







代码参照 http://cuiqingcai.com/990.html
#coding=utf-8
import requests
import json
from bs4 import BeautifulSoup
import urllib2
import re
def main():
headers={
'Host':'www.qiushibaike.com',
'If-None-Match':'"5f4c51ff98311e9713e3bab9abba1c1369d50a93"',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2050.400 QQBrowser/9.5.10218.400'
}
url='http://www.qiushibaike.com/hot/page/1'
requests=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(requests)
content=response.read().decode('utf-8') #content是网页源码
pattern = re.compile('<div.*?author[\s\S]*?<img src=.*?alt="(.*?)">[\s\S]*?<span>(.*?)</span>',re.S)
items = re.findall(pattern,content)
for item in items:
print "用户名:",item[0]
print "内容:",item[1].strip()+"\n"
if __name__ == '__main__':
main()pattern的正则表达式是关键:<div.*?author[\s\S]*?<img src=.*?alt="(.*?)">[\s\S]*?<span>(.*?)</span>
这里是对content(即网页的源代码进行正则匹配)
使用在线正则表达式测试工具:http://tool.oschina.net/regex/
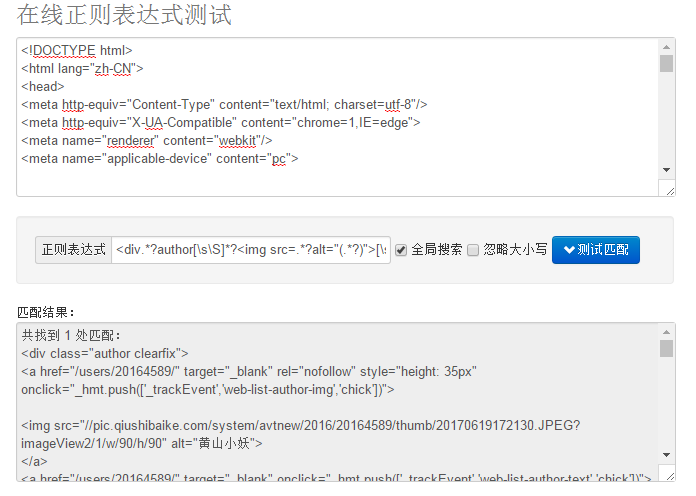
<div class="author clearfix">
<a href="/users/34630660/" target="_blank" rel="nofollow" style="height: 35px" οnclick="_hmt.push(['_trackEvent','web-list-author-img','chick'])">
<img src="//pic.qiushibaike.com/system/avtnew/3463/34630660/thumb/2017092517213069.PNG?imageView2/1/w/90/h/90" alt="昆昆人">
</a>
<a href="/users/34630660/" target="_blank" οnclick="_hmt.push(['_trackEvent','web-list-author-text','chick'])">
<h2>
昆昆人
</h2>
</a>
<div class="articleGender manIcon">47</div>
</div>
<a href="/article/119747920" target="_blank" class="contentHerf" οnclick="_hmt.push(['_trackEvent','web-list-content','chick'])">
<div class="content">
<span>
同事的店铺租出去了,租金10万,但是一直没有拿到租金,所以打电话,上门去讨,打官司等等手段全部用上了,可惜还是一分钱没有拿到。后来别人出主意,找讨债公司,女人去了直接开骂,男人恐吓,租客吓的据说浑身发抖,孩子吓的哭的哇哇的,赶紧还了一部分,剩余的每个月还,且保证每个月按时还,不然讨债公司马上上门。同事租金和讨债公司4 6开,想想何必呢,欠债还钱天经地义,闹到这一步,自己担惊受怕,家人也跟着受连累。当然同事也是受了损失。
</span><div.*?author[\s\S]*?<img src=.*?alt="(.*?)">[\s\S]*?<span>(.*?)</span>
[\s\S]*?中\s表示匹配任何不可见字符,如制表符,换页符,空格,\S匹配任意可见字符,*任意个数,?非贪婪匹配。[\s\S]*?:以非贪婪匹配的方式,匹配到任意多个字符
(.*?)代表分组,即我们取到的item[0]和item[1]
运行结果:
















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









