










xLSTM —— LSTM 焕发新生的创新之作
近年来,LSTM(长短期记忆网络)在深度学习领域被广泛应用,尤其是在自然语言处理和时间序列预测任务中。然而,随着 Transformer 的崛起,LSTM 的一些局限性逐渐暴露出来,比如信息存储的灵活性不足、难以并行处理长序列数据等。为了解决这些问题,研究者们推出了 xLSTM 模型,通过引入指数门控、改进的记忆结构和残差堆叠架构,让 LSTM 在现代 AI 应用中重获新生。本文将深入探讨 xLSTM 的创新之处以及其在实际应用中的表现。
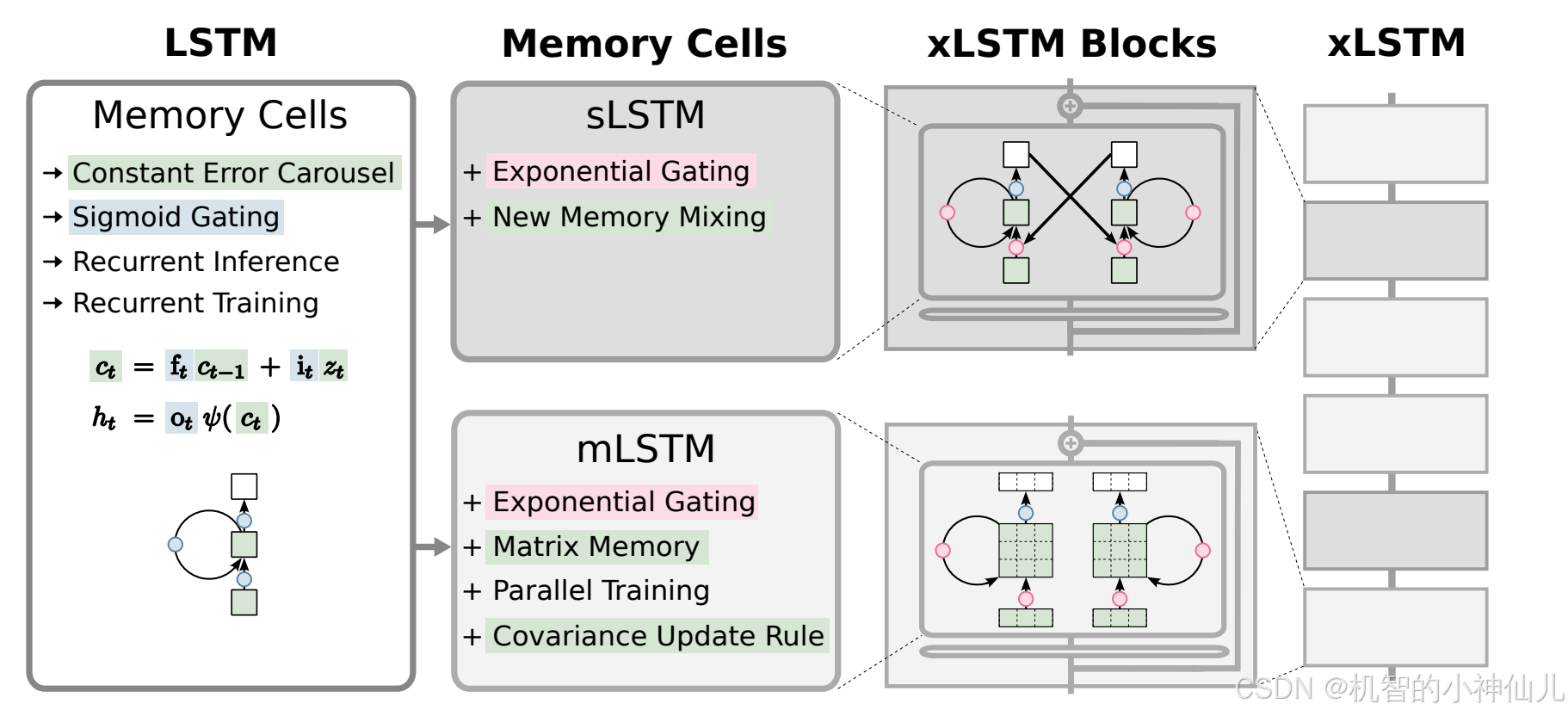
为什么 xLSTM 是必要的?
LSTM 模型虽然在一定程度上解决了 RNN 的梯度消失问题,但在处理复杂的长时间依赖任务时依然存在以下几个主要问题:
- 信息存储的灵活性受限:传统的 LSTM 依赖于 sigmoid 门控,限制了信息的灵活流动。
- 存储容量有限:LSTM 的记忆单元为标量存储,处理大量复杂信息时表现不足。
- 并行化能力弱:由于时间步之间的顺序依赖,LSTM 无法实现高效并行化计算。
xLSTM 的设计正是为了解决这些瓶颈,使得 LSTM 能够在大规模深度学习应用中发挥更大作用。
xLSTM 的核心创新
xLSTM 的主要改进集中在以下几个方面:
1. 指数门控(Exponential Gating)
xLSTM 引入了新的指数门控机制,这种机制允许信息流动的更大灵活性。在传统 LSTM 中,输入门和遗忘门通过 sigmoid 激活函数控制,输出范围在 0 到 1 之间。而在 xLSTM 中,门控采用指数激活函数,增强了信息的动态调整能力,尤其在长时间序列中表现出色。指数门控使模型更容易应对相似向量的识别问题,并在更新存储值时表现得更为有效。
2. 改进的记忆结构
xLSTM 提出了两种新型记忆单元:sLSTM 和 mLSTM。
- sLSTM(标量记忆):sLSTM 保留了标量存储的特点,并引入了新颖的多层混合机制,使得不同层的记忆可以相互作用,从而增强存储和信息流动的灵活性。
- mLSTM(矩阵记忆):mLSTM 通过使用矩阵形式的记忆单元,极大地提升了模型的存储容量,能够有效存储稀疏信息。矩阵记忆单元通过协方差更新规则来更新,使得模型在处理复杂信息时有了显著的提升。
3. 完全并行化能力
传统的 LSTM 依赖于时间步之间的隐藏状态传递,而 mLSTM 通过消除这种依赖,实现了完全的并行化。对于长序列处理,xLSTM 相比传统 LSTM 在效率上有显著提升,非常适合在 GPU 上进行高效计算。
4. 残差堆叠架构(Residual Stacking Architecture)
xLSTM 引入了类似 Transformer 的残差堆叠架构,将 sLSTM 和 mLSTM 整合到残差块中,以残差堆叠的方式形成深层网络。这种架构不仅提高了模型的扩展性,还有效防止了深层网络中的梯度消失问题,使得模型可以更好地学习复杂的历史依赖关系。
实验与结果
在多个实验中,xLSTM 在时间序列预测、自然语言处理等任务中表现出色。特别是在长序列数据预测任务中,xLSTM 的性能超越了传统 LSTM 和许多 Transformer 模型。
例如,在一个模拟的多查询关联任务(Multi-Query Associative Recall)中,xLSTM 需要从长序列中存储和检索多个键值对。实验显示,xLSTM 能够在较长序列和较多存储需求的情况下保持较高的精度,其矩阵记忆结构显著提升了模型的稀疏信息存储能力。
此外,在长时间序列处理任务(如 Long Range Arena)中,xLSTM 展现了高效的处理能力和低复杂度的内存需求,充分体现了其设计的优势。
xLSTM 的应用场景
xLSTM 的设计使得它在多个领域展现出强大的应用潜力:
- 时间序列预测:xLSTM 可以用于股票预测、电力负荷预测等任务,处理长序列数据的能力尤其突出。
- 自然语言处理:虽然 Transformer 已成为 NLP 的主流架构,但 xLSTM 在一些需要长时间依赖的任务中依然具备优势,例如文本生成和机器翻译。
- 大型语言模型(LLM):实验表明,xLSTM 能够扩展到数十亿参数的规模,在预测和语言建模任务中表现优异。
xLSTM 的优缺点
优点:
- 灵活的存储机制与指数门控使得模型在长序列依赖建模上表现更好。
- 完全并行化设计适合 GPU 上的高效训练。
- 残差堆叠架构增强了模型的扩展性。
缺点:
- 相较于传统 LSTM,xLSTM 的计算资源和存储空间需求更高。
- 需要更复杂的超参数调优,训练时间较长。
总结
xLSTM 是对传统 LSTM 模型的一个重要扩展,结合了指数门控、矩阵记忆和残差堆叠架构,使得其在长序列建模方面具有显著的优势。xLSTM 的出现,不仅让 LSTM 在与 Transformer 等模型的竞争中焕发新生,也为未来的 AI 应用提供了新的思路。随着模型规模的进一步扩展,xLSTM 有望在自然语言处理、时间序列分析等领域发挥更大的作用,为深度学习技术的进步贡献力量。
原文链接:https://arxiv.org/pdf/2405.04517
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
import numpy as np
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score, mean_absolute_percentage_error
import torch.nn.functional as F
import warnings
warnings.filterwarnings('ignore')
# CausalConv1D: 实现因果卷积(Causal Convolution),确保输出不会依赖未来的时间步
class CausalConv1D(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation=1, **kwargs):
super(CausalConv1D, self).__init__()
# 计算填充以确保卷积因果性
self.padding = (kernel_size - 1) * dilation
self.conv = nn.Conv1d(in_channels, out_channels, kernel_size, padding=self.padding, dilation=dilation, **kwargs)
def forward(self, x):
# 前向传播:截取填充部分,以确保输出仅依赖于过去的信息
x = self.conv(x)
return x[:, :, :-self.padding]
# BlockDiagonal: 构建一个分块对角线层,用于实现多头机制下的线性变换
class BlockDiagonal(nn.Module):
def __init__(self, in_features, out_features, num_blocks):
super(BlockDiagonal, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.num_blocks = num_blocks
# 检查每个 block 的输出特征维度是否一致
assert out_features % num_blocks == 0
block_out_features = out_features // num_blocks
# 初始化多个线性变换层,每个层对应一个头(head)
self.blocks = nn.ModuleList([nn.Linear(in_features, block_out_features) for _ in range(num_blocks)])
def forward(self, x):
# 对每个 head 应用对应的线性变换并拼接结果
x = [block(x) for block in self.blocks]
x = torch.cat(x, dim=-1)
return x
# mLSTMBlock: 实现 mLSTM 模块,包含矩阵记忆和协方差更新规则
class mLSTMBlock(nn.Module):
def __init__(self, input_size, head_size, num_heads, proj_factor=2):
super(mLSTMBlock, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.proj_factor = proj_factor
# 层归一化用于正则化输入
self.layer_norm = nn.LayerNorm(input_size)
# 投影层,用于高维转换
self.up_proj_left = nn.Linear(input_size, int(input_size * proj_factor))
self.up_proj_right = nn.Linear(input_size, self.hidden_size)
self.down_proj = nn.Linear(self.hidden_size, input_size)
# 因果卷积确保时间步的因果性
self.causal_conv = CausalConv1D(1, 1, 4)
# 跳跃连接,用于残差连接
self.skip_connection = nn.Linear(int(input_size * proj_factor), self.hidden_size)
# 多头注意力机制的键、查询和值
self.Wq = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
self.Wk = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
self.Wv = BlockDiagonal(int(input_size * proj_factor), self.hidden_size, num_heads)
# 输入门、遗忘门和输出门
self.Wi = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.Wf = nn.Linear(int(input_size * proj_factor), self.hidden_size)
self.Wo = nn.Linear(int(input_size * proj_factor), self.hidden_size)
# 分组归一化用于稳定输出
self.group_norm = nn.GroupNorm(num_heads, self.hidden_size)
def forward(self, x, prev_state):
h_prev, c_prev, n_prev, m_prev = prev_state
# 归一化和投影操作
x_norm = self.layer_norm(x)
x_up_left = self.up_proj_left(x_norm)
x_up_right = self.up_proj_right(x_norm)
# 因果卷积和残差连接
x_conv = F.silu(self.causal_conv(x_up_left.unsqueeze(1)).squeeze(1))
x_skip = self.skip_connection(x_conv)
# 计算多头注意力
q = self.Wq(x_conv)
k = self.Wk(x_conv) / (self.head_size ** 0.5) # 缩放因子
v = self.Wv(x_up_left)
# 门控计算
i_tilde = self.Wi(x_conv)
f_tilde = self.Wf(x_conv)
o = torch.sigmoid(self.Wo(x_up_left))
# 更新记忆单元
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * (v * k)
n_t = f * n_prev + i * k
h_t = o * (c_t * q) / torch.max(torch.abs(n_t.T @ q), 1)[0]
# 输出并进行残差连接和归一化
output = self.group_norm(h_t + x_skip) * F.silu(x_up_right)
final_output = self.down_proj(output) + x
return final_output, (h_t, c_t, n_t, m_t)
# sLSTMBlock: 实现 sLSTM 模块,包含标量记忆和多头混合机制
class sLSTMBlock(nn.Module):
def __init__(self, input_size, head_size, num_heads, proj_factor=4 / 3):
super(sLSTMBlock, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.proj_factor = proj_factor
# 层归一化和因果卷积
self.layer_norm = nn.LayerNorm(input_size)
self.causal_conv = CausalConv1D(1, 1, 4)
# 定义多头标量记忆门控
self.Wz = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wi = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wf = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Wo = BlockDiagonal(input_size, self.hidden_size, num_heads)
self.Rz = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Ri = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Rf = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
self.Ro = BlockDiagonal(self.hidden_size, self.hidden_size, num_heads)
# 分组归一化和残差连接
self.group_norm = nn.GroupNorm(num_heads, self.hidden_size)
self.up_proj_left = nn.Linear(self.hidden_size, int(self.hidden_size * proj_factor))
self.up_proj_right = nn.Linear(self.hidden_size, int(self.hidden_size * proj_factor))
self.down_proj = nn.Linear(int(self.hidden_size * proj_factor), input_size)
def forward(self, x, prev_state):
h_prev, c_prev, n_prev, m_prev = prev_state
# 归一化和卷积
x_norm = self.layer_norm(x)
x_conv = F.silu(self.causal_conv(x_norm.unsqueeze(1)).squeeze(1))
# 标量记忆更新
z = torch.tanh(self.Wz(x_norm) + self.Rz(h_prev))
o = torch.sigmoid(self.Wo(x_norm) + self.Ro(h_prev))
i_tilde = self.Wi(x_conv) + self.Ri(h_prev)
f_tilde = self.Wf(x_conv) + self.Rf(h_prev)
# 记忆更新计算
m_t = torch.max(f_tilde + m_prev, i_tilde)
i = torch.exp(i_tilde - m_t)
f = torch.exp(f_tilde + m_prev - m_t)
c_t = f * c_prev + i * z
n_t = f * n_prev + i
h_t = o * c_t / n_t
# 输出并进行残差连接
output = self.group_norm(h_t)
output_left = self.up_proj_left(output)
output_right = self.up_proj_right(output)
output = output_left * F.gelu(output_right)
final_output = self.down_proj(output) + x
return final_output, (h_t, c_t, n_t, m_t)
# xLSTM: 主模型类,用于堆叠多个 sLSTM 和 mLSTM 层并实现前向传播
class xLSTM(nn.Module):
def __init__(self, input_size, head_size, num_heads, layers, batch_first=False, proj_factor_slstm=4 / 3, proj_factor_mlstm=2):
super(xLSTM, self).__init__()
self.input_size = input_size
self.head_size = head_size
self.hidden_size = head_size * num_heads
self.num_heads = num_heads
self.layers = layers
self.num_layers = len(layers)
self.batch_first = batch_first
# 根据配置动态创建 sLSTM 和 mLSTM 层
self.layers = nn.ModuleList()
for layer_type in layers:
if layer_type == 's':
layer = sLSTMBlock(input_size, head_size, num_heads, proj_factor_slstm)
elif layer_type == 'm':
layer = mLSTMBlock(input_size, head_size, num_heads, proj_factor_mlstm)
else:
raise ValueError(f"Invalid layer type: {layer_type}. Choose 's' for sLSTM or 'm' for mLSTM.")
self.layers.append(layer)
def forward(self, x, state=None):
# 确保输入形状,支持 batch_first 参数
if self.batch_first: x = x.transpose(0, 1)
seq_len, batch_size, _ = x.size()
# 初始化状态
if state is not None:
state = torch.stack(list(state)).to(x.device)
state = state.transpose(0, 1)
else:
state = torch.zeros(self.num_layers, 4, batch_size, self.hidden_size, device=x.device)
# 逐时间步执行前向传播
output = []
for t in range(seq_len):
x_t = x[t]
for layer in range(self.num_layers):
x_t, state_tuple = self.layers[layer](x_t, tuple(state[layer].clone()))
state[layer] = torch.stack(list(state_tuple))
output.append(x_t)
output = torch.stack(output)
if self.batch_first:
output = output.transpose(0, 1)
state = tuple(state.transpose(0, 1))
return output, state



















 1965
1965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











