








 该专栏为热销专栏榜 第11名
该专栏为热销专栏榜 第11名 超级会员免费看
超级会员免费看


paper: https://arxiv.org/pdf/2402.03300
目录
算法定义
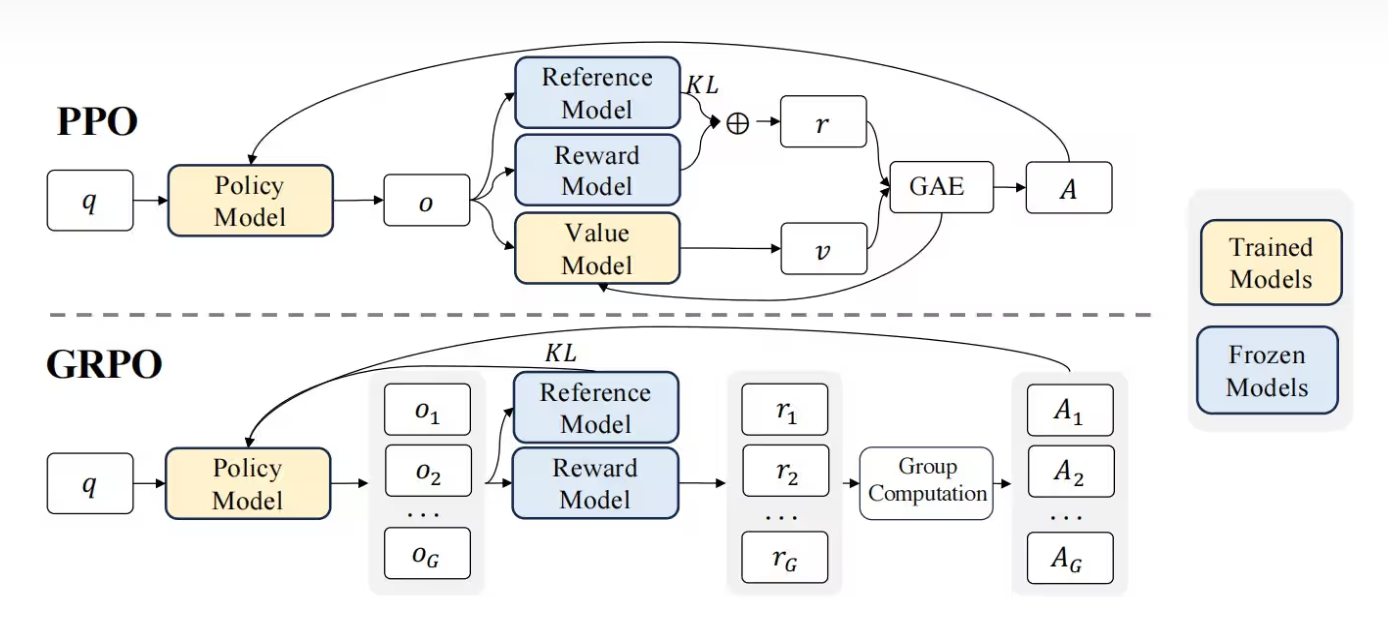
在大语言模型(LLM)的强化学习微调阶段,Group Relative Policy Optimization (GRPO)算法作为一种创新方法崭露头角。GRPO是一种在线学习算法,其核心思想是通过评估一组响应之间的相对关系来优化模型,而不是依赖外部评估者。这种方法显著提高了训练效率,特别适用于需要复杂问题解决和长链思维的推理任务。
GRPO算法的主要特点包括:
-
组抽样 :对于给定状态,使
paper: https://arxiv.org/pdf/2402.03300
目录
在大语言模型(LLM)的强化学习微调阶段,Group Relative Policy Optimization (GRPO)算法作为一种创新方法崭露头角。GRPO是一种在线学习算法,其核心思想是通过评估一组响应之间的相对关系来优化模型,而不是依赖外部评估者。这种方法显著提高了训练效率,特别适用于需要复杂问题解决和长链思维的推理任务。
GRPO算法的主要特点包括:
组抽样 :对于给定状态,使
 1119
1842
1119
1842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























