







Dify 介绍
项目概览
- 名称:Dify 一词源自 Define + Modify,意指定义并且持续的改进你的 AI 应用,它是为你而做的(Do it for you)。
- 描述: Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。 由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
- GitHub 地址: langgenius/dify
- 官网地址:Dify.AI · 生成式 AI 应用创新引擎
- 官方文档:欢迎使用 Dify
主要技术特性
-
后端技术:Python/Flask/PostgreSQL
-
前端技术:Next.js
| 特性 | 描述 |
|---|---|
| LLM 推理引擎 | Dify Runtime (自 v0.4 起移除了 LangChain) |
| 商业模型支持 | 10+ 家,包括 OpenAI 与 Anthropic 新的主流模型通常在 48 小时内完成接入 |
| MaaS 供应商支持 | 7 家:Hugging Face、Replicate、AWS Bedrock、NVIDIA、GroqCloud、together.ai、OpenRouter |
| 本地模型推理 Runtime 支持 | 6 家:Xoribits(推荐)、OpenLLM、LocalAI、ChatGLM、Ollama、NVIDIA TIS |
| OpenAI 接口标准模型接入支持 | ∞ 家 |
| 多模态技术 | ASR 模型 GPT-4o 规格的富文本模型 |
| 预置应用类型 | 对话型应用 文本生成应用 Agent 工作流 |
| Prompt 即服务编排 | 可视化编排界面支持实时预览 编排模式 : - 简易模式 - Assistant 模式 - Flow 模式 变量类型 : - 字符串 - 单选枚举 - 外部 API - 文件(Q3 支持) |
| Agentic Workflow 特性 | 可视化流程编排 + 节点调试 支持节点 : - LLM - 知识库检索 - 问题分类 - 条件分支 - 代码执行 - 模板转换 - HTTP 请求 - 工具 |
| RAG 特性 | 可视化知识库管理 索引方式 : - 关键词 - 文本向量 - LLM辅助问题-分段 检索方式 : - 关键词 - 相似度匹配 - 混合检索 - 多路召回 召回优化 : ReRank 模型 |
| ETL 技术 | 支持 TXT/Markdown/PDF/HTML/DOC/CSV 自动清洗 支持同步 Notion 文档和网页 |
| 向量数据库支持 | Qdrant(推荐)、Weaviate、Milvus、Pgvector、Chroma、OpenSearch、TiDB、腾讯向量、Oracle 等 14 家 |
| Agent 技术 | ReAct + Function Call 工具支持 : - OpenAI Plugin 标准 - OpenAPI Specification 内置工具 : 40+ 款(2024 Q2) |
| 日志 | 支持日志标注 |
| 标注回复 | 支持 Q&A 对标注 可导出为微调数据格式 |
| 内容审查机制 | OpenAI Moderation 或外部 API |
| 团队协同 | 工作空间与多成员管理 |
| API 规格 | RESTful(功能全覆盖) |
| 部署方式 | Docker、Helm |
主要特性
- Prompt 可视化编排: 支持拖拽组件进行复杂逻辑的设计。
- 多模型集成: 支持多种大语言模型提供商,如 OpenAI、Anthropic、阿里云等。
- 增强检索 (Retrieval-Augmented Generation): 利用 RAG 技术结合向量数据库提高回复质量。
- 工作流引擎: 提供强大的任务调度能力和自定义脚本执行。
- 多租户管理: 支持多个组织和个人用户的资源隔离和权限控制。
架构图
1. Dataset(数据集)
- Dataset ETL:负责数据的抽取、转换和加载。这一步确保数据准备好,以便后续处理。
- Dify RAG Pipeline:RAG(检索增强生成)管道,负责检索、索引和评估数据,以便更好地支持模型的生成任务。
- Storage:存储模块,包括向量数据库(VectorDB)、关系数据库(Relation DB)和知识图谱(KG)等,用于存储数据和模型需要的其他信息。
2. Prompts(提示词)
- Dify Prompts IDE:一个集成开发环境,用于创建和管理提示词。它支持 Playground(测试环境)、Endpoint(端点)和 Version(版本控制)等功能。
- Dify Agent DSL:一个领域特定语言(DSL),用于定义智能体的行为,包括感知(Perception)、规划(Planning)和行动(Action)。
3. Orchestration Studio(编排工作室)
- 核心模块:负责协调和管理整个应用栈中的各个组件,确保数据和指令在不同模块之间正确流动。
4. Plugins Toolbox(插件工具箱)
- Workflow, Community, Interface…:提供各种插件和工具,用于扩展平台的功能,支持工作流管理、社区互动和用户界面定制等。
5. Dify LLMOps
- Monitor, Annotation, Lifecycle…:负责模型的监控、标注和生命周期管理,确保模型在生产环境中的性能和质量。
6. Queries Requests(查询请求)
- Dify BaaS Platform:提供 API 和 AgentaaS 服务,支持应用构建和集成。
- API/AgentaaS:提供 API 接口和智能体即服务,方便开发者集成和使用。
- App Builder:应用构建器,帮助用户快速构建基于 LLMs 的应用。
7. Moderation System(审核系统)
- Filtering, Risk Ass, Quality…:负责内容过滤、风险评估和质量控制,确保生成内容的安全性和高质量。
- Cache System:缓存系统,用于日志记录、快照和结果缓存,提高系统性能和响应速度。
8. LLMs(大型语言模型)
- Commercial LLMs:商业化的大型语言模型。
- Open Source LLMs:开源的大型语言模型。
- MaaS Platform:模型即服务平台,提供模型的部署和管理服务。
流程说明
- Contextual data(上下文数据):绿色箭头表示数据在系统中的流动,从数据集到存储,再到模型和响应。
- Prompts and examples(提示词和示例):蓝色箭头表示提示词和示例在系统中的使用,从提示词管理到编排工作室,再到模型。
- Queries & Requests(查询和请求):橙色箭头表示用户查询和请求的处理流程,从请求到平台,再到模型和响应。
- Outputs & Responses(输出和响应):红色箭头表示模型的输出和响应,从模型到缓存系统,再到用户。
Dify Orchestration Studio 的功能介绍

它是一个用于构建和管理生成式 AI 应用的专业工作站。图中展示了六个主要的功能模块:
RAG Pipeline
- 功能:安全地构建私有数据与大型语言模型之间的数据通道,并提供高可靠的索引和检索工具。
- 作用:通过检索增强生成(RAG)技术,将私有数据与语言模型结合,提高生成内容的准确性和相关性。
Prompt IDE
- 功能:为提示词工程师设计的友好易用的提示词开发工具,支持无缝切换多种大型语言模型。
- 作用:提供一个集成开发环境,方便工程师创建、测试和管理提示词,确保生成内容的质量。
Enterprise LLMOps
- 功能:开发者可以观测推理过程、记录日志、标注数据、训练并微调模型,使应用脱离黑盒,持续迭代优化。
- 作用:提供企业级的模型操作和管理工具,帮助开发者监控和优化模型性能,确保应用的透明性和可维护性。
BaaS Solution
- 功能:基于后端及服务理念的 API 设计,大幅简化生成式 AI 应用研发流程。
- 作用:通过提供即用即付的 API 服务,降低开发门槛,加速生成式 AI 应用的开发和部署。
LLM Agent
- 功能:定制化 Agent,自主调用系列工具完成复杂任务。
- 作用:通过智能代理自动化处理复杂任务,提高工作效率和处理复杂业务流程的能力。
Workflow
- 功能:编排 AI 工作流,使其输出更稳定可控。
- 作用:通过工作流管理,确保 AI 应用的输出稳定性和可控性,满足企业级应用的需求。
Dify Orchestration Studio 旨在为开发者提供一个全面的平台,整合了数据处理、提示词管理、模型操作、API 服务、智能代理和工作流管理等功能,以支持高效构建和管理生成式 AI 应用。
安装指南
前置条件
确保以下软件已正确安装:
- Git: 版本 >= 2.23
- Python: 版本 >= 3.9
- Node.js & npm: Node.js 版本 >= 14.x, npm 版本 >= 6.x
- PostgreSQL: 版本 >= 12.x
- Redis: 最新稳定版本
克隆仓库
git clone https://github.com/langgenius/dify.git
cd dify
安装依赖
进入后端目录并安装所需的 Python 包:
cd backend
pip install -r requirements.txt
进入前端目录并安装所需的 JavaScript 包:
cd ../frontend
npm install
配置环境变量
复制 .env.example 文件为 .env 并编辑其中的配置项:
cp .env.example .env
nano .env
初始化数据库
运行迁移脚本来设置初始数据库模式:
alembic upgrade head
启动服务
后台服务
uvicorn app.main:app --reload
前台服务
cd frontend
npm start
访问浏览器查看是否成功启动:
- Backend: http://localhost:8000/docs (API 文档)
- Frontend: http://localhost:3000/
核心功能详解
1. Prompt 可视化编排
允许用户通过图形界面轻松设计复杂的提示流程,无需编写大量代码。支持条件判断、循环等多种高级操作。Prompt Visual Editor
2. 多模型集成
内置对多种主流大语言模型的支持,并且可以通过简单的配置接入新的模型提供商。
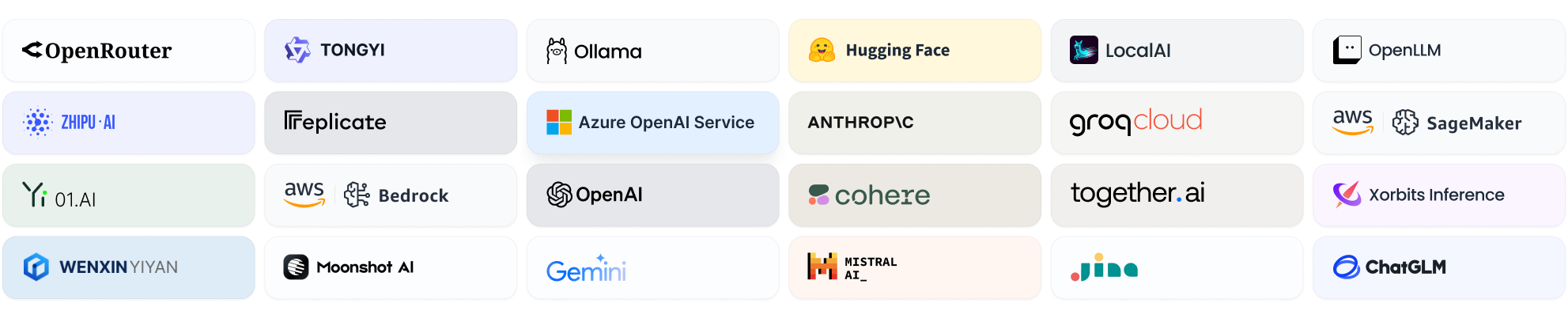
常用模型列表
- OpenAI Models: GPT-3, GPT-4
- Anthropic Models: Claude
- Alibaba Cloud Models: Qwen
- Custom Providers: 自定义 RESTful API
3. 增强检索 (RAG)
利用 Retriever-Augmented Generation 技术,结合外部知识库提高生成文本的质量和准确性。
支持的数据格式
- TXT
- Markdown
- JSON
向量存储选项
- Faiss: 适用于小规模数据集
- Pgvector: PostgreSQL 扩展,适合大规模分布式存储
4. 工作流引擎
提供灵活的工作流管理和任务调度能力,支持自定义脚本执行。
基本概念
- Nodes: 功能单元,例如 HTTP 请求、数据库查询等。
- Edges: 连接 Nodes 形成 DAG 图形。
- Scripts: 使用 Python 编写的自定义逻辑。
5. 多租户管理
支持不同组织和个人用户的独立空间和权限分配。
角色与权限
- Admin: 全局管理员,拥有最高权限。
- User: 普通用户,只能访问自己的应用和服务。
- Guest: 访客用户,仅能浏览公开内容。
云服务工作室 - Dif
-
知识库:
# 如何制作蛋炒饭 蛋炒饭是一道简单又美味的家常菜,关键在于米饭的干爽和火候的掌握。以下是经典做法: ------ ### **材料准备**(1-2人份) - 隔夜米饭 1碗(水分少更佳,或用新鲜米饭晾凉后使用) - 鸡蛋 2个 - 葱花 适量 - 火腿肠/午餐肉/虾仁 适量(可选) - 胡萝卜丁、青豆、玉米粒等 适量(可选) - 盐 适量 - 生抽 1小勺(可选,提鲜) - 胡椒粉 少许 - 食用油 2-3勺 ------ ### **步骤详解** 1. **处理食材** - 鸡蛋打入碗中,加少许盐和胡椒粉打散。 - 火腿肠、胡萝卜等配菜切丁,青豆/玉米焯水备用(如果用的话)。 - 隔夜米饭提前用手或勺子轻轻捏散,避免结块。 2. **炒鸡蛋** - 热锅倒1勺油,中火将蛋液倒入,快速用锅铲划散,炒至凝固但保持嫩滑,盛出备用。 3. **炒配菜** - 补少许油,中火将葱花爆香,加入火腿丁、胡萝卜丁等配菜翻炒至断生。 4. **炒米饭** - 转中大火,倒入米饭快速翻炒,用铲背压散结块,炒至米饭粒粒分明(约2分钟)。 - 将炒好的鸡蛋倒回锅中,与米饭混合均匀。 5. **调味** - 加盐、少许生抽(可选)调味,撒胡椒粉提香,翻炒均匀。 - 出锅前撒葱花,翻炒两下即可。 ------ ### **技巧总结** - **米饭处理**:隔夜饭最佳,新鲜米饭可铺开晾凉或用冰箱冷藏1小时去水分。 - **蛋液裹饭法**(可选):蛋液直接倒入米饭拌匀再炒,让每粒饭裹上蛋液,呈现金黄色。 - **火候**:全程中大火快炒,避免粘锅,用不粘锅更省心。 - **配菜灵活**:可按喜好加香菇、腊肠、虾仁等,但不宜过多以免抢味。 ------ 这样炒出的蛋炒饭干香松软,蛋香浓郁,快去试试吧! # 如何制作回锅肉 回锅肉是川菜中的经典家常菜,以“肥而不腻、香辣回甜”著称,关键在于肉片的处理和豆瓣酱的炒香。以下是传统做法: ------ ### **材料准备**(2人份) - 主料 - 带皮五花肉 300克(或二刀肉,肥瘦相间为佳) - 配菜 - 蒜苗(青蒜)100克,斜刀切段(蒜白和蒜叶分开放) - 可选配菜:青椒、洋葱、莲白等 - 调料 - 郫县豆瓣酱 1.5大勺(灵魂调料,不可省略) - 豆豉 10克(切碎,提味用) - 甜面酱 1小勺(可选,增加酱香) - 生抽 1小勺 - 白糖 1/2小勺(平衡咸辣) - 料酒 1大勺 - 姜片 3片、葱段 2根(煮肉用) - 食用油 少许(五花肉会出油) ------ ### **步骤详解** #### **1. 煮肉处理**(关键步骤) - **煮肉**:五花肉冷水下锅,加姜片、葱段、1大勺料酒,中火煮20-25分钟,至筷子能轻松插入肉皮(肉熟但未软烂)。 - **冷却**:捞出肉用冷水冲洗,擦干水分后切成2-3毫米薄片(越薄越易出灯盏窝)。 #### **2. 煸炒肉片**(出油的关键) - 热锅放少许油,中火下肉片翻炒至肉片卷曲、肥肉部分透明(此时煸出多余油脂,肉片边缘微焦呈“灯盏窝”状)。 - 将肉片拨到锅边,倒出部分猪油(避免油腻,保留约1-2勺油炒酱)。 #### **3. 炒香调料** - 转小火,锅中余油里加入豆瓣酱、豆豉碎,炒出红油和香味(避免火大炒糊)。 - 加入甜面酱(可选)翻炒均匀,再与肉片混合。 #### **4. 调味与配菜** - 加入生抽、白糖调味,中火翻炒使肉片裹满酱料。 - 先下蒜苗白色部分炒至断生,再放入蒜叶快速翻炒均匀(约30秒,保持蒜叶翠绿)。 #### **5. 出锅** - 关火,淋少许锅边醋(可选,增香解腻),装盘即可。 ------ ### **技巧总结** - **选肉**:带皮五花肉或二刀肉(后腿肉)最佳,肥瘦比例3:7。 - **切片**:肉冷却后切薄片,热刀切更整齐。 - **火候**:煸肉时中火逼出油脂,炒酱务必小火防焦。 - **灯盏窝**:肉片薄且煸炒到位时自然卷曲,形成标志性的窝状。 - **替代方案**:若无蒜苗,可用青椒、卷心菜代替;豆瓣酱不可少,若无甜面酱可略加糖调和。 ------ 这样炒出的回锅肉酱香浓郁,肉片油亮微卷,搭配米饭绝佳 # 如何制作辣椒炒肉 辣椒炒肉是湘菜中的经典家常菜,讲究“鲜辣下饭,肉嫩椒香”,关键在于辣椒的煸炒和肉片的滑嫩处理。以下是地道做法: ------ ### **材料准备**(2人份) - 主料 - 猪前腿肉/五花肉 200克(肥瘦相间) - 螺丝椒/线椒 5-6根(辣味足,皮薄的品种) - 辅料 - 蒜片 3瓣 - 豆豉 1小勺(可选,增香) - 腌肉料 - 生抽 1大勺 - 老抽 1/2小勺(上色) - 料酒 1小勺 - 淀粉 1小勺(锁住水分) - 调味 - 盐 少许(根据辣椒辣度调整) - 蚝油 1小勺 - 香醋 几滴(出锅前淋,提味) ------ ### **步骤详解** #### **1. 处理食材** - **肉片腌制**:猪肉切薄片(肥瘦分开,肥肉煸油用),瘦肉加腌肉料抓匀,最后淋1勺油封住水分,腌10分钟。 - **辣椒处理**:辣椒斜刀切滚刀块(去籽可减辣),拍松更易入味。 #### **2. 干煸辣椒**(关键步骤) - 热锅不放油,直接下辣椒中火煸炒,边炒边用锅铲按压,至辣椒表皮微皱、散发焦香(约3分钟),盛出备用。 #### **3. 炒肉片** - 热锅加少许油,先下肥肉片煸出油脂至金黄,再放蒜片、豆豉爆香。 - 转大火,倒入腌好的瘦肉片快速滑散,炒至变色(约1分钟)。 #### **4. 合炒调味** - 加入煸好的辣椒,与肉片翻炒均匀,加蚝油、少许盐调味(腌肉已加酱油,盐要少)。 - 沿锅边淋几滴香醋,激出香味后关火。 ------ ### **技巧总结** 1. **选材要点** - 辣椒首选螺丝椒或湖南本地椒,青椒不够辣可用小米椒补充。 - 猪肉带少许肥肉更香,纯瘦肉需加更多油防柴。 2. **火候关键** - 煸辣椒用中火逼出香气,炒肉需大火快炒锁住嫩度。 - 豆豉和蒜片是灵魂,小火爆香避免焦糊。 3. **口感升级** - 腌肉时加淀粉和油,肉片更滑嫩。 - 最后淋醋去腻增香,但量要少(吃不出酸味)。 4. **变通做法** - 加浏阳豆豉或白木耳(云耳)是湖南部分地区特色。 - 嗜辣者可加一勺剁椒同炒。 ------ 这样做出的辣椒炒肉辣而不燥,肉片裹着椒香,汤汁拌饭一绝!🌶️🔥 # 如何制作粉蒸肉 粉蒸肉是一道软糯鲜香的经典蒸菜,融合了肉的醇厚与米粉的米香,关键在于米粉的包裹和火候的控制。以下是传统做法: ------ ### **材料准备**(3-4人份) - 主料 - 带皮五花肉 500克(肥瘦相间,层次分明) - 腌肉料 - 生抽 2大勺 - 老抽 1小勺(上色) - 料酒 1大勺 - 腐乳汁 1大勺(可选,增香) - 白糖 1小勺 - 姜末 1小勺、蒜末 1小勺 - 白胡椒粉 少许 - 蒸肉粉 - 市售五香蒸肉粉 100克(或自制:大米+糯米炒黄后打碎,加八角、花椒粉混合) - 辅料 - 红薯/南瓜/土豆 200克(垫底吸油) - 清水 3-4大勺(调节米粉湿度) ------ ### **步骤详解** #### **1. 处理猪肉** - 五花肉切5毫米厚片(不宜过薄,否则易碎),用温水浸泡10分钟去血水,挤干水分。 - 加入所有腌肉料抓匀,腌制30分钟以上(隔夜更入味)。 #### **2. 裹米粉** - 将蒸肉粉分次加入腌好的肉中,每片肉均匀裹粉,若米粉太干可少量加水调节(湿度以米粉能黏住肉片,捏不成团为准)。 #### **3. 摆盘蒸制** - 蒸碗底部铺红薯块(或其他根茎类蔬菜),将裹粉的肉片皮朝下整齐码放。 - 蒸锅水烧开后放入,**大火蒸1.5-2小时**(时间越长越软糯,高压锅可缩短至40分钟)。 #### **4. 出锅翻盘** - 蒸好后倒扣在盘中,撒葱花或香菜点缀。 ------ ### **技巧总结** 1. **选肉关键** - 五花肉首选下五花(肥瘦均匀),若怕腻可加几片瘦肉混合。 - 带皮蒸制更香糯,猪皮需焯水去腥。 2. **米粉控制** - 自制米粉:大米与糯米比例2:1,干锅炒至微黄,加五香粉、辣椒粉调味。 - 米粉湿度以“捏能成团,轻碰即散”为佳,太湿易结块,太干口感粗糙。 3. **蒸制窍门** - 垫菜吸油:红薯、芋头或山药可平衡油腻,吸收肉汁后更香甜。 - 蒸锅水量要足,中途避免开盖,防止蒸汽不足导致夹生。 4. **风味变化** - 川味:加豆瓣酱或辣椒粉腌制,麻辣鲜香。 - 荷叶版:用荷叶包裹蒸制,增添清香。 ------ 这样做出的粉蒸肉米粉油润,肉质酥软不腻,入口即化,配米饭或夹馒头都超满足!🍖
使用
配置模型
需要先在 Dify 的 设置 – 模型供应商 页面内添加并配置所需要的模型。
-
百川大模型:开发者注册账户送80元使用额度
-
本地:
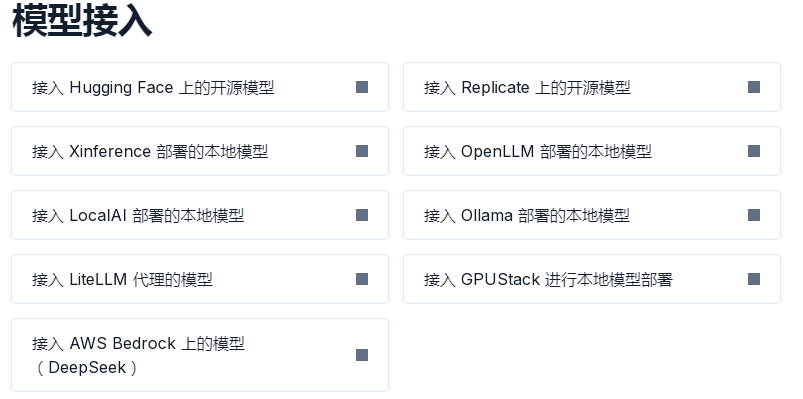
按模型的使用场景将模型分为以下 4 类:
- 系统推理模型
- Embedding 模型
- Rerank 模型:增强检索能力,改善 LLM 的搜索结果
- 语音文字转换模型
构建应用
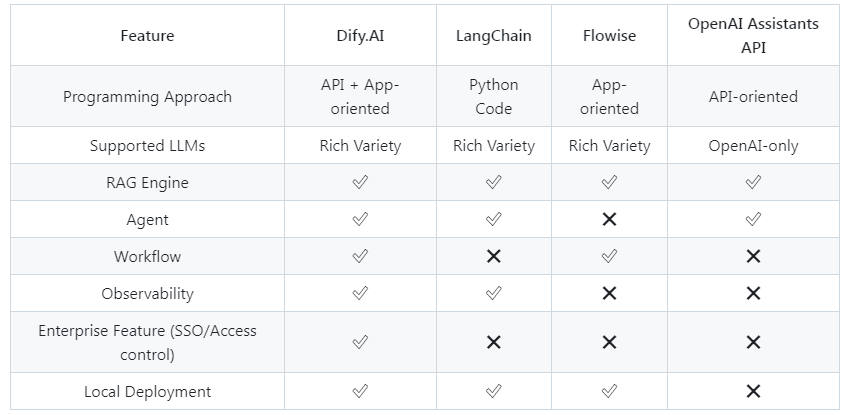
- 聊天助手:基于 LLM 构建对话式交互的助手
- 对话型应用可以用在客户服务、在线教育、医疗保健、金融服务等领域。这些应用可以帮助组织提高工作效率、减少人工成本和提供更好的用户体验。
- 文本生成应用:面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
- Agent:能够分解任务、推理思考、调用工具的对话式智能助手
- 智能助手(Agent Assistant),利用大语言模型的推理能力,能够自主对复杂的人类任务进行目标规划、任务拆解、工具调用、过程迭代,并在没有人类干预的情况下完成任务。
- 对话流(Chatflow):适用于设计复杂流程的多轮对话场景,支持记忆功能并能进行动态应用编排。
- 工作流(Workflow):适用于自动化、批处理等单轮生成类任务的场景的应用编排方式,单向生成结果。
- 工作流通过将复杂的任务分解成较小的步骤(节点)降低系统复杂度,减少了对提示词技术和模型推理能力的依赖,提高了 LLM 应用面向复杂任务的性能,提升了系统的可解释性、稳定性和容错性。
- 工作流分为两种类型:
- Chatflow:面向对话类情景,包括客户服务、语义搜索、以及其他需要在构建响应时进行多步逻辑的对话式应用程序。
- Workflow:面向自动化和批处理情景,适合高质量翻译、数据分析、内容生成、电子邮件自动化等应用程序。


















 6312
6312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











