







 本文介绍了一种基于深度学习的文本生成技术,特别聚焦于利用LSTM模型生成古典诗词。通过大量诗词数据训练,模型能根据给定的首句、首字或特定模式生成高质量的五言绝句。
本文介绍了一种基于深度学习的文本生成技术,特别聚焦于利用LSTM模型生成古典诗词。通过大量诗词数据训练,模型能根据给定的首句、首字或特定模式生成高质量的五言绝句。
文本生成-诗词生成案例
1.1 文本生成问题
文本生成是自然语言处理中一个重要的研究领域,具有广阔的应用前景。国内外已经有诸如Automated Insights、Narrative Science以及“小南”机器人、“小明”机器人、“运动报道机器人”等文本生成系统投入使用。这些系统根据格式化数据或自然语言文本生成新闻、财报或者其他解释性文本。例如,Automated Insights的WordSmith技术已经被美联社等机构使用,帮助美联社报道大学橄榄球赛事、公司财报等新闻。这使得美联社不仅新闻更新速度更快,而且在人力资源不变的情况下扩大了其在公司财报方面报道的覆盖面。
解决这个问题的深度学习模型,最常见的是借助于语言模型,或者seq2seq这种encoder-decoder模型。我们这里使用最经典的语言模型,借助LSTM构建一个AI文本生成器。
1.2 文本生成原理
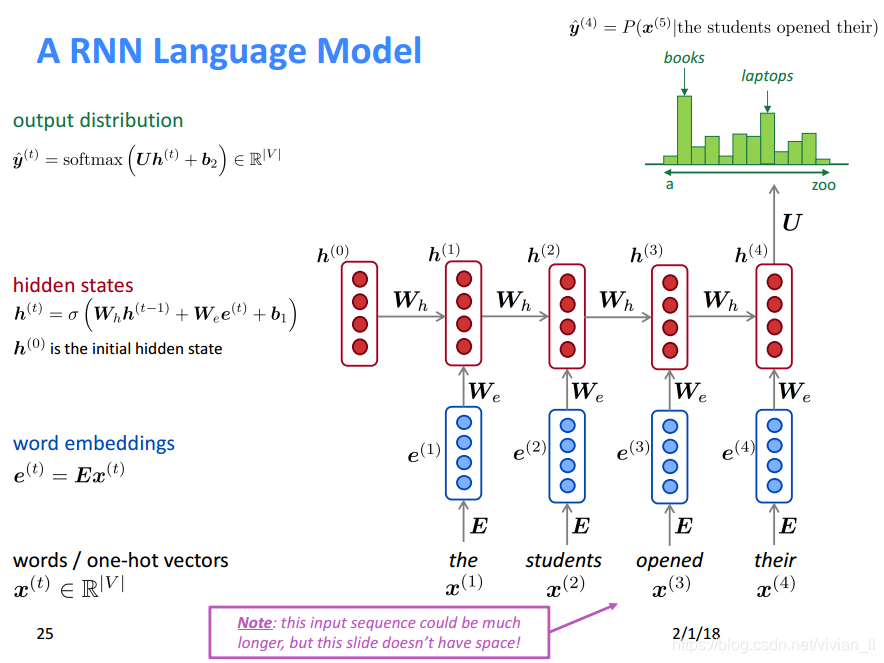
我们简单回顾一下我们在语言模型课程中讲到的内容,基于RNN(LSTM)的语言模型可以根据上下文去推断下一个位置有更高的概率出现哪个词,比如一个人说:"我是中国人,我的母语是__ "。 对于在“__”中需要填写的内容,RNN通过前文的“母语”知道需要是一种语言,通过“中国”知道这个语言需要是“中文”。而这种方式可以用来做文本生成,我们在给定词的头部一些字后,可以根据大量的诗歌文本总训练得到的语言模型,预估下一个位置合适填入的字词。
1.3 关于数据源
本项目更丰富的数据源可以在诗词github取到,感谢github作者的分享。
1.4 诗词生成器
我们这里使用keras工具库完成一个诗词生成器,实现方案是最简单的基于语言模型的实现方式。

导入库
# 引入需要的工具库
import numpy as np
import random
import os
from keras.layers import LSTM, Dropout, Dense
from keras.models import Input, Model, load_model
from keras.optimizers import Adam
from keras.callbacks import LambdaCallback,ModelCheckpoint
# 看下数据
!head -5 /jhub/students/data/course11/项目4/1.poetry_generator/dataset/poetry.txt
每行数据是一首诗,冒号前是题目,冒号后是诗句。
首春:寒随穷律变,春逐鸟声开。初风飘带柳,晚雪间花梅。碧林青旧竹,绿沼翠新苔。芝田初雁去,绮树巧莺来。
初晴落景:晚霞聊自怡,初晴弥可喜。日晃百花色,风动千林翠。池鱼跃不同,园鸟声还异。寄言博通者,知予物外志。
初夏:一朝春夏改,隔夜鸟花迁。阴阳深浅叶,晓夕重轻烟。哢莺犹响殿,横丝正网天。珮高兰影接,绶细草纹连。碧鳞惊棹侧,玄燕舞檐前。何必汾阳处,始复有山泉。
度秋:夏律昨留灰,秋箭今移晷。峨嵋岫初出,洞庭波渐起。桂白发幽岩,菊黄开灞涘。运流方可叹,含毫属微理。
仪鸾殿早秋:寒惊蓟门叶,秋发小山枝。松阴背日转,竹影避风移。提壶菊花岸,高兴芙蓉池。欲知凉气早,巢空燕不窥。
# 由于机器读写权限问题,需要把预训练模型拷贝到tmp文件夹下
!cp /jhub/students/data/course11/项目4/1.poetry_generator/model/poetry_model.h5 ../../tmp/
文本预处理
(对于古典诗歌,不做分词。)
# 定义配置类
class ModelConfig(object):
poetry_file = '/jhub/students/data/course11/项目4/1.poetry_generator/dataset/poetry.txt'
weight_file = '../../tmp/poetry_model.h5'
max_len = 6 # 五言绝句
batch_size = 64
learning_rate = 0.003
# 定义文件读取函数
def preprocess_data(ModelConfig):
# 语料文本内容
files_content = ''
with open(ModelConfig.poetry_file, 'r',encoding='UTF-8') as f:
for line in f:
x = line.strip() + "]" # 因为每首诗的长度不一样,所以在这里加一个分隔
# 取出具体诗的内容
x = x.split(":")[1]
# 根据长度过滤脏数据
if len(x) <= 5 :
continue
# 过滤出五言绝句
if x[5] == ',': # 第六个字符是逗号,则认为是五言绝句
files_content += x
# 字频统计
words = sorted(list(files_content)) # 按汉字编码排序(个人感觉也可以不排序)
counted_words = {}
for word in words:
if word in counted_words:
counted_words[word] += 1
else:
counted_words[word] = 1
# 低频字过滤
delete_words = []
for key in counted_words:
if counted_words[key] <= 2:
delete_words.append(key)
for key in delete_words:
del counted_words[key]
wordPairs = sorted(counted_words.items(), key=lambda x: -x[1]) # 频数取负,即倒序
words, _ = zip(*wordPairs)
words += (" ",)
# 构建 字到id的映射字典 与 id到字的映射字典
word2idx = dict((c, i) for i, c in enumerate(words))
idx2word = dict((i, c) for i, c in enumerate(words))
word2idx_dic = lambda x: word2idx.get(x, len(words) - 1)
return word2idx_dic, idx2word, words, files_content
构建LSTM模型
自定义自由度,四种预估模式(根据首句、根据首字、根据前max_len个字、藏头诗)
class LSTMPoetryModel(object):
def __init__(self, config):
self.model = None
self.do_train = True
self.loaded_model = True
self.config = config
# 诗歌训练文件预处理
self.word2idx_dic, self.idx2word, self.words, self.files_content = preprocess_data(self.config)
# 诗列表
self.poems = self.files_content.split(']')
# 诗的总数量
self.poems_num = len(self.poems)
# 如果有预训练好的模型文件,则直接加载模型,否则开始训练
if os.path.exists(self.config.weight_file) and self.loaded_model:
self.model = load_model(self.config.weight_file)
else:
self.train()
def build_model(self):
'''LSTM模型构建'''
print('模型构建中...')
# 输入的维度
input_tensor = Input(shape=(self.config.max_len, len(self.words))) # 此处未加Embedding层,加了会更好
lstm = LSTM(512, return_sequences=True)(input_tensor)
dropout = Dropout(0.6)(lstm)
lstm = LSTM(256)(dropout)
dropout = Dropout(0.6)(lstm)
dense = Dense(len(self.words), activation='softmax')(dropout)
self.model = Model(inputs=input_tensor, outputs=dense)
optimizer = Adam(lr=self.config.learning_rate)
self.model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
def sample(self, preds, temperature=1.0):
'''
temperature可以控制生成诗的创作自由约束度
当temperature<1.0时,模型会做一些随机探索,输出相对比较新的内容
当temperature>1.0时,模型预估方式偏保守
在训练的过程中可以看到temperature不同,结果也不同
就是一个概率分布变换的问题,保守的时候概率大的值变得更大,选择的可能性也更大
'''
preds = np.asarray(preds).astype('float64')
exp_preds = np.power(preds,1./temperature)
preds = exp_preds / np.sum(exp_preds)
prob = np.random.choice(range(len(preds)),1,p=preds)
return int(prob.squeeze())
def generate_sample_result(self, epoch, logs):
'''训练过程中,每5个epoch打印出当前的学习情况'''
if epoch % 5 != 0:
return
# 追加模式添加内容
with open('../../tmp/out.txt', 'a',encoding='utf-8') as f:
f.write('==================第{}轮=====================\n'.format(epoch))
print("\n==================第{}轮=====================".format(epoch))
for diversity in [0.7, 1.0, 1.3]:
print("------------设定诗词创作自由度约束参数为{}--------------".format(diversity))
generate = self.predict_random(temperature=diversity)
print(generate)
# 训练时的预测结果写入txt
with open('../../tmp/out.txt', 'a',encoding='utf-8') as f:
f.write(generate+'\n')
def predict_random(self,temperature = 1):
'''预估模式1:随机从库中选取一句开头的诗句,生成五言绝句'''
if not self.model:
print('没有预训练模型可用于加载!')
return
index = random.randint(0, self.poems_num)
sentence = self.poems[index][: self.config.max_len]
generate = self.predict_sen(sentence,temperature=temperature)
return generate
def predict_first(self, char,temperature =1):
'''预估模式2:根据给出的首个字,生成五言绝句'''
if not self.model:
print('没有预训练模型可用于加载!')
return
index = random.randint(0, self.poems_num)
# 选取随机一首诗的最后max_len个字+给出的首个文字作为初始输入
sentence = self.poems[index][1-self.config.max_len:] + char
generate = str(char)
# 预测后面23个字
generate += self._preds(sentence,length=23,temperature=temperature)
return generate
def predict_sen(self, text,temperature =1):
'''预估模式3:根据给出的前max_len个字,生成诗句'''
'''此例中,即根据给出的第一句诗句(含逗号),来生成古诗'''
if not self.model:
return
max_len = self.config.max_len
if len(text)<max_len:
print('给出的初始字数不低于 ',max_len)
return
sentence = text[-max_len:]
print('第一行为:',sentence)
generate = str(sentence)
generate += self._preds(sentence,length = 24-max_len,temperature=temperature)
return generate
def predict_hide(self, text,temperature = 1):
'''预估模式4:根据给4个字,生成藏头诗五言绝句'''
if not self.model:
print('没有预训练模型可用于加载!')
return
if len(text)!=4:
print('藏头诗的输入必须是4个字!')
return
index = random.randint(0, self.poems_num)
# 选取随机一首诗的最后max_len个字+给出的首个文字作为初始输入
sentence = self.poems[index][1-self.config.max_len:] + text[0]
generate = str(text[0])
print('第一行为 ',sentence)
for i in range(5):
next_char = self._pred(sentence,temperature)
sentence = sentence[1:] + next_char
generate+= next_char
for i in range(3):
generate += text[i+1]
sentence = sentence[1:] + text[i+1]
for i in range(5):
next_char = self._pred(sentence,temperature)
sentence = sentence[1:] + next_char
generate+= next_char
return generate
def _preds(self,sentence,length = 23,temperature =1):
'''
供类内部调用的预估函数,输入max_len长度字符串,返回length长度的预测值字符串
sentence:预测输入值
lenth:预测出的字符串长度
'''
sentence = sentence[:self.config.max_len]
generate = ''
for i in range(length):
pred = self._pred(sentence,temperature)
generate += pred
sentence = sentence[1:]+pred
return generate
def _pred(self,sentence,temperature =1):
'''供类内部调用的预估函数,根据一串输入,返回单个预测字符'''
if len(sentence) < self.config.max_len:
print('in def _pred,length error ')
return
sentence = sentence[-self.config.max_len:]
x_pred = np.zeros((1, self.config.max_len, len(self.words)))
for t, char in enumerate(sentence):
x_pred[0, t, self.word2idx_dic(char)] = 1.
preds = self.model.predict(x_pred, verbose=0)[0]
next_index = self.sample(preds,temperature=temperature)
next_char = self.idx2word[next_index]
return next_char
def data_generator(self):
'''生成器生成数据'''
i = 0
while 1:
x = self.files_content[i: i + self.config.max_len]
y = self.files_content[i + self.config.max_len]
if ']' in x or ']' in y:
i += 1
continue
y_vec = np.zeros(
shape=(1, len(self.words)),
dtype=np.bool
)
y_vec[0, self.word2idx_dic(y)] = 1.0
x_vec = np.zeros(
shape=(1, self.config.max_len, len(self.words)),
dtype=np.bool
)
for t, char in enumerate(x):
x_vec[0, t, self.word2idx_dic(char)] = 1.0
yield x_vec, y_vec
i += 1
def train(self):
'''训练模型'''
print('开始训练...')
number_of_epoch = len(self.files_content)-(self.config.max_len + 1)*self.poems_num
number_of_epoch /= self.config.batch_size
number_of_epoch = int(number_of_epoch / 2.5)
print('总迭代轮次为 ',number_of_epoch)
print('总诗词数量为 ',self.poems_num)
print('文件内容的长度为 ',len(self.files_content))
if not self.model:
self.build_model()
self.model.fit_generator(
generator=self.data_generator(),
verbose=True,
steps_per_epoch=self.config.batch_size,
epochs=number_of_epoch,
callbacks=[
ModelCheckpoint(self.config.weight_file, save_weights_only=False),
LambdaCallback(on_epoch_end=self.generate_sample_result)
]
)
model = LSTMPoetryModel(ModelConfig)
print('预训练模型加载成功!')
看下模型预测效果如何
for i in range(3):
#藏头诗
sen = model.predict_hide('争云日夏')
print(sen)
第一行为: 翁夜往还。争
争音常开台,云来清子恩。日天扉青家,夏作浮音为。
第一行为: 啄江海隅。争
争空谁上尽,云云中林翠。日落危西烟,夏更无长塞。
第一行为: 珠坠还结。争
争独望云落,云华北山山。日远仙入还,夏红游长无。
for i in range(3):
#给出第一句话进行预测
sen = model.predict_sen('山为斜好几,')
print(sen)
第一行为: 山为斜好几,
山为斜好几,风外风玉正。东云水赏叶,先松句断采。
第一行为: 山为斜好几,
山为斜好几,隐公帝碧自。开夜知孤满,下且露落鸟。
第一行为: 山为斜好几,
山为斜好几,六池如中田。阙露奇雪前,然十盛空不。
for i in range(3):
#给出第一个字进行预测
sen = model.predict_first('山')
print(sen)
山家光出观,隐黄戎识移。愿传兰重弦,飞方来凤为。
山迹几星道,寒行极幽直。方朝蝉家复,人经识子木。
山溪二屡正,归飞情尽宅。山未子华帝,花云新酒三。
for temp in [0.5,1,1.5]:
#随机抽取第一句话进行预测
sen = model.predict_random(temperature=temp)
print(sen)
第一行为: 十载别仙峰,
十载别仙峰,不春幽思入。山不春兰知,光三落台平。
第一行为: 已沐识坚贞,
已沐识坚贞,薄欢月坐终。旗国去向仙,采成赠金露。
第一行为: 水尔何如此,
水尔何如此,良不枝愿宁。中鹤四刺疑,境暮衣可独。
不满意可以运行model.train()再训练一会,觉得诗句可以看就可以停下来了,重新执行模型预测看下效果。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









