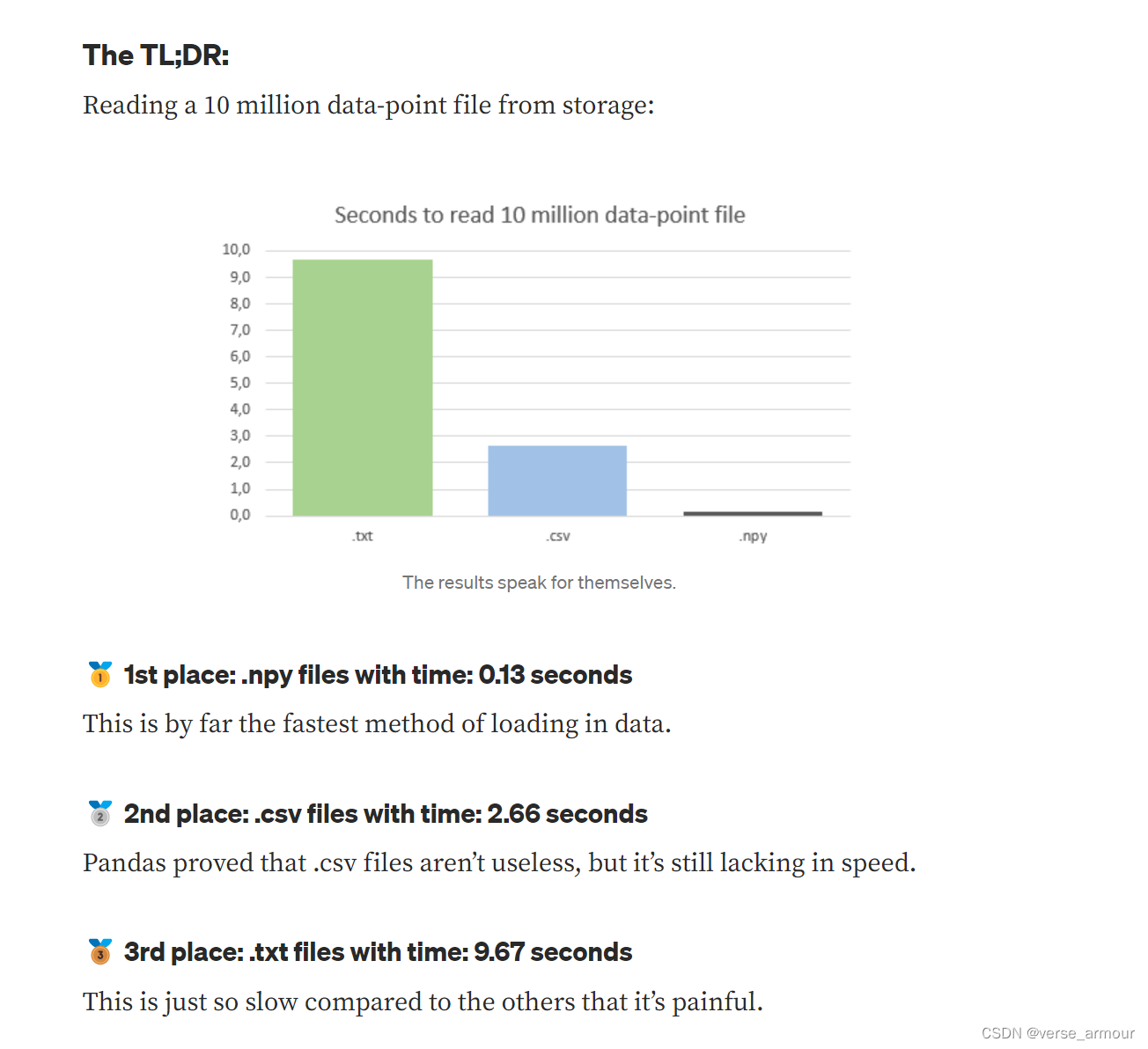
A LOT faster, also notice that we didn’t need to reshape the data since that information was contained in the .npy file.(速度更快)
Another “minor” feature of using .npy files is the reduced storage the file occupies. In this case it’s more than a 50% reduction in size. This can wary a lot though but in general the .npy files are more storage friendly.(占用内存更少)
四、读取和保存
(1)加载npy文件,并将npy文件写入一个txt文件
import numpy as np
test=np.load('./bvlc_alexnet.npy',encoding ="latin1")#加载文件
doc =open('1.txt','a')#打开一个存储文件,并依次写入print(test,file=doc)#将打印内容写入文件中
(2)保存npy文件
#显示字典print(train_dataset.class_to_idx)
idx_to_labels ={y:x for x,y in train_dataset.class_to_idx.items()}#获取dict:train_dataset.class_to_idx的keys和valuesprint(idx_to_labels)
np.save('idx_to_labels.npy',idx_to_labels)
np.save('labels_to index.npy',train_dataset.class_to_idx)
(3)结构解析
import numpy as np
from numpy import*#使用numpy的属性且不需要在前面加上numpyimport tensorflow as tf
#模型文件(.npy)部分内容如下:由一个字典组成,字典中的每一个键对应一层网络模型参数。(包括权重w和偏置b)
a ={'conv1':[array([[1,2],[3,4]],dtype=float32),array([5,6],dtype=float32)],'conv2':[array([[1,2],[3,4]],dtype=float32),array([5,6],dtype=float32)]}
conv1_w = a['conv1'][0]
conv1_b = a['conv1'][1]
conv2_w = a['conv2'][0]
conv2_b = a['conv2'][1]print(conv1_w)print(tf.Variable(conv1_w))print(conv1_b)print(tf.Variable(conv1_b))


























 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











