






VMamba: Visual State Space Model
作者:Yue Liu,Yunjie Tian,Yuzhong Zhao,Hongtian Yu,Lingxi Xie,Yaowei Wang,Qixiang Ye,Yunfan Liu
时间:2024年1月
期刊:ArXiv
摘要:卷积神经网络CNN和ViTs是目前视觉表示学习的主要骨干网络。虽ViT因其拟合能力超过CNN,但其可扩展性受到注意力计算复杂性的限制。受到Mamba有效建模长序列的能力的启发,本文提出VMamba,一个通用的视觉骨干模型,旨在将计算复杂度降低到线性,同时保留ViTs的优势功能。为增强VMamba在处理视觉数据方面的适应性,引入交叉扫描模块(CSM),以实现具有全局感受野的2D图像空间中的1D选择性扫描。此外,对细节和架构设计方面做了进一步的改进,以提高VMamba的性能和推理速度。
介绍:视觉表示学习是计算机视觉中最基础的研究课题之一,自深度学习时代开始以来,视觉表示学习取得了重大突破。卷积神经网络(Convolution Neural Networks, CNNs)[38,19,22,29,42]和视觉变形器(Vision transformer, ViTs)这两类主要的深度基础模型已被广泛应用于各种视觉任务中。虽然两者在计算表达性视觉表示方面都取得了显著的成功,但ViTs通常比CNNs表现出更好的性能,这可以归因于注意力机制促进的全局感受野和动态权重。
然而,在图像大小方面,注意力机制需要二次复杂度,因此在处理下游密集的预测任务时,如目标检测、语义分割等,会导致昂贵的计算开销。为了解决这个问题,大量的工作已经致力于通过限制计算窗口的大小或步长来提高注意的效率,尽管代价是限制感受野的规模。这促使我们设计一个具有线性复杂度的新的视觉基础模型,同时仍然保留与全局感受野和动态权重相关的优势。
从最近提出的状态空间模型中汲取灵感,文章引入了视觉状态空间模型(被称为VMamba)来进行有效的视觉表示学习。VMamba在有效降低注意力复杂性方面的成功背后的关键概念继承自选择性扫描空间状态顺序模型(S6),该模型最初设计用于处理自然语言处理(NLP)任务。与传统的注意计算方法不同,S6使一维数组(如文本序列)中的每个元素都可以通过压缩的隐藏状态与之前扫描的任意样本进行交互,有效地将二次复杂度降为线性。
然而,由于视觉数据的非因果性质,直接将这种策略应用于一个补丁化(patchified)、平面化的图像将不可避免地导致感受野受限,因为无法估计与未扫描补丁的关系。我们将这个问题称为“方向敏感”问题,并建议通过新引入的跨扫描模块(CSM)来解决这个问题。CSM并不是单向地(纵向或纵向)遍历图像特征图的空间域,而是采用四向扫描策略,即从整个特征图的四个角向相反位置扫描(如图2 (b)所示)。该策略保证了特征图中的每个元素在不同方向上整合了所有其他位置的信息,从而在不增加线性计算复杂度的情况下呈现出全局的感受野。

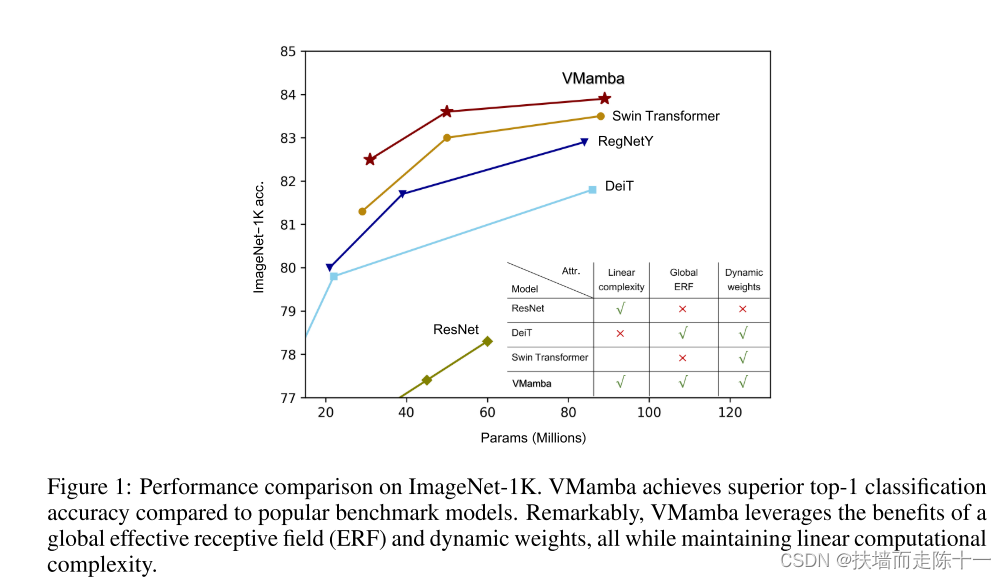
在不同的视觉任务上进行了大量的实验来验证VMamba的有效性。如图1所示,与包括Resnet[19]、ViT[10]和Swin[28] 1在内的基准视觉模型相比,VMamba模型在ImageNet-1K上显示出更好的或至少具有竞争力的性能。文章还报告了下游密集预测任务的结果。例如VMambaTiny/Small/Base(分别具有22/44/75 M参数)使用MaskRCNN检测器(1×训练计划)在COCO上实现了46.5%/48.2%/48.5%的mAP,使用512 × 512输入的UperNet在ADE20K上实现了47.3%/49.5%/50.0%的mIoU,展现了其作为一个强大的基础模型的潜力。此外,当使用更大的图像作为输入时,ViT的FLOPs比CNN模型的FLOPs增加得更快,尽管通常仍然表现出更好的性能。然而,有趣的是VMamba本质上是一个基于Transformer架构的基础模型,它能够在FLOPs稳步增加的情况下获得与ViT相当的性能。
文章总结这些贡献如下:
•我们提出了VMamba,一个具有全局感受野和动态权值的视觉状态空间模型,用于视觉表示学习。VMamba为视觉基础模型提供了一种新的选择,它超越了现有的CNNs和ViTs选择。
•引入了交叉扫描模块(CSM),弥补了一维阵列扫描和二维平面遍历之间的差距,在不影响感受野的情况下,促进了S6向视觉数据的扩展。
•在没有弄虚作假的情况下,我们表明VMamba在各种视觉任务中,包括图像分类、对象检测和语义分割,都能取得很好的结果。这些发现强调了VMamba作为一个鲁棒的视觉基础模型的潜力。
方法实现:
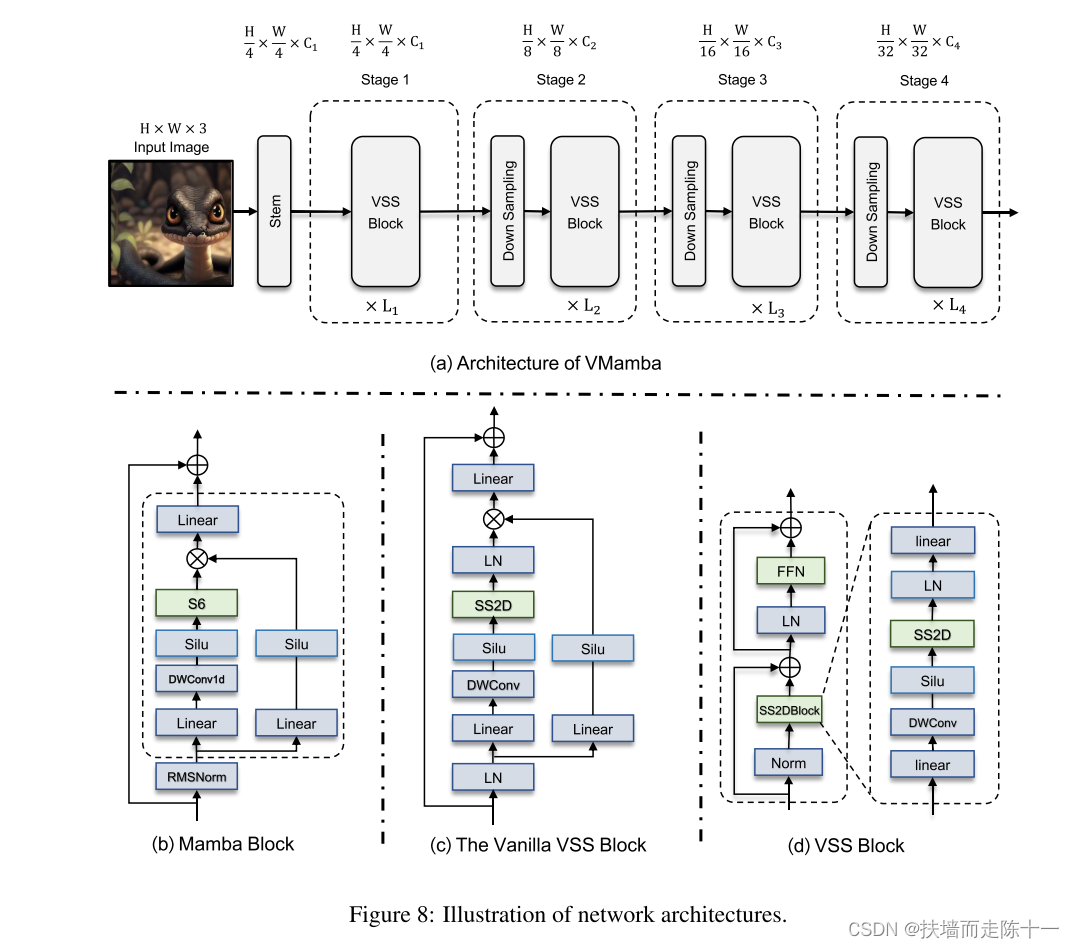
VMamba首先使用stem模块将输入图像划分为补丁,从而生成空间维度为H/4 × W/4的2D特征图。随后,多个网络阶段,每个阶段由VSS块组成,前面是下采样层(第一阶段除外),用于创建分辨率为H/8 × W/8,H/16 × W/16和H/32 × W/32的分层表示。通过补丁合并执行下采样操作,VSS块的详细结构如图8(b)所示。
Vanilla VSS Block: 两个分支:一个用于使用3 × 3深度方向卷积层的特征提取,另一个由线性映射和随后的激活层组成,激活层计算乘法门控信号。Mamba和vanilla VSS模块之间的主要区别是用SS2D模块取代了S6模块,这使得选择性扫描能够适应2D视觉数据。值得注意的是,虽然位置嵌入偏差是基于视觉变换器的模型中的常见做法,但由于SS2D中选择性扫描的顺序性质,我们避免使用它。此外,vanilla VSS块的架构设计也与视觉Transformer块的架构设计不同,视觉transformer块通常遵循Norm → attention → Norm → MLP例程(vanilla VSS块中没有MLP层)。因此,该版本的VSS块比ViT块浅,使我们能够在总模型深度的类似预算内堆叠更多块。
Accelerating VMamba:
尽管它们在长序列建模中效率很高,但基于SSM的架构[14]在处理较小规模的输入时经常遇到计算速度降低的问题,这可能会限制VMamba的实际效用。在本小节中,我们将介绍我们如何提高VMamba的吞吐量,在224 × 224的输入分辨率下将其从400张图像/秒提高到1,336张图像/秒,而不会显著牺牲性能。如图9所示,第4节(V01)中提出的vanilla VMamba-Tiny模型实现了426张图像/s的吞吐量,包括22.9M参数和5.6G FLOP(如果选择性扫描操作可以通过单个for循环实现,则FLOP将降至4.5G)。低吞吐量和高内存开销给VMamba的实际部署带来了挑战。因此,为了提高其推理速度,已经做出了重大努力,主要集中在实现细节和架构设计方面的进步。
在ImageNet-1k数据集评估分类性能:
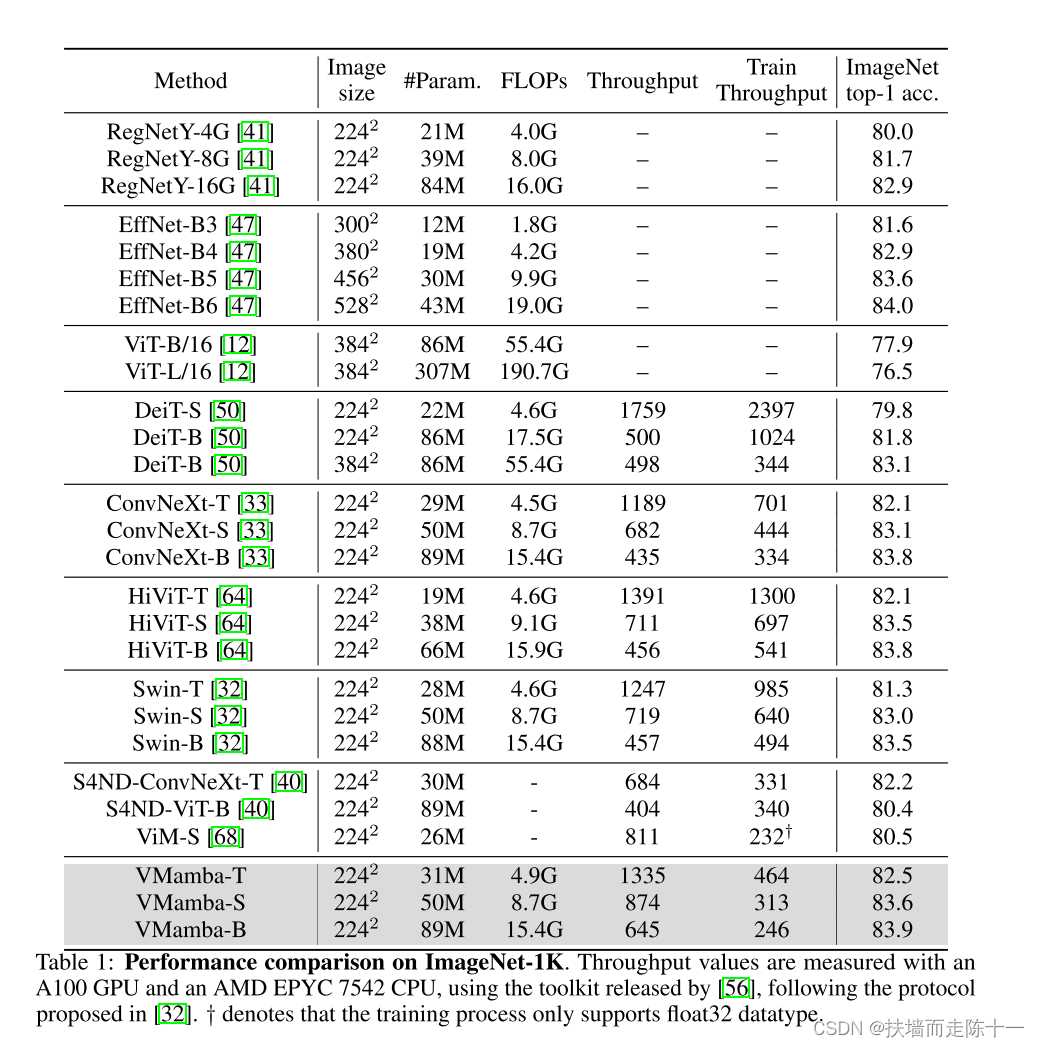
结论:文章提出的VMamba模型相较于Vits,CNN方法都有所提升,在对比实验中,文章分类性能,目标检测,语义分割等性能表现良好。















 3491
3491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









