







易犯错误:
temp.push_back(data[rightStart]); 不是 temp.push_back(rightStart);
int nums = 56423;
int sum = 0;
while (nums != 0){
cout << nums % 10 << ' '; //3 2 4 6 5 个位逆序输出
sum = sum + nums % 10; // 取个位数求和(取余数)
nums = nums / 10; // 取个位前的数字(取除数)
}
nums % 10 //取个位
nums / 10 //取个位前
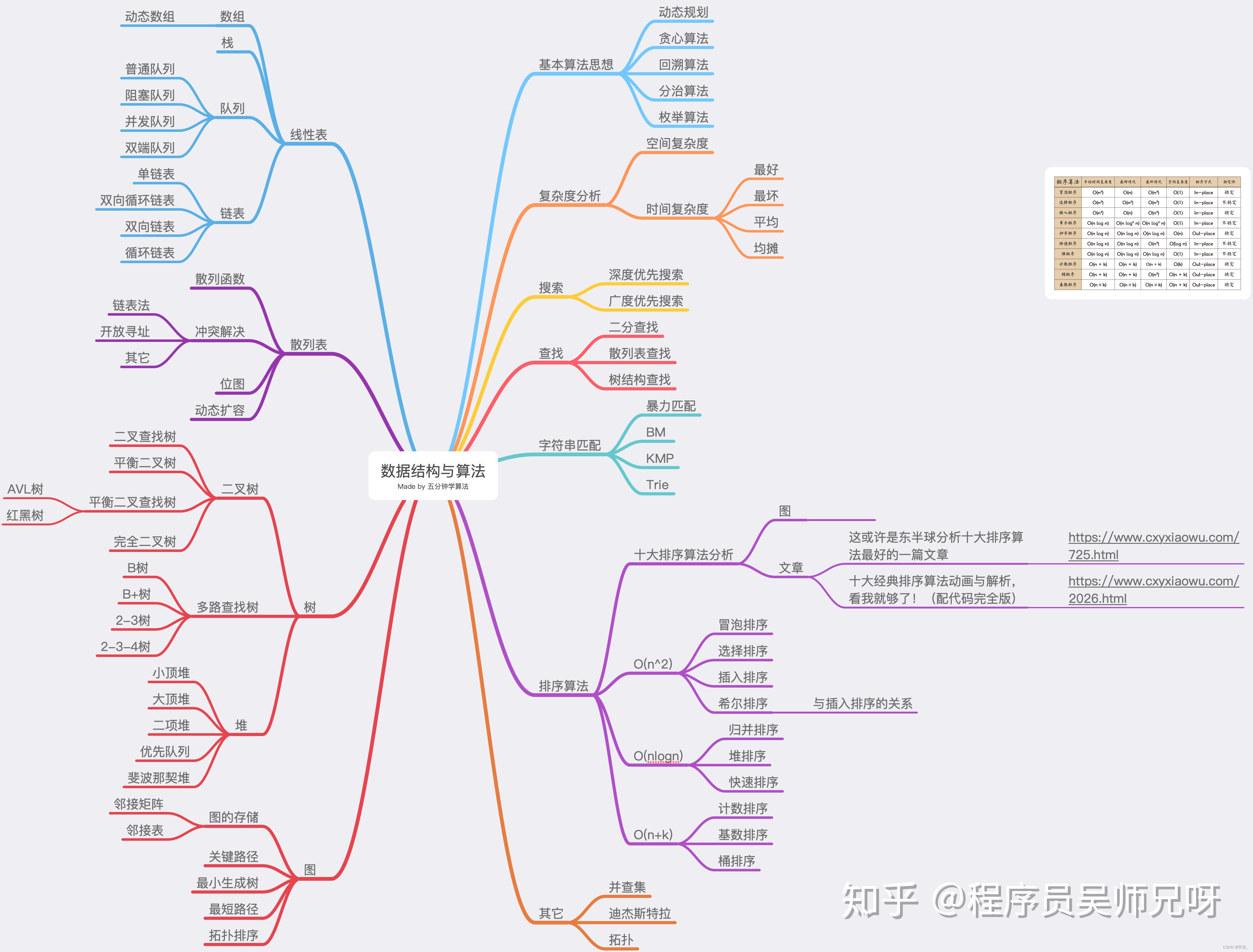
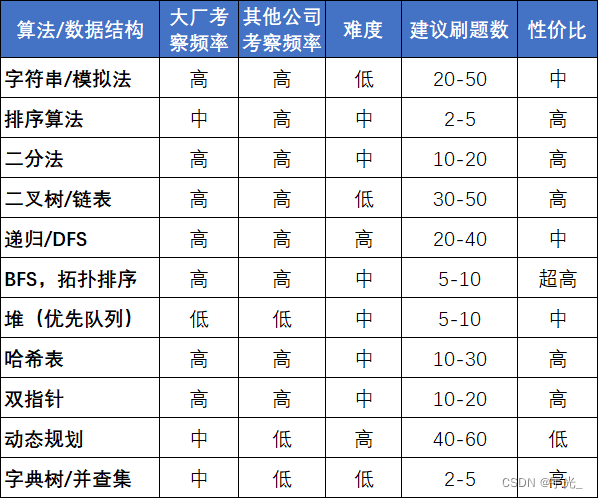
- 1、常见数据结构:链表、树(如二叉树)。(链表和二叉树是重点,图这些可以先放着)
- 2、常见算法思想:贪心法、分治法、穷举法、动态规划,回溯法。(贪心、穷举、分治是基础,动态规划有难度,可以先放着)
1. 常见概念
1.1 时间复杂度
- 常数阶O(1)
- 对数阶O(logN)
- 线性阶O(n)
- 线性对数阶O(nlogN)
- 平方阶O(n²)
- 立方阶O(n³)
- K次方阶O(n^k)
- 指数阶(2^n)
1.2 空间复杂度
- 比较常用的有:O(1)、O(n)、O(n²)
//空间复杂度 O(n)
int[] m = new int[n]
for(i=1; i<=n; ++i)
{
j = i;
j++;
}
1.3 迭代、循环和遍历的区别
- 循环(loop) - 最基础的概念, 所有重复的行为
- 递归(recursion) - 在函数内调用自身, 将复杂情况逐步转化为基本情况
- (数学)迭代(iterate) - 在多次循环中逐步接近结果
- (编程)迭代(iterate) - 按顺序访问线性结构中的每一项
- 遍历(traversal) - 按规则访问非线性结构中的每一项
2. 哈希表(Hash Table)
- unordered_set
- unordered_multiset
- unordered_map
- unordered_multimap
- unordered_map (或者 unordered_set )省去了排序的过程,如果偶尔刷题时候 map 或者 set 超时了,可以考虑 unordered_map (或者 unordered_set )缩短代码运行时间、提升代码效率
//哈希查找
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> hash_map;
for(int i=0; i<nums.size(); i++) {
//查找key是否存在,若存在,返回该键的元素的迭代器;
//若不存在,返回m.end();
auto it = hash_map.find(target-nums[i]);
//unordered_map<int,int>::iterator it = hash_map.find(target-nums[i]);
if(it != hash_map.end()) {
return{it->second,i};
}
hash_map[nums[i]]=i; //构建哈希映射表,键值key和实值value对应,
}
return{};
}
};
复杂链表的复制
描述
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针random指向一个随机节点),请对此链表进行深拷贝,并返回拷贝后的头结点。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)。
//复杂链表的复制,请对此链表进行深拷贝,并返回拷贝后的头结点。
//struct RandomListNode {
// int val;
// struct RandomListNode *next, *random;
// RandomListNode(int x) :
// val(x), next(NULL), random(NULL) {
// }
//};
//构建哈希表,迭代解法
RandomListNode* Clone(RandomListNode* pHead)
{
if (pHead == nullptr) return nullptr;
std::unordered_map<RandomListNode*, RandomListNode*> hash_map;
// 若用 while(pHead != nullptr){pHead = pHead->next;},由于pHead非局部变量,会导致pHead变化
for (RandomListNode* p = pHead; p != nullptr; p = p->next) //p相当于i,对复杂链表遍历
{
// 有参构造的初始化,指针均为空
hash_map[p] = new RandomListNode(p->val); //构建哈希映射表,深拷贝重新复制开辟到堆区,p->val初始化
}
for (RandomListNode* p = pHead; p != nullptr; p = p->next)
{
hash_map[p]->next = hash_map[p->next]; //把拷贝后的链表链接起来
hash_map[p]->random = hash_map[p->random];//在哈希表中random指向的地址也收录了
}
return hash_map[pHead];
}
//递归解法
//关键是保存住映射关系,可以说是哈希表和链表的组合吧
unordered_map<RandomListNode*,RandomListNode*> hash_map;
RandomListNode* Clone(RandomListNode* pHead)
{
if(pHead == nullptr) return nullptr;
// 有参构造的初始化
RandomListNode* newHead = new RandomListNode(pHead->val);
hash_map[pHead] = newHead; //这里需要保存的是 pHead -> newHead 的映射关系,必须在这里保存
newHead->next = Clone(pHead->next);//到这一步,其实所有的点已经全部生成了
newHead->random = nullptr;//其实默认已经是nullptr了,有没有这一步其实没什么关系
if(pHead->random != nullptr) newHead->random = hash_map[pHead->random];//这一步,真的是灵魂所在了
return newHead;
}
删除链表的重复节点
描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
// 哈希解法
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead) {
if(pHead == nullptr) return nullptr;
vector<ListNode*> vec; //记录新链表
unordered_map<int, int> hash;
// 由于pHead非局部变量,会导致其变化
//while(pHead != nullptr) {
//hash[pHead->val]++;
//pHead = pHead->next;
//}
for(ListNode* p = pHead; p != nullptr; p = p->next) {
hash[p->val]++;
}
// 由于已排序,重复节点一定是连续重复的
ListNode* newHead;
for(ListNode* p = pHead; p != nullptr; p = p->next) {
if(hash[p->val] == 1){
// 进行深拷贝复制节点(next为空),浅拷贝会导致(next指向下一节点)
newHead = new ListNode(p->val);
vec.push_back(newHead);
}
}
if(vec.size() == 0) return nullptr;
if(vec.size() == 1) return vec[0];
for(int i = 0; i < vec.size()-1; ++i) { //数组两个以上元素的情况
// 链接两个链表节点,最后一个节点会带有之间的节点,故1.拷贝节点来杜绝 2.或最后节点置为空
vec[i]->next = vec[i+1];
}
//vec[vec.size() - 1]->next = nullptr; //2.或最后节点置为空
return vec[0];
}
};
2. 二叉树
2.1 二叉树的基本概念
- 父节点、子节点:如果一个节点下面连接多个节点,那么该节点称为父节点,它下面的节点称为子节点。
- 叶子节点:没有任何子节点的节点称为叶子节点。
- 兄弟节点:具有相同父节点的节点互称为兄弟节点。
- 节点度:节点拥有的子树个数。
- 树的度:所有结点的度数的最大值。二叉树的度<=2。
- 树的深度/高度:树中结点的最大层次数称为树的深度或高度。(树的深度和高度一样,不是节点的深度和高度)
- 二叉树深度定义:从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的节点个数为树的深度(等于层数)
- 满二叉树:各层都是满的
- 完全二叉树:除了最后一层,其余各层都是满的,并且最后一层的节点集中在左边
- 二叉排序树(二叉搜索树、二叉查找树)BST:可以为空树,若它的左子树不空,则左子树上的所有结点的值均小于根节点的值;若它的右子树不空,则右子树上的所有结点的值均大于根节点的值,左右子树分别为二叉排序树。
- 平衡二叉树AVL:是二叉查找树的一个进化体,又被称为AVL树,它是一颗空树或左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
- 红黑树RB-Tree:是一种平衡二叉查找树的变体,它的左右子树高差有可能大于1,所以红黑树不是严格意义上的平衡二叉树(AVL),其平均统计性能要强于 AVL树
通常堆(完全二叉树)是通过一维数组来实现的。在数组起始位置为0的情形中,父结点和子结点的位置关系如下:
1.索引为i的左孩子的索引是 (2* i+1)
2.索引为i的右孩子的索引是 (2* i+2)
3.索引为i的父结点的索引是 (i -1)/2
(若len = vec.size()不是下标,而是元素大小,则(len-1-1)/2 = len/2 - 1
2.2 四种基本的遍历思想
- 前序遍历:根结点 —> 左子树 —> 右子树(根左右)
- 中序遍历:左子树 —> 根结点 —> 右子树(左根右)
- 后序遍历:左子树 —> 右子树 —> 根结点(左右根)
- 层次遍历:仅仅需按层次遍历就可以
- 前序遍历:1 2 4 5 7 8 3 6
- 中序遍历:4 2 7 5 8 1 3 6
- 后序遍历:4 7 8 5 2 6 3 1
- 层次遍历:1 2 3 4 5 6 7 8
- 遍历的实现方式主要是:递归和非递归
- 递归遍历的实现非常容易,非递归的实现需要用到栈,难度系数要高一点
- 根是相对的,对于整棵树而言只有一个根,但对于每棵子树而言,又有自己的根
//二叉树节点的定义
class TreeNode{
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
}
TreeNode* node; node->val = 1;
TreeNode node(1); //开辟到栈区
TreeNode* node = new TreeNode(1); //开辟到堆区
2.3 前序遍历(迭代:dfs,辅助栈)
// 递归解法,不重新构造函数
class Solution {
public:
vector<int> vec;
vector<int> preorderTraversal(TreeNode* root) {
if(root == nullptr) return vec;
vec.push_back(root->val);
preorderTraversal(root->left); //不需要返回
preorderTraversal(root->right);
return vec;
}
};
// 递归解法,重新构造函数
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> vec;
preorder(root,vec);
return vec;
}
void preorder(TreeNode* root, vector<int> &vec){
if(root==nullptr){
return;
}
vec.push_back(root->val);
preorder(root->left,vec);
preorder(root->right,vec);
}
};
// dfs,借助辅助栈
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
// 迭代解法,dfs
vector<int> vec;
if(root == nullptr) return vec;
stack<TreeNode*> s; //辅助栈
s.push(root);
while(!s.empty()) {
root = s.top();
vec.push_back(root->val);
s.pop();
if(root->right != nullptr) s.push(root->right);
if(root->left != nullptr) s.push(root->left);
}
return vec;
}
};
2.4 中序遍历(迭代: dfs,辅助栈)
// 中序遍历
// 递归解法
class Solution {
public:
vector<int> vec;
vector<int> inorderTraversal(TreeNode* root) {
if(root == nullptr) return vec;
inorderTraversal(root->left); //无返回
vec.push_back(root->val);
inorderTraversal(root->right);
return vec;
}
};
// 构造函数,递归
vector<int> inorderTraversal(TreeNode* root) {
vector<int> vec;
inorder(root, vec);
return vec;
}
void inorder(TreeNode* root, vector<int> &vec) { //传值是本身的拷贝
if(root == nullptr) return;
inorder(root->left, vec);
vec.push_back(root->val);
inorder(root->right, vec);
}
// 迭代 dfs
vector<int> inorderTraversal(TreeNode* root) {
// 借助辅助栈
stack<TreeNode*> s; // 只能存储指针,这样才能找到上一级的根节点
vector<int> vec;
while(root != nullptr || !s.empty()) { //只要有一个1就是1
while(root != nullptr) {
s.push(root);
root = root->left;
}
root = s.top(); //返回上一级的根节点
vec.push_back(root->val);
s.pop();
root = root->right;
}
return vec;
}
2.5 后序遍历(迭代跟前序遍历类似)
//递归解法
class Solution {
public:
vector<int> vec;
vector<int> postorderTraversal(TreeNode* root) {
if(root == nullptr) return vec;
postorderTraversal(root->left);
postorderTraversal(root->right);
vec.push_back(root->val);
return vec;
}
};
//递归解法,构建函数
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> vec;
postorder(root,vec);
return vec;
}
void postorder(TreeNode* root, vector<int> &vec){
if(root == nullptr){return;}
postorder(root->left, vec);
postorder(root->right, vec);
vec.push_back(root->val);
}
};
//迭代,与前序遍历类似
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
vector<int> vec;
if(root == nullptr) return vec;
stack<TreeNode*> s; //借助辅助栈
s.push(root);
while(!s.empty()) {
root = s.top();
vec.push_back(root->val);
s.pop();
if(root->left != nullptr) s.push(root->left);
if(root->right != nullptr) s.push(root->right); //根右左
}
reverse(vec.begin(), vec.end()); //反转,变为左右根
return vec;
}
};
2.6 层序遍历(bfs,辅助队列,重点记忆,细节太多)
// 层序遍历,bfs解法
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>> res;
if(root == nullptr) return res; //边界条件
queue<TreeNode*> q; //构造辅助队列,利用先进先出的特性
q.push(root);
while(!q.empty()){
vector<int> vec;
// 遍历队列,采用取头部数据的方式
int len = q.size(); //必须存起来,size是动态变化的
for(int i = 0; i < len; ++i) {
root = q.front(); //很重要,调整root指针的指向
vec.push_back(root->val);
q.pop();
//每遍历一个节点就插入左右节点到队列中
if(root->left != nullptr) q.push(root->left);
if(root->right != nullptr) q.push(root->right);
}
res.push_back(vec); //插入数组
}
return res;
}
};
2.7 平衡二叉树(两重递归解法)
//是否为平衡二叉树
int highCalculate(TreeNode* pRoot) {
if(pRoot == nullptr) return 0;
int leftHigh = highCalculate(pRoot->left);
int rightHigh = highCalculate(pRoot->right);
return 1+max(leftHigh, rightHigh);
}
bool IsBalanced_Solution(TreeNode* pRoot) {
if(pRoot == nullptr) return true; //空树也是平衡二叉树
bool leftBalanced = IsBalanced_Solution(pRoot->left);
bool rightBalanced = IsBalanced_Solution(pRoot->right);
if(leftBalanced && rightBalanced &&
abs(highCalculate(pRoot->left) - highCalculate(pRoot->right)) <= 1)
return true;
else
return false;
}
3. 链表
- 头指针:顾名思义是一个指针,指向链表的开始地址;(是链表必需的)
- 头结点:第一个节点,该节点只有地址信息,改地址指向下一个结点,数据域无信息;(不是链表所必需的)
- 首元结点:含第一个元素的结点,为链表的实际开始位置,数据域包含第一个数据信息,指针指向下一个结点。
作用:
- 头指针:头指针就是链表的名字,头指针具有标识作用。头指针仅仅是个指针而已。无论链表是否为空,头指针均不为空。但是头指针为空,链表肯定为空
- 头结点:有了头结点后,对在第一个元素结点前插入结点和删除第一个结点,其操作与对其它结点的操作统一了。
- 不带头结点的单链表对于第一个节点的操作与其他节点不一样,需要特殊处理,这增加了程序的复杂性和出现bug的机会,因此,通常在单链表的开始结点之前附设一个头结点。
- 带头结点的单链表,初始时一定返回的是指向头结点的地址,所以一定要用二维指针,否则将导致内存访问失败或异常。
- 带头结点与不带头结点初始化、插入、删除、输出操作都不一样,在遍历输出链表数据时,带头结点的判断条件是while(head->next!=NULL),而不带头结点是while(head!=NULL),虽然头指针可以在初始时设定,但是如1所述,对于特殊情况如只有一个节点会出现问题。
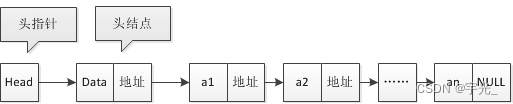
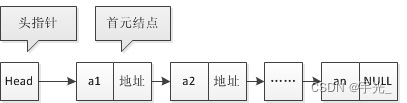
3.1 单向链表
- 单向链表(单链表)是链表的一种,它由节点组成,每个节点都包含下一个节点的指针,下图就是一个单链表,头节点为空(有时候头节点不一定为空)
单链表删除节点
单链表添加节点
3.2 双向循环链表
- 双向链表(双链表)是链表的一种。和单链表一样,双链表也是由节点组成,它的每个数据结点中都有两个指针,分别指向直接后继(节点的右侧 next)和直接前驱(节点的左侧 pre)。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
双向链表删除节点
//删除节点pindex
pindex->next->prev = pindex->prev;
pindex->prev->next = pindex->next;
free(pindex); //注意释放节点
双向链表添加节点
//将pnode节点插入到pindex之前
pnode->prev = pindex->prev;
pnode->next = pindex;
pindex->prev->next = pnode;
pindex->prev = pnode;
4. 数组(二维数组)
4.1 数组插入值
vector<int> B(len, 0);
B[i] = tempA; //如果没有开辟数组空间,不能【】来插入数值
vector<int> B;
B.push_back(tempA);
4.2 数组初始化
vector<vector<bool>> dp(m, vector<bool>(n, false)); // m X n
vector<int>({array[ret.first], array[ret.second]}); // 匿名对象初始化,初始化两个值
1.vector二维数组的创建和初始化
vector <int> vec(10,90); //将10个一维动态数组初始为90
vector<vector<int>> vec(row,vector<int>(col,0));
//初始化row * col二维动态数组,初始化值为0
vector<vector<int>> vec(3,vector<int>(4,0)); //代表三行四列
0 0 0 0
0 0 0 0
0 0 0 0
2.获取一维数组的长度
int size = vec.size();
3.获取二维数组的长度
int size_row = vec.size(); //获取行数row
int size_col = vec[0].size(); //获取列数col
4.给vector二维数组赋值
简单的就直接赋值
ans[0][0]=1;
ans[0][1]=2;
ans[1][0]=3;
ans[1][1]=4;
5. 字符串(char*和string)
// 数字字符限定为 0-9
//一、char 转 int
char c = '0';
int i3 = c - '0'; // 0
//int i1 = c; // 48
//int i2 = c - 0; // 48
//int i4 = c + '0'; // 96
//二、int 转 char
int i = 5;
char c4 = i + '0'; // 5
//char c1 = i; // 越界
//char c2 = i - 0; // 越界
//char c3 = i - '0'; // 越界
注意:
cout << 'test'; // Note the single quotes.
//给我的输出1952805748.
通常,这是四个字符合并的ASCII值。
't' == 0x74; 'e' == 0x65; 's' == 0x73; 't' == 0x74;
所以0x74657374是1952805748。
5.1 字符串长度获取
- 用string的成员方法length()获取字符串长度,length()比较直观,表示的就是该字符串的长度。
string str="abc";
len = str.length()
//结果为3
- 用string的成员方法size()获取字符串长度,size()表示的是string这个容器中的元素个数。那么size()表示的就是这个vector(容器)中char的个数。
string str="abc";
len = str.size();
//结果为3
- 用strlen获取字符串长度。strlen同样也可以用于C++的string。但是需要用str.c_str()将C++ string转换为char*类型。
string str = "abc";
const char* c = str.c_str(); //常量指针是指针(指向可改,值不可改)
char* c = (char*)str.c_str();
const char* c = str.data();
int len = strlen(c);
5.2 C++ 中 string和char* 的区别
- char*:char *是一个指针,可以指向一个字符串数组,至于这个数组可以在栈上分配,也可以在堆上分配,堆得话就要你手动释放了。
//vs版本兼容性问题,新版本vs2017,2019都会遇到这个问题,新版本vs对此有更严格的要求
const char* s1 = "str111";
1.char* s1 = "str111"; //内容是不可以改的(vs2019报错)
s1++; *s1; //可以用移动指针的方式来访问
2.char s2[] = "string"; //内容是可以改的
s2[0] = 'j';
for (int i = 0; s2[i] != '\0'; ++i) {
cout << s2[i];
}
3.char* p = new char[10]; //开辟到堆区
5.2.1 string转char*
- 有如下三种方法实现类型转换,分别是:c_str(); data(); copy();
//1. c_str()方法
//注意:若不添加const,会报错invalid conversion from const char* to char *。char*要开辟新的空间,可以加上const或强制转化成char*。
string str=“world”;
const char *c = str.c_str(); //加const或等号右边用char* //常量指针是指针(指向可改,值不可改)
char *p = (char*)str.c_str(); p[0] = 'a'; //内容是可以改的
//c的值不可改
//2. data()方法
string str = "hello";
const char* p = str.data();//加const或等号右边用char*
char * p=(char*)str.data();
//3.copy()方法
string str="qweqwe";
char data[30];
str.copy(data, 3, 0);//0表示复制开始的位置,3代表复制的字符个数
5.2.2 char * 转string
//直接赋值
string s;
char *p = "hello";
s = p;
注意:
- 当我们定义了一个string,就不能用scanf(“%s”,s)和printf(“%s”,s)输入输出。主要是因为%s要求后面是对象的首地址
5.3 C 字符串函数
strcpy(str1,str2);//将str2里面的字符串复制到str1数组中
5.4 string和int的相互转换
一、int转换成string
//c++11标准增加了全局函数std::to_string:
string to_string (int val);
string to_string (long val);
string to_string (long long val);
string to_string (unsigned val);
string to_string (unsigned long val);
string to_string (unsigned long long val);
string to_string (float val);
string to_string (double val);
string to_string (long double val);
二、string转换成int
int stoi (string str);
float stof(string str);
long stol(string str);
long long stoll(string str);
// 1.atoi是 C 语言的库函数,atoi()不会做范围检查,如果超出范围的话,超出上界,则输出上界,超出下界,则输出下界;
// 2.stoi()会做范围检查,默认范围是在int的范围内的,如果超出范围的话则会runtime error!
stoi();//函数原型 int atoi(const string& str);
atoi();//函数原型 int atoi(const char* str);
atof();//浮点型
atol();//long型
#include<cstring> // 头文件
string s1("1234567");
char* s2 = "1234567";
char s3[] = "123";
int a = stoi(s1); //string
int a1 = stoi(s2); // char*
int b = atoi(s2);
int c = atoi(s1.c_str()); //string
int d = atoi(s3);
注意事项:
//1. 在字符串尾插一个'A'字符,参数必须是字符形式
str1.puch_back ('A');
//2. vector<string> 不能拷贝到 string
vector<string> v = {"aa","bb"};
string a(v.begin(), v.end()); //报错,不能区间拷贝
6. 栈、队列
// 判断栈不为空很重要,防止栈溢出(s.top()溢出)
7. 堆
完全二叉树:除了最后一层,其余各层都是满的,并且最后一层的节点集中在左边
7.1 堆的特点
- 将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等
- 大部分时间我们是使用完全二叉树来存储堆的,但是堆并不等于完全二叉树,例如二项堆,斐波那契堆,就不属于二叉树
- 一般的操作进行一次的时间复杂度在O(1)~O(logn)之间
- 注意:堆的根节点中存放的是最大或者最小元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0 的位置,但是最小的元素则未必是最后一个元素。唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
7.2 堆的使用情况
- 构建优先队列
- 支持堆排序
- 快速找出一个集合中的最小值(或者最大值)
通常堆(完全二叉树)是通过一维数组来实现的。在数组起始位置为0的情形中,父结点和子结点的位置关系如下:
(1)索引为i的左孩子的索引是 (2* i+1)
(2)索引为i的右孩子的索引是 (2* i+2)
(3)索引为i的父结点的索引是 (i -1)/2
(若len = vec.size()不是下标,而是元素大小,则(len-1-1)/2 = len/2 - 1
注意:这里得到的关系由数组的起始位置来决定。
因此,在第一个元素的索引为0时:
对于大顶堆有:arr(i)>arr(2* i+1) && arr(i)>arr(2* i+2)
对于小顶堆有:arr(i)<arr(2* i+1) && arr(i)<arr(2* i+2)
7.3 优先队列
- STL 中的 priority_queue 其实就是一个大根堆(默认大顶堆)
#include <queue> //要包含头文件
#include<functional> // 涉及到仿函数,要包含内建的仿函数
优先队列具有队列的所有特性,包括基本操作:
//top 访问队头元素 (普通 queue 为 front())
//empty 队列是否为空
//size 返回队列内元素个数
//push 插入元素到队尾 (并排序)
//emplace 原地构造一个元素并插入队列
//pop 弹出队头元素
//swap 交换内容
//小顶堆 (开头是小) (与 set 和 sort 相反)
priority_queue <int,vector<int>,greater<int> > q; //greater和less是std实现的两个仿函数
//大顶堆(开头是大)
priority_queue <int,vector<int>,less<int> >q;
//默认是大顶堆,直接输入元素则使用默认容器和比较函数
priority_queue<int> a;
//等价 priority_queue<int, vector<int>, less<int> > a;
与往常的初始化不同,优先队列的初始化涉及到一组而外的变量,这里解释一下初始化:
- T就是Type为数据类型
- Container是容器类型,(Container必须是用数组实现的容器,比如vector,deque等等,但不能用 list。STL里面默认用的是vector)
- Compare是比较方法,类似于sort第三个参数那样的比较方式,对于自定义类型,需要我们手动进行比较运算符的重载。与sort直接Bool一个函数来进行比较的简单方法不同,Compare需要使用结构体的运算符重载完成,直接bool cmp(int a,int b){ return a>b; } 这么写是无法通过编译的。
struct cmp
{ //这个比较要用结构体表示
bool operator()(int &a, int &b) const
{
return a > b; //小顶堆
}
};
priority_queue<int,vector<int>,cmp> q; //使用自定义比较方法
priority_queue<int> pq;
// pair类型
priority_queue<pair<int, int> > a;
pair<int, int> b(1, 2);
pair<int, int> c(1, 3);
pair<int, int> d(2, 5);
a.push(d);
a.push(c);
a.push(b);
// 自定义数据类型
struct tmp2 //重写仿函数
{
bool operator() (tmp1 a, tmp1 b)
{
return a.x < b.x; //大顶堆
}
};
最小的K个数
29 最小的K个数
// 优先队列priority_queue
class Solution {
public:
vector<int> GetLeastNumbers_Solution(vector<int> input, int k) {
vector<int> vec;
if(k == 0 || k > input.size()) return vec;
// 构建优先队列
priority_queue<int, vector<int>, greater<int> > pq; //默认大顶堆,换成小顶堆
for(int i = 0; i < input.size(); ++i) {
pq.push(input[i]);
}
while(k--){
vec.push_back(pq.top());
pq.pop();
}
return vec;
}
};
8. 图论
- 图是用来对对象之间的成对关系建模的数学结构,由"节点"或"顶点"(Vertex)以及连接这些顶点的"边"(Edge)组成。
- 图的顶点集合不能为空,但边的集合可以为空。图可能是无向的,这意味着图中的边在连接顶点时无需区分方向。否则,称图是有向的。
- 图的分类:无权图和有权图,连接节点与节点的边是否有数值与之对应,有的话就是有权图,否则就是无权图。

















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











