







CDF(cumulative distribution function)叫做累积分布函数,描述一个实数随机变量X的概率分布,是概率密度函数的积分。它的最主要作用就是观测某些数值也就是随机变量的取值在那个附近出现的概率比较大,它是一个增函数. 可以有效的处理一些异常值.随机变量小于或者等于某个数值的概率P(X<=x),即:F(x) = P(X<=x) 。累积分布函数(cumulative distribution function):对连续函数,所有小于等于a的值,其出现概率的和。F(a)=P(x<=a)
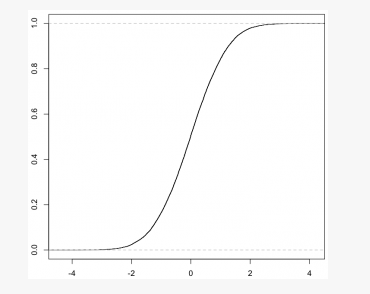
根据这张累积分布函数图,可以很方便地回答之前的两个问题:1)CDF中横轴上的2对应的Y值约为0.98,因此所有大于2的数据点所占比例约为2%。 2)CDF中横轴上的1.3对应的Y值约为0.75,因此所有介于1.3和2之间的数据点所占比例约为23% (0.98-0.75)。
与直方图、核密度估计相比,累积分布函数存在以下几个特点:
累积分布函数是X轴单调递增函数。
累积分布函数更加平滑,图像中噪音更小。
累积分布函数没有引入带宽等外部概念,因此不会丢失任何数据信息。对于给定的数据集,累积分布函数是唯一的。
累积分布函数一般都经过归一化处理,单调递增且趋近于1。
现在我们就是要用这个数据画一组CDF图像.
%read data into matirx
%http function
fid = fopen('./test.csv','rt'); %首先打开文件把数据读取出来
C = textscan(fid, '%f %f %f', 'Delimiter',',');
fcolse(fid); %之后把数据扫描进C这个变量中,我们是按照浮点类型的形式来处理我们的数据的
%由于我们的数据有三列,所有我们这里取了三个%f出来,根据不同的数据我们取不同的格式说明符号.可以用类似C语言.每个数据之间是按照","来做分割.
%Delimiter表示的是取某些分割符来切分数据,再后面我们写逗号,表示按照逗号来分割数据
data1 = deal(C{1});
% 每一列数据表示的一次随机实验中取到的随机变量,所以我们分别处理这三组数据,以此类推.
data2 = deal(C{2});
data3 = deal(C{3});
cdfplot(data1);% 在matlab中画图我们使用cdfplot,这个命令
set(h1,'color','b','LineWith',3);
xlabel('NUmbers of Http Pings','FontSize',30);
ylabel('CDF','FontSize',30);
title('')通信的魅力就是在于随机性中蕴含的确定性,这也就是为什么你随便拿出一本通信方面的教材,前面几章都会大篇幅的讲解随机过程,随机过程也是研究生必须深入了解的一门课,特别是对于信号处理以及通信专业的学生。
在实际工作中,通常会得到很多随机的数,我们要分析它们的分布,最常见的就是用PDF和CDF来描述了。好了,还是举出一个具体例子吧。

那么实际中我们要验证是不是符合这样的分布,首先看代码再解释:
close all;
clear all;
N = 100000;
x = randn(1,N);
y = randn(1,N);
r = sqrt(0.5*(x.^2 + y.^2));%每个分量的方差为0.5
step = 0.1;
range = 0:step:3;
h = hist(r,range);
pr_approx_pdf = h/(step*sum(h));
pr_theory = (range/0.5).*exp(-range.^2); %0.5即为方差
figure(1)
plot(range,pr_approx_pdf,'ro',range,pr_theory,'gs-');
hold on
plot(range,raylpdf(range,sqrt(0.5)),'bd') %用matlab自带函数同样能生成理论曲线。
xlabel('z'),ylabel('PDF'),title('The PDF of Rayleigh distribution')
legend('pr\_approx\_pdf','pr\_theory','pr\_theory\_matlab')
grid;
pr_approx_cdf = cumsum(h)/(sum(h));
figure(2)
plot(range,raylcdf(range,sqrt(0.5))),hold on
plot(range,pr_approx_cdf,'rs','LineWidth',2)
xlabel('z'),ylabel('CDF'),title('The CDF of Rayleigh distribution')
legend('pr\_theory\_matlab','pr\_approx\_cdf','Location','Best') 

简单解释:我们用到了hist()函数来求结果,其实hist就是直方图,小学都开始使用的计算概率的方法。hist结果是落入每个区间的个数,所以有如下的等式:
PDF=n/(n_total*step),表示了单位长度内的概率大小,而这就是概率密度!同样,在求CDF的过程中,我们要求的是Pr(x<=X)的概率,所以我们就用了累积加函数cumsum()来获得一个累积分布,然后在除以总个数,就得到了累积概率分布。
CDF示例代码:cdf.m
function [xTime,yPercentage]=cdf(initValue,step,endValue,sample);
xTime=[];
yPercentage=[];
totalNum=length(sample);
for i=initValue:step:endValue
temp=length(find(sample<=i))/totalNum;
xTime=[xTime,i];
yPercentage=[yPercentage,temp];
end
clear;
initValue=0;
step=0.1;
sample1=[0.7,1.2,1.5,2.0,1.3,1.7,2.2,2.5,3.6];
sample2=[0.8,1.1,1.4,2.1,1.2,1.8,2.1,2.4,3.7,4.2,5.4];
endValue1=ceil(max(sample1));
endValue2=ceil(max(sample2));
endValue=max(endValue1,endValue2);
[xTime1,yPercentage1]=cdf(initValue,step,endValue,sample1);
[xTime2,yPercentage2]=cdf(initValue,step,endValue,sample2);
plot(xTime1,yPercentage1,'r');
hold on
plot(xTime2,yPercentage2,'g');
ylabel('F(x)')
xlabel('Example(exp)')
legend('曲线1','曲线2');
title('Title');clc
close all
clear all
a=randn(1,100000);
maxa=max(a) %最大值
mina=min(a) %最小值
size(a) %尺寸
b=linspace(mina,maxa,100); %分为99个区间
a=sort(a); %将a排列
s=1;
k=1;
n=zeros(1,99);
for i=1:100-1
for s=1:length(a)
if a(s)>=b(i)&a(s)<=b(i+1)
n(i)=n(i)+1;
s=s+1;
end
end
end
sum(n) %检验是否总数不变;
b=b(1:100-1);
plot(b,n,'go');
xlabel('区间');
ylabel('分布数');
















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









