





nlp和数据挖掘
Machines learning algorithms, since their inception, have been designed to handle numbers. This worked well with data that could be easily converted into numerical form; be it images or sound, solutions to these types of problems were quickly developed and deployed. Yet one area is still not yet completely in the grasp of machines — language, because it is distinctly human.
自从机器学习算法问世以来,它们就被设计用来处理数字。 这与可以轻松转换为数字形式的数据很好地结合在一起; 无论是图像还是声音,都可以快速开发和部署针对此类问题的解决方案。 然而,仍然没有一个领域完全掌握机器-语言,因为它显然是人类。
Feasible methods to convert language into numbers always end up losing information. Consider, for instance, TF-IDF vectorization, a very standard method of text-to-number conversion that works well enough for very simple tasks but fails to understand the nuances of language, like sarcasm, context, cultural references, idioms, and words with multiple meanings. Even with the development of landmark solutions like BERT, natural language processing is still perhaps the field machine learning has the most room to improve in.
将语言转换为数字的可行方法总是会丢失信息。 例如,考虑TF-IDF矢量化,这是一种非常标准的文本到数字的转换方法,可以很好地完成非常简单的任务,但无法理解语言的细微差别,例如讽刺,语境,文化参考,成语和单词有多种含义。 即使像BERT这样的具有里程碑意义的解决方案的开发,自然语言处理仍可能是现场机器学习有最大的改进空间。
Perhaps, to approach such a unique problem full of exceptions and nuance, machine learning engineers need to find more creative solutions — after all, not every problem can be solved or feasibly deployed using a neural network variant. Consider graph theory, an often overlooked or dismissed field of mathematics, founded by Leonhard Euler in 1736 with the pondering of the Seven Bridges of Königsberg problem. It would seem unlikely that graph theory and natural language processing would work together, but they do — in a spectacularly ingenious and creative fusion of the two studies, their intersection paves the way for more diverse solutions in NLP and machine learning as a whole.
也许,为了解决这种充满异常和细微差别的独特问题,机器学习工程师需要找到更多有创意的解决方案-毕竟,并非所有问题都可以使用神经网络变体来解决或可行地部署。 考虑图论,这是一个经常被忽视或忽视的数学领域,由伦纳德·欧拉(Leonhard Euler)于1736年对柯尼斯堡问题的七桥问题进行了思考。 图论和自然语言处理似乎不太可能一起工作,但是它们确实做到了—在两项研究的惊人巧妙和创造性融合中,它们的交集为NLP和整个机器学习的更多样化解决方案铺平了道路。
All images were created by author unless stated otherwise.
除非另有说明,否则所有图像均由作者创建。
A knowledge (semantic) graph is, daresay, one of the most fascinating concepts in data science. The applications, extensions, and potential of knowledge graphs to mine order from the chaos of unstructured text is truly mind-blowing.
敢说,知识(语义)图是数据科学中最令人着迷的概念之一。 知识图的应用,扩展和潜力,从非结构化文本的混乱中挖掘出的订单,真是令人赞叹。
The graph consists of nodes and edges, where a node represents an entity and an edge represents a relationship. No entity in a graph can be repeated twice, and when there are enough entities in a graph, the connections between each can reveal worlds of information.
该图由节点和边组成,其中节点代表实体,边代表关系。 图形中的任何实体都不能重复两次,并且当图形中有足够的实体时,每个实体之间的联系可以揭示信息世界。

Just with a few entities, interesting relationships begin to emerge. As a general rule, entities are nouns and relationships are verbs; for instance, “the USA is a member of NATO” would correspond to a graph relationship “[entity USA] to [entity NATO] with [relationship member of]”. Just using text from three to four sentences of information, one could construct a rudimentary knowledge graph:
只有几个实体,有趣的关系开始出现。 通常,实体是名词,关系是动词。 例如,“美国是北约的成员”将对应于“ [实体美国]与[实体]的[关系成员]”之间的图形关系。 只需使用三到四个信息句子的文本,就可以构建基本的知识图:

Imagine the sheer amount of knowledge possessed in a complete Wikipedia article, or even an entire book! One could perform detailed analyses with this abundance of data; for example, identifying the most important entities or what the most common action or relationship an entity is on the receiving end of. Unfortunately, while building knowledge graphs is simple for humans, it is not scalable. We can build simple rule-based automated graph-builders.
想象一下,完整的Wikipedia文章甚至一本书中都拥有如此丰富的知识! 一个人可以用大量的数据进行详细的分析。 例如,识别最重要的实体或实体在接收端最常见的动作或关系。 不幸的是,尽管构建知识图对于人类来说很简单,但是却不可扩展。 我们可以构建简单的基于规则的自动图形生成器。
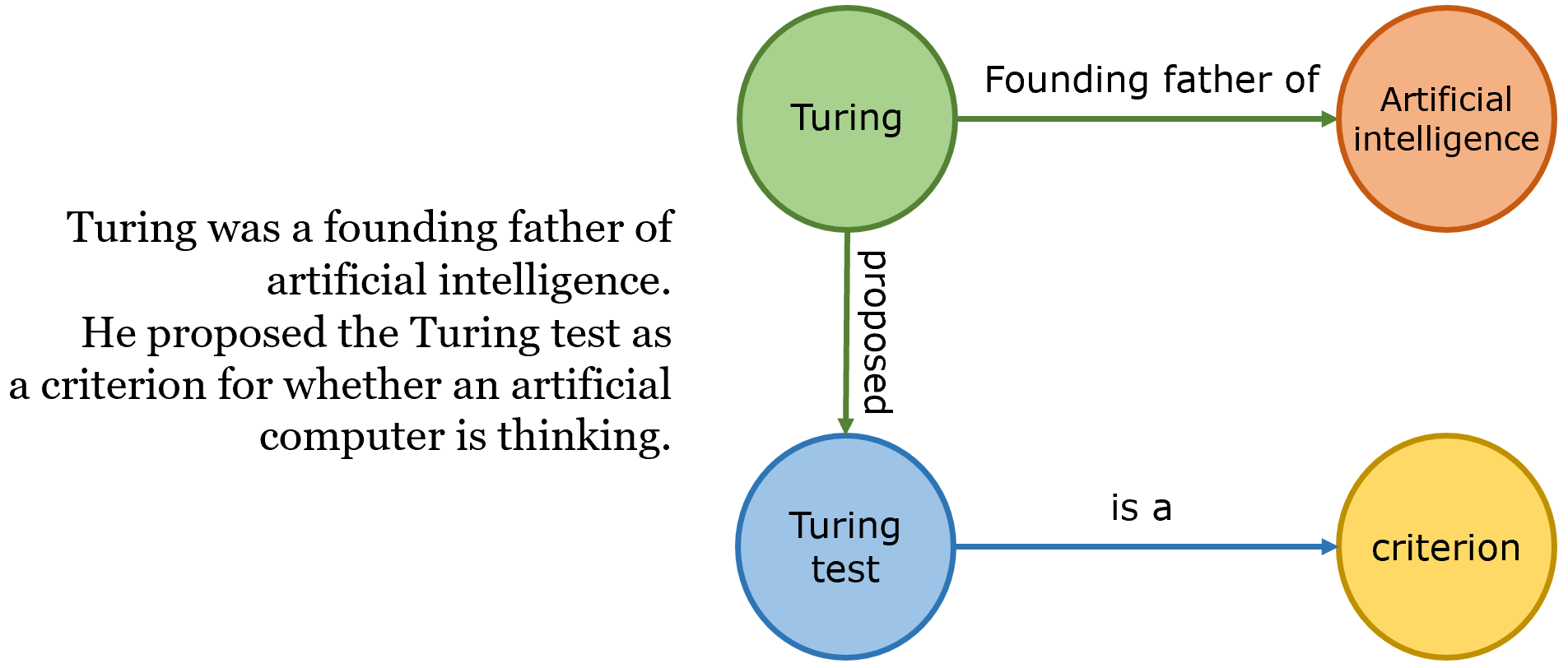
To demonstrate the automation of knowledge-graph building, consider an expert of a biography of the great computer scientist and founder of artificial intelligence, Alan Turing. Since we’ve established that entities are nouns and verbs are relationships, let us first split the text into chunks, where each contains a relationship between two objects.
为了演示知识图构建的自动化,请考虑一位伟大的计算机科学家和人工智能创始人艾伦·图灵的传记的专家。 既然我们已经确定实体是名词,而动词是关系,那么让我们首先将文本分成多个块,每个块包含两个对象之间的关系。

A simple method to do this is to separate by sentence, but a more rigorous method would be to separate by clause, since there may be many clauses and hence relationships in a single sentence (“she walked her dog to the park, then she bought food”).
一种简单的方法是按句子分隔,但更严格的方法是按子句分隔,因为一个句子中可能有很多子句,因此关系也很复杂(“她walk狗去公园,然后她买了餐饮”)。
Identifying the objects involved — entity extraction — is a more difficult task. Consider “Turing test”: this is an example of a nested entity, or an entity within the name of another entity. While POS (part of speech) tagging is sufficient for single-word nouns, one will need to use dependency parsing for multi-word nouns.
识别涉及的对象(实体提取)是一项更加困难的任务。 考虑“图灵测试”:这是嵌套实体或另一个实体名称内的实体的示例。 尽管POS(词性)标记对于单个单词的名词就足够了,但人们将需要对多个单词的名词使用依赖项解析。

Dependency parsing is the task of recognizing a sentence and assigning a syntax-based structure to it. Because dependency trees are based on grammar and not word-by-word, it doesn’t care how many words an object consists of, as long as it is enclosed by other structures like verbs (‘proposed’) or transitioning phrases (‘as a…’). It is also used to find the verb that relates the two objects, systematically following what it believes is the syntax of the sentence and the rules of grammar. One can also use similar methods to link pronouns (‘he’, ‘she’, ‘they’) to the person it refers to (pronoun resolution).
依赖性分析是识别句子并为其分配基于语法的结构的任务。 因为依赖关系树基于语法,而不是逐词,所以只要对象被动词(“提议”)或过渡短语(“ as”)等其他结构包围,它就不在乎对象包含多少个单词。一个…')。 它也用于查找与两个对象相关的动词,系统地遵循它认为的句子句法和语法规则。 人们还可以使用类似的方法将代词(“他”,“她”,“他们”)链接到所指代的人(代词解析)。
It is worth mentioning that one may also benefit from building a knowledge graph by adding synonyms; tutorials will often show examples with the same word repeated many times for simplicity, but to humans using the same word repeatedly is so looked down-upon that writers actively find synonyms (words that mean the same thing as another word). One way to do this is with Hearst patterns, named after Marti Hearst, a computational linguistics researcher and professor at UC Berkeley. In her extensive research, she discovered a set of reoccurring patterns that can be reliably used to extract information.
值得一提的是,通过添加同义词可以从构建知识图中受益。 为了简单起见,教程通常会显示多次重复使用同一单词的示例,但对于反复使用同一单词的人类来说,却显得如此卑鄙,以至于作者积极地找到同义词(与另一单词含义相同的单词)。 一种实现方法是使用赫斯特模式,该模式以加州大学伯克利分校的计算机语言学研究人员和教授马蒂·赫斯特的名字命名。 在广泛的研究中,她发现了一组可以可靠地用于提取信息的重复模式。

These Hearst patterns occur very often, especially in large text repositories like Wikipedia or an Encyclopedia. By recording all of these word meanings and relationships alongside noun-verb-noun relationships, the knowledge graph will have a tremendous amount of information and understanding. After all, humans recognize and interact with objects in relation to other events or objects (“hey, I won that trophy at the basketball championship!”).
这些赫斯特模式非常常见,尤其是在大型文本存储库中,例如Wikipedia或Encyclopedia。 通过记录所有这些词义和关系以及名词-动词-名词关系,知识图将具有大量的信息和理解。 毕竟,人类会识别与其他事件或物体相关的物体并与之互动(“嘿,我在篮球锦标赛上赢得了那座奖杯!”)。
Using a variety of simple rules, one can create an entire knowledge graph from a piece of text. A knowledge graph created on all of Wikipedia would, theoretically, be smarter than any single human could, in that it understands the relation and context of certain objects with others, and is hence able to build a detailed arsenal of deeper knowledge about a variety of subjects.
使用各种简单规则,可以从一段文本创建整个知识图。 从理论上讲,在整个Wikipedia上创建的知识图谱将比任何一个人类都聪明,因为它了解某些对象与其他对象之间的关系和上下文,因此能够建立有关各种知识的详细知识的详细信息库。科目。
There are always exceptions in language, however, and using a rule-based method to create knowledge graphs may seem outdated. A more modern neural network-based method may be able to construct a knowledge graph with more robustness and adaptivity to the quirks and turns of text.
但是,在语言上总是有例外,使用基于规则的方法来创建知识图谱似乎已经过时了。 一种更现代的基于神经网络的方法可能能够构建对文本的古怪和转折具有更高鲁棒性和适应性的知识图。
Text summarization is an important part of natural language processing. While there are certainly many heavy-duty ways to do it, like an encoder-decoder model, it may be overkill, or even perform worse, than a graph-based method. The key to text summarization is to select the important aspects of text and to compile them. This is known as an extractive approach to text summarization; instead of generating new text, this approach finds the most important sentence within the document.
文本摘要是自然语言处理的重要组成部分。 尽管肯定有许多繁重的方法可以做到,例如编码器/解码器模型,但与基于图的方法相比,它可能会过大,甚至性能更差。 文本摘要的关键是选择文本的重要方面并进行编译。 这被称为文本摘要的提取方法。 这种方法不是生成新文本,而是在文档中找到最重要的句子。
Once a knowledge graph has been created on a text, it will likely be massive. After all, the size of a graph grows exponentially with each additional node, and there is a tremendous amount of detail and nuance within the graph. This allows for a graph reduction algorithm to be applied, which calculates the ‘centrality’ of a node, depending on several factors, including the frequency and weight of connections to other nodes, as well as the attributes of the nodes they connect to. Each sentence is then given a score based on how important elements and relationships in it are, and the highest few are given entrance into a final summary.
在文本上创建知识图后,它可能会很大。 毕竟,图的大小随每个其他节点呈指数增长,并且图内有大量的细节和细微差别。 这允许应用图归约算法,该算法根据几个因素来计算节点的“中心度”,这些因素包括与其他节点的连接的频率和权重以及它们连接到的节点的属性。 然后根据句子中的重要元素和相互关系为每个句子评分,最后几个句子的分数最高。
This approach is beautiful for several reasons:
这种方法之所以美观,有几个原因:
- It is unsupervised. Unlike another popular extractive summarization method, in which a classifier (most likely a neural network) is trained to predict whether a sentence should be included in a summary or not, it is not restricted by lack of abundance or objectivity in training labels. 它是无监督的。 与另一种流行的提取摘要方法不同,在该方法中训练分类器(最有可能是神经网络)以预测句子是否应包括在摘要中,该方法不受训练标签中缺乏丰满性或客观性的限制。
- It works in all languages. Creating a knowledge graph and utilizing the fruits of it is universal, since it emphasizes relationships and not necessarily the value of the name of an entity. This cannot be said for many other NLP frameworks. 它适用于所有语言。 创建知识图并利用它的成果是普遍的,因为它强调关系,而不一定强调实体名称的值。 对于许多其他NLP框架,这不能说。
- It can separate by topic. The beauty of graph modelling is that you will find clusters in a semantic graph, where each represents one specific topic. We can ensure that the algorithm will not be distracted by a heavily-trafficked topic while there are other prominent but less-connected clusters (topics) because it aims for centrality. 它可以按主题分开。 图建模的优点在于,您将在语义图中找到群集,每个群集代表一个特定的主题。 我们可以确保算法不会因人口众多的话题而分散注意力,同时还有其他突出但联系较少的集群(话题),因为它的目的是集中性。
The potential for graph theory in natural language processing is blinding — for instance, with the similarity of documents (in which each document is a node) or with the dynamic clustering of texts. Graph theory implementations of textual data is also incredibly interpretable, and has the power to transform the terrain of text mining and analysis. Beyond the scope of NLP, graph theory is becoming ever more important in studying the effects of diseases and networking.
图论在自然语言处理中的潜力是令人迷惑的,例如,与文档的相似性(每个文档都是一个节点)或文本的动态聚类有关。 文本数据的图论实现也是难以解释的,并且具有改变文本挖掘和分析领域的能力。 除了NLP的范围外,图论在研究疾病和网络影响方面也变得越来越重要。
It’s time to get creative and start exploring.
是时候发挥创造力并开始探索了。
nlp和数据挖掘















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









