






 DiffusionDet是一个两部分的模型,包括图像编码器和检测解码器。它利用ResNet和SwinTransformer生成特征图,并通过检测解码器逐步细化边界框预测。在训练过程中,模型通过添加高斯噪声和坐标缩放模拟数据扩散。在推断时,从噪声框开始逐步去噪得到预测边界框。该方法还涉及精确的匹配策略来计算损失并优化性能,最终评估指标是mAP。
DiffusionDet是一个两部分的模型,包括图像编码器和检测解码器。它利用ResNet和SwinTransformer生成特征图,并通过检测解码器逐步细化边界框预测。在训练过程中,模型通过添加高斯噪声和坐标缩放模拟数据扩散。在推断时,从噪声框开始逐步去噪得到预测边界框。该方法还涉及精确的匹配策略来计算损失并优化性能,最终评估指标是mAP。
Architecture
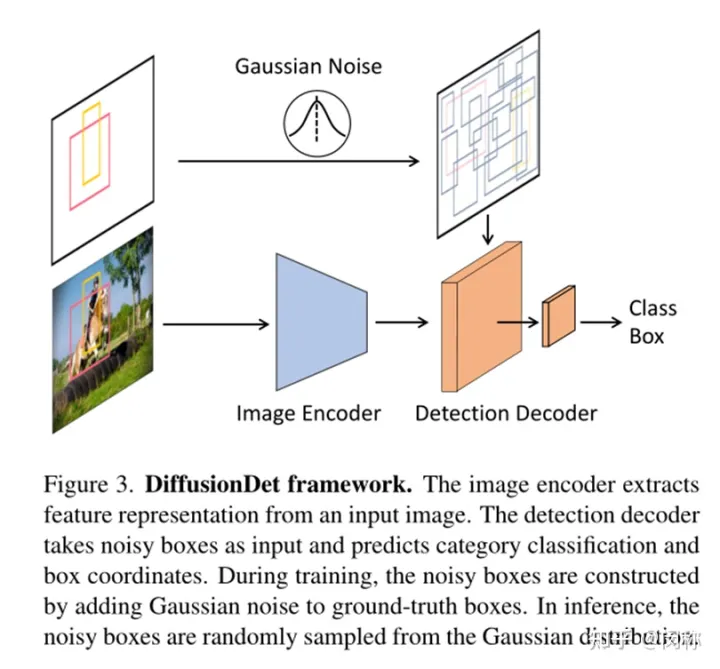
整个模型分成两个部分,即图像编码器和检测解码器,检测解码器将以深度特征作为条件,而不是原始图像,以从噪声框zt中逐步细化边界框预测。
Image encoder。图像编码器将原始图像作为输入,使用ResNet和基于Transformer的模型(如Swin)实现DiffusionDet。特征金字塔网络用于生成ResNet和Swin骨干的多尺度特征图。
Detection decoder。检测解码器将一组建议框作为输入,将特征图裁剪RoI特征,并送入检测头,以获得回归框和分类结果。检测解码器由6个级联阶段组成。
Training
将image送入backbone&neck -> 生成特征图fm -> 填充gt框为固定数量500 -> gt框加高斯噪声 -> gt框坐标缩放 -> 将N个损坏的框送入检测器(diffusion部分,singlediffusiondetHead): -> 截取ROI特征 -> self_att ()+ inst_interact() -> obj_features -> 送入回归头和分类头cls layer()® layer() -> 网络生成N个bbox reg delta和cls scores -> 处理网络输出,生成预测框&cls scores -> 循环6次,用新生成的预测框截取ROI feature -> 生成最终的500个预测框 -> 进入assing部分:-> 计算500个预测框的对于n个gt框的match_cost list(focalloss,boxL1loss,giou) -> 计算vaild_mask -> 初筛:根据vaild_mask筛选出有效预测框与gt框的match_cost_list -> 计算 2dIoU -> 精筛:Use 2DIoU and matching cost to calculate the dynamic top-k positive targets -> Use 2DIoU计算每个gt框的候选框数量dynamic top-k -> 根据matching cost筛选出dynamic top-k个预测框 -> 过滤掉gt之间的共用预测框 -> 得到500个预测框中的候选框mask以及对应的gt框索引值indices-> 计算候选框loss:-> loss_classification() -> loss_boxes():L1loss ->loss_giou()
生成建议框->送入网络:->将特征图裁剪roi特征 ->送入检测头->输出cls_scores和bbox ->计算loss
注意:
1. 由于信噪比对扩散模型的性能有显著影响,因此gt框坐标需要缩放。(我们观察到,与图像生成任务相比,目标检测倾向于相对更高的信号缩放值。)
Inference
从Gaussian采样的噪声框开始,逐步去噪到预测框。
将image送入backbone&neck -> 生成特征图fm ->Sampling step:随机采样500个噪声框noise_bboxes -> 送入检测器(diffusion部分,singlediffusiondetHead) -> 生成最终500个预测框 -> Box renewal(用新随机噪声框替换掉低iou的预测框):-> 初筛:根据cls_scores_thr过滤掉最大类别分数依然过低的框,得到过滤后的indices-> 生成新的噪声框补足500个框-> nms极大值抑制(置信度使用sigmoid(cls_scores), 去除重叠框-> 区分TP、FP:iou>thr且置信度最高的是TP,其余均为FP -> 计算mAP

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









