






今天是20240329,我见有人问我,我看了下现在的YOLOv5_6.1——7.0的版本是支持未改网络结构的.pt在export.py直接转.engine的,6.1以前的版本不可以直接转,至于master大家可以去试试
————————————————————————————————————————————————————————————————————————————————————————————————
说在前面,之前做项目遇到了需要对yolov5进行tensorrt加速,然后部署在边缘设备上,写本篇主要是为了记住加速的步骤,见别的很多大佬先转换的.wts,现在已经不用那么复杂了,有更简洁的方法,如果能对大家有帮助,我也很开心。
一、首先yolov5的环境配置就不说了,网上资料已经很多了。
二、再者,CUDA和CUDNN安装以及完整训练步骤,也不说了网上资料依然已经很多了。
三、主要记录下tensorrt,tensorrt的安装,在csdn上也能搜到很多,截止到我写这篇文章的时候,大家普遍用的tensorrt8.x的版本,TensorRT 同时支持 C++ 和 Python。因为yolov5是python写的,所以我也主要用python的。
转换网络权重文件主要分为未修改网络的权重文件,和自行修改网络后的权重文件。
其中未修改网络的权重文件可以直接把yolov5源码训练得到的.pt转换为tensorrt支持的.engine文件,这个.engine在yolov5的detect.py里可以直接调用,当然也可以自己写推理代码
自行修改网络后的权重文件是先将yolov5源码训练得到的.pt文件转换成.onnx,再把.onnx转化为优化后的.onnx,最后再把优化后的.onnx转换为tensorrt支持的.engine,这个.engine在yolov5的detect.py里可以直接调用,当然也可以自己写推理代码。
首先.pt文件可以通过yolov5自带的export.py这个程序去直接转化,如果是未修改网络的权重文件,可以在export.py程序里,最下面的parse_opt函数里修改参数如下:
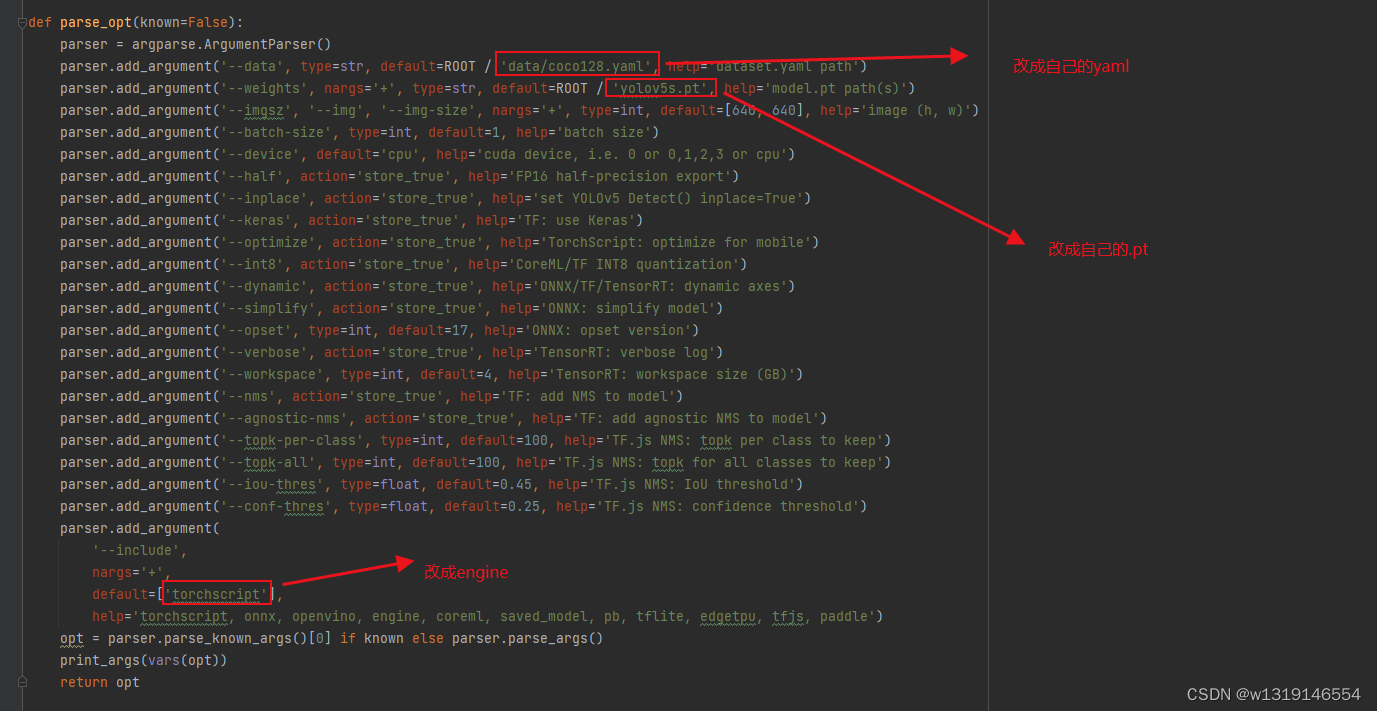
然后右击运行,如果环境配好的话,等几分钟就可以转换好了,我的这个yolov5版本是随时更新的yolov5_master版本,不同的版本可能不太一样,不过大同小异。(有些比较老的版本不能直接转.engine,如果不能转,就看我下面的自行修改网络后的权重文件转.engine,步骤是一样的。)转换.engine后,可以在yolov5的detect.py里可以直接调用,当然也可以自己写推理代码。
如果训练后得到自行修改网络后的权重文件,首先在yolov5自带的export.py里,修改

然后右击运行,如果环境配好的话,等几秒钟就可以转换好了,转换好后会得到一个.onnx的文件,这个.onnx是未优化后的,得在一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine这里进行优化(感谢这位大佬)。主要是onnx转onnx,得到优化后的.onnx后,通过下面的代码去转换成.engine。
import tensorrt as trt
import os
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
TRT_LOGGER = trt.Logger()
def get_engine(onnx_file_path, engine_file_path=""):
"""Attempts to load a serialized engine if available, otherwise builds a new TensorRT engine and saves it."""
def build_engine():
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(
EXPLICIT_BATCH
) as network, builder.create_builder_config() as config, trt.OnnxParser(
network, TRT_LOGGER
) as parser, trt.Runtime(
TRT_LOGGER
) as runtime:
config.max_workspace_size = 1 << 32 # 4GB
builder.max_batch_size = 1
# Parse model file
if not os.path.exists(onnx_file_path):
print(
"ONNX file {} not found, please run yolov3_to_onnx.py first to generate it.".format(onnx_file_path)
)
exit(0)
print("Loading ONNX file from path {}...".format(onnx_file_path))
with open(onnx_file_path, "rb") as model:
print("Beginning ONNX file parsing")
if not parser.parse(model.read()):
print("ERROR: Failed to parse the ONNX file.")
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# # The actual yolov3.onnx is generated with batch size 64. Reshape input to batch size 1
# network.get_input(0).shape = [1, 3, 608, 608]
print("Completed parsing of ONNX file")
print("Building an engine from file {}; this may take a while...".format(onnx_file_path))
plan = builder.build_serialized_network(network, config)
engine = runtime.deserialize_cuda_engine(plan)
print("Completed creating Engine")
with open(engine_file_path, "wb") as f:
f.write(plan)
return engine
if os.path.exists(engine_file_path):
# If a serialized engine exists, use it instead of building an engine.
print("Reading engine from file {}".format(engine_file_path))
with open(engine_file_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
else:
return build_engine()
def main():
"""Create a TensorRT engine for ONNX-based YOLOv3-608 and run inference."""
# Try to load a previously generated YOLOv3-608 network graph in ONNX format:
onnx_file_path = "best0605-sim.onnx"
engine_file_path = "best0605-sim.engine"
get_engine(onnx_file_path, engine_file_path)
if __name__ == "__main__":
main()
主要是把倒数几行的.onnx和.engine输入输出路径和名字改一下就好,环境都配置好的话,运行代码需要两三分钟,之后就可以得到.engine,转换.engine后,可以在yolov5的detect.py里可以直接调用,当然也可以自己写推理代码。
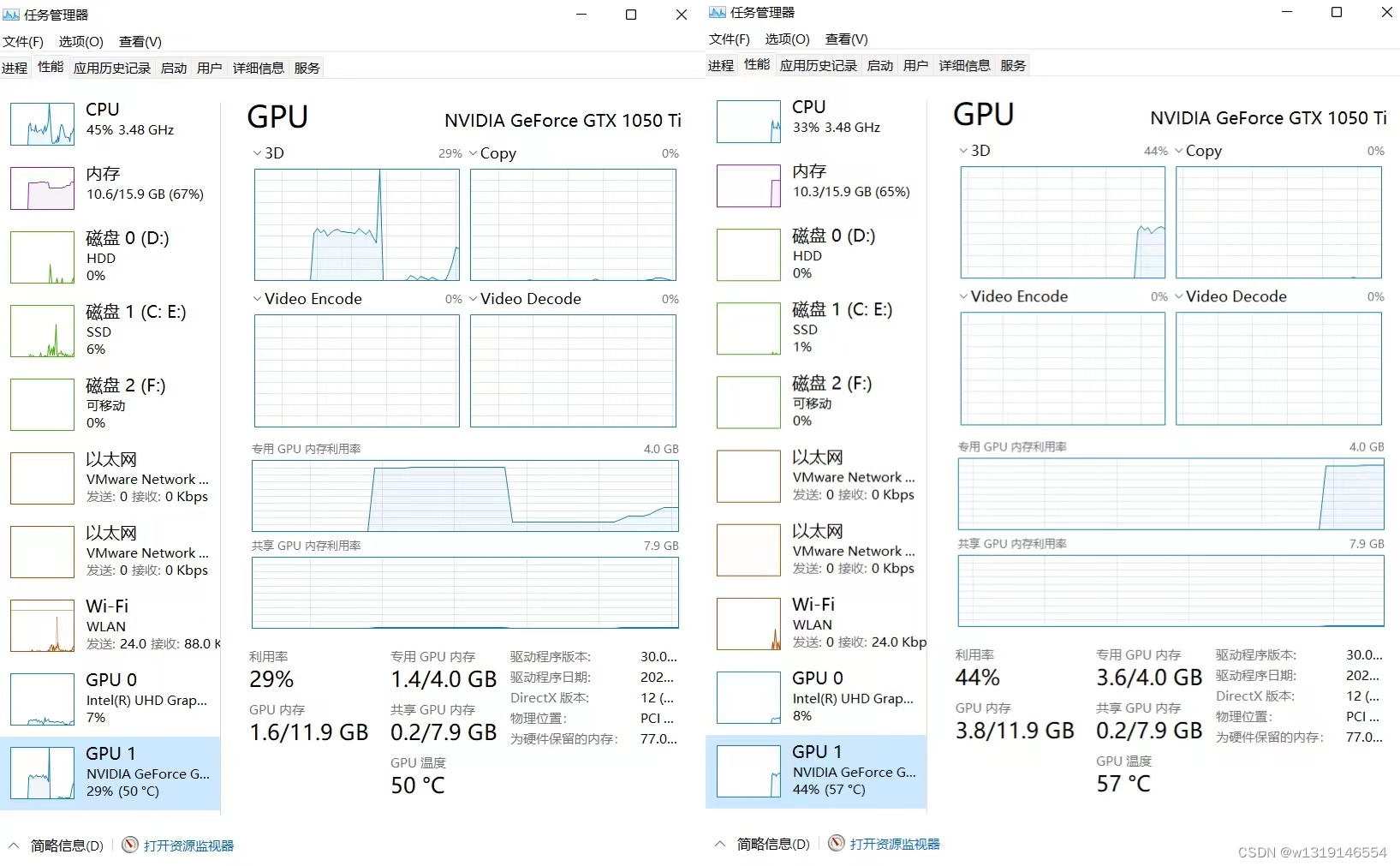
下图左侧是tensorrt加速后的显存占用率,右侧是未加速的显存占用率,可见tensorrt加速后,占用资源明显低于未加速的,GPU占用内存从3.8G降到了1.6G,这对一些计算能力不足边缘设备去运行yolov5提供了很大的方便,同时节省的算力也可以用来运行其他的功能等。
如果遇到报错,要不是环境配置问题,要不就是版本问题,另外如果提示opest什么的错误,可以尝试修改一下这个数字:多试几次。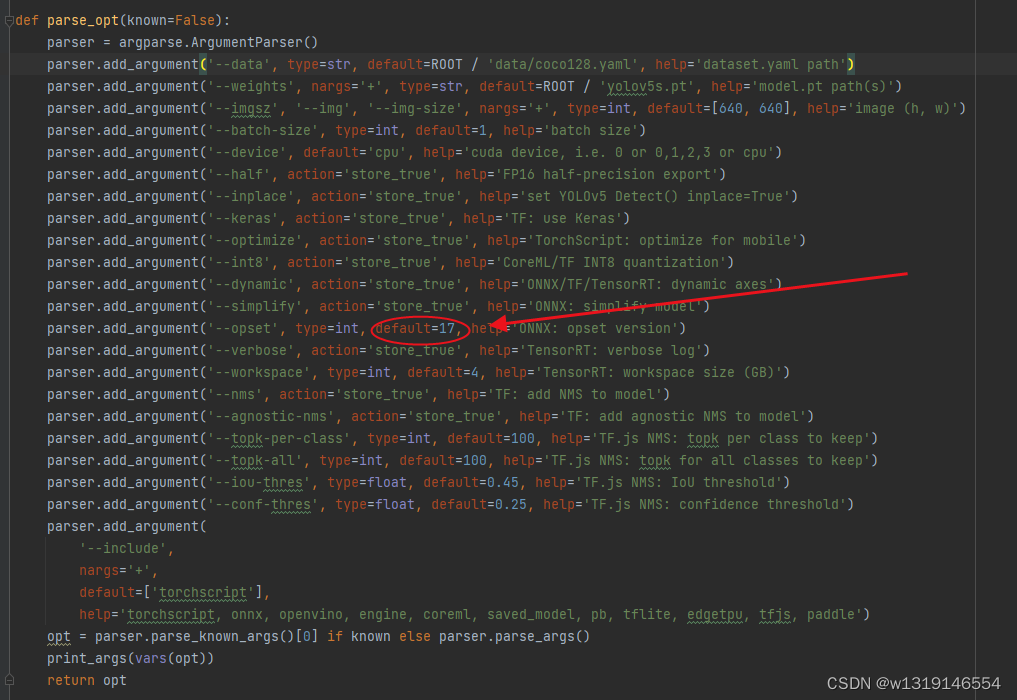
最后还有很重要的提醒一下,onnx文件可以跨设备使用,但是在转换.engine时,最好还是在那个设备上用,就用那个设备去转,要不然如果在一台设备上转的.engine,却在另一台设备上用的话,可能会因为版本问题而报错。
还有就是在转engine时,设备会很吃电,供电电压也不能太小,我之前在AGX上转,有一次没用220v供电,而是用的电池供电,导致还没转完,就断电关机了。
以上就是我对yolov5进行tensorrt加速的过程,我主要是在windows11系统和AGX的Ubuntu18.04和TX2的Ubuntu18.04上进行的,都成功了,并且资源利用也大大减小了。有什么问题欢迎在评论区问我。


















 2449
2449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











