







 本文探讨了在选择开源模型时应关注社区活跃度、模型参数规模和量化技术的重要性,以LLama2和通义千问为例,强调了参数大小与效果的关系,并介绍了如何在内存限制下利用量化和Langchain框架。
本文探讨了在选择开源模型时应关注社区活跃度、模型参数规模和量化技术的重要性,以LLama2和通义千问为例,强调了参数大小与效果的关系,并介绍了如何在内存限制下利用量化和Langchain框架。
原则1:选择开源技术主要看社区和支持
与其他开源技术一样,我们应该最关注的两个指标是社区活跃度(星级数)和其背后的组织。
对比核心的几个开源模型:
| 模型 | 参数规模(B) | 星星数(k) | 组织 | 国家 |
|---|---|---|---|---|
| LLama2 | 7,13,34,70 | 52.1 | Meta | 美国 |
| Mistral 7B | 7 | 8.5 | Mistral AI | 法国 |
| 通义千问Qwen | 1.8,7,14,72 | 10.5 | 阿里巴巴 | 中国 |
| ChatGLM-6B | 6 | 11.6 | 智谱AI | 中国 |
以上数据截止至2024年04月10日,仅代表个人使用经验。后续我会进行一些简单的评测,如果有其他模型你们想了解的,也可以私信我。
通过以上的比较,我认为LLama2和通义千问Qwen绝对是开源模型界的领导者。无论是社区活跃度,参数规模支持程度,还是更新频率,这两个模型都领先于其他的开源模型。我建议大家在学习和研究的时候选择这两个模型。
参考资料:
https://github.com/wgwang/awesome-LLMs-In-China?tab=readme-ov-file
https://github.com/eugeneyan/open-llms
https://chat.lmsys.org/?leaderboard
原则2:选7B还是70B?参数越大,效果越好
-
不同参数规模模型效果对比
我们来看一下,对于同一个问题,在同一个模型下不同参数规模的回答效果如何。
我们选择了通义千问模型,从左到右依次是4B模型,7B模型,72B模型。
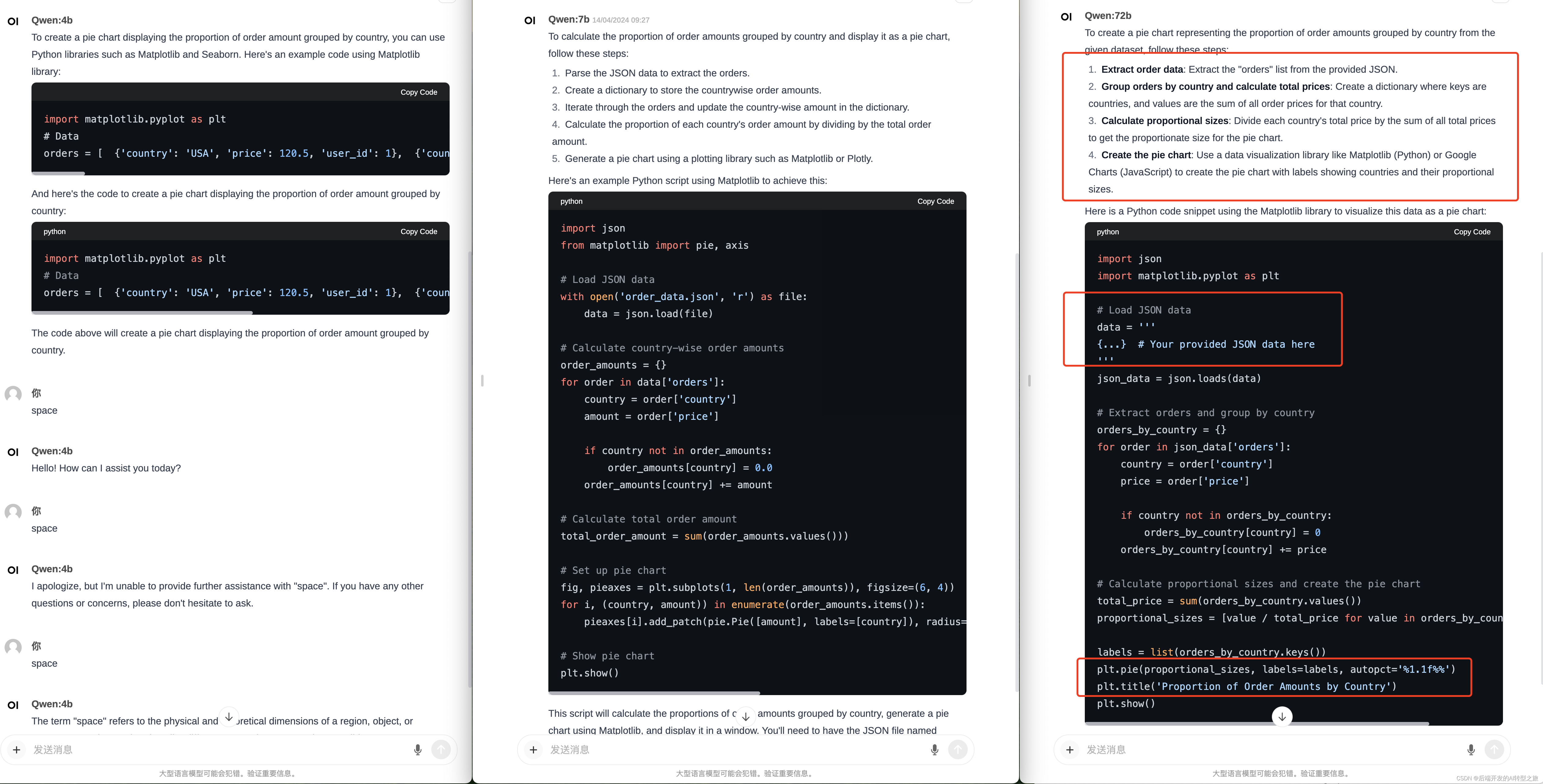
比较可以看出,4B模型未能给出答案,而7B模型提供了步骤说明和代码。72B模型不仅给出了步骤说明和代码,而且其步骤更具结构化,标题加粗,使用分号等,使人更容易理解。它给出的代码也更优秀,首先在数据部分采用了类似占位符的形式,便于我们填充。其次,它在饼图上提供了标题和数据格式化。
通过比较,我们可以得出这样的结论:对于同一个模型,参数越大,模型的效果通常越好。
那么,对于不同模型呢?会出现越级的情况吗?文章结尾有彩蛋
当然,越大规模的参数,对内存需求越大。
-
内存不够怎么办
模型参数的规模与内存(实际上指的是显存)强烈相关,模型的参数需全部加载到内存中才能进行推理。简单地说,1B参数大约需要4GB,那么7B的模型需要28G的内存,70B的模型则需要280G的内存。算下来,24G内存的4090显卡都甚至无法运行7B的模型,这还如何玩!
先别急,内存问题可以通过模型量化来解决。量化是通过降低参数的精度来减少对内存的需求。量化后的7B模型仅需3.8G,足以轻松在任何一台PC上运行。
从Ollama支持的模型库中可以看出,大型模型在量化后对内存的需求,如下表:
模型 参数 对内存需求 LLama2 7B 7B 3.8G LLama2 13B 13B 7.3G LLama2 70B 70B 39G 但是,量化也会带来新的问题,不同程度的参数精度损失会增加模型的困惑度(俗称:变傻)。因此,我们需要找到一个平衡,选择最经济且最可用的量化后的模型。
我们可以在HuggingFace上找到量化模型,一般开源模型都会说明量化后的困惑度,并推荐大家选择合适的量化模型。如果你对此感兴趣,可以跳到附录查看
-
没有显卡怎么办
感谢万能的Docker,借助Ollama的Docker镜像,我们可以轻松地在CPU上运行应用程序,无需进行任何复杂的配置。即使没有高端显卡,我们也无需担心。
亲测,在Macbook Air M1上使用docker运行,如下图:
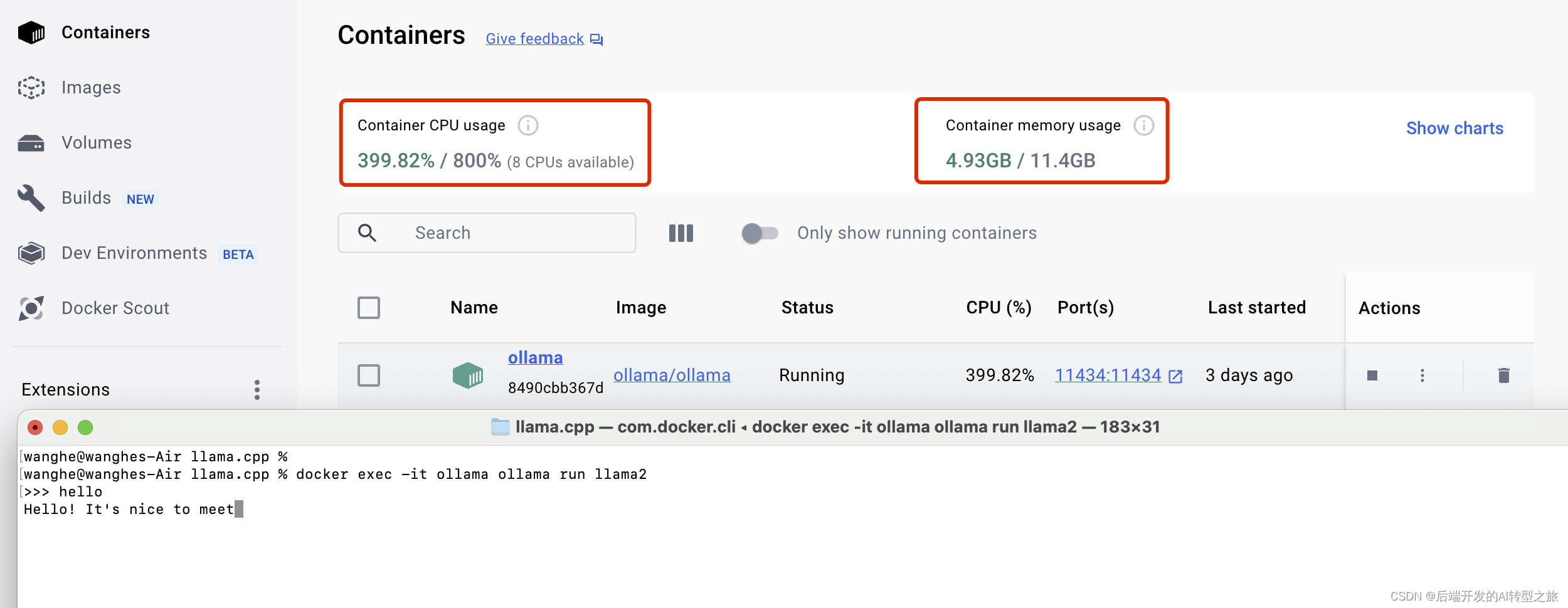
参考地址:https://ollama.com/blog/ollama-is-now-available-as-an-official-docker-image
原则3:在推理速度可用的情况下,优先考虑参数规模
-
推理速度达到多少算可用
Reddit上的一项调研。多数人认为7-10 Token/s是一种可用的速度。这个速度大概等于每秒5-7.5个单词,因为一般来说,1个单词等于1.3个Token。我认为10 Token/s是一个可用的临界点。然而,也有一些人持极端观点,他们认为每秒1个Token也是可以接受的。这个讨论非常有趣,有兴趣的人可以去看看。

Reddit关于Token速度的讨论:https://www.reddit.com/r/LocalLLaMA/comments/162pgx9/what_do_yall_consider_acceptable_tokens_per/
-
使用llama.cpp测试模型的推理速度
笔者用两台电脑测试,配置如下:
- MacBook Air:16G内存,M1芯片
- Mac Studio:128G内存,M1 ultra芯片,性能≈英伟达3090
测试结果如下:
电脑 模型参数 Token MacBook Air 4B 19.9 T/s MacBook Air 7B 12.5 T/s Mac Studio 4B 83.6 T/s Mac Studio 7B 71.2 T/s Mac Studio 70B 13.7 T/s
从测试结果来看,16G内存的MacBook Air能够轻松运行7B模型。而对于Mac Studio,它足以应对市场上的任何一个开源模型
原则4:模型专用,不同需求选择不同类别的模型
-
选择对应语种的模型
在中文环境下,建议选择国内的模型,而不是国外的中文版本。目前,支持中文的模型较少。如果对应的模型不支持中文,一种建议的方法是把问题翻译成英文进行提问,获取答案后再将答案翻译成中文。当然,如果你的英文能力强,可以忽略这个建议。从目前的情况来看,中文大模型的整体效果不如英文模型,这一方面是因为训练语料相对较少;另一方面,中文的复杂性较高,想要取的更好的效果比较困难。
-
选择专用模型
一般用途选择通用模型,聊天用途选择Chat模型,编码等用途选择专用模型。不同的模型训练的语料是不同的,各有其优势。根据用途选择对应的模型,可以达到最好的效果。
原则5:要考虑模型的可扩展性
在考虑扩展性时,我们需要考虑两个方面:运行环境的适应性和有没有优秀的应用框架。
-
运行环境的适配性
Ollama是一个优秀的开源项目,提供模型基座,屏蔽环境差异,可以在Windows、MacOS、Linux上运行,甚至可以在无GPU的情况下,仅用CPU运行。
Ollama支持服务器端,通过使用Rest API接口,向外部提供统一的大模型服务。这些接口使上层应用可以轻松接入,极大地提高了系统的可用性。
目前,Ollama支持的模型众多,主流的开源模型都可以在Ollama库中找到。此外,Ollama还支持自定义模型。你可以从HuggingFace上下载更多模型,然后加载到Ollama中,这使得Ollama的应用更加丰富。
!https://prod-files-secure.s3.us-west-2.amazonaws.com/6cdb6123-fe4f-4c2d-888c-dcc64931d8b1/dbdfb663-a517-4f2c-a691-9a9372a11397/Untitled.png
Ollama模型库:https://ollama.com/library
-
是否支持优秀的应用框架
目前最优秀的应用框架就是Langchain,后面我们会单独介绍Langchain。好消息是Langchain支持了Ollama,这意味着只要Ollama提供支持的模型,Langchain就可以支持。以下是Langchain集成Ollama的示例
# LangChain supports many other chat models. Here, we're using Ollama from langchain_community.chat_models import ChatOllama from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate # supports many more optional parameters. Hover on your `ChatOllama(...)` # class to view the latest available supported parameters llm = ChatOllama(model="llama2") prompt = ChatPromptTemplate.from_template("Tell me a short joke about {topic}") # using LangChain Expressive Language chain syntax # learn more about the LCEL on # /docs/expression_language/why chain = prompt | llm | StrOutputParser() # for brevity, response is printed in terminal # You can use LangServe to deploy your application for # production print(chain.invoke({"topic": "Space travel"}))从代码中,我们可以看出,Langchain支持Ollama的调用。
参考地址:https://python.langchain.com/docs/integrations/chat/ollama/

关注我,一起AI转型之旅~

















 876
876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









