








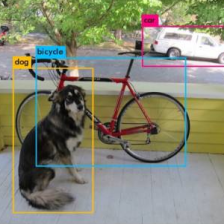
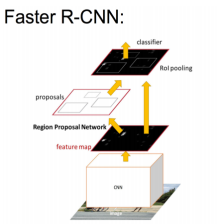
训练数据处理
前面我们将了RPN模型,同时包含特征提取的,输入是图片,输出是分类和回归,我们现在有了模型的预测输出,因为做的是有监督学习,所以我们还需要真实值输出,也就是标注框相关的分类和回归部分,以便于去计算损失。还是train_frcnn.py:
# 图片,rpn的分类和回归,增强后的图片数据
X, Y, img_data = next(data_gen_train)
# 返回三个损失 总得loss rpn_loss_cls rpn_loss_regr
loss_rpn = model_rpn.train_on_batch(X, Y)
上面的Y就是真实的分类和回归,因为要统一成RPN模型的输出格式才可以进行损失计算,所以我们需要把他们预处理一下,我们通过data_gen_train迭代器来获取预处理后的数据,每次就一张图片。
# 获取真实的标注训练数据
data_gen_train = data_generators.get_anchor_gt(train_imgs, classes_count, C, nn.get_img_output_length,
K.image_dim_ordering(), mode='train')
# 获取真实的标注测试数据
data_gen_val = data_generators.get_anchor_gt(val_imgs, classes_count, C, nn.get_img_output_length,
K.image_dim_ordering(), mode='val')
可以看到迭代器其实是这个函数data_generators.get_anchor_gt,就是获取真实框的预处理信息,下面我们来看看这个方法。
训练数据处理
来看看这个文件data_generators.py的SampleSelector:
# 样本选择器
class SampleSelector:
def __init__(self, class_count):
# ignore classes that have zero samples
# 获取所有类别名的序列,除去个数是0的,针对bg
self.classes = [b for b in class_count.keys() if class_count[b] > 0]
# 把传入的序列无限重复下去 比如序列 ABC ,重复就是 ABCABCBC... 这样是为了实现样本均衡,所有类别比例都均衡,按ABCABC这样的序列下去
self.class_cycle = itertools.cycle(self.classes)
# 依次迭代获取下一个类别
self.curr_class = next(self.class_cycle)
# 判断图片中是否含有采样器的当前类,为了实现样本均衡,没有就不处理了,有才处理
def skip_sample_for_balanced_class(self, img_data):
class_in_img = False
for bbox in img_data['bboxes']:
cls_name = bbox['class']
#只要图片中包含类别就够了,几个没关系
if cls_name == self.curr_class:
class_in_img = True
self.curr_class = next(self.class_cycle)
break
# 包含了这个类别就可以处理,不包含就这个图片就没用了
if class_in_img:
return False
else:
return True
这个样本选择器,主要是为了样本均衡的时候用的,他的目的就是为了保持样本均衡,要一个迭代器不停的迭代出样本的类别的序列,比如ABCABC…这样循环下去,以保证样本的比例是均衡的。skip_sample_for_balanced_class这个方法就是在筛选图片是否符合样本均衡的要求,具体在get_anchor_gt这个方法里会看到。如果我现在需要的是类别A的框,你图片里没有,那对不起,你这张图片我不要了,继续检查下一张,如果有,我才去处理。然后我继续迭代下一个需要的是类别B,继续检查图片。这样就强制实现了样本均衡,但是会丢掉很多不符合他类别序列顺序的样本了,其实不太合理,比如如果我的样本序列是AABBCC明显也是符合样本均衡的,但是强制那么多,就把一般的样本丢了,这样就浪费了,所以貌似这个样本均衡的机制也没启动,可以看到配置里是self.balanced_classes = False。
好了,其实这个选择器没啥用,因为样本均衡没启动,但是我也讲一下这个干嘛用的,便于理解。接下来要讲get_anchor_gt这个方法了,怎么预处理标注框:
'''
获取真实的标注框信息
'''
def get_anchor_gt(all_img_data, class_count, C, img_length_calc_function, backend, mode='train'):
'''
:param all_img_data: 所有的图片数据
:param class_count: 类别数量的字典
:param C: 配置
:param img_length_calc_function: 特征图的尺寸
:param backend: 后台是tf还是th
:param mode: 是否训练
:return:
'''
# The following line is not useful with Python 3.5, it is kept for the legacy
# all_img_data = sorted(all_img_data)
sample_selector = SampleSelector(class_count)
while True:
#训练的时候混洗一下
if mode == 'train':
np.random.shuffle(all_img_data)
# 迭代所有的图片信息
for img_data in all_img_data:
try:
# 是否要实现样本均衡,就是按照sample_selector迭代的序列进行样本的提取,否则就不要这个样本,
# 比如样本迭代是A B C A B C... 如果图片中有这个类别的框,就处理,如果没有就不处理这个图片,直接看下一个图片了
if C.balanced_classes and sample_selector.skip_sample_for_balanced_class(img_data):
continue
# read in image, and optionally add augmentation
if mode == 'train':
img_data_aug, x_img = data_augment.augment(img_data, C, augment=True)
else:
img_data_aug, x_img = data_augment.augment(img_data, C, augment=False)
# 原始图像的宽高
(width, height) = (img_data_aug['width'], img_data_aug['height'])
(rows, cols, _) = x_img.shape
assert cols == width
assert rows == height
# get image dimensions for resizing
# 获取原图按照规定尺寸缩放后的宽高 默认是以最大600的长度,可以设置
(resized_width, resized_height) = get_new_img_size(width, height, C.im_size)
# resize the image so that smalles side is length = 600px
# 将原图缩放到规定尺寸
x_img = cv2.resize(x_img, (resized_width, resized_height), interpolation=cv2.INTER_CUBIC)
try:
# 计算RPN分类和回归
y_rpn_cls, y_rpn_regr = calc_rpn(C, img_data_aug, width, height, resized_width, resized_height, img_length_calc_function)
except:
continue
# Zero-center by mean pixel, and preprocess image
# 更改维度顺序,转成RGB,cv默认是BGR
x_img = x_img[:,:, (2, 1, 0)] # BGR -> RGB
x_img = x_img.astype(np.float32)
# 做自定义的标准化
x_img[:, :, 0] -= C.img_channel_mean[0]
x_img[:, :, 1] -= C.img_channel_mean[1]
x_img[:, :, 2] -= C.img_channel_mean[2]
x_img /= C.img_scaling_factor
# 转置 通道放最前面了
x_img = np.transpose(x_img, (2, 0, 1)) # (3,600,1000)
x_img = np.expand_dims(x_img, axis=0) # (1,3,600,1000)
# 将回归误差后半部分误差值进行缩放
y_rpn_regr[:, y_rpn_regr.shape[1]//2:, :, :] *= C.std_scaling
# tf的话通道放最后
if backend == 'tf':
x_img = np.transpose(x_img, (0, 2, 3, 1))
y_rpn_cls = np.transpose(y_rpn_cls, (0, 2, 3, 1))
y_rpn_regr = np.transpose(y_rpn_regr, (0, 2, 3, 1))
yield np.copy(x_img), [np.copy(y_rpn_cls), np.copy(y_rpn_regr)], img_data_aug
except Exception as e:
print(e)
continue
从头开始看,初始化样本选择器,其实没啥用,如果是训练就混洗图片数据,看一下图片数据的格式:

然后遍历所有的图片数据,如果开启了样本均衡,就要判断样本选择器是否选这个样本了,不选就直接遍历下一个样本了,这里没开启,所以也不用管,就处理样本就好了。如果训练集的话可能要进行数据增强,也就是data_augment.py里的augment方法,我们先来看看这个方法吧,不然上面的代码不好理解:
# 图片增强 翻转,旋转
def augment(img_data, config, augment=True):
assert 'filepath' in img_data
assert 'bboxes' in img_data
assert 'width' in img_data
assert 'height' in img_data
# 深拷贝,不然会修改原图
img_data_aug = copy.deepcopy(img_data)
# 图片信息 cv读出来的是BGR
img = cv2.imread(img_data_aug['filepath'])
# 如果要进行数据增强的话,其实也就是旋转 翻转 然后更新一些信息
if augment:
# 高和宽
rows, cols = img.shape[:2]
# 水平翻转 50%概率
if config.use_horizontal_flips and np.random.randint(0, 2) == 0:
img = cv2.flip(img, 1)
# 修正x
for bbox in img_data_aug['bboxes']:
x1 = bbox['x1']
x2 = bbox['x2']
bbox['x2'] = cols - x1
bbox['x1'] = cols - x2
# 竖直翻转 50%概率
if config.use_vertical_flips and np.random.randint(0, 2) == 0:
img = cv2.flip(img, 0)
# 修正y
for bbox in img_data_aug['bboxes']:
y1 = bbox['y1']
y2 = bbox['y2']
bbox['y2'] = rows - y1
bbox['y1'] = rows - y2
# 旋转 顺时针,转置可以看成图片主对角线对称过来的样子
if config.rot_90:
angle = np.random.choice([0,90,180,270],1)[0]
if angle == 270:
img = np.transpose(img, (1,0,2))
# 垂直翻转
img = cv2.flip(img, 0)
elif angle == 180:
# 水平垂直翻转
img = cv2.flip(img, -1)
elif angle == 90:
img = np.transpose(img, (1,0,2))
# 水平翻转
img = cv2.flip(img, 1)
elif angle == 0:
pass
# 旋转后坐标修正
for bbox in img_data_aug['bboxes']:
x1 = bbox['x1']
x2 = bbox['x2']
y1 = bbox['y1']
y2 = bbox['y2']
if angle == 270:
bbox['x1'] = y1
bbox['x2'] = y2
bbox['y1'] = cols - x2
bbox['y2'] = cols - x1
elif angle == 180:
bbox['x2'] = cols - x1
bbox['x1'] = cols - x2
bbox['y2'] = rows - y1
bbox['y1'] = rows - y2
elif angle == 90:
bbox['x1'] = rows - y2
bbox['x2'] = rows - y1
bbox['y1'] = x1
bbox['y2'] = x2
elif angle == 0:
pass
# 旋转过后可能宽高有变化
img_data_aug['width'] = img.shape[1]
img_data_aug['height'] = img.shape[0]
return img_data_aug, img
上面的代码也比较好理解,数据增强后,坐标肯定就变啦,具体可以自己画个图算算,光脑子想想不清楚,画个图就知道坐标怎么回事了,还有就是图片转置其实就是沿着颜色矩阵的主对角线进行翻转,然后配合图片本身的水平和竖直翻转就可以等价于角度的旋转,只是取了90,180,270这些比较好算的角度,否则就可能要进行复杂了。最后结果返回增强后的图片信息,和图片颜色信息。
然后我们继续看get_anchor_gt,后面获取了原始图片的高和宽,进行了缩放,把短边强制缩放成600,长边跟着比例缩放,可以看这个函数get_new_img_size比较简单不多说了,看代码就好了:
# 获得新的图片尺寸,短边长设置为600,等比例缩放比如500x300 变为 1000x600
def get_new_img_size(width, height, img_min_side=600):
if width <= height:
f = float(img_min_side) / width
resized_height = int(f * height)
resized_width = img_min_side
else:
f = float(img_min_side) / height
resized_width = int(f * width)
resized_height = img_min_side
return resized_width, resized_height
然后就用cv把图片给缩放了,之后我们要对图片真实数据进行RPN网络的分类和回归梯度的计算,主要是为了就是让标注数据处理成RPN输出的格式,好计算误差,用的是这个函数calc_rpn,因为这个方法比较复杂,所以我打算用新的篇章去讲。

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。















 6048
6048











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









