






xLSTM是近期比较热门的模型,其是基于LSTM的改进模型,主要改进点体现在指数门控、记忆结构、并行化能力以及残差堆叠架构上。
主要阵地在公众号,会优先更新公众号,欢迎通过下面二维码扫码关注

1. 指数门控 (Exponential Gating)
传统的 LSTM 依赖于 sigmoid 门控函数,这种门控函数的输出在[0,1]之间,限制了信息的灵活流动。而在 xLSTM 中,引入了指数门控,这使得输入和遗忘门可以以指数方式控制记忆更新,从而允许更高效的信息流动与存储调整。
对于传统的 LSTM,记忆更新公式为:
![]()
其中 it 和ft是通过 sigmoid 函数计算的输入门和遗忘门。
而在 xLSTM 中,指数门控通过以下公式实现:
![]()
或者
![]()
这样,输入门it通过指数激活函数使得在处理不同时间步时能够动态地调整存储的权重,从而增强模型对存储值的更新能力。这种增强解决了 LSTM 在处理相似输入时难以调整存储值的问题(如“最近邻搜索问题”)。
2. 新的记忆结构 (Memory Structure)
xLSTM 提出了两种新的记忆单元:sLSTM 和 mLSTM。
2.1 sLSTM(标量记忆和新记忆混合)
sLSTM 仍然保留了标量记忆单元,但是引入了新记忆混合机制,使得记忆单元可以在多个层之间进行混合。这个机制可以通过头机制来实现,即多个记忆单元混合在每个头内,但不跨头进行混合。
sLSTM 的前向传播公式为:
![]()
这个公式中,nt是归一化状态,用来保持输入门与所有未来遗忘门的乘积。
2.2 mLSTM(矩阵记忆与协方差更新)
mLSTM 引入了矩阵记忆,允许存储和检索基于矩阵的记忆内容,而不仅仅是标量值。通过协方差更新规则,模型可以有效扩展其存储容量,并显著提高稀有信息的存储与检索能力。
mLSTM 的前向传播公式为:
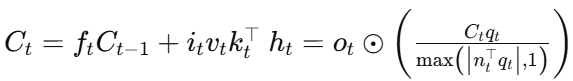
其中,Ct是矩阵记忆,vt和kt分别为值向量和键向量,qt是查询向量,协方差更新规则保证了记忆的有效存储。
这种矩阵记忆能够解决传统 LSTM 的稀有令牌预测问题,即 LSTM 在预测稀有令牌时由于其有限的标量记忆容量表现不佳,而 mLSTM 能够通过矩阵记忆结构解决这个问题。
3. 并行化能力 (Parallelization)
LSTM 的一个关键缺陷是其依赖时间步之间的顺序计算,无法并行化。而 mLSTM 通过消除记忆混合(即时间步之间的隐藏状态连接),实现了完全的并行化。这使得 xLSTM 相比传统 LSTM,在处理长序列时显著提高了计算效率。
下图中展示了 mLSTM 的并行化特点,它通过矩阵记忆单元和协方差更新规则,消除了时间步之间的依赖,从而支持并行训练和推理。
4. 残差堆叠架构 (Residual Stacking Architecture)
xLSTM 使用了残差堆叠架构,将 sLSTM 和 mLSTM 集成到残差块(residual block)中,通过残差堆叠形成更复杂的架构。这种方式与Transformer 架构类似,进一步提升了模型的扩展性如下图所示:
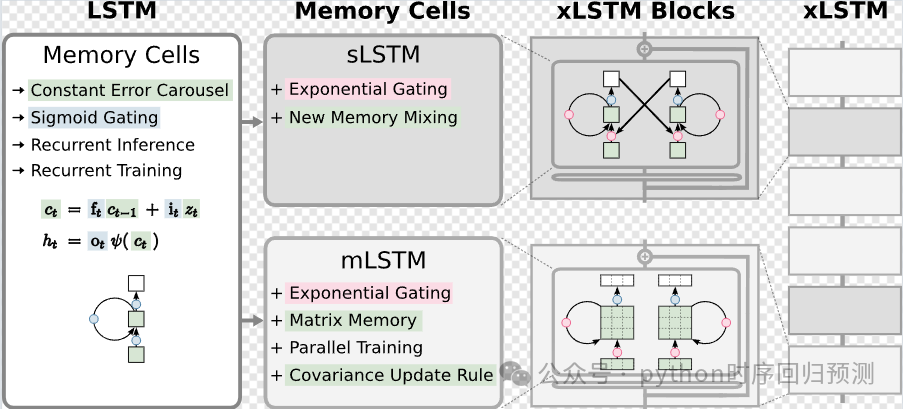
-
第一列:展示了传统的 LSTM 结构,它包含了常量误差环(constant error carousel)和 sigmoid 门控机制,用于解决梯度消失问题。LSTM 的记忆单元通过输入门和遗忘门来控制状态更新。
-
第二列:是 xLSTM 引入的两个扩展模型:
-
sLSTM:具备新的记忆混合机制和指数门控,通过标量记忆更新提升了存储能力。
-
mLSTM:具备矩阵记忆、协方差更新规则和并行训练能力,极大地扩展了模型的存储容量。
-
-
第三列:展示了 sLSTM 和 mLSTM 集成到残差块中的 xLSTM 块,这些块用于非线性地总结历史数据,进而提高序列预测的效果。
-
第四列:展示了 xLSTM 块通过残差堆叠构建的完整 xLSTM 架构。
总的来说,xLSTM 通过指数门控、新的记忆结构、并行化能力和残差堆叠架构,显著提升了传统 LSTM 的存储和计算能力,使其能够与 Transformer 和状态空间模型竞争。
xLSTM代码有许多人售卖,但其实在网上早有开源代码,但是源代码是只有单变量,下面分享我基于开源代码进行拆分得到的xLSTM(原代码包含和slstm、mlstm的对比)以及多变量的xLSTM。
有想要其它相关模型的话可以咸鱼搜索“清朝简单的饮料”、“安仁坊天蝎座果”和“黉门街打球的生姜”,优先搜索“清朝简单的饮料”!!!除这三个号外其它均为我的二次销售盗版(有些盗版连文案都不改一下直接复制我的就离谱),出了问题无法保障!!!此外csdn上也有较多我的盗版模型!!!!我的模型均使用焦作市的空气质量数据!!!注意甄别!!!!!老版本模型可能存在些许问题!!!!!还有最新的XLSTM、KAN-LSTM、TimesNet等等模型。也会陆续更新模型,欢迎关注!!!!!!
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, mean_absolute_percentage_error
import torch.nn.functional as F
import warnings
warnings.filterwarnings('ignore')
class CausalConv1D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation=1, **kwargs):
super(CausalConv1D, self).__init__()
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, padding=self.padding, dilation=dilation, **kwargs)
def forward(self, x):
x = self.conv(x)
return x[:, :, :-self.padding]
class BlockDiagonal(nn.Module):
def __init__(self, in_features, out_features, num_blocks):
super(BlockDiagonal, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.num_blocks = num_blocks
assert out_features % num_blocks == 0
block_out_features = out_features // num_blocks
self.blocks = nn.ModuleList([
nn.Linear(in_features, block_out_features)
for _ in range(num_blocks)
])
def forward(self, x):
x = [block(x) for block in self.blocks]
x = torch.cat(x, dim=-1)
return x
class mLSTMBlock(nn.Module):
def __init__(self, input_size, head_size, num_heads, proj_factor=2):
super(mLSTMBlock, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.proj_factor = proj_factor
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.up_proj_left = nn.Linear(input_size, int(input_size * proj_factor))
self.up_proj_right = nn.Linear(input_size, self.hidden_size)
self.down_proj = nn.Linear(self.hidden_size, input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.skip_connection = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.Wq = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
self.Wk = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
self.Wv = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
self.Wi = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.Wf = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.Wo = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.group_norm = nn.GroupNorm(num_heads, self.hidden_size)
def forward(self, x, prev_state):
h_prev, c_prev, n_prev, m_prev = prev_state
h_prev = h_prev.to(x.device)
c_prev = c_prev.to(x.device)
n_prev = n_prev.to(x.device)
m_prev = m_prev.to(x.device)
assert x.size(-1) == self.input_size
x_norm = self.layer_norm(x)
x_up_left = self.up_proj_left(x_norm)
x_up_right = self.up_proj_right(x_norm)
x_conv = F.silu(self.causal_conv(x_up_left.unsqueeze(1)).squeeze(1))
x_skip = self.skip_connection(x_conv)
q = self.Wq(x_conv)
k = self.Wk(x_conv) / (self.head_size ** 0.5)
v = self.Wv(x_up_left)
i_tilde = self.Wi(x_conv)
f_tilde = self.Wf(x_conv)
o = torch.sigmoid(self.Wo(x_up_left))
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * (v * k) # v @ k.T
n_t = f * n_prev + i * k
h_t = o * (c_t * q) / torch.max(torch.abs(n_t.T @ q), 1)[0] # o * (c @ q) / max{|n.T @ q|, 1}
output = h_t
output_norm = self.group_norm(output)
output = output_norm + x_skip
output = output * F.silu(x_up_right)
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class sLSTMBlock(nn.Module):
def __init__(self, input_size, head_size, num_heads, proj_factor=4 / 3):
super(sLSTMBlock, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.proj_factor = proj_factor
assert proj_factor > 0
self.layer_norm = nn.LayerNorm(input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
self.Wz = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wi = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wf = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wo = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Rz = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Ri = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Rf = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Ro = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.group_norm = nn.GroupNorm(num_heads, self.hidden_size)
self.up_proj_left = nn.Linear(self.hidden_size, int(self.hidden_size * proj_factor))
self.up_proj_right = nn.Linear(self.hidden_size, int(self.hidden_size * proj_factor))
self.down_proj = nn.Linear(int(self.hidden_size * proj_factor), input_size)
def forward(self, x, prev_state):
assert x.size(-1) == self.input_size
h_prev, c_prev, n_prev, m_prev = prev_state
h_prev = h_prev.to(x.device)
c_prev = c_prev.to(x.device)
n_prev = n_prev.to(x.device)
m_prev = m_prev.to(x.device)
x_norm = self.layer_norm(x)
x_conv = F.silu(self.causal_conv(x_norm.unsqueeze(1)).squeeze(1))
z = torch.tanh(self.Wz(x_norm) + self.Rz(h_prev))
o = torch.sigmoid(self.Wo(x_norm) + self.Ro(h_prev))
i_tilde = self.Wi(x_conv) + self.Ri(h_prev)
f_tilde = self.Wf(x_conv) + self.Rf(h_prev)
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * z
n_t = f * n_prev + i
h_t = o * c_t / n_t
output = h_t
output_norm = self.group_norm(output)
output_left = self.up_proj_left(output_norm)
output_right = self.up_proj_right(output_norm)
output_gated = F.gelu(output_right)
output = output_left * output_gated
output = self.down_proj(output)
final_output = output + x
return final_output, (h_t, c_t, n_t, m_t)
class xLSTM(nn.Module):
def __init__(self, input_size, head_size, num_heads, layers, batch_first=False, proj_factor_slstm=4 / 3,
proj_factor_mlstm=2):
super(xLSTM, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.layers = layers
self.num_layers = len(layers)
self.batch_first = batch_first
self.proj_factor_slstm = proj_factor_slstm
self.proj_factor_mlstm = proj_factor_mlstm
self.layers = nn.ModuleList()
for layer_type in layers:
if layer_type == 's':
layer = sLSTMBlock(input_size, head_size, num_heads, proj_factor_slstm)
elif layer_type == 'm':
layer = mLSTMBlock(input_size, head_size, num_heads, proj_factor_mlstm)
else:
raise ValueError(f"Invalid layer type: {layer_type}. Choose 's' for sLSTM or 'm' for mLSTM.")
self.layers.append(layer)
def forward(self, x, state=None):
assert x.ndim == 3
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
if state is not None:
state = torch.stack(list(state)).to(x.device)
assert state.ndim == 4
num_hidden, state_num_layers, state_batch_size, state_input_size = state.size()
assert num_hidden == 4
assert state_num_layers == self.num_layers
assert state_batch_size == batch_size
assert state_input_size == self.input_size
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size, device=x.device)
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
return output, state
###########################################单变量预测模型##############################################
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data = pd.read_excel('单变量.xlsx', engine='python').drop('date',axis=1)
dataset = data.values.astype('float32')
batch_size = 32
seq_len = 8
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
def create_dataset(dataset, seq_len=8):
dataX, dataY = [], []
for i in range(len(dataset) - seq_len):
a = dataset[i:(i + seq_len - 1)]
dataX.append(a)
dataY.append(dataset[i + seq_len - 1])
return torch.Tensor(dataX), torch.Tensor(dataY)
trainX, trainY = create_dataset(train, seq_len)
testX, testY = create_dataset(test, seq_len)
train_dataset = TensorDataset(trainX, trainY)
test_dataset = TensorDataset(testX, testY)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
input_size = 1
head_size = 32
num_heads = 2
model = xLSTM(input_size, head_size, num_heads, batch_first=True, layers='msm').to(device)
def train_model(model, epochs=20, learning_rate=0.01):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
train_losses = []
for epoch in tqdm(range(epochs), desc='Training xLSTM'):
model.train()
epoch_loss = 0
for i, (inputs, targets) in enumerate(train_loader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs, _ = model(inputs)
outputs = outputs[:, -1, :]
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
train_losses.append(epoch_loss / len(train_loader))
return model, train_losses
trained_model, train_losses = train_model(model)
plt.figure()
plt.plot(train_losses, label='xLSTM')
plt.title('Training Losses for xLSTM')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.legend()
plt.show()
def evaluate_model(model, data_loader):
model.eval()
predictions = []
with torch.no_grad():
for inputs, _ in data_loader:
inputs = inputs.to(device)
outputs, _ = model(inputs)
predictions.extend(outputs[:, -1, :].cpu().numpy())
return predictions
test_predictions = evaluate_model(trained_model, test_loader)
preds = scaler.inverse_transform(np.array(test_predictions).reshape(-1, 1))
actual = scaler.inverse_transform(testY.numpy().reshape(-1, 1))
rmse = mean_squared_error(actual, preds, squared=False)
mae = mean_absolute_error(actual, preds)
mape = mean_absolute_percentage_error(actual, preds)
r2 = r2_score(actual, preds)
print(f"RMSE: {rmse:.4f}")
print(f"MAE: {mae:.4f}")
print(f"MAPE: {mape:.4f}")
print(f"R^2: {r2:.4f}")
plt.figure()
plt.plot(actual, label='Actual')
plt.plot(preds, label='xLSTM Predictions')
plt.title('xLSTM Predictions vs Actual')
plt.legend()
plt.show()
###########################################多变量预测模型##############################################
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
data = pd.read_excel('多变量.xlsx').drop('date',axis=1)
target_col_name = 'canopy'
seq_len = 8
feature_cols = data.columns.drop(target_col_name)
target_col = data[target_col_name].values.astype('float32')
features = data[feature_cols].values.astype('float32')
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_features = scaler.fit_transform(features)
scaled_target = scaler.fit_transform(target_col.reshape(-1, 1))
dataset = np.hstack((scaled_features, scaled_target))
def create_dataset(dataset, seq_len=8, target_col_idx=-1):
dataX, dataY = [], []
for i in range(len(dataset) - seq_len):
a = dataset[i:(i + seq_len - 1), :-1]
dataX.append(a)
dataY.append(dataset[i + seq_len - 1, target_col_idx])
return torch.Tensor(dataX), torch.Tensor(dataY)
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0:train_size, :], dataset[train_size:len(dataset), :]
trainX, trainY = create_dataset(train, seq_len, target_col_idx=-1)
testX, testY = create_dataset(test, seq_len, target_col_idx=-1)
train_dataset = TensorDataset(trainX, trainY)
test_dataset = TensorDataset(testX, testY)
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
input_size = len(feature_cols)
head_size = 32
num_heads = 2
model = xLSTM(input_size, head_size, num_heads, batch_first=True, layers='msm').to(device)
def train_model(model, epochs, learning_rate):
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.MSELoss()
train_losses = []
for epoch in tqdm(range(epochs), desc='Training xLSTM'):
for inputs, targets in train_loader:
inputs, targets = inputs.to(device), targets.to(device)
model.train()
optimizer.zero_grad()
outputs, _ = model(inputs)
outputs = outputs[:, -1, :]
if len(targets.shape) == 2:
targets = targets
elif len(targets.shape) == 1:
targets = targets.unsqueeze(1)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
if (epoch+1) % 5 == 0:
print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.item():.4f}')
return model, train_losses
def evaluate_model(model, data_loader):
model.eval()
predictions = []
with torch.no_grad():
for inputs, _ in data_loader:
inputs = inputs.to(device)
outputs, _ = model(inputs)
predictions.extend(outputs[:, -1, :].cpu().numpy())
return predictions
trained_model, train_losses = train_model(model, epochs=5, learning_rate=0.01)
test_predictions = evaluate_model(trained_model, test_loader)
preds = scaler.inverse_transform(np.array(test_predictions).reshape(-1, input_size))
actual = scaler.inverse_transform(testY.numpy().reshape(-1, 1))
rmse = mean_squared_error(actual, preds[:, 0], squared=False)
mae = mean_absolute_error(actual, preds[:, 0])
mape = mean_absolute_percentage_error(actual, preds[:, 0])
r2 = r2_score(actual, preds[:, 0])
print(f"RMSE: {rmse:.4f}")
print(f"MAE: {mae:.4f}")
print(f"MAPE: {mape:.4f}")
print(f"R^2: {r2:.4f}")
plt.figure()
plt.plot(actual[:, 0], label='Actual')
plt.plot(preds[:, 0], label='xLSTM Predictions')
plt.title('xLSTM Predictions vs Actual')
plt.legend()
plt.show()使用xLSTM的预测效果如下图:
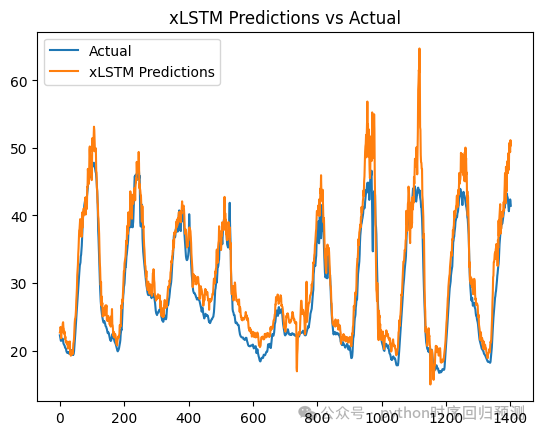
由于没有好好调参数,因此从预测效果来看,与前面的crossformer等模型相比还是有一定差距的。同学们也可以自己调节参数看看效果变化,也可以自己试着叠叠乐,叠一些优化算法和分解算法等等!!!!当然如果需要对未来值进行预测也可以私信咨询,有偿添加!!!!
需要源代码和模型原文的可以通过下面链接下载,自行理解!!!
链接:https://pan.baidu.com/s/15eLyZu5m7BLbtISeXhu26A?pwd=1sei
提取码:1sei

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









