3卷积核,可以达到替换几乎所有网络层的效果,所以我们只在网络尾部进行了这样的替换操作。

3.4 Larger dimensional 1 × 1 conv layer after GAP
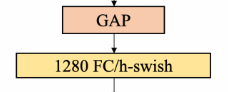
在我们的轻量级网络PP-LCNet中,经过全局平均池化(GAP)后,网络的输出维度较小。直接添加最后的分类层可能会丢失特征的组合。为了增强网络的拟合能力,在最后的GAP层之后添加了一个1280维的1×1卷积(相当于全连接层),这样可以在不增加太多推理时间的情况下存储更多模型。
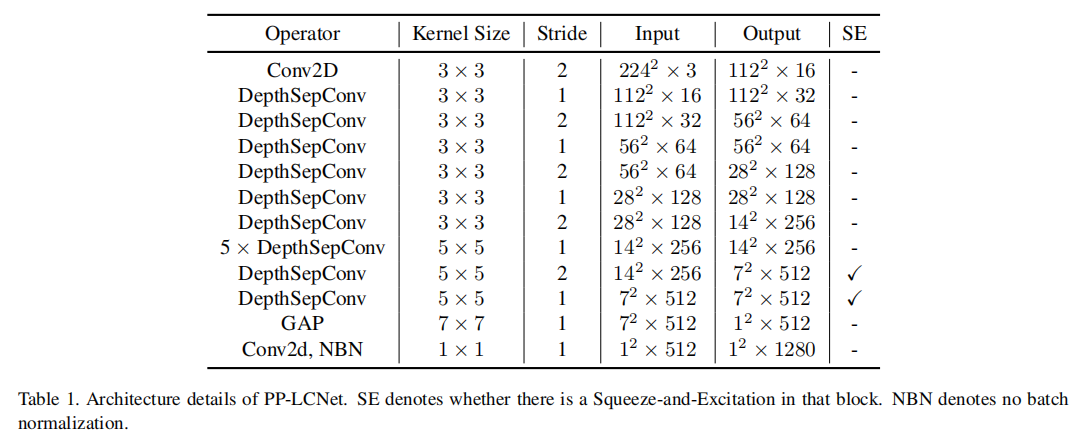
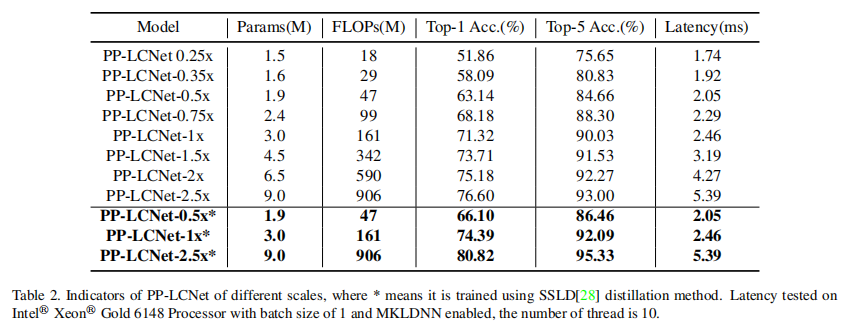
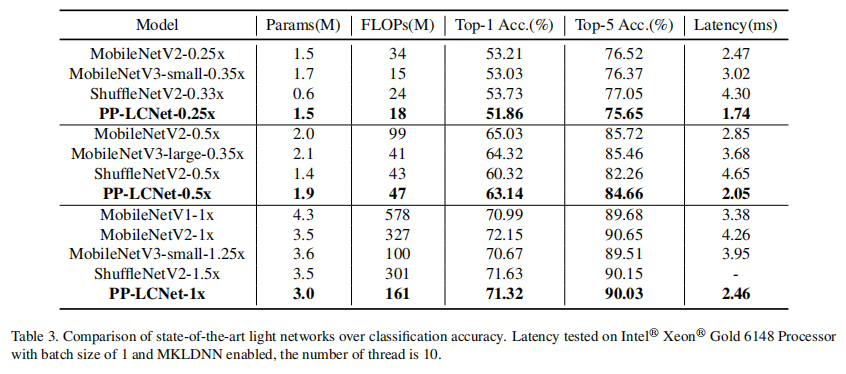
通过这四种改进,我们的模型在ImageNet-1k[27]数据集上表现良好,表3列出了我们在Intel CPU上与其他轻量级模型的性能对比。
4. Experiment|实验
4.1 Implementation Details|实现细节
为了进行公平的比较,使用PaddlePaddle重新实现了MobileNetV1[14]、MobileNetV2[15]、MobileNetV3[20]、ShuffleNetV2[17]、PicoDet[29]和Deeplabv3+[8]。在4块V100 GPU上训练这些模型,CPU测试环境基于Intel Xeon Gold 6148处理器,批处理大小为1,并启用了MKLDNN加速。
4.2 Image Classification|图像分类
在图像分类任务中,在ImageNet-1k[27]数据集上对PP-LCNet进行了训练,该数据集包含128万张训练图像和5万张1000个类别的验证图像。使用了带有权重衰减设置为3e-5(大型模型为4e-5)的SGD优化器,动量设置为0.9,批处理大小为2048。学习率根据余弦调度进行调整,用于训练360个epoch,其中包含5个线性预热epoch。初始学习率设为0.8。 在训练阶段,每个图像被随机裁剪到224×224并随机水平翻转。在评估阶段,首先将图像沿短边缩放到256,然后应用中心裁剪到224×224。表2展示了不同规模下PP-LCNet的top-1和top-5验证准确度以及推理时间。此外,使用SSLD[28]蒸馏方法时,模型的准确度可以显著提高。表3展示了PP-LCNet与最先进模型的比较。与其他轻量级模型相比,PP-LCNet展现了强大的竞争力。
4.3 Object Detection|目标检测
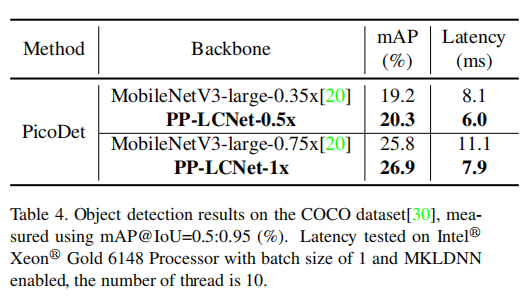
对象检测任务中,在COCO-2017[30]数据集上训练了所有模型,该数据集包含80个类别和118,000张图像。这些模型在COCO-2017[30]的验证集上进行了评估,该验证集包含5000张图像。我们使用了由PaddleDection开发的轻量级PicoDet作为基准模型。表4展示了以PP-LCNet和MobileNetV3[20]为骨干的物体检测结果。整个网络使用随机梯度下降(SGD)进行了146K次迭代,以224张图像的minibatch在4个GPU上进行分布训练。学习率计划是余弦的,从0.3作为基础学习率,持续280个epoch。权重衰减设置为1e-4,动量设置为0.9。令人印象深刻的是,PP-LCNet的骨干网络在COCO[30]上的mAP和推理速度相比MobileNetV3[20]有了显著的提高。
4.4 Semantic Segmentation|语义分割
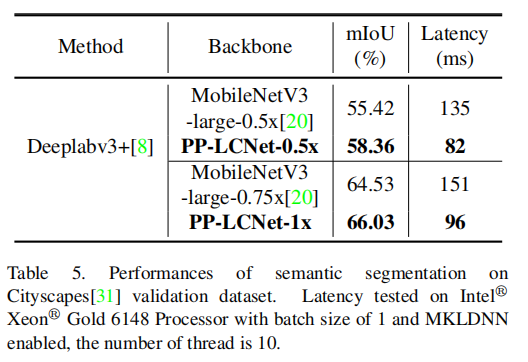
在语义分割任务中,还对PP-LCNet在Cityscapes数据集[31]上的性能进行了评估,该数据集包含5000张高质量标注的图像。我们采用了由PaddleSeg开发的DeeplabV3+[8]作为基准方法,并将输出步长设置为32。数据通过随机水平翻转、随机缩放和随机裁剪进行增强。随机缩放包括{0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0},裁剪分辨率设置为1024 × 512。我们使用初始学习率为0.01的SGD优化器,动量为0.9,权重衰减为4e-5。我们采用幂函数学习率计划,幂值为0.9。所有模型在4块V100 GPU上以32的批大小训练了80K次迭代。
在比较中,采用了MobileNetV3[20]作为骨干网络。如表5所示,PP-LCNet-0.5x在mIoU(平均交并比)上比MobileNetV3-large-0.5x[20]高出2.94%,尽管如此,它的推理时间却减少了53毫秒。与更大的模型相比,PP-LCNet也展示了强大的性能。当使用PP-LCNet-1x作为骨干网络时,模型的mIoU比MobileNetV3-large-0.75x高出1.5%,但推理时间减少了55毫秒。
4.5 Ablation Study|消融研究
- SE模块[26]在不同位置的效果。
- SE模块[26]是一种通道间的注意力机制,能够提高模型的准确性。
- 然而,如果随意增加SE模块[26]的数量,模型的推理速度将会下降,因此研究如何合理地在模型中添加SE模块[26]是值得的。
- 通过实验,我们发现SE模块[26]对网络的尾部影响最大。
- 表7展示了在网络不同位置添加仅两个SE模块[26]的结果。表格清楚地显示,在网络的最后两个块中添加SE模块[26]对于几乎相同的推理时间更为有利。
- 因此,为了平衡推理速度,PP-LCNet只在网络的最后两个块中添加SE模块[26]。
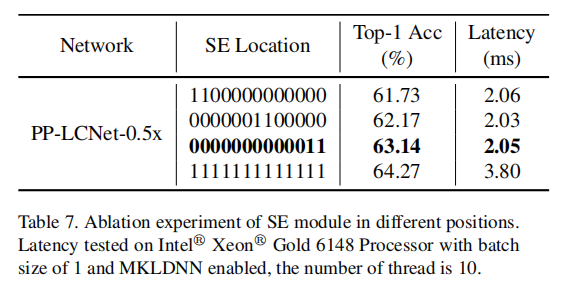
- 大核在不同位置的影响。
- 尽管大核可以提高准确度,但在网络的所有位置添加它并不是最佳选择。
- 通过实验,已经展示了正确添加大核的一般规则。表8展示了5×5深度可分离卷积的位置。其中,1表示DepthSepConv中的深度可分离卷积核为5×5,0表示DepthSepConv中的深度可分离卷积核为3×3。
- 从表中可以看出,与SE模块[26]添加的位置相似,将5×5卷积添加到网络的尾部也更具竞争力。PP-LCNet选择了表中第三行的配置。
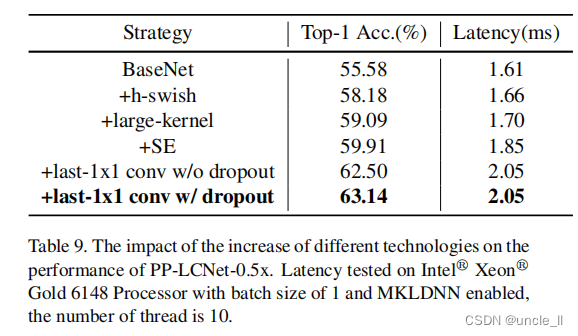
- 不同技术的影响。
- 在PP-LCNet中,采用了4种不同的技术来提升模型的性能。
- 表9展示了这些技术对PP-LCNet的累积提升,表6则列出了减少不同模块对PP-LCNet的影响。
- 可以看出,H-Swish和大核能够在不增加太多推理时间的情况下提升模型性能。
- 增加少量SE模块[26]能进一步提升性能。
- 在GAP之后使用更大的全连接层也能显著提高准确度。
- 同时,由于涉及相对较大的矩阵,dropout策略的使用能够进一步提高模型的准确度。

5. Conclusion and Future work
本研究总结了设计轻量级Intel CPU网络的一些方法,这些方法能够在保持推理时间不变的同时提高模型的准确性。尽管这些方法源自于以往的研究,但它们在准确性与速度之间的平衡尚未通过实验得到充分验证。通过广泛的实验和对这些方法的验证,我们提出了PP-LCNet,它在多个视觉任务上表现更加强大,并且实现了更好的准确性与速度平衡。此外,这项工作还减少了神经架构搜索(NAS)的搜索空间,并为NAS提供了更快获得轻量级模型的可能性。在未来,我们也将使用NAS来获得更快、更强大的模型。
References
-
[1] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012. 1
-
[2] Jia Li, Yafei Song, Jianfeng Zhu, Lele Cheng, Ying Su, Lin Ye, Pengcheng Yuan, and Shumin Han. Learning from large scale noisy web data with ubiquitous reweighting for image classification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. 1
-
[3] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91–99, 2015. 1
-
[4] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017. 1
-
[5] Tianzhu Zhang, Changsheng Xu, and Ming-Hsuan Yang. Multi-task correlation particle filter for robust object tracking. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4335–4343, 2017. 1
-
[6] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems, pages 568–576, 2014. 1
-
[7] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017. 1
-
[8] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, \2017. 1, 4, 5
-
[9] Ali Borji, Ming-Ming Cheng, Qibin Hou, Huaizu Jiang, and Jia Li. Salient object detection: A survey. Computational visual media, pages 1–34, 2019. 1
-
[10] Yun Liu, Ming-Ming Cheng, Xiaowei Hu, Kai Wang, and Xiang Bai. Richer convolutional features for edge detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3000–3009, 2017. 1
-
[11] Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning. arXiv preprint arXiv:1611.01578, \2016. 2
-
[12] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 2
-
[13] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1–9, 2015. 2
-
[14] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco An dreetto, and Hartwig Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861, 2017. 2, 3, 4
-
[15] Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4510–4520, 2018. 2, 4
-
[16] Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6848–6856, 2018. 2
-
[17] Ningning Ma, Xiangyu Zhang, Hai-Tao Zheng, and Jian Sun. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European conference on computer vision (ECCV), pages 116–131, 2018. 2, 4
-
[18] Kai Han, Yunhe Wang, Qi Tian, Jianyuan Guo, Chunjing Xu, and Chang Xu. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1580–1589, 2020. 2
-
[19] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019. 2, 3
-
[20] Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, pages 1314–1324, 2019. 2, 3, 4,5
-
[21] Bichen Wu, Xiaoliang Dai, Peizhao Zhang, Yanghan Wang, Fei Sun, Yiming Wu, Yuandong Tian, Peter Vajda, Yangqing Jia, and Kurt Keutzer. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 10734–10742, 2019. 2
-
[22] Changlin Li, Jiefeng Peng, Liuchun Yuan, Guangrun Wang, Xiaodan Liang, Liang Lin, and Xiaojun Chang. Blockwisely supervised neural architecture search with knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1989–1998, 2020. 2
-
[23] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment. arXiv preprint arXiv:1908.09791, \2019. 2
-
[24] Mingxing Tan and Quoc V Le. Mixconv: Mixed depthwise convolutional kernels. arXiv preprint arXiv:1907.09595, \2019. 2, 3
-
[25] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
-
[26] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018. 3,5, 6
-
[27] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3, 4
-
[28] Cheng Cui, Ruoyu Guo, Yuning Du, Dongliang He, Fu Li, Zewu Wu, Qiwen Liu, Shilei Wen, Jizhou Huang, Xiaoguang Hu, et al. Beyond self-supervision: A simple yet effective network distillation alternative to improve backbones. arXiv preprint arXiv:2103.05959, 2021. 4, 5
-
[29] PaddlePaddle Authors. Paddledetection, object detection and instance segmentation toolkit based on paddlepaddle. https://github.com/PaddlePaddle/PaddleDetection, 2019. 4
-
[30] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 5
-
[31] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 5
实践
任务:分类图片中是否有人还是无人,先git clone paddleclas项目,然后进入项目;
环境安装
- 安装paddlepaddle
# CPU only
python3 -m pip install paddlepaddle==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# CUDA 10.2
python3 -m pip install paddlepaddle-gpu==2.5.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
# CUDA 11.2
python3 -m pip install paddlepaddle-gpu==2.5.2.post112 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# CUDA 11.6
python3 -m pip install paddlepaddle-gpu==2.5.2.post116 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# CUDA 11.7
python3 -m pip install paddlepaddle-gpu==2.5.2.post117 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
# CUDA 12.0
python3 -m pip install paddlepaddle-gpu==2.5.2.post120 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
- 安装paddleclas
pip install paddleclas
数据
wget https://paddleclas.bj.bcebos.com/data/PULC/person_exists.tar

- nobody:标签0
- someone:标签1
训练
GPU机器下,假若两张显卡
export CUDA_VISIBLE_DEVICES=0,1
python3 -m paddle.distributed.launch \
--gpus="0,1" \
tools/train.py \
-c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml
评估
训练好模型之后,可以通过以下命令实现对模型指标的评估。
python3 tools/eval.py \
-c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
-o Global.pretrained_model="output/PPLCNet_x1_0/best_model"
预测
模型训练完成之后,可以加载训练得到的预训练模型,进行模型预测。在模型库的 tools/infer.py 中提供了完整的示例,只需执行下述命令即可完成模型预测:
python3 tools/infer.py \
-c ./ppcls/configs/PULC/person_exists/PPLCNet_x1_0.yaml \
-o Global.pretrained_model=output/PPLCNet_x1_0/best_model
输出结果如下:
[{'class_ids': [1], 'scores': [0.9999976], 'label_names': ['someone'], 'file_name': 'deploy/images/PULC/person_exists/objects365_02035329.jpg'}]
- 这里
-o Global.pretrained_model="output/PPLCNet_x1_0/best_model"指定当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。 - 默认是对
deploy/images/PULC/person_exists/objects365_02035329.jpg进行预测,此处也可以通过增加字段-o Infer.infer_imgs=xxx对其他图片预测。 - 二分类默认的阈值为0.5, 如果需要指定阈值,可以重写
Infer.PostProcess.threshold,如-o Infer.PostProcess.threshold=0.9794,该值需要根据实际场景来确定。


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











