









文章目录
1 * 1 卷积核

如上图所示,输入为 3 通道的 5 × 5图片,与单个 1 × 1的卷积核(3通道)进行卷积运算,每个通道的数据与对应通道的卷积核运算,得到 3 个通道的中间矩阵,对应位置相加得到最终的输出张量。对于输入 shape 为 [b, h, w, C𝑖𝑛], 1 × 1卷积层的输出为 [b, h, w, C𝑜𝑢𝑡](注意,1 × 1卷积核使得输出高/宽没有改变,只改变了通道数) ,其中C𝑖𝑛为输入数据的通道数,C𝑜𝑢𝑡为输出数据的通道数,也是1 × 1卷积核的数量。 1 × 1卷积核的一个特别之处在于,它可以不改变特征图的宽高,而只对通道数𝑐进行变换。
梯度传播
解决一个关键问题,卷积层通过移动感受野的方式实现离散卷积操作,梯度传播是如何进行的?
考虑一简单的情形,输入为3 × 3的单通道矩阵,与一个2 × 2的卷积核,进行卷积运算,输出结果打平后直接与虚构的标注计算误差,如下图所示,讨论这种情况下的梯度更新方式。
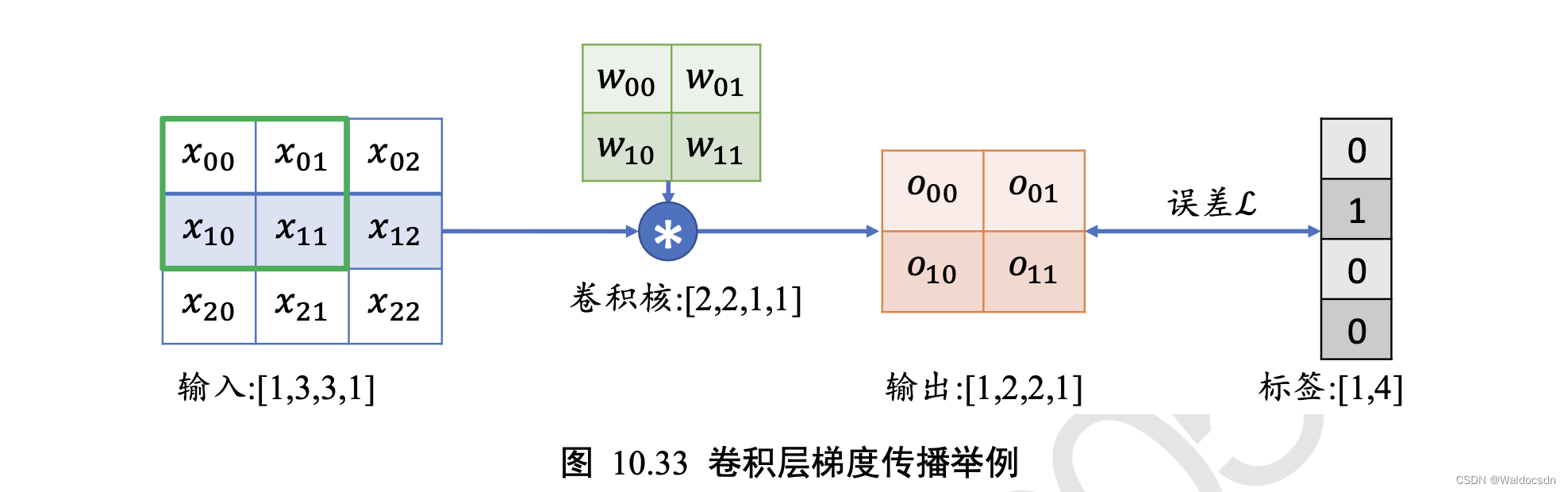

可以观察到,通过循环移动感受野的方式并没有改变网络层可导性,同时梯度的推导也并不复杂,只是当网络层数增大以后,人工梯度推导将变得十分的繁琐。不过深度学习框架会自动完成所有参数的梯度计算与更新,程序猿只需要设计好网络结构即可~
池化层(Pooling Layer)
在卷积层中,可以通过调节步长参数s实现特征图的高宽成倍缩小,从而降低了网络的参数量。实际上,除了通过设置步长,还有一种专门的网络层可以实现尺寸缩减功能,它就是这里要介绍的池化层(Pooling Layer)。
池化层同样基于局部相关性的思想,通过从局部相关的一组元素中进行采样或信息聚合,从而得到新的元素值。
特别地,最大池化层(Max Pooling)从局部相关元素集中选取最大的一个元素值;平均池化层(Average Pooling)从局部相关元素集中计算平均值并返回。
以 5 * 5 输入𝑿的“最大池化层”为例,考虑“池化感受野”窗口大小𝑘 = 2,步长𝑠 = 1的情况,如下图 10.34 所示:
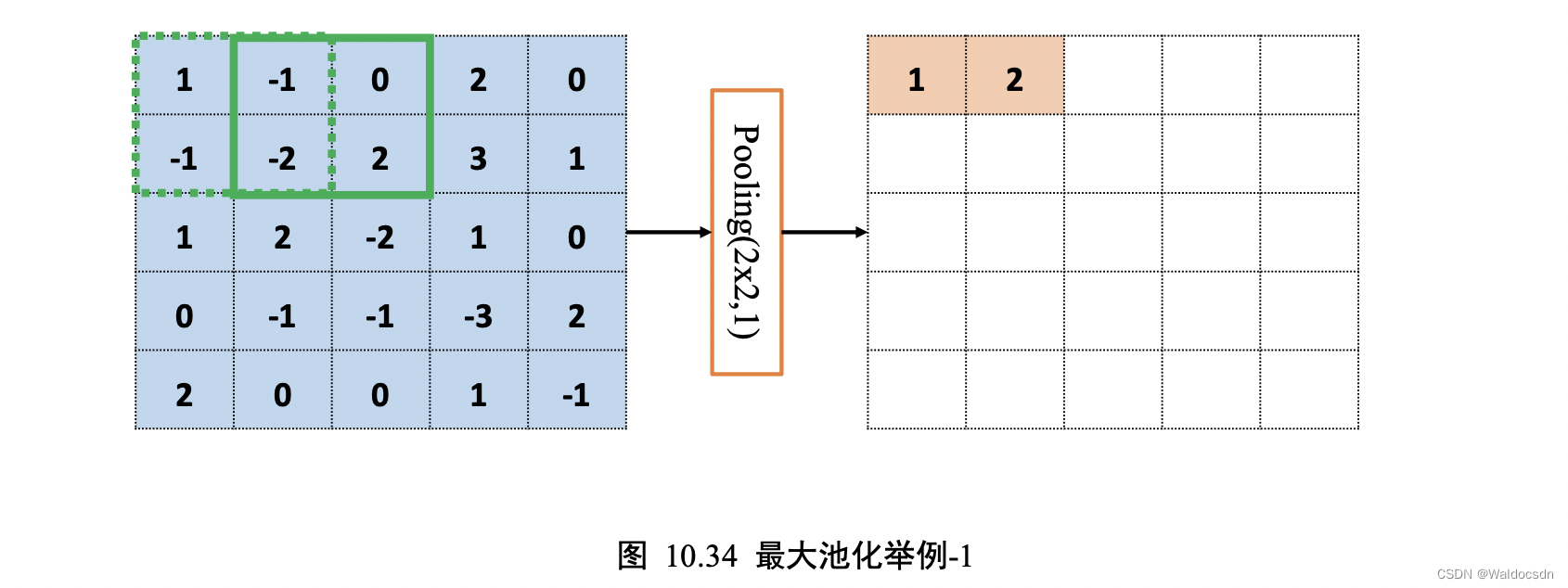
绿色虚线方框代表第一个感受野的位置,感受野元素集合为{1, -1, -1, -2}。
在最大池化采样的方法下,通过𝑥′=max({1, -1, -1, -2}) = 1 计算出当前位置的输出值为 1,并写入对应位置。
若采用的是平均池化操作,则此时的输出值应为 𝑥′=avg({1, -1, -1, -2}) = -0.75。
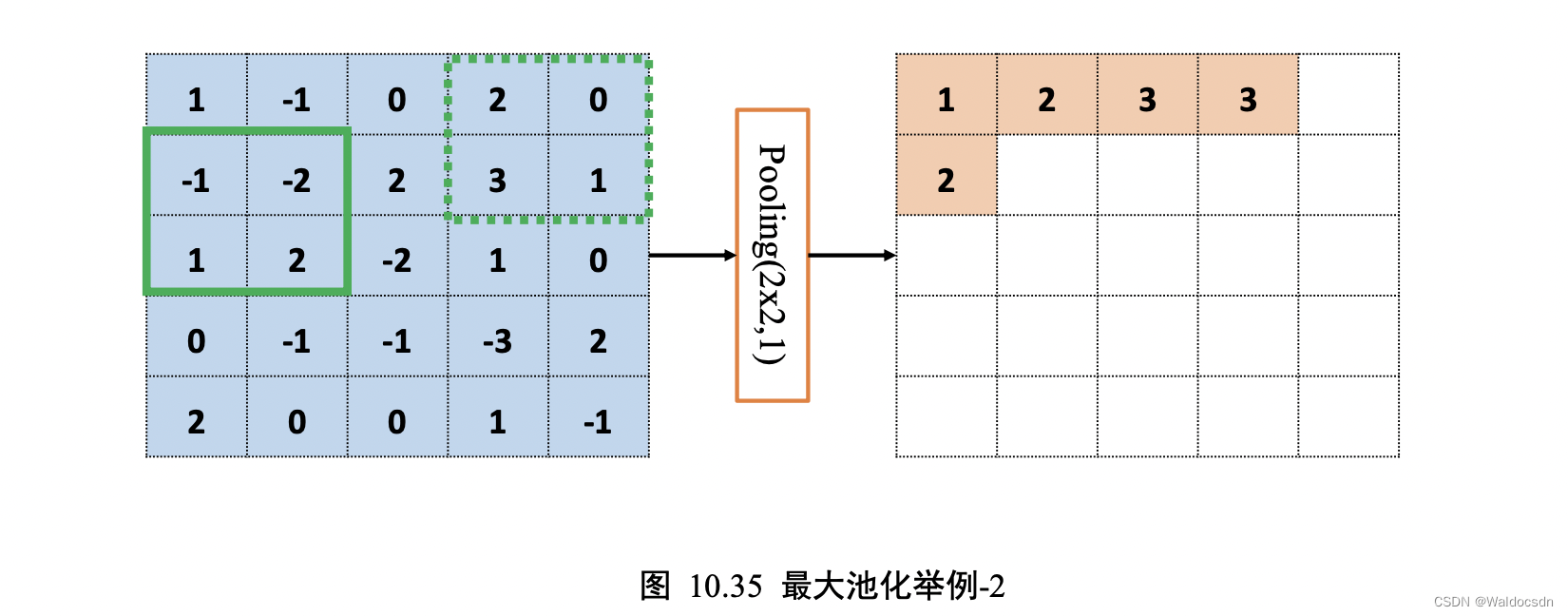
计算完当前位置的感受野后,与卷积层的计算步骤类似,将感受野按着步长向右移动若干单位,此时的输出𝑥′=max(-1, 0, -2, 2) = 2。
同样的方法,逐渐移动感受野窗口至最右边,计算出输出𝑥′ = max(2, 0, 3, 1) = 3,此时窗口已经到达输入边缘,按照卷积层同样的方式,感受野窗口向下移动一个步长,并回到行首,如图 10.35:
循环往复,直至最下方、最右边,获得最大池化层的输出,长宽为 4 * 4,略小于输入𝑿的高宽,如图 10.36:
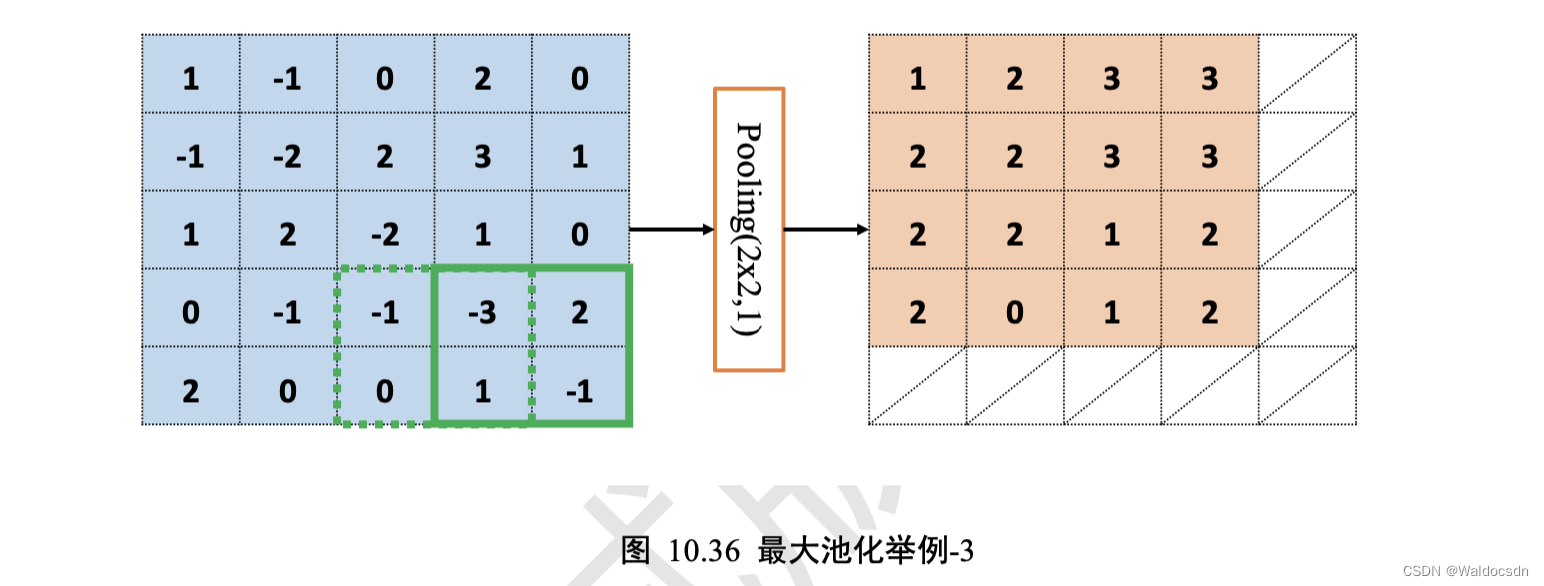
由于池化层没有需要学习的参数,计算简单,并且可以有效减低特征图的尺寸,非常适合图片这种类型的数据,在计算机视觉相关任务中得到了广泛的应用。
通过精心设计池化层感受野的高宽𝑘和步长𝑠参数,可以实现各种降维运算。比如,一种常用的池化层设定是感受野大小𝑘 = 2,步长𝑠 = 2,这样可以实现输出只有输入高宽一半的目的。如下图 10.37、图 10.38 所示,感受野𝑘 = 3,步长𝑠 = 2,输入𝑿高宽为 5 * 5 , 输出𝑶高宽只有2 * 2。
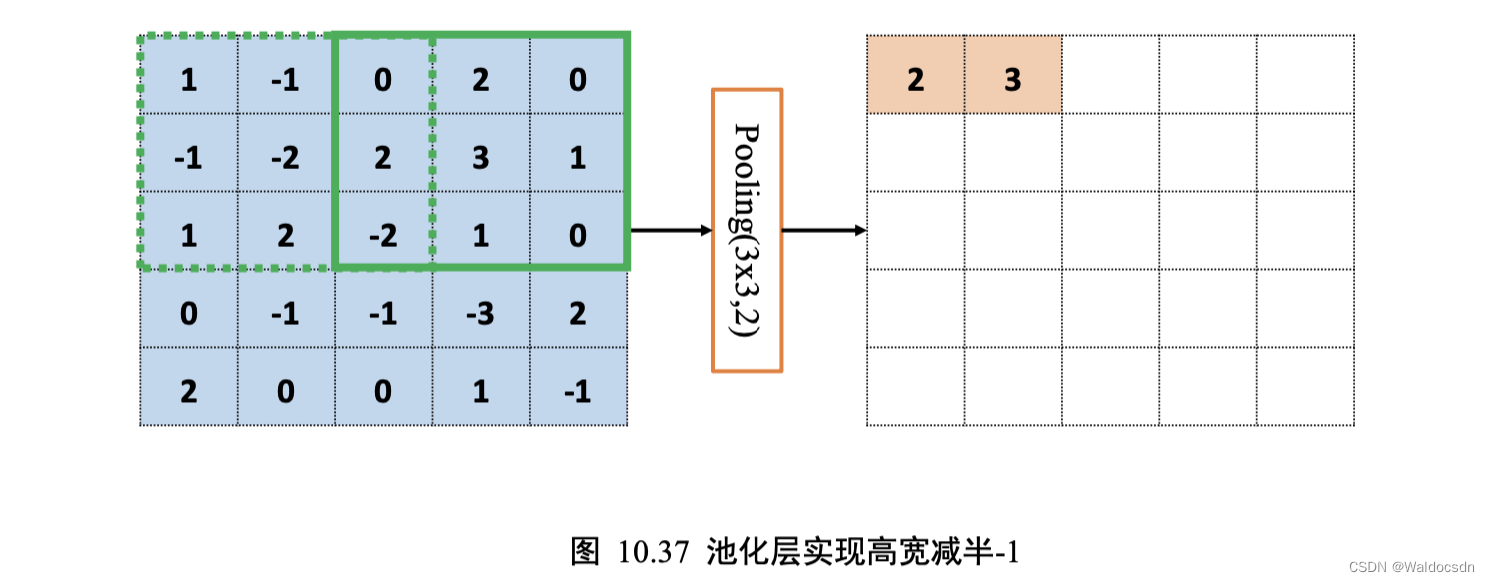
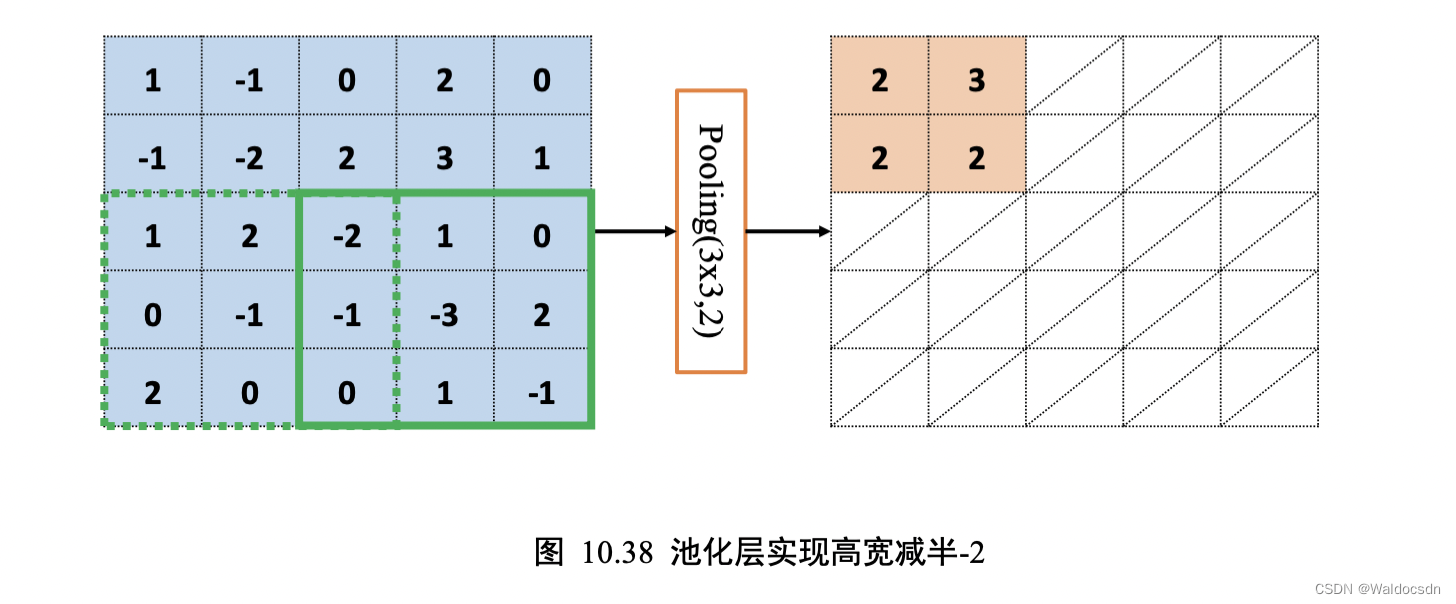
补充:
下面视频清晰版: 链接: https://pan.baidu.com/s/1HtZqSXjmp3dqZJ5AA6bjjA?pwd=urn9 提取码: urn9
CVNLP基础文章10Pooling视频
Sigmoid激活函数
Sigmoid 函数也叫 Logistic 函数,定义为:
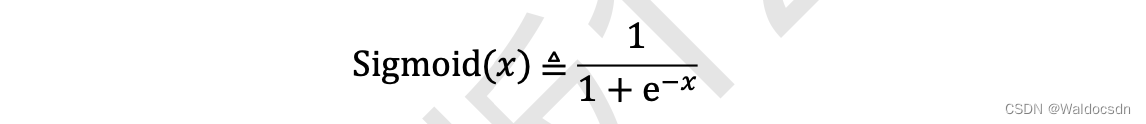
它的一个优良特性就是能够把𝑥 ∈ 𝑅的输入“压缩”到𝑥 ∈ (0,1)区间,这个区间的数值在机器学习常用来表示以下意义:
❑ 概率分布: (0,1)区间的输出和概率的分布范围[0,1]契合,可以通过 Sigmoid 函数将输出转译为概率输出
❑ 信号强度 : 一般可以将 0~1 理解为某种信号的强度,如像素的颜色强度,1 代表当前通道颜色最强,0 代表当前通道无颜色;抑或代表门控值(Gate)的强度,1 代表当前门控全部开放,0 代表门控关闭。
Sigmoid 函数连续可导,如下图所示,可以直接利用梯度下降算法优化网络参数,应用非常广泛。
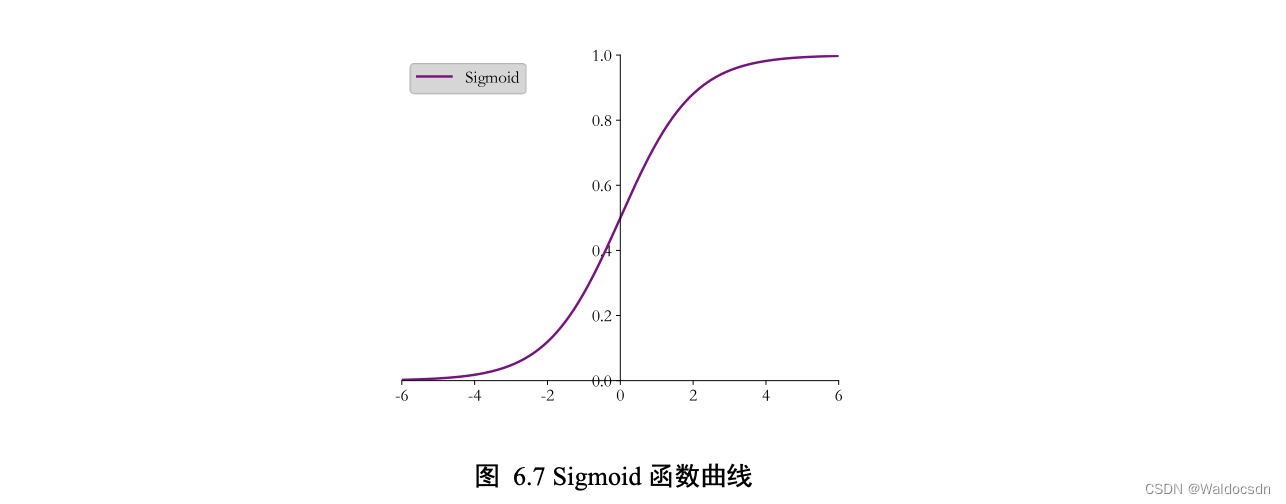
在 TensorFlow 中,可以通过 tf.nn.sigmoid 实现 Sigmoid 函数,代码如下: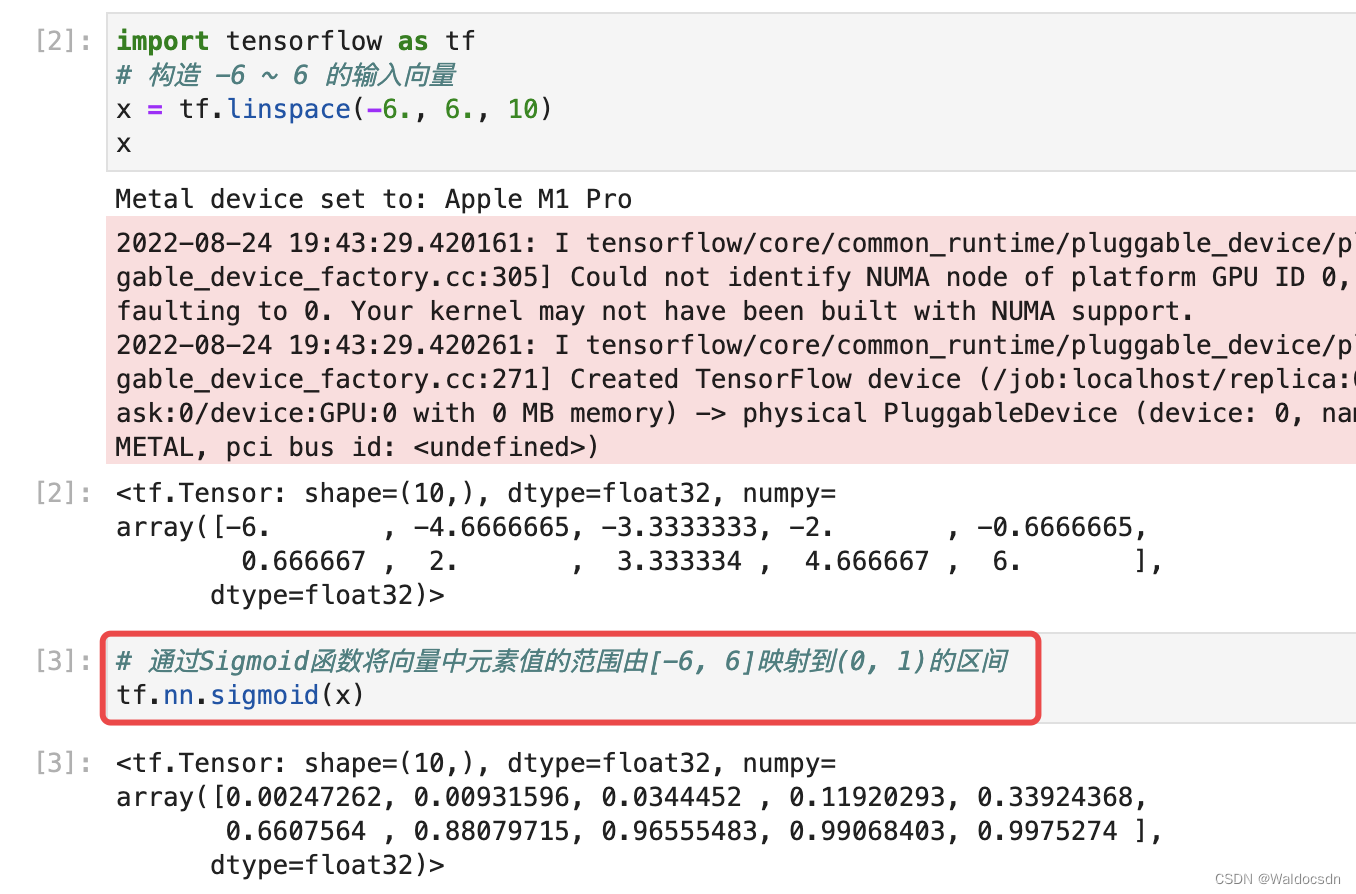
ReLU激活函数
在 ReLU(REctified Linear Unit,修正线性单元)激活函数提出之前,Sigmoid 函数通常是神经网络的激活函数首选。但是 Sigmoid 函数在输入值较大或较小时容易出现梯度值接近于 0 (导数为0)的现象,称为梯度弥散现象。出现梯度弥散现象时,网络参数长时间得不到更新, 导致训练不收敛或停滞不动的现象发生,较深层次的网络模型中更容易出现梯度弥散现象。2012 年提出的 8 层 AlexNet 模型采用了一种名叫 ReLU 的激活函数,使得网络层数达到了 8 层,自此 ReLU 函数应用的越来越广泛。
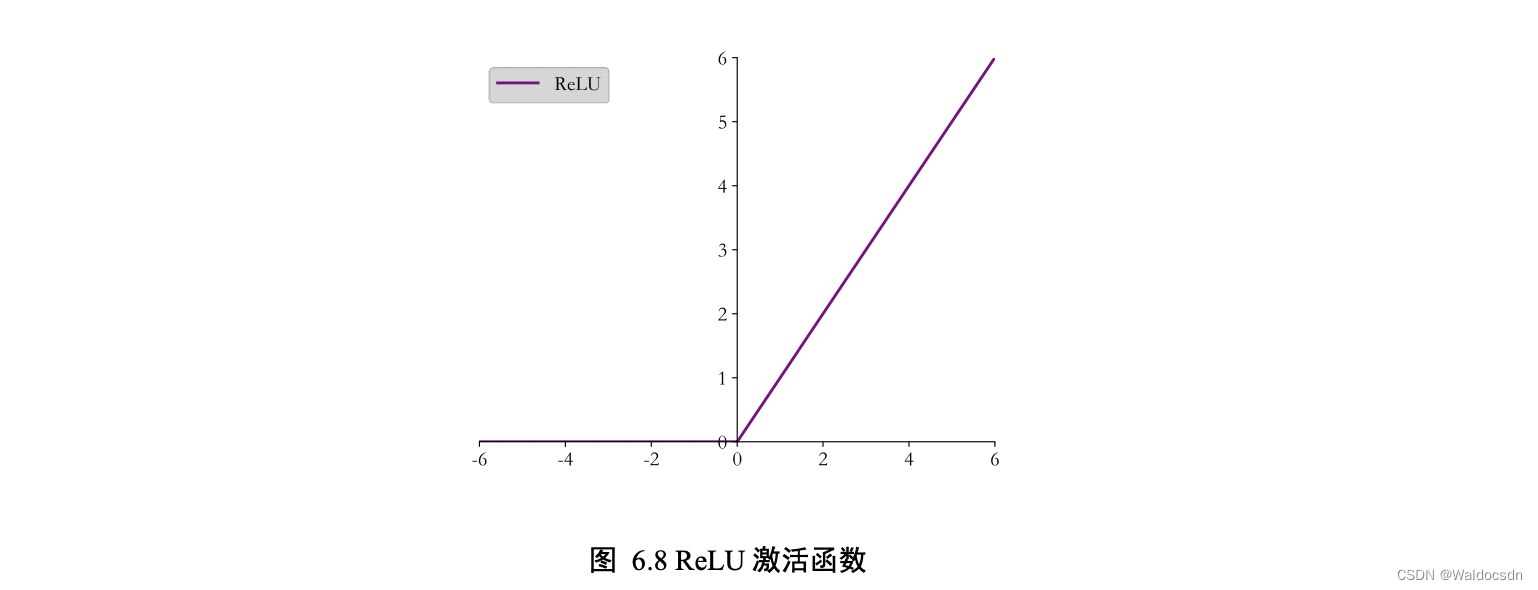
ReLU 函数定义为: ReLU(𝑥) ≜ max(0, 𝑥)
函数曲线如下图所示,可以看到,ReLU 对小于 0 的值全部抑制为 0;对于正数则直接输出:
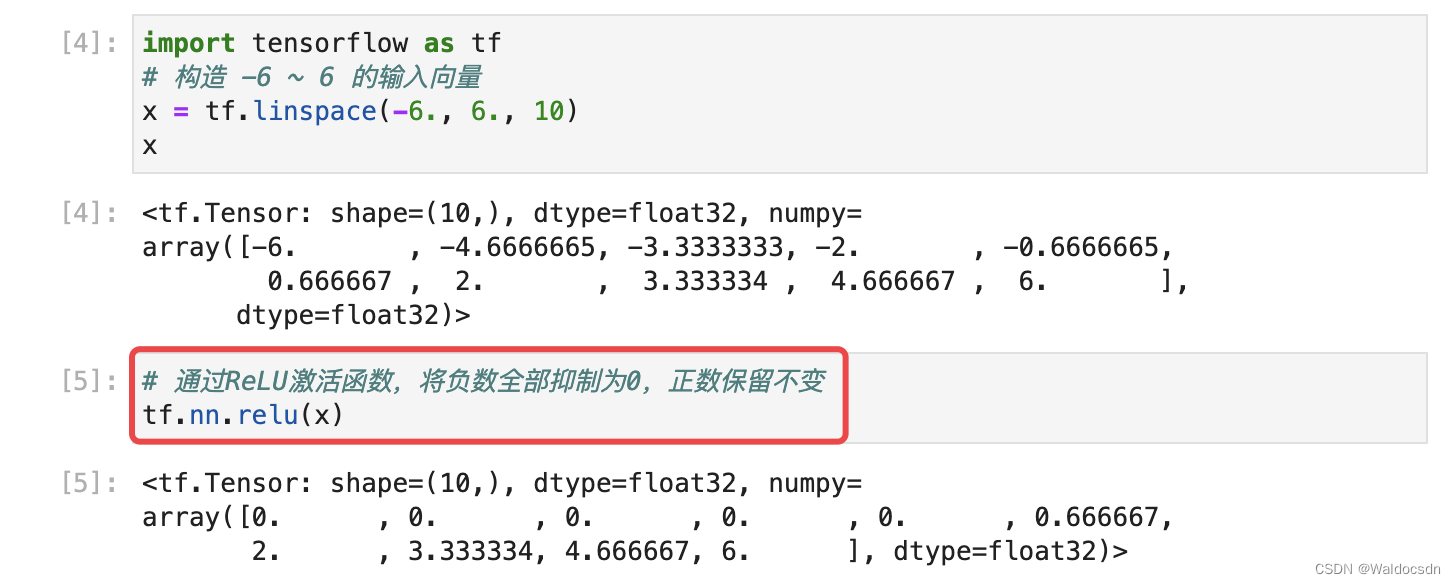
在 TensorFlow 中,可以通过 tf.nn.relu 实现 ReLU 函数,代码如下:
BatchNorm层
BN层用于“参数标准化”,它可以使得输入x的分布相近,并且分布在较小范围内(如0附近),这更有利于函数的优化。(之前文章的代码中除以255也是使得x在0附近) 。通过“堆叠Conv-BN-ReLU-Pooling”方式可以获得不错的模型性能。
在深度学习中,如果设定了合适的权重初始值,则各层的激活值分布会有适当的广度,从而使得“学习”进行地更加顺利。为了使各层拥有适当的广度,使用Batch Normalization可以强制性地调整激活值的分布。
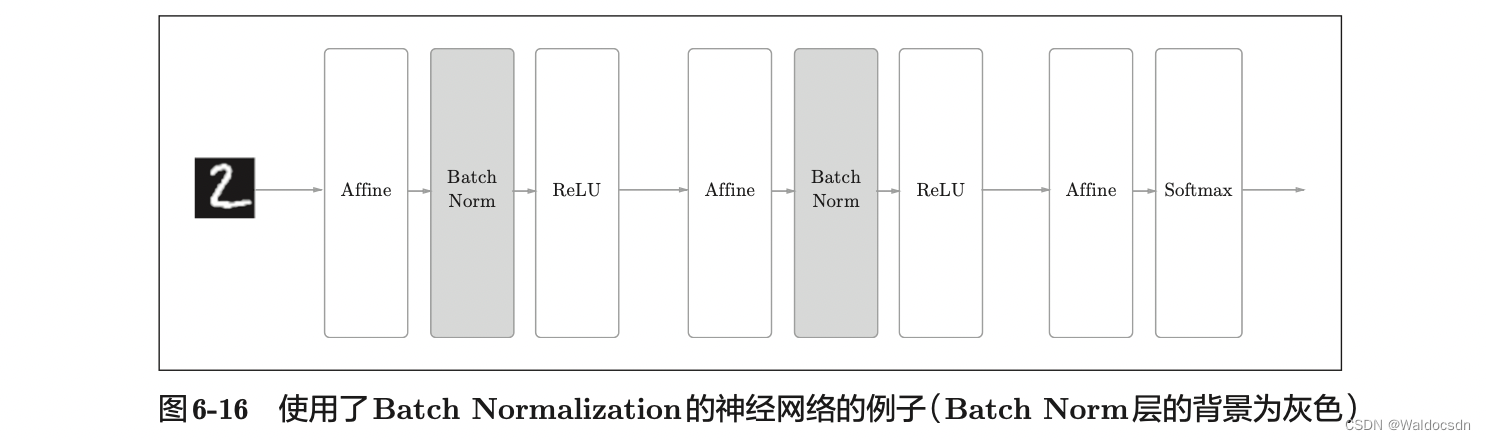
Batch Norm的思路是调整各层的激活值分布使其拥有适当的广度。为此,要向神经网络中插入对数据分布进行正规化的层,即 Batch Normalization层(下文简称Batch Norm层),Batch Norm的正向传播如下图:



下面是一个“参数标准化”受益的例子:
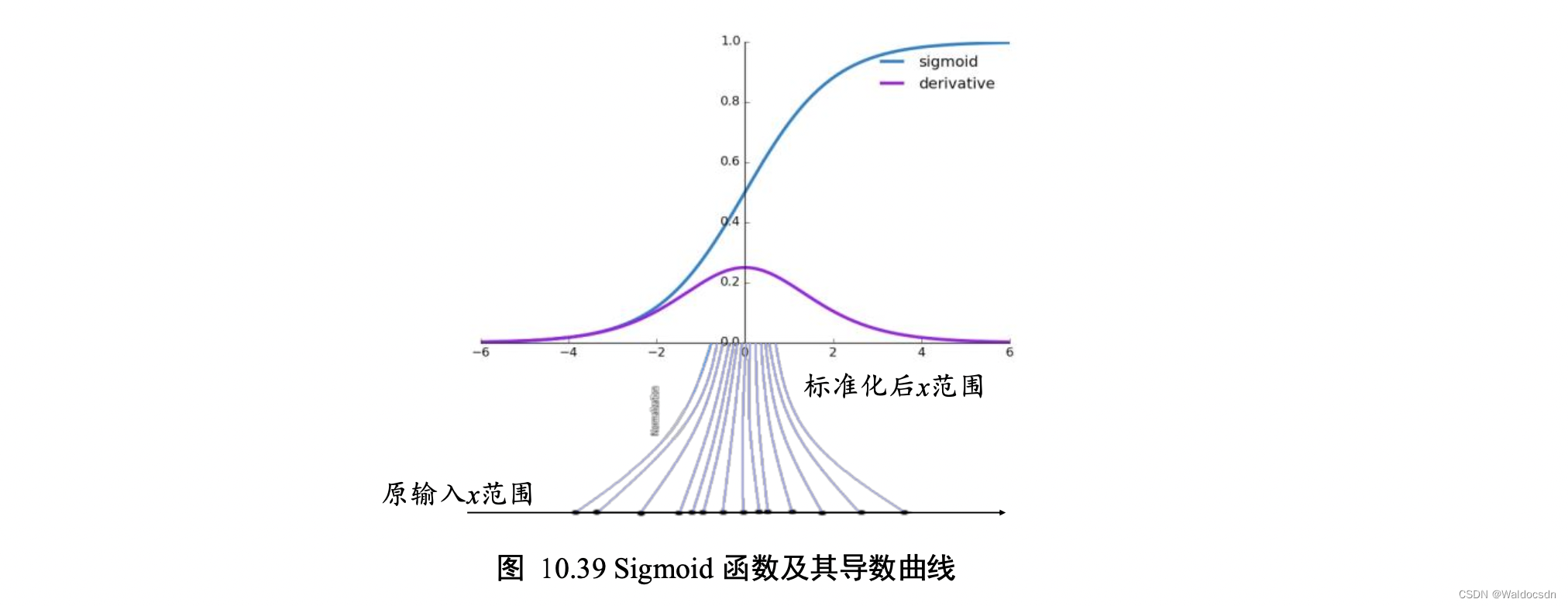
考虑 Sigmoid 激活函数和它的梯度分布,如下图所示,Sigmoid 函数在𝑥 ∈ [−2, 2]区间的导数值在[0.1, 0.25]区间分布;当𝑥>2或𝑥<−2时,Sigmoid函数的导数变得很小,逼近于 0,从而容易出现梯度弥散现象。为了避免因为输入较大或者较小而导致 Sigmoid 函数出现梯度弥散现象,将函数输入𝑥标准化映射到 0 附近的一段较小区间将变得非常重要,可以从图看到,通过标准化重映射后,值被映射在 0 附近,此处的导数值不至于过小,从而不容易出现梯度弥散现象。
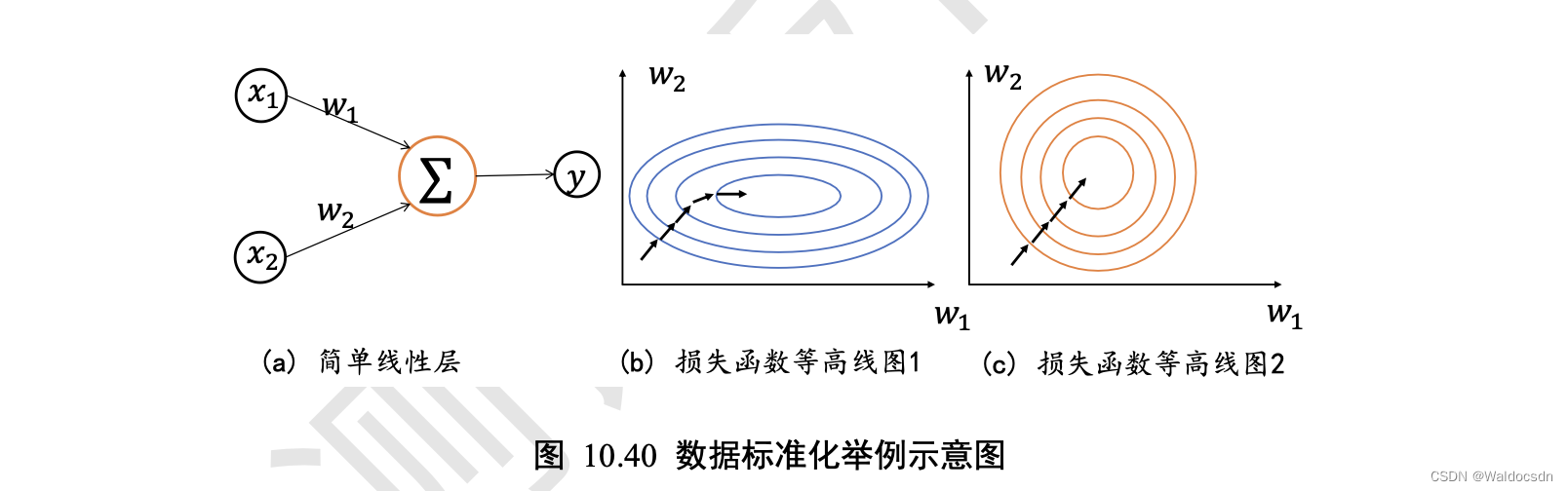
考虑 2 个输入节点的线性模型,如图 10.40(a)所示: L = 𝑎 = 𝑥1*𝑤1 + 𝑥2*𝑤2 + b
讨论如下 2 种输入分布下的优化问题:
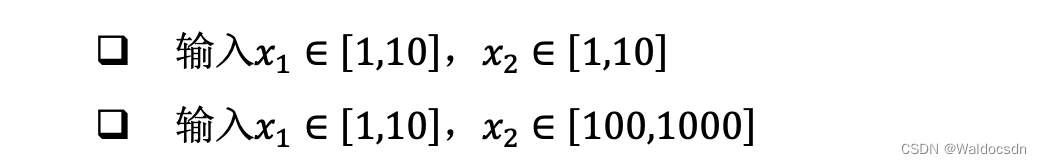
由于模型相对简单,可以绘制出 2 种𝑥1、𝑥2下,函数的损失等高线图,图 10.40(b)是𝑥1 ∈ [1, 10]、𝑥2 ∈ [100, 1000]时的某条优化轨迹线示意,图 10.40( c )是𝑥1 ∈ [1, 10]、𝑥2 ∈ [1, 10]时的某条优化轨迹线示意,图中的圆环中心即为全局极值点。

通过上述的2个例子,我们能够经验性归纳出: 网络层输入𝑥分布相近,并且分布在较小范围内时(如 0 附近),更有利于函数的优化。那么如何保证输入𝑥的分布相近呢? 数据标准化可以实现此目的,通过数据标准化操作可以将数据𝑥映射到𝑥̂:
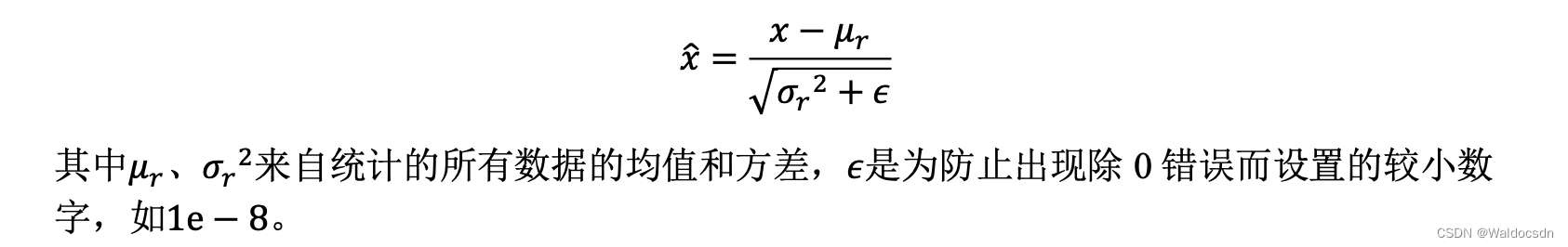
Batch Normalization的评估
现在我们使用 Batch Norm 层进行实验。首先,使用 MNIST 数据集,观察使用Batch Norm层和不使用Batch Norm层时学习的过程会如何变化结果,如图 6-18 所示:

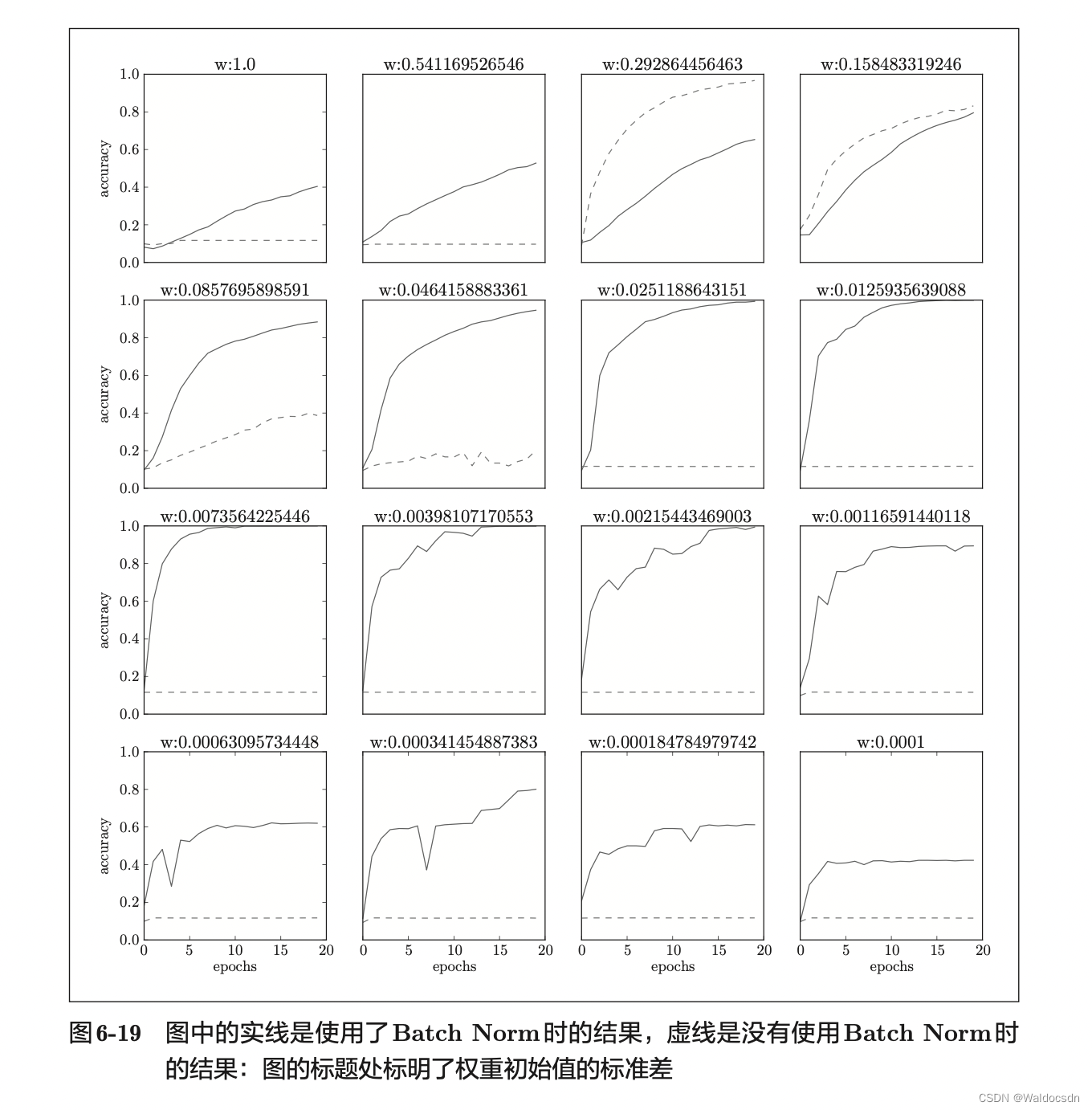
从图6-18的结果可知,使用Batch Norm后,学习进行得更快了。接着, 给予不同的初始值尺度,观察学习的过程如何变化。图 6-19 是权重初始值的标准差为各种不同的值时的学习过程图。
我们发现,几乎所有的情况下都是使用Batch Norm时学习进行得更快。 同时也可以发现,实际上,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。
综上,通过使用Batch Norm,可以推动学习的进行。并且,让权重初始值变得健壮(“对初始值健壮”表示不那么依赖初始值)。
- 注1: BN需要在ReLU之前,这样更好;
- 注2: 超参数是指: 各层的神经元数量、batch大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差
- 注3: 过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态
CIFAR10与VGG13实战
CIFAR10介绍
CIFAR10 数据集由加拿大 Canadian Institute For Advanced Research 发布,它包含了飞机、汽车、鸟、猫等共 10 大类物体的彩色图片,每个种类收集了 6000 张32 × 32大小图片,共 6 万张图片。其中 5 万张作为训练数据集,1 万张作为测试数据集。每个种类样片如下图所示:

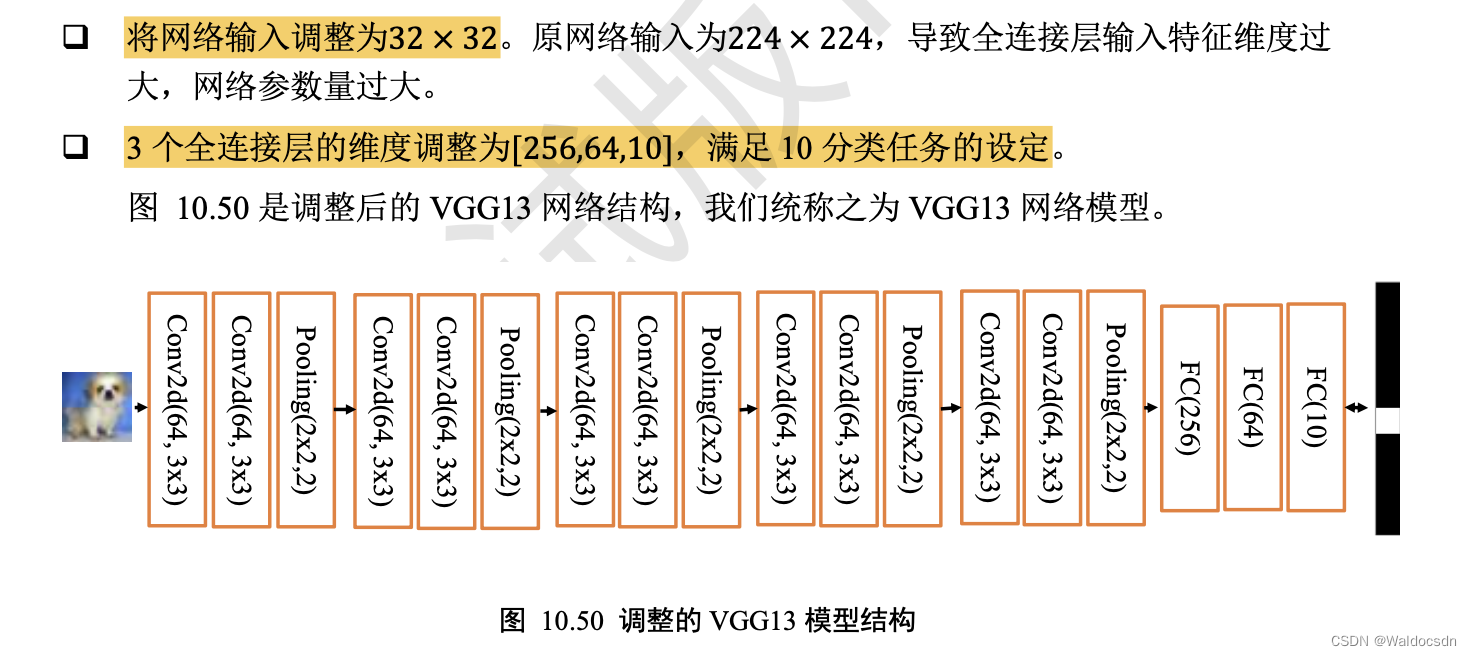
调整的VGG13模型结构
导入各种包
import os # “os”是系统包
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # TensorFlow的最小打印日志的等级为2。
# TensorFlow集成了深度学习环境,每次运行都会显示一些电脑环境信息,设置了这个值,就可以隐藏一些不紧要的输出,更简洁。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, optimizers, datasets, Sequential
# 获取CIFAR10数据集
(x, y), (x_test, y_test) = datasets.cifar10.load_data()
# 打印训练集和测试集的形状
x.shape, y.shape, x_test.shape, y_test.shape
运行截图:
将y(标签)多余的维度压平
删除y的一个维度,[b,1] => [b]
y = tf.squeeze(y, axis=1)
y_test = tf.squeeze(y_test, axis=1)
# 再次打印训练集和测试集的形状
x.shape, y.shape, x_test.shape, y_test.shape
运行截图:
处理数据
def preprocessing(x_data, y_data):
x_data = tf.cast(x_data, dtype=tf.float32) / 255
y_data = tf.cast(y_data, dtype=tf.int32)
return x_data, y_data
# 构建训练集对象,随机打乱,预处理,批量化
train_db = tf.data.Dataset.from_tensor_slices((x, y))
train_db = train_db.shuffle(1000).map(preprocessing).batch(128)
# 构建测试集对象,预处理,批量化
test_db = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_db = test_db.map(preprocessing).batch(128)
# 从训练集中采样一个Batch,并观察
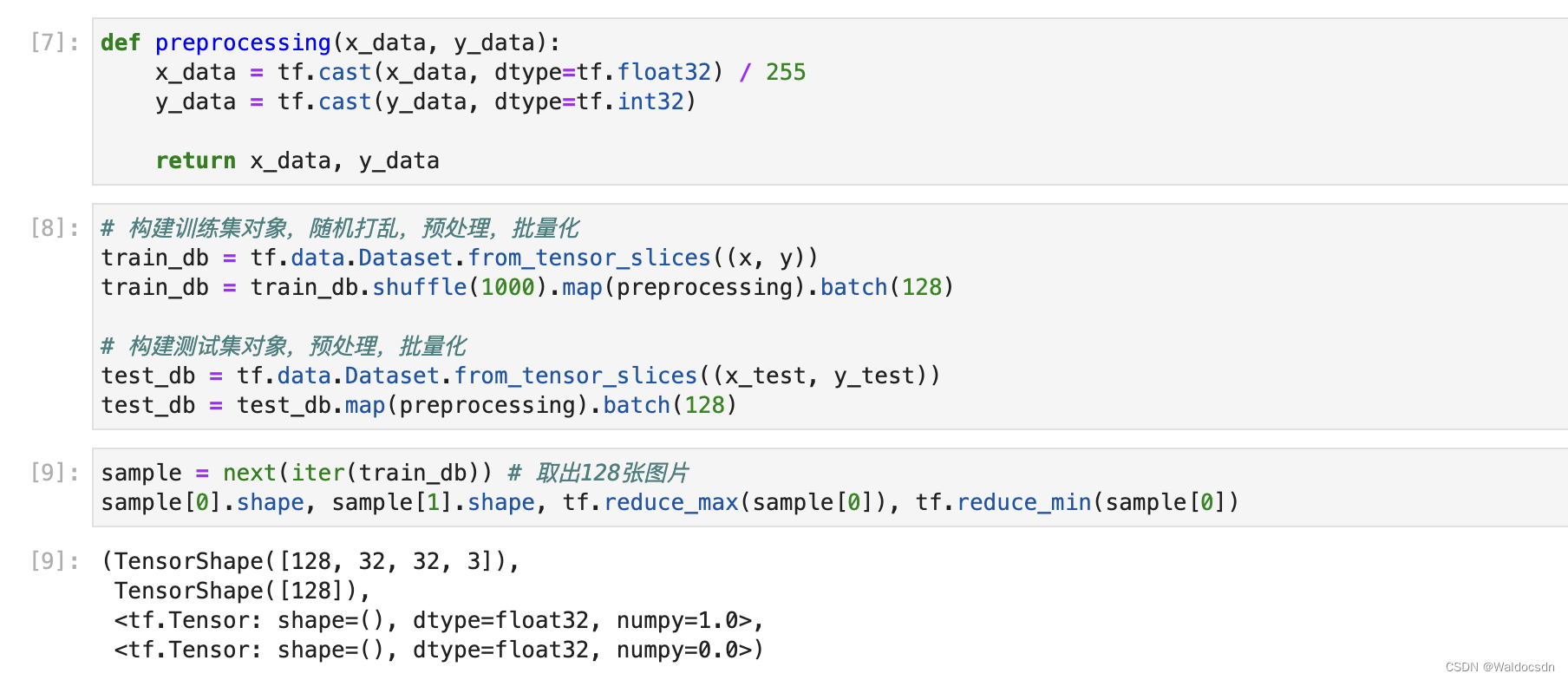
# 这一步务必细致观察,思考
sample = next(iter(train_db)) # 取出128张图片
sample[0].shape, sample[1].shape, tf.reduce_max(sample[0]), tf.reduce_min(sample[0])
运行截图:
构建模型并设置优化器
# 假设卷积层的输入维度是: [None, 32, 32, 3]
# 先创建包含多网络层的列表
conv_layers = [
# # Conv-Conv-Pooling单元1,64个3*3卷积核,高宽大小减半
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 32, 32, 64]
layers.Conv2D(64, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 32, 32, 64]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),#[None, 16, 16, 64]
# Conv-Conv-Pooling单元2,128个3*3卷积核,输出通道提升至128,高宽大小减半
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 16, 16, 128]
layers.Conv2D(128, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 16, 16, 128]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),#[None, 8, 8, 128]
# Conv-Conv-Pooling单元3,256个3*3卷积核,输出通道提升至256,高宽大小减半
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 8, 8, 256]
layers.Conv2D(256, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 8, 8, 256]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),#[None, 4, 4, 256]
# Conv-Conv-Pooling单元4,512个3*3卷积核,输出通道提升至512,高宽大小减半
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 4, 4, 512]
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 4, 4, 512]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),#[None, 2, 2, 512]
# Conv-Conv-Pooling单元5,512个3*3卷积核,输出通道提升至512,高宽大小减半
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 2, 2, 512]
layers.Conv2D(512, kernel_size=[3, 3], padding='same', activation=tf.nn.relu),#[None, 2, 2, 512]
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),#[None, 1, 1, 512]
]
# 利用前面创建的层列表构建网络容器
conv_net = Sequential(conv_layers)
# 全连接子网络包含了 3 个全连接层,每层添加 ReLU 非线性激活函数,最后一层除外。
# 假设全连接层的输入维度是: [None, 512]
fc_net = Sequential([
layers.Dense(256, activation=tf.nn.relu),#[None, 256]
layers.Dense(128, activation=tf.nn.relu),#[None, 128]
layers.Dense(64, activation=tf.nn.relu),#[None, 64]
layers.Dense(10, activation=None),#[None, 10]
])
# 设置优化器
optimizer = optimizers.Adam(learning_rate=1e-4)
build上面2个子网络,并打印网络参数信息
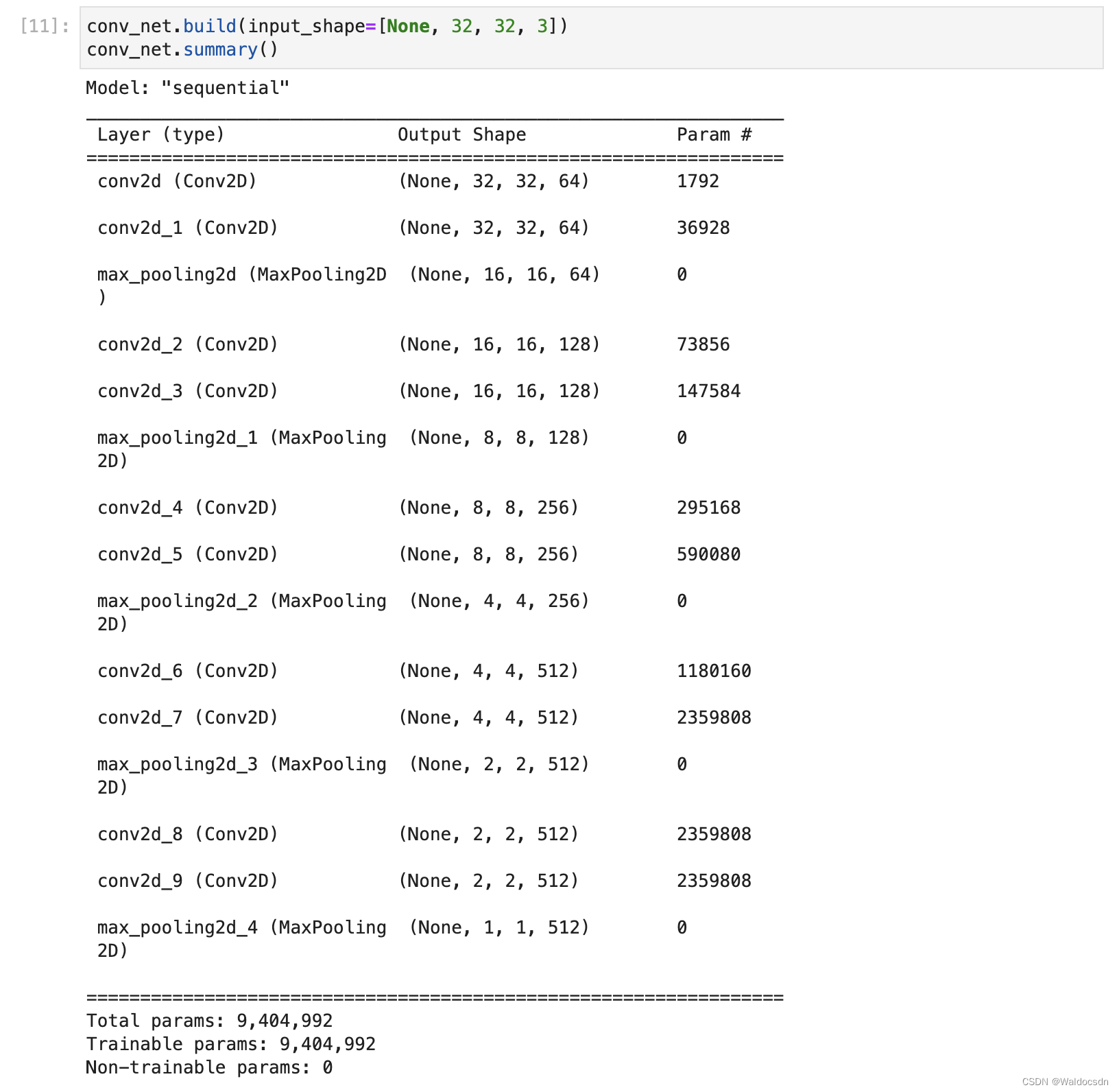
- 查看卷积层参数信息:
conv_net.build(input_shape=[None, 32, 32, 3])
conv_net.summary()
运行截图:
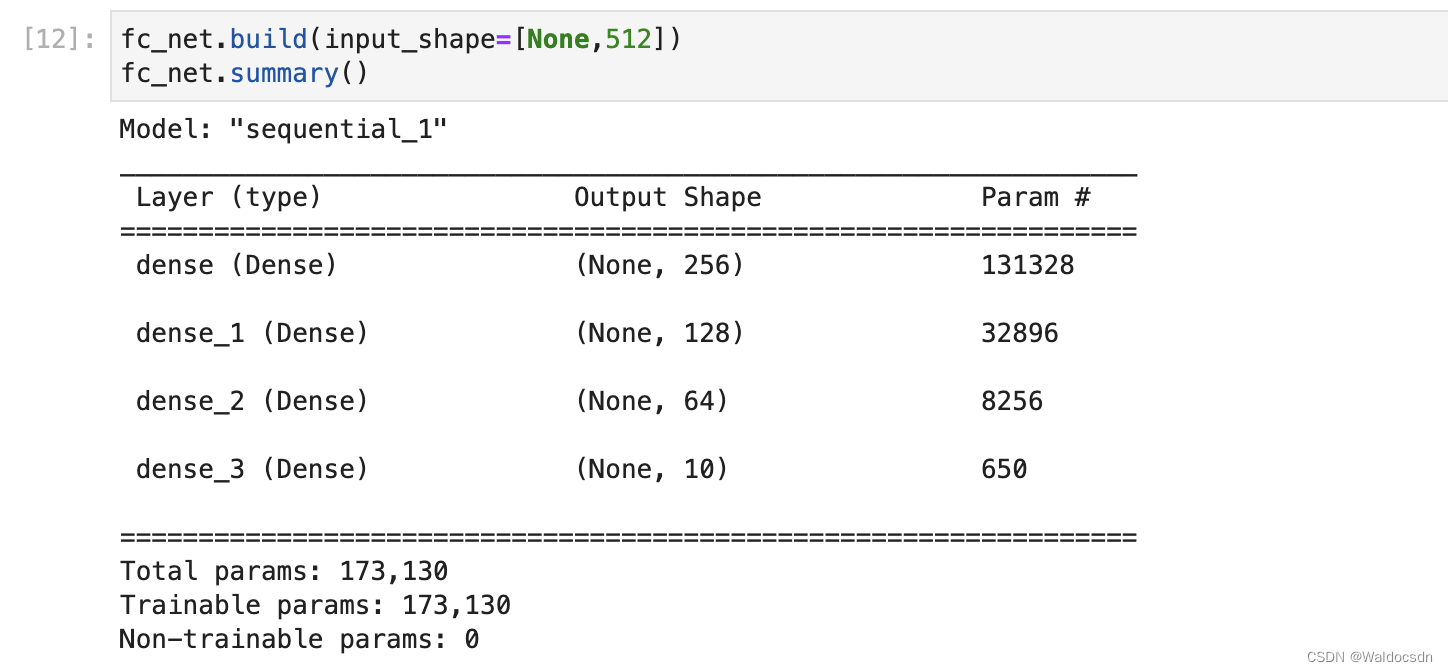
- 查看全连接层参数信息:
fc_net.build(input_shape=[None,512])
fc_net.summary()
运行截图:
合并 2 个子网络的待优化参数列表
由于我们将网络实现为 2 个子网络,在进行梯度更新时,需要合并 2 个子网络的待优化参数列表
# 列表合并,合并2个网络的参数
# variables也是列表
variables = conv_net.trainable_variables + fc_net.trainable_variables
训练模型,计算准确率
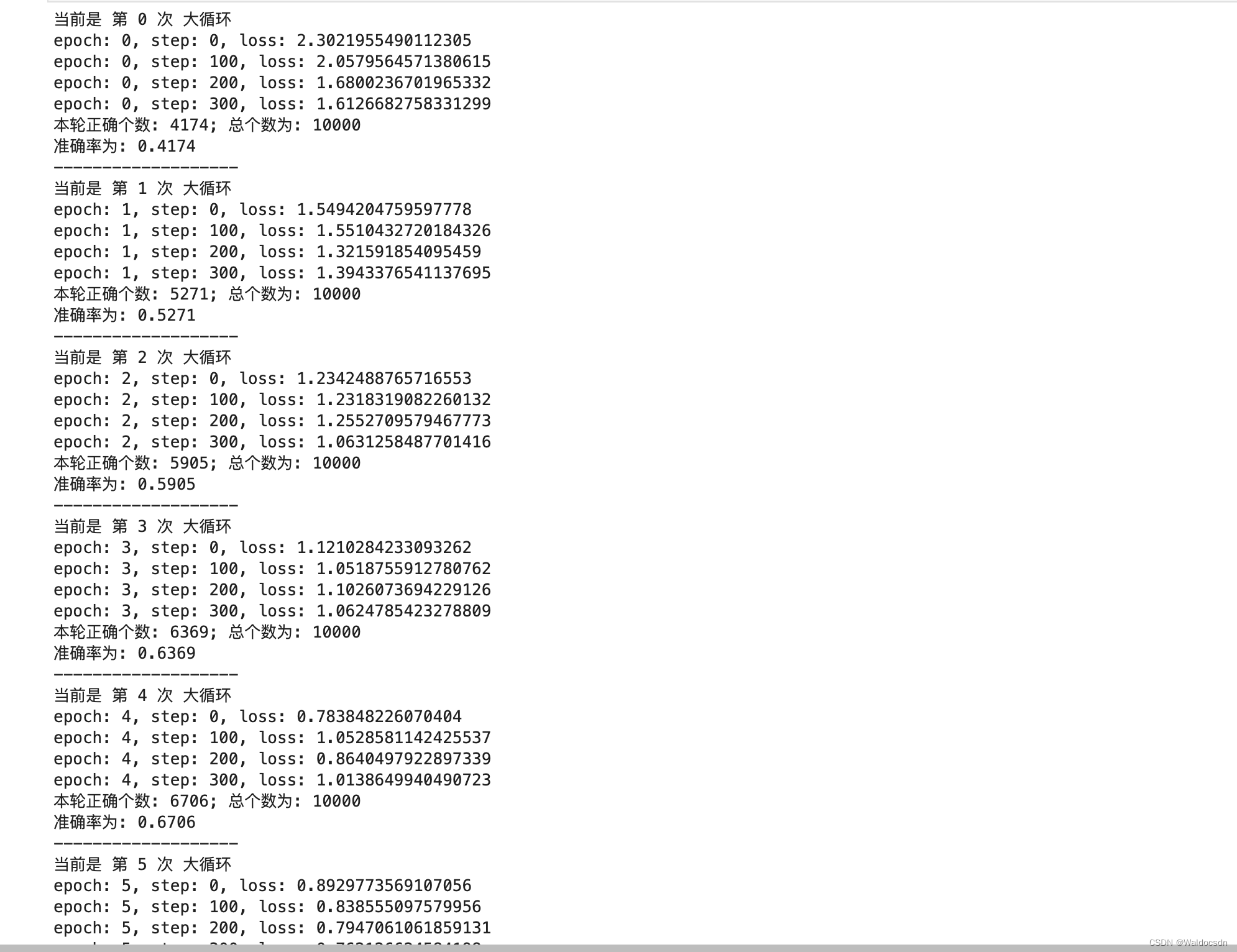
使用训练集训练模型;每个epoch结束后,使用测试集计算当前模型的准确率
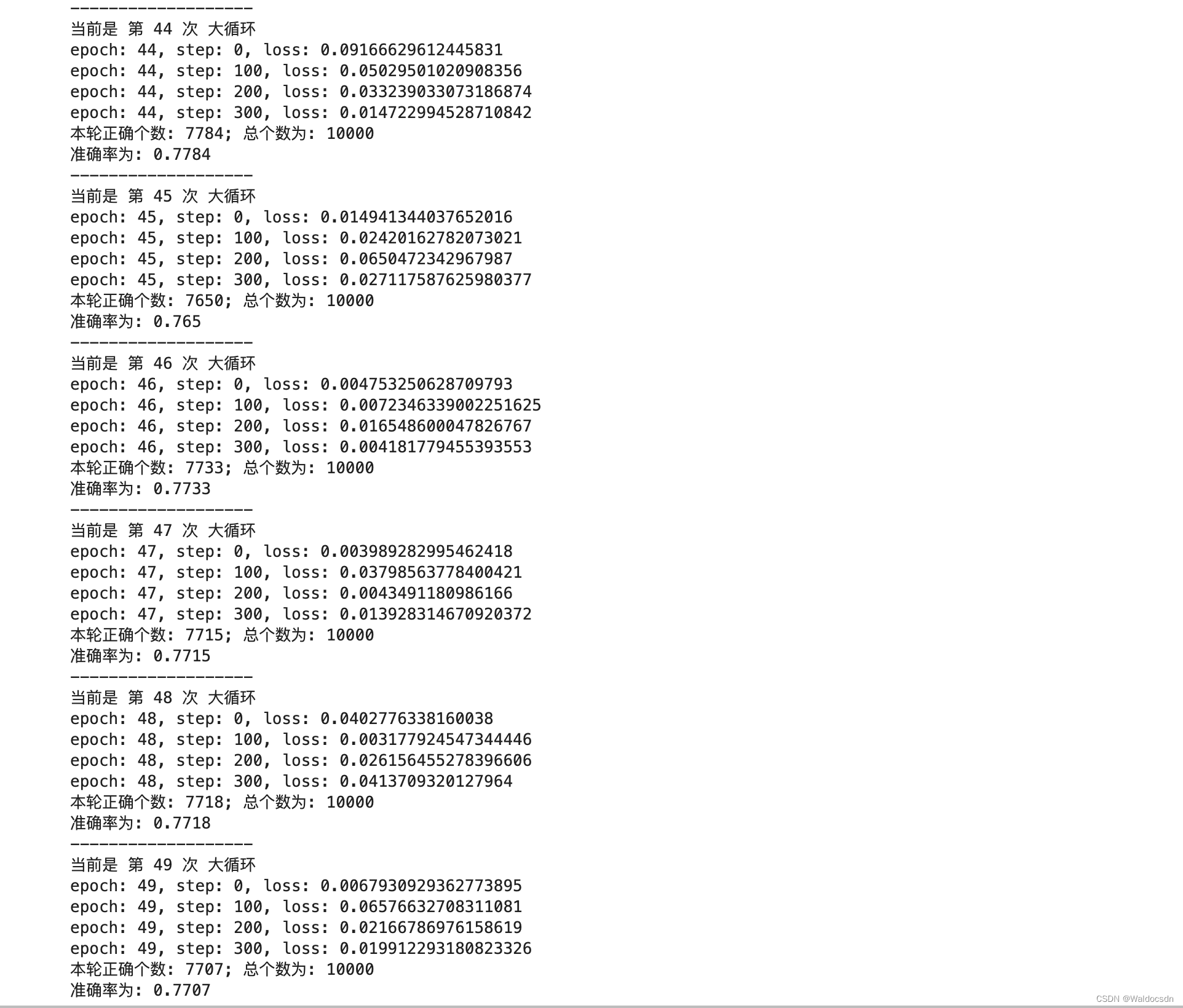
for epoch in range(50):
print(f"当前是 第 {epoch} 次 大循环")
for step, (x, y) in enumerate(train_db):
with tf.GradientTape() as tape:
# x: [b, 32, 32, 3] => [b, 1, 1, 512]
out = conv_net(x)
# x: 在进入全连接线性层之前,将维度打平与全连接层匹配
out = tf.reshape(out, [-1, 512])
# x: [b, 512] => [b, 10]
train_out = fc_net(out)
# y: [b, ] => [b, 10]
y_onehot = tf.one_hot(y, depth=10)
# 多分类常用的一种loss函数
# categorical: 分类;crossentropy: 交叉熵
loss_ce = tf.losses.categorical_crossentropy(y_onehot, train_out, from_logits=True)
loss_ce = tf.reduce_mean(loss_ce) # 计算平均交叉熵损失
# 注意缩进
# 计算梯度,“variables”里面是各个w、b参数,更新参数w、b后也放入其中
# 对所有参数求梯度,grads里面是w、b的梯度
grads = tape.gradient(loss_ce, variables)
# 自动更新梯度 w' = w - learning rate * grad w b' = b - learning rate * grad b
optimizer.apply_gradients(zip(grads, variables))
if step % 100 == 0:
print('epoch: {}, step: {}, loss: {}'.format(epoch, step, float(loss_ce)))
total_correct, total_number = 0, 0
for xval, yval in test_db:
# xtest: [b, 32, 32, 3] => [b, 1, 1, 512]
out2 = conv_net(xval)
# xtest: 在进入全连接线性层之前,将维度打平与全连接层匹配
out2 = tf.reshape(out2, (-1, 512))
# xtest: [b, 512] => [b, 10]
logits_out = fc_net(out2)
# 注意指定axis值
probability = tf.nn.softmax(logits_out, axis=-1)
predict = tf.cast(tf.argmax(probability, axis=-1), dtype=tf.int32)
bool_correct = tf.equal(predict, yval)
num_correct = tf.cast(bool_correct, dtype=tf.int32)
num_correct = tf.reduce_sum(num_correct)
total_correct += num_correct
total_number += yval.shape[0]
print(f"本轮正确个数: {total_correct}; 总个数为: {total_number}")
accuracy = total_correct / total_number
print(f"准确率为: {accuracy}")
print('-------------------')
部分运行截图:
中间略















 1918
1918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









