





互联网激发词语
Spotify is a Swedish music streaming and media services provider. The main project’s aim is to predict users churn for Sparkify (a Spotify-style a mythical music service). Like every Internet service Spotify makes money from user activity. Sparkify’s users perform different actions on the service pages. Project’s data is a log file. It’s mean that the data have more than one record for each user. The project’s full dataset is 12GB, of which you can analyze a mini subset is 128 MB.
Spotify是瑞典的音乐流媒体服务提供商。 主要项目的目的是预测用户对Sparkify(Spotify风格的神话音乐服务)的流失。 像每项Internet服务一样,Spotify可以通过用户活动赚钱。 Sparkify的用户在服务页面上执行不同的操作。 项目的数据是一个日志文件。 这意味着每个用户的数据具有多个记录。 该项目的完整数据集为12GB,您可以分析其中的一个迷你子集为128 MB。
问题陈述 (Problem Statement)
The case solvation consists of:
案例解决包括:
- determine target to predict based on the information in 18th feature columns; 根据第18个要素列中的信息确定要预测的目标;
- predict users churn. 预测用户流失。

The shape of the dataset is 286500 rows and 18 columns. The one record display that the user Colin Freeman listened the song Rockpools by Martha Tilston.
数据集的形状为286500行18列。 一条记录显示用户Colin Freeman收听了Martha Tilston演唱的Rockrocks。
The data is not a dataset. It is a part of log file. This data does not consist of any features could be using for prediction directly. All of the data columns are using to describe a user or a user action. We can see the 18th columns in the dataframe and we have to determine which column contains the information about user churn.
数据不是数据集。 它是日志文件的一部分。 此数据不包含任何可直接用于预测的功能。 所有数据列均用于描述用户或用户操作。 我们可以在数据框中看到第18列,我们必须确定哪一列包含有关用户流失的信息。
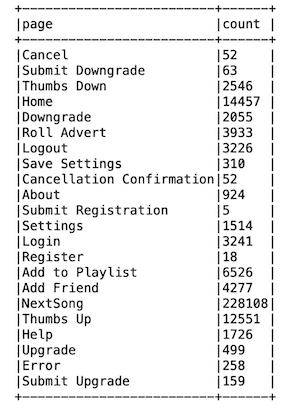
We have to explore dataframe columns. And the first task is to determine target to predict. Column ‘page’ have this information.
我们必须探索数据框列。 首要任务是确定要预测的目标。 列“页面”具有此信息。
The visiting counts of the ‘Cancel’ and ‘Cancellation Confirmation’ are 52. These rows contain the information about churned users.
“取消”和“取消确认”的访问计数为52。这些行包含有关搅动用户的信息。
Handling null values
处理空值

Initial dataset has null values in some columns. We can see that columns ‘firstName’ and ‘LastName’ have 8346 null values. Furthermore, the column ‘userAgent’ includes the 8346 null values too.
初始数据集在某些列中具有空值。 我们可以看到列“ firstName”和“ LastName”具有8346空值。 此外,“ userAgent”列也包含8346个空值。

Nevertheless, the column ‘userId’ has not null values. We have to check the column ‘userId’ on invalid data, like an empty row. An empty row looks like the image on the left.
但是,列“ userId”不具有空值。 我们必须检查无效数据(如空行)上的“ userId”列。 空行看起来像左边的图像。
We can see the ‘Logged Out’ value in the ‘auth’ column where the ‘userId’ column value is an empty row. What the values does the ‘auth’ column include, except ‘Logged Out’?
我们可以在“ auth”列中看到“ Logged Out”值,其中“ userId”列值为空行。 除“已注销”外,“身份验证”列包含哪些值?

The plot show us that the ‘auth’ column consists of the ‘Logged Out’ and the ‘Guest’ values. We can drop all rows with the ‘Logged Out’ and the ‘Guest’ values due to these rows are the audit records and have not the information about a user churn or any user activity.
该图显示了“ auth”列由“ Logged Out”和“ Guest”值组成。 我们可以使用“已注销”和“来宾”值删除所有行,因为这些行是审核记录,并且不包含有关用户流失或任何用户活动的信息。
The remained rows with null values we can not drop due to they have information to predict users churn.
剩下的带有空值的行我们不能删除,因为它们具有预测用户流失的信息。
Categorical features handling
分类特征处理
Some columns in tha dataset have categorical values. We have to change them to ‘0’ and ‘1’ values using ‘dummy’ columns.
tha数据集中的某些列具有分类值。 我们必须使用“虚拟”列将其更改为“ 0”和“ 1”值。
Numerical features
数值特征
Each user has different count of listened song, completed sessions. We should create columns contained of users listened songs and completed sessions. These columns describe the users activity. We can call the columns as the first part users activity.
每个用户的听歌数,完成的会话数都不同。 我们应该创建包含用户听过的歌曲和完成的会话的列。 这些列描述了用户活动。 我们可以将这些列称为第一部分用户活动。
The second part users activity are the visited pages. As we saw earlier the users did not cancel a subscription visited more times the pages ‘Add Friend’, ‘Add to Playlist’, ‘Save Settings’, ‘Submit Upgrade’, ‘Thumbs Up’. We can create some columns to store information about users activity on the pages.
第二部分用户活动是访问页面。 如前所述,用户没有取消多次访问“添加朋友”,“添加到播放列表”,“保存设置”,“提交升级”,“竖起大拇指”页面的订阅。 我们可以创建一些列来存储有关页面上用户活动的信息。
Firstly, we create several pandas dataframes with count of visited pages. Secondly, we create the columns with agregated data in the spark dataframe. Thirdly, we recreate the spark dataframe and drop columns with raw categorical features.
首先,我们创建几个带有访问页面计数的熊猫数据框。 其次,我们在spark数据框中创建具有聚合数据的列。 第三,我们重新创建spark数据框并删除具有原始分类功能的列。
模型实施 (Models implementation)
PySpark’s MLlib has the most common machine learning classification algorithms. In the project we are using three of them:
PySpark的MLlib具有最常用的机器学习分类算法。 在项目中,我们使用其中三个:
Received metrics
收到的指标
Random Forest model gives the best F1-score: 0.87.
随机森林模型给出的最佳F1分数:0.87。
Logistic Regression model take the second place with F1-score: 0.8.
Logistic回归模型的F1得分排名第二:0.8。
Gradient-boosted tree is the worst model for the project, F1-score: 0.7.
渐变增强树是该项目最差的模型,F1分数:0.7。
结论 (Conclusion)
The hardest part of the project was a prerpocessing the dataset. I was wandered that the initial dataset had not been a ‘dataset’. It was not a spread of some features. The initial dataset was a part of log file that consisted users actifity.
该项目最困难的部分是对数据集进行处理。 我徘徊于最初的数据集不是“数据集”。 这并不是某些功能的传播。 初始数据集是包含用户活动性的日志文件的一部分。
I had to transform the project’s data to dataset with unique user’s records.
我必须将项目的数据转换为具有唯一用户记录的数据集。
The second problem was the most dataset columns was not a feature columns. These columns included records that described user’s sessions and actions. And I wrangled the data and aggregated it.
第二个问题是数据集最多的列不是要素列。 这些列包括描述用户的会话和操作的记录。 然后我整理了数据并进行了汇总。
My full solution you can find at here.
我的完整解决方案可以在这里找到。
翻译自: https://medium.com/@ivashkinrg/sparkify-users-churn-prediction-e022f1065e4b
互联网激发词语















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









