






import tensorflow as tf
import random
#训练函数y=2x-1,a/b分别要训练为2,-1
x=tf.placeholder(tf.float32,[1])
a=tf.Variable(tf.constant([1],dtype=tf.float32))
#b=tf.Variable(tf.constant([1],dtype=tf.float32))
y=a*x#+b
#
_y=tf.placeholder(tf.float32,[1])
loss=tf.square(y-_y)
train=tf.train.GradientDescentOptimizer(1e-4).minimize(loss)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
while True:
input=[random.randint(0,100)] #不乘以0.0001,则网络无法收敛
label=[input[0]*2]
print(input)
print(label)
_,av,bv,lossv=sess.run([train,a,a,loss],feed_dict={x:input,_y:label})
if (lossv<1e-6):
break
print("a=%s b=%s loss=%s" %(av,bv,lossv)) 以上网络训练参数a,使其满足y=a*x=2*x。
以下两个条件成立时,网络会无法收敛,且参数迅速扩大直至变成NaN:
input/label值过大:如0~100
学习率较大,如0.1。
分析如下:
loss对a的函数为二次函数,Loss对a的导数为一次函数,导数大小取决输入数据x/y的大小,
当学习率太高/输入数据太大,会导致导数非常大,直接跳到二次函数对称轴另一边,如下图:
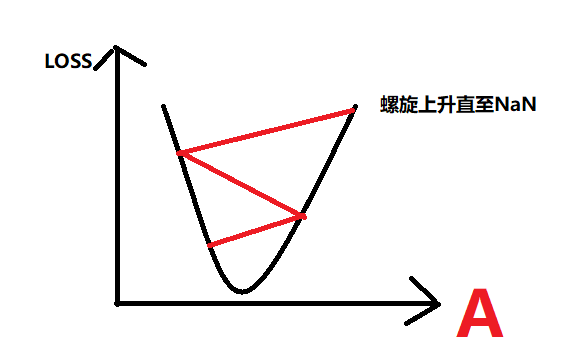
如何解决这个问题:
BN应该可以很大程度上解决这个问题;
其他的就是改小学习率。。。凭经验。。
learning rate 减小10倍有时候意味网络训练非常慢。















 3189
3189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









