





 本文探讨了深度学习模型的压缩,特别是神经网络修剪技术。通过删除权重或神经元来减小模型大小,以降低存储和运行成本。基于权重的修剪因易于实施且不影响性能而更受欢迎,但需要稀疏计算的支持。另一方面,修剪节点虽然允许密集计算,但在硬件上的支持更好,但可能影响准确性。在确定修剪目标时,关键在于识别那些对模型性能影响较小的参数。
本文探讨了深度学习模型的压缩,特别是神经网络修剪技术。通过删除权重或神经元来减小模型大小,以降低存储和运行成本。基于权重的修剪因易于实施且不影响性能而更受欢迎,但需要稀疏计算的支持。另一方面,修剪节点虽然允许密集计算,但在硬件上的支持更好,但可能影响准确性。在确定修剪目标时,关键在于识别那些对模型性能影响较小的参数。
Much of the success of deep learning has come from building larger and larger neural networks. This allows these models to perform better on various tasks, but also makes them more expensive to use. Larger models take more storage space which makes them harder to distribute. Larger models also take more time to run and can require more expensive hardware. This is especially a concern if you are productionizing a model for a real-world application.
深度学习的成功大部分来自建立越来越大的神经网络。 这使这些模型可以更好地执行各种任务,但也使它们的使用成本更高。 较大的型号占用更多的存储空间,这使得它们更难分配。 较大的型号还需要更多的时间来运行,并且可能需要更昂贵的硬件。 如果要为实际应用程序生成模型,则尤其要担心。
Model compression aims to reduce the size of models while minimizing loss in accuracy or performance. Neural network pruning is a method of compression that involves removing weights from a trained model. In agriculture, pruning is cutting off unnecessary branches or stems of a plant. In machine learning, pruning is removing unnecessary neurons or weights. We will go over some basic concepts and methods of neural network pruning.
模型压缩旨在减小模型的大小,同时最大程度地降低准确性或性能损失。 神经网络修剪是一种压缩方法,涉及从训练模型中删除权重。 在农业中,修剪会切断植物不必要的分支或茎。 在机器学习中,修剪可以消除不必要的神经元或重量。 我们将介绍神经网络修剪的一些基本概念和方法。
减轻体重或神经元? (Remove weights or neurons?)
There are different ways to prune a neural network. (1) You can prune weights. This is done by setting individual parameters to zero and making the network sparse. This would lower the number of parameters in the model while keeping the architecture the same. (2) You can remove entire nodes from the network. This would make the network architecture itself smaller, while aiming to keep the accuracy of the initial larger network.
修剪神经网络有多种方法。 (1)您可以修剪砝码。 这是通过将各个参数设置为零并使网络稀疏来完成的。 这将减少模型中的参数数量,同时保持架构不变。 (2)您可以从网络中删除整个节点。 这将使网络体系结构本身更小,同时旨在保持初始较大网络的准确性。
Weight-based pruning is more popular as it is easier to do without hurting the performance of the network. However, it requires sparse computations to be effective. This requires hardware support and a certain amount of sparsity to be efficient.
基于权重的修剪更受欢迎,因为它更易于执行而不会损害网络性能。 但是,它要求稀疏计算才能有效。 这需要硬件支持和一定程度的稀疏性才能有效。
Pruning nodes will allow dense computation which is more optimized. This allows the network to be run normally without sparse computation. This dense computation is more often better supported on hardware. However, removing entire neurons can more easily hurt the accuracy of the neural network.
修剪节点将允许进行更优化的密集计算。 这样可以使网络正常运行而无需进行稀疏计算。 通常在硬件上更好地支持这种密集的计算。 但是,删除整个神经元会更容易损害神经网络的准确性。
修剪什么? (What to prune?)
A major challenge in pruning is determining what to prune. If you are removing weights or nodes from a model, you want the parameters you remove to be less useful. There are different heuristics and methods of determining which nodes are less important and can be removed with minimal effect on accuracy. You can use heuristics based on the weights or activations of a neuron to determine how important it is for the model’s performance. The goal is to remove more of the less important parameters.
修剪中的主要挑战是确定修剪的对象。 如果要从模型中删除权重或节点,则希望删除的参数不太有用。 有不同的启发式方法和方法来确定哪些节点不太重要,可以将其删除而对精度的影响最小。 您可以基于神经元的权重或激活来使用启发式方法来确定它对模型性能的重要性。 目标是删除更多次要参数。
One of the simplest ways to prune is based on the magnitude of the weight. Removing a weight is essentially setting it to zero. You can minimize the effect on the network by removing weights that are already close to zero, meaning low in magnitude. This can be implemented by removing all weights below a certain threshold. To prune a neuron based on weight magnitude you can use the L2 norm of the neuron’s weights.
修剪的最简单方法之一是根据重量的大小。 删除权重实际上是将其设置为零。 您可以通过消除已经接近零的权重(即幅度较小)来最大程度地降低对网络的影响。 这可以通过去除低于某个阈值的所有权重来实现。 要根据体重大小修剪神经元,可以使用神经元重量的L2范数。
Rather than just weights, activations on training data can be used as a criteria for pruning. When running a dataset through a network, certain statistics of the activations can be observed. You may observe that some neurons always outputs near-zero values. Those neurons can likely be removed with little impact on the model. The intuition is that if a neuron rarely activates with a high value, then it is rarely used in the model’s task.
训练数据的激活不仅可以用作权重,还可以用作修剪的标准。 通过网络运行数据集时,可以观察到某些激活统计信息。 您可能会观察到某些神经元总是输出接近零的值。 这些神经元可能会被移除,而对模型的影响很小。 直觉是,如果神经元很少以高值激活,则很少在模型任务中使用它。
In addition to the magnitude of weights or activations, redundancy of parameters can mean a neuron can be removed. If two neurons in a layer have very similar weights or activations, it can mean they are doing the same thing. By this intuition, we can remove one of the neurons and preserve the same functionality.
除了权重或激活的大小外,参数的冗余还意味着可以删除神经元。 如果一层中的两个神经元具有非常相似的权重或激活,则可能意味着它们在做相同的事情。 通过这种直觉,我们可以去除其中一个神经元并保留相同的功能。
Ideally in a neural network, all the neurons have unique parameters and output activations that are significant in magnitude and not redundant. We want all the neurons are doing something unique, and remove those that are not.
理想情况下,在神经网络中,所有神经元都具有唯一的参数和输出激活,这些参数和输出激活的大小都很大,而不是多余的。 我们希望所有的神经元都在做独特的事情,并删除那些不是。
什么时候修剪? (When to prune?)
A major consideration in pruning is where to put it in the training/testing machine learning timeline. If you are using a weight magnitude-based pruning approach, as described in the previous section, you would want to prune after training. However, after pruning, you may observe that the model performance has suffered. This can be fixed by fine-tuning, meaning retraining the model after pruning to restore accuracy.
修剪中的主要考虑因素是将其放在训练/测试机器学习时间表中的何处。 如果您使用上一节中所述的基于权重的修剪方法,则需要在训练后修剪。 但是,修剪后,您可能会发现模型性能受到了影响。 这可以通过微调来解决,这意味着在修剪后重新训练模型以恢复准确性。
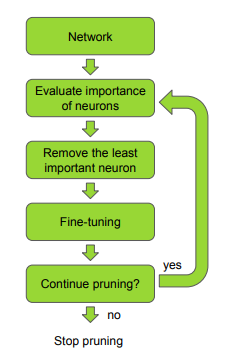
The usage of pruning can change depending on the application and methods used. Sometimes fine-tuning or multiple iterations of pruning are not necessary. This depends on how much of the network is pruned.
修剪的用法可以根据所使用的应用程序和方法而变化。 有时不需要微调或修剪的多次迭代。 这取决于修剪多少网络。
如何评估修剪? (How to evaluate pruning?)
There multiple metrics to consider when evaluating a pruning method: accuracy, size, and computation time. Accuracy is needed to determine how the model performs on its task. Model size is how much bytes of storage the model takes. To determine computation time, you can use FLOPs (Floating point operations) as a metric. This is more consistent to measure than inference time and it does not depend on what system the model runs on.
评估修剪方法时,需要考虑多个指标:准确性,大小和计算时间。 需要准确性来确定模型如何执行其任务。 模型大小是模型占用的存储字节数。 要确定计算时间,可以使用FLOP(浮点运算)作为度量标准。 测量比推理时间更一致,并且不依赖于模型运行的系统。
With pruning, there is a tradeoff between model performance and efficiency. You can prune heavily and have a smaller more efficient network, but also less accurate. Or you could prune lightly and have a highly performant network, that is also large and expensive to operate. This trade-off needs to be considered for different applications of the neural network.
通过修剪,可以在模型性能和效率之间进行权衡。 您可以进行大量修剪,并拥有较小的更有效的网络,但准确性也较低。 或者,您可以轻松修剪并拥有一个高性能的网络,该网络规模庞大且操作昂贵。 对于神经网络的不同应用,需要考虑这种折衷。
结论 (Conclusion)
Pruning is an effective method of making neural networks more efficient. There are plenty of choices and areas of research in this area. We want to continue to make advances in deep learning while also keeping our models energy, time, and space-efficient.
修剪是提高神经网络效率的有效方法。 该领域有很多选择和研究领域。 我们希望继续在深度学习方面取得进步,同时还要保持模型的能量,时间和空间效率。
翻译自: https://towardsdatascience.com/pruning-neural-networks-1bb3ab5791f9















 807
807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









