







基于anaconda的yolov5安装教程
下载所需文件
从以下方法下载yolov5
https://github.com/ultralytics/yolov5
或者我的百度网盘(非最新)
链接:https://pan.baidu.com/s/1g4ddiSrw0UMLiavvTTD2Wg
提取码:zqze
在anaconda中配置环境
创建环境存放文件夹
conda create -n yolov5 python=3.7
conda activate yolov5

登录pytorch的官网 https://pytorch.org/get-started/locally/,根据自己的环境,进行选择,网站会给出相应的安装命令。我这里的环境是linux、pip、cuda 10.1
(查看cuda版本号nvcc -V)

显然这张图中并没有我所需要的版本,那么就点击红色的install previous versions of PyTorch,或者打开网址https://pytorch.org/get-started/previous-versions/自行寻找对应的版本安装
*
注意:是在conda activate yolov5后输入指令,即处于yolov5环境
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html`
或者
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=10.1 -c pytorch
为了成功安装,我采用了pip安装,并且在后面加了-i https://pypi.douban.com/simple/
下图为cuda10.1的安装pytorch
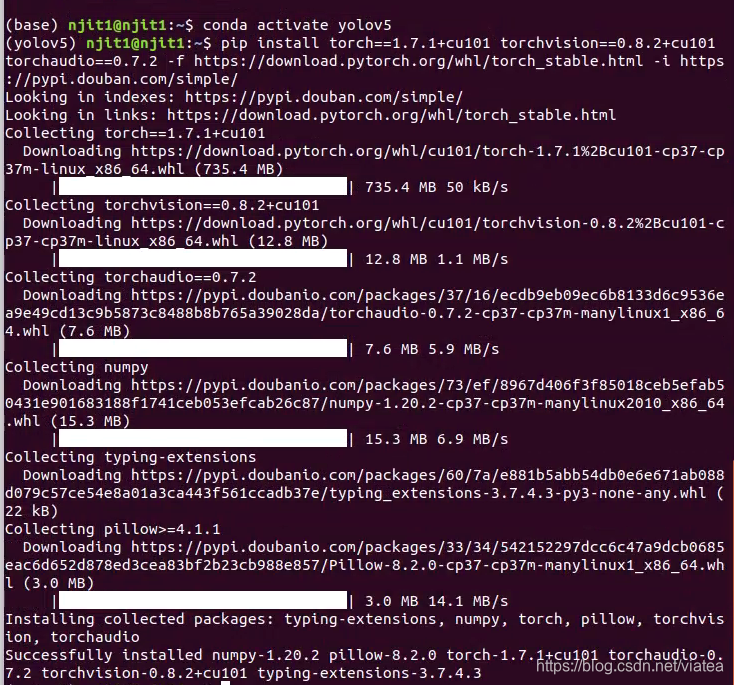
安装成功后,继续
pip install ipython
安装完pytorch后,我们在ipython中查看安装的结果
$ ipython
Python 3.7.10 (default, Feb 26 2021, 18:47:35)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.22.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import torch
In [2]: torch.cuda.is_available()
Out[2]: True
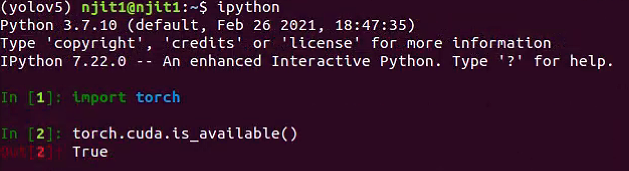
键入exit()推出ipython
此时,说明GPU版本的pytorch安装成功
安装yolov5
进入刚刚解压的yolov5文件夹
cd yolov5-4.0/
安装yolov5所需环境
pip install -U -r requirements.txt

运行python detect.py,默认情况下,脚本会去读取inference/images下的所有图片并进行目标检测,带有目标框的结果图片保存在inference/out下。
训练
准备数据集,与yolov4一样,.jpg与.txt放在一个文件夹中
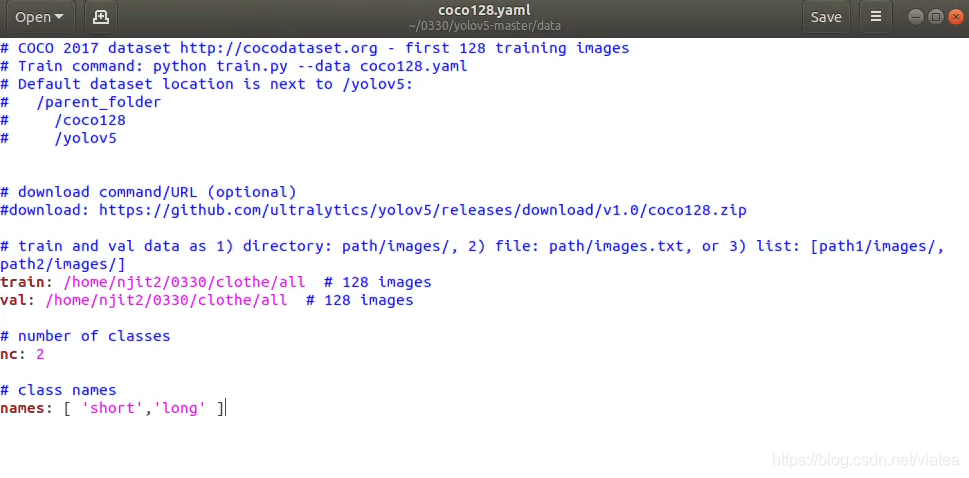
*1.*修改/data/中的coco128.yaml,将第十行注释即#download: https://github.com/ultralytics/yolov5/releases/download/v1.0/coco128.zip,
修改以下两个部分:
#number of classes
nc:
#class names
names:
train:
val:
路径最好为绝对路径,工程应用中将测试集与训练集为同一文件,保证样本足够
*2.*修改models中的.yaml文件,根据需求进行选取,只需修改第二行的nc: 2 #number of classes
3.
python train.py --img 480 --batch 32 --epochs 400 --data ./data/coco128.yaml --cfg ./models/yolov5s.yaml --weights ./weights/yolov5s.pt --device 0,1
--epochs:训练的epoch,默认值300
--batch-size:默认值16
--cfg:模型的配置文件,默认为yolov5s.yaml
--data:数据集的配置文件,默认为data/coco128.yaml
--img-size:训练和测试输入大小,默认为[640, 640]
--rect:rectangular training,布尔值
--resume:是否从最新的last.pt中恢复训练,布尔值
--nosave:仅仅保存最后的checkpoint,布尔值
--notest:仅仅在最后的epoch上测试,布尔值
--evolve:进化超参数(evolve hyperparameters),布尔值
--bucket:gsutil bucket,默认值''
--cache-images:缓存图片可以更快的开始训练,布尔值
--weights:初始化参数路径,默认值''
--name:如果提供,将results.txt重命名为results_name.txt
--device:cuda设备,例如:0或0,1,2,3或cpu,默认''
--adam:使用adam优化器,布尔值
--multi-scale:改变图片尺寸img-size +/0- 50%,布尔值
--single-cls:训练单个类别的数据集,布尔值
多 GPU分布式数据并行模式
必须通过python -m torch.distributed.launch --nproc_per_node,然后是通常的参数。
python -m torch.distributed.launch --nproc_per_node 3 train.py --batch 96 --data coco.yaml --weights yolov5s.pt --device 0,1,2
–nproc_per_node指定要使用的 GPU 数量。在上面的例子中,它是 3。
–batch 是总批次大小。它将平均分配给每个 GPU。在上面的示例中,每个 GPU 是 96/3=32。上面的代码将使用 GPU 0… (N-1)
测试
权重在runs/train/exp*中,一般使用best.pt
python test.py --weights runs/train/exp2/weights/best.pt --data ./data/coco.yaml --save-txt --iou-thres 0.2 --img-size 480
--weights :预训练模型路径,默认值weights/yolov5s.pt
--data:数据集的配置文件,默认为data/coco.yaml
--batch-size:默认值32
--img-size:推理大小(pixels),默认640
--conf-thres:目标置信度阈值,默认0.001
--iou-thres:NMS的IOU阈值,默认0.65
--save-json:把结果保存为cocoapi-compatible的json文件
--task:默认val,可选其他值:val, test, study
--device:cuda设备,例如:0或0,1,2,3或cpu,默认''
--half:半精度的FP16推理
--single-cls:将其视为单类别,布尔值
--augment:增强推理,布尔值
--verbose:显示类别的mAP,布尔值
可视化
使用tensorboard可视化结果
在yolov5目录下,使用:
tensorboard --logdir=runs
注意:
如果返回拒绝了我们的请求,可以在tensorboard的后面加上参数–port ip:
tensorboard --logdir=runs --host=192.168.0.134


















 936
936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









