





 本文介绍了Pandas库中最常用的十大功能,包括读取Excel和CSV文件、处理HTML、缺失值处理、数据框统计、数据连接、数据分析、切片切块、列的添加与删除、值更新及函数应用等。通过实例展示了如何进行数据处理和分析,如计算总和、平均值、描述性统计、合并数据框、更新值、创建新列等操作,帮助数据科学家和工程师更高效地工作。
本文介绍了Pandas库中最常用的十大功能,包括读取Excel和CSV文件、处理HTML、缺失值处理、数据框统计、数据连接、数据分析、切片切块、列的添加与删除、值更新及函数应用等。通过实例展示了如何进行数据处理和分析,如计算总和、平均值、描述性统计、合并数据框、更新值、创建新列等操作,帮助数据科学家和工程师更高效地工作。
熊猫数据集
There are many tutorials about pandas on the internet and books. Pandas library is one of the most used libraries by data scientists and data engineers. In this tutorial, I am going to list the pandas’ functions I use the most.
互联网上有很多关于熊猫的教程和书籍。 熊猫图书馆是数据科学家和数据工程师最常用的图书馆之一。 在本教程中,我将列出我最常使用的熊猫功能。
While there are many functions to select here are my top ten most used ones. Please let me know yours in the comment section. I will be happy to add them to my collections. I will be focusing on pandas Data Frame rather than series.
虽然这里有很多功能可供选择,但它们是我最常使用的十大功能。 请在评论部分告诉我您的信息。 我很乐意将它们添加到我的收藏中。 我将专注于熊猫数据框而不是系列。
Let’s starts with importing pandas.
让我们从导入熊猫开始。
import pandas as pd- Files Operation 文件操作
Excel
电子表格
import pandas as pd
data = pd.read_excel(‘path_to_your_excel file’, sep=‘ ’, index_col=‘name’, dtype=dtypes, sheet_name=’’)CSV
CSV
import pandas as pd
data = pd.read_excel(‘path_to_your_excel file’, sep=‘ ’ , index_col=‘name’, dtype=dtypes)Read HTML
阅读HTML
import pandas as pd
data = pd.read_html(‘data.html’, index_col=0)Note: you can add datatype when you import the files. i.e and if you want to omit the header, set header=False.
注意:导入文件时可以添加数据类型。 即,如果要省略标题,请设置header = False。
dtypes = {‘colname’: ’datatype’, ‘Weight’: ‘float32’}Pandas considers these as missing values
熊猫认为这些是缺失的价值观
(’ ’),’nan’,’-nan’,’NA’,’N/A’,’NaN’,’null’
(''),'nan','-nan','NA','N / A','NaN','null'
When reading and writing files you can replace them like
读写文件时,您可以像替换它们一样
df.to_csv('new-data.csv', na_rep='(missing)')2. Statistics in Pandas Data Frame
2.熊猫数据框中的统计数据
Sum
和
df['colName'].sum()Mean
意思
df['colName'].mean()Cumulative Sum
累计总和
df['colName'].cumsum()Summary Statistics
统计摘要
df['colName'].describe()Count
计数
df['colName'].count()Min/Max
最小/最大
df['colName'].min()
df['colName'].max()Median
中位数
df['colName'].median()Sample Variance
样本差异
df['colName'].var()Standard Deviation
标准偏差
df['colName'].std()Skewness
偏度
df['colName'].skew()Kurtosis
峰度
df['colName'].kurt()Correlation Matrix Of Values
值的相关矩阵
df.corr()3. Join Operations
3.加入运营
Pandas provides SQL like capabilities in large data sets
Pandas在大型数据集中提供类似SQL的功能
Simple Join
简单加入
pd.concat([df_a, df_b], axis=1)Merge two data frames with condition_column value
合并两个带condition_column值的数据帧
pd.merge(df_new, df_n, on=‘join_condition_column_name’)Merge with outer join
与外部联接合并
pd.merge(df_a, df_b, on=‘condition_column', how='outer’)Merge with inner join
与内部联接合并
pd.merge(df_a, df_b, on=‘condition_column', how='inner’)Merge with right join
以正确的合并合并
pd.merge(df_a, df_b, on=’common_column_id’, how=’right’)Merge with left join
与左联接合并
pd.merge(df_a, df_b, on=‘common_column_id ‘, how=’left’)Merge while adding a suffix to duplicate column names
在添加后缀以重复列名称时合并
pd.merge(df_a, df_b, on=’ common_column_id ‘, how=’left’, suffixes=(‘_left’, ‘_right’))Merge based on indexes
根据索引合并
pd.merge(df_a, df_b, right_index=True, left_index=True)4. Pandas Data Analysis
4.熊猫数据分析
See the first 10 entries
查看前10个条目
dataFrame.head(10)See the last 10 entries
查看最近的10个条目
dataFrame.tail(10)Total Number of records in Datasets
数据集中的记录总数
dataFrame.shape[0]Number of columns in the datasets
数据集中的列数
dataframes.columnsDatasets indexed Detail
数据集索引明细
data.indexSummarize the Data Frame
汇总数据框
data.describe()Summarize all the columns
汇总所有列
data.describe(include = “all”)Mean value of column
列的平均值
round(data.columnname.mean())Least occurred value in column
列中出现最少的值
data.columnnsme.value_counts().tail()5. Slice and dice
5.切片切块
loc in Pandas : from https://www.analyticsvidhya.com/blog/2020/02/loc-iloc-pandas/
Loc in Pandas:来自https://www.analyticsvidhya.com/blog/2020/02/loc-iloc-pandas/
loc is label-based, which means that we have to specify the name of the rows and columns that we need to filter out.
loc 是基于标签的,这意味着我们必须指定需要过滤的行和列的名称。
iloc in Pandas : from https://www.analyticsvidhya.com/blog/2020/02/loc-iloc-pandas/
大熊猫iloc:来自https://www.analyticsvidhya.com/blog/2020/02/loc-iloc-pandas/
On the other hand, iloc is integer index-based. So here, we have to specify rows and columns by their integer index.
另一方面,iloc是基于整数索引的。 因此,在这里,我们必须通过整数索引指定行和列。
Examples
例子
import numpy as np # imported numpy to make arrays.
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
print(df)Output :
输出:

# Using `iloc[]`
print(df.iloc[0][0])Output: 1
输出1
# Using `loc[]`
print(df.loc[0][2])Output : 3
输出3
# Using `at[]`
print(df.at[1,2])Output : 6
输出6
# Using `iat[]`
print(df.iat[0,2])Output : 3
输出3
6. Appending Column to existing dataframe
6.将列追加到现有数据框
Example
例
df = pd.DataFrame(data=np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=['A', 'B', 'C'])
print(df)# Append a column to `df`
df.loc[:, 'D'] = pd.Series(['5', '6' ,'7'], index=df.index)
print(df)Output:
输出:

7. Dropping Duplicate value from dataFrames
7.从dataFrames中删除重复的值
Example
例
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[0,1,1,1], "C":["A","A","B","A"]})
print(df)# droping duplicate value from A and C
df = df.drop_duplicates(subset=['A', 'C'], keep=False)
print(df)# froping the whole column in index 1, which remove the whole row
df = df.drop(df.index[[1]])
print(df)Output :
输出:

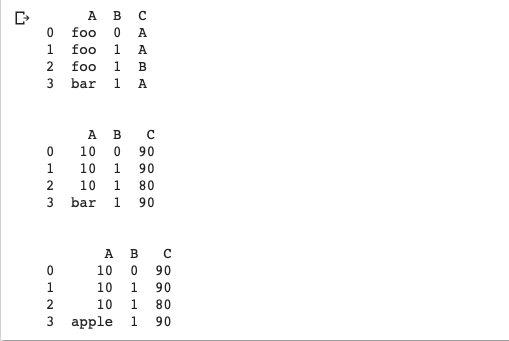
8. Update Value
8.更新价值
Example
例
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[0,1,1,1], "C":["A","A","B","A"]})
print(df)# Replace strings by number (0-4)
df = df.replace(['foo', 'A','B' ], [10,90 , 80])
print(df)# Replace using `regex`
df = df.replace({r'[^0-9]+': 'apple'}, regex=True)
print(df)Output:
输出:
9. Apply Function
9.应用功能
we can make a custom function or use a lambda function to change the record in the data frame once and dynamically.
我们可以创建自定义函数或使用lambda函数一次动态地更改数据帧中的记录。
Example
例
df = pd.DataFrame({"A":["foo", "foo", "foo", "bar"], "B":[0,1,1,1], "C":["A","A","B","A"]})
print(df)
print('\n')
doubler = lambda x: x*2
df = df.replace({r'[^0-9]+': 10}, regex=True)
df = df.apply(doubler)
print(df)Output:
输出:

Creating new column from existing columns
从现有列创建新列
dfa = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
print(dfa)
dfa = dfa.assign(C=lambda x: x['A'] + x['B'],D=lambda x: x['A'] + x['C'])
dfaOutput:
输出:

10. Taking dictionary, series as input in data frame.
10.以字典,系列作为数据框中的输入。
Take a dictionary as input to your DataFrame
将字典作为DataFrame的输入
my_dict = {1: [‘1’, ‘3’], 2: [‘1’, ‘2’], 3: [‘2’, ‘4’]}
print(pd.DataFrame(my_dict))Output:
输出:

Series as input to your Data Frame
系列作为数据框的输入
my_series = pd.Series({“England”:”London”, “Nepal”:”kathmandu”, “China”:”Baiging”, “Belgium”:”Brussels”})
print(pd.DataFrame(my_series))
print(len(my_series.shape))Output:
输出:

There are so many functions i haven’t added in this list. But these are the ones I use the most. Panda is a rich library and it has very good documentation from the official web site. You can read from this link. https://pandas.pydata.org
我没有在列表中添加太多功能。 但是这些是我使用最多的。 熊猫图书馆是一个丰富的图书馆,它拥有来自官方网站的非常好的文档。 您可以从此链接阅读。 https://pandas.pydata.org
翻译自: https://medium.com/the-innovation/pandas-for-data-scientist-a2d8a8e81d04
熊猫数据集

















 1973
1973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









