






概述
要想分析应用程序的图形性能,必须先掌握一个最基本的知识,就是对 OpenGL API 底下系统运作方式有一定理解,才能推断和观察实际的绘制行为。
同步API与异步执行
首先要了解OpenGL API的调用与执行之间的关系。从应用程序的角度而言,OpenGL API是同步API,即调用过程是同步的,应用程序进行一系列的函数调用来设置其下一绘制任务所需的状态,然后调用glDraw函数(通常称为绘制调用)触发实际的绘制操作。由于 API是同步的,执行绘制调用后的所有API行为都被认为渲染已经发生,但在几乎所有GPU硬件的OpenGL实现上,这只是一种由驱动程序维持的一个假象。
与glDraw绘制调用相似,驱动程序维持的第二个假象是swapbuffer帧缓冲交换。大多数OpenGL应用程序的开发人员会告诉你,调用 eglSwapBuffers将交换其应用程序的前缓冲区和后缓冲区。虽然这在逻辑上是对的,但驱动程序实现时,在几乎所有平台上,实际的缓冲区交换可能会在很久之后才会发生。
Pipelining抽象
OpenGL驱动程序创造这些假象的根本原因在于性能。如果我们强制渲染操作真正同步发生,会面临这样的尴尬:CPU忙于创建下一绘制状态时,GPU会闲置;GPU执行渲染时,CPU 会闲置。对于以性能为重的GPU而言,所有这些闲置时间都是绝然不可接受的。

为了尽可能减少这种空闲时间,我们使用OpenGL 驱动程序来保持同步渲染行为的假象,同时实际执行时是异步处理渲染和帧交换。
通过异步运行,我们可以构建一个小的工作队列,GPU从队列的一端处理旧的工作负载,而CPU将新的工作推到另一端。这种方法的优点是,只要我们保持队列满载,总是有工作可以在GPU上运行,从而提供最佳性能。
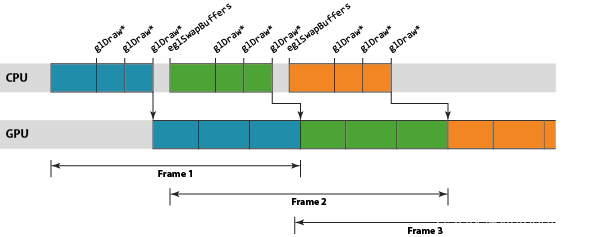
Pipeline的工作单元是基于每个渲染目标进行调度的,其中渲染目标可以是窗口表面或屏幕外渲染缓冲区。在两步过程中处理一个渲染目标。首先,GPU处理渲染目标中所有绘制调用的顶点着色,然后处理渲染目标的片段着色。因此,渲染管线是一个三阶段的管线:CPU处理、几何处理和碎片处理阶段。
Pipeline负载限制

从上图中可以观察到,片元操作是三个操作中最慢的,越来越落后于CPU和几何处理阶段。这种情况并不罕见;与顶点相比,要着色的片段要多得多,因此片段着色通常是主要的处理操作。
事实上,我们希望最大限度地减少从CPU工作完成到渲染完成的延迟量——对最终用户来说,这影响交互体验,例如触摸屏设备的显示与输入之间的交互延迟达到几百毫秒会让人觉得沮丧。——所以我们不希望等待片元处理阶段的积压工作变得太大。简而言之,我们需要一些机制来定期降低CPU线程的速度,当工作队列已经满到足以保持性能时,停止它排队工作。
这种Pipeline限流机制通常由窗口系统提供,而不是由图形驱动程序本身提供。如果窗口系统已经有N个以上的缓冲区排队等待渲染,那么它可以简单地通过拒绝将缓冲区返回到应用程序的图形堆栈来控制Pipeline深度。
如果出现这种情况,则一旦达到“N”,CPU每帧将空闲一次,在EGL或OpenGL API函数内部阻塞,直到一个挂起的缓冲区被渲染显示,从而释放一个缓冲区用于新的渲染操作。
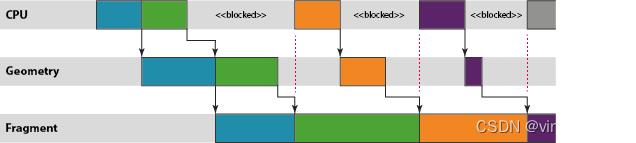
如果图形渲染速度快于显示器刷新率,可能会启用"vsync limited",即同步等待垂直消隐(vsync)信号,该信号告诉显示控制器它可以切换到下一个前缓冲器。如果GPU产生帧的速度快于显示器所能显示的速度,窗口将积累许多已经完成渲染但仍需要在屏幕上显示的缓冲区,这些帧也计入应用程序的N帧限制。
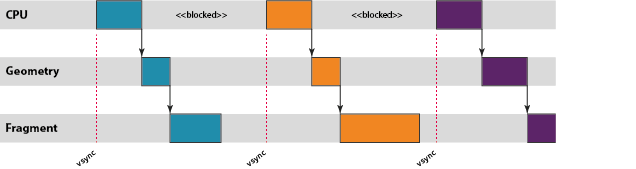
如上图所看到的,如果启用vsync,那么CPU和GPU都完全空闲的时间段是很常见的。在这些情况下,平台动态电压和频率缩放(DVFS)通常会试图降低当前工作频率,从而降低电压和能耗。
技术交流:
















 4954
4954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









