





Chapter 4.1 SRAM BASICS AND CACHE GEOMETRY
SRAM是当今计算机系统中广泛使用的一种重要的内存类型。数据为静态存储,不需要定期刷新。SRAM中的数据也是不稳定的,所以SRAM是一种临时数据存储类型。sram用于大多数现代cpu的片上缓存和寄存器文件。与DRAM相比,SRAM拥有更大、更复杂的bit cell。因此,SRAM的数据密度较低,制造成本较高,通常用于容量较小的存储结构。另一方面,SRAM的访问速度比DRAM快。所以SRAM适用于高速缓存和位于内存层次结构顶部的寄存器。典型的SRAM具有如图4.1所示的6-晶体管单元结构。该cell由一对交叉耦合的逆变器(cross-coupled inverters)和两个接入晶体管(access transistors)组成。交叉耦合逆变器有两种稳定状态,因此可以存储一位数据。接入晶体管用于数据位的读写。
SRAM单元被安排在一个array中以进行有效的数据访问。在SRAM阵列中,一个字线跨越一行并通过接入晶体管连接到一行中的所有cell。同样,一对位线(BL/BLB)跨越一列并连接列中的所有cell。一些外围逻辑被放置在每个SRAM阵列周围,帮助从阵列访问数据。行地址解码器连接到所有的字线,并用于根据行地址激活正确的字线。BL外设包括感测放大器、位线预充和写入驱动器。在一个读周期中,位线首先被预充电,作为读取的准备。然后激活目标字线,在每个位线对(bitline pair)上,BL或BLB保持高位,这取决于相应的bit-cell的值。在一个写周期中,每个写驱动器都会根据需要写的值将BL或BLB提高到高电压。然后激活目标字线,每个cell的交叉耦合逆变器根据BL/BLB值切换到新的状态。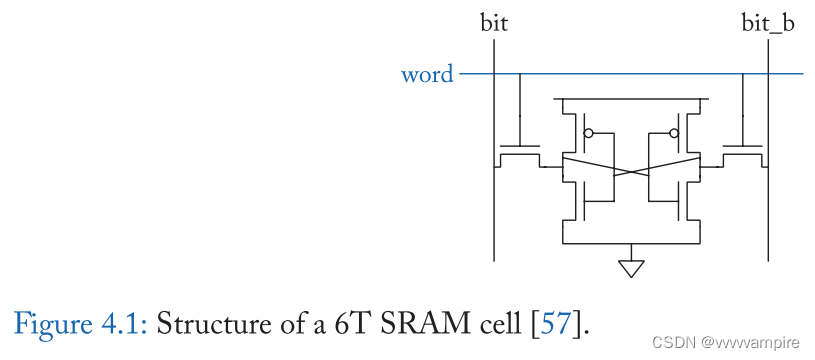
SRAM单元必须在读写过程中和数据保存阶段保持存储数据的正确性。一个定量的SRAM单元的稳定性测量方法是噪声容限(noise margin),这是电子噪声的最大水平,不会导致SRAM单元的数据损坏。我们简要概述了现代处理器中cache的几何结构。图4.2展示了一个多核处理器,其模型粗略地模仿了英特尔的至强处理器[58,59]。共享的最后一级缓存(Last Level Cache, LLC)被分配到许多slice上(这里讨论的Xeon E5为8-14个),这些slice可以通过共享的环形互连(图中没有显示)被cora访问。图4.2b显示了LLC缓存的一个slice。该slice有80个32KB的bank,分为20种组织方式。每个bank由两个16kb的sub-array连接。图4.2c显示了一个由8kb SRAM array组成的16KB sub-array的内部结构。图4.2显示了一个8kb的SRAM array。SRAM阵列被组织成多行数据存储bit-cells。同一行中的bit-cells共享一个字线,而同一列中的bit-cells格共享一对位线。
SRAM阵列中的in-SRAM矢量运算(图4.2)可以利用缓存结构中的大量并行性,将数千个SRAM阵列(Xeon E5中有·4480个阵列)重新利用为矢量计算单元。我们观察到LLC访问延迟主要由缓存slice内的线延迟、访问上层缓存控制结构和network-on-chip控制。因此,一个典型的LLC访问可以花费~30个周期,而一个SRAM阵列访问只有一个周期(在4 GHz时钟[58])。幸运的是,in-SRAM架构只需要SRAM阵列访问,而不需要传统缓存访问的开销。因此,可以节省大量的精力和时间用于连接和更高级别的内存层次结构。
Chapter4.2 DIGITAL COMPUTING APPROACHES
Chapter4.3 ANALOG AND DIGITAL MIXED-SIGNAL APPROACHES
Chapter 4.4 NEAR-SRAM COMPUTING
Near-SRAM计算将额外的计算组件放置在SRAM结构附近,而在In-SRAM计算中,SRAM阵列或外部设备被修改来进行计算。早在20世纪90年代,就有人提出将近sram计算设备作为一种协处理器。例如,Terasys[3]将single-bit的ALU放置在SRAM阵列附近,每个位线放置一个。数据从SRAM中读出,计算由ALU以位串行(bit-serial)方式执行。主处理器负责向SRAM阵列发送计算指令。
CPU缓存是用SRAM构建的一个主要的架构组件,因此最近很多工作都在探索用CPU缓存实现Near-SRAM计算的机会。计算是由放置在CPU缓存层次结构中的定制PE实现的。为了实现足够的并行性,PE被放置在最后一级cache slice 附近,在cora和最后一级缓存slice间的数据路径上[74]。PE有各种类型的实现,包括简单的in-order内核,可重构的结构如FPGA[75],以及特定应用程序的定制逻辑[76]。被加速的应用程序大多是涉及CPU处理的数据密集型操作,如数据库[76]和网络栈(network stack)中的函数[74]。在简化的编程模型和灵活的计算调度上对Near-sram计算进行了优化。例如,Livia[75]根据内存层次中操作数的位置,优化计算(PE或CPU核)的位置,从而减少总体数据移动。虽然并行度比in-SRAM计算低,但near-SRAM计算不需要对sram结构进行低级修改,并且支持不同PE设计的更灵活的计算模式。















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









