





熊猫数据集
Filtering data from a data frame is one of the most common operations when cleaning the data. Pandas provides a wide range of methods for selecting data according to the position and label of the rows and columns. In addition, Pandas also allows you to obtain a subset of data based on column types and to filter rows with boolean indexing.
从数据帧中过滤数据是清理数据时最常见的操作之一。 熊猫提供了多种根据行和列的位置和标签选择数据的方法。 此外,Pandas还允许您基于列类型获取数据子集,并使用布尔索引来过滤行。
In this article, we will cover the most common operations for selecting a subset of data from a Pandas data frame: (1) selecting a single column by label, (2) selecting multiple columns by label, (3) selecting columns by data type, (4) selecting a single row by label, (5) selecting multiple rows by label, (6) selecting a single row by position, (7) selecting multiple rows by position, (8) selecting rows and columns simultaneously, (9) selecting a scalar value, and (10) selecting rows using Boolean selection.
在本文中,我们将介绍从Pandas数据框中选择数据子集的最常见操作:(1)按标签选择单个列,(2)按标签选择多个列,(3)按数据类型选择列,(4)按标签选择单行,(5)按标签选择多行,(6)按位置选择单行,(7)按位置选择多行,(8)同时选择行和列,(9 )选择标量值,以及(10)使用布尔选择选择行。
Additionally, we will provide multiple coding examples! Now, let’s get started :) ❤️
此外,我们将提供多个编码示例! 现在,让我们开始吧:)❤️
资料集 (Data set)
In this article, we use a small data set for learning purposes. In the real world, the data sets employed will be much larger; however, the procedures used to filter the data remain the same.
在本文中,我们出于学习目的使用了一个小的数据集。 在现实世界中,使用的数据集将更大。 但是,用于过滤数据的过程保持不变。
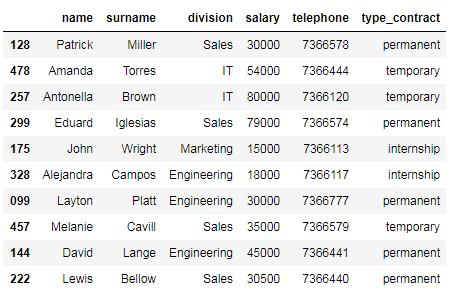
The data frame contains information about 10 employees of a company: (1) id, (2) name, (3) surname, (4) division, (5) telephone, (6) salary, and (7) type of contract.
数据框包含有关公司10名员工的信息:(1)id,(2)名称,(3)姓氏,(4)部门,(5)电话,(6)薪水和(7)合同类型。
1.按标签选择单列 (1. Selecting a single column by label)
To select a single column in Pandas, we can use both the . operator and the [] operator.
要在Pandas中选择单个列,我们可以同时使用。 运算符和[]运算符。
Selecting a single column by label
通过标签选择单列
→ df[string]
→df [string]
The following code access the salary column using both methods (dot notation and square braces).
以下代码使用两种方法(点符号和方括号)访问salary列。
# select the column (salary) using dot notation
salary = df_employees.salary
# select the column (salary) using square brackets
salary_2 = df_employees['salary']
# we obtain a Series object, when a single column is selected
print(type(salary))
# <class 'pandas.core.series.Series'>
print(type(salary_2))
# <class 'pandas.core.series.Series'>
salary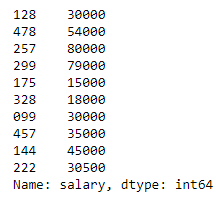
As shown above, when a single column is retrieved, the result is a Series object. To obtain a DataFrame object when selecting only one column, we need to pass in a list with a single item instead of just a string.
如上所示,当检索单个列时,结果是Series对象。 为了在仅选择一列时获得一个DataFrame对象,我们需要传入一个包含单个项目而不是一个字符串的列表。
# obtain a Series object by passing in a string to the indexing operator
df_employees['salary']
# obtain a DataFrame object by passing a list with a single item to the indexing operator
df_employees[['salary']]
Besides, it is important to bear in mind that we can not use dot notation to access a specific column of a data frame when the column name contains spaces. If we do it, a SyntaxError is raised.
此外,重要的是要记住,当列名包含空格时,我们不能使用点符号来访问数据框的特定列。 如果我们这样做,则会引发SyntaxError 。
2.按标签选择多列 (2. Selecting multiple columns by label)
We can select multiple columns of a data frame by passing in a list with the column names as follows.
我们可以通过传递带有列名的列表来选择一个数据框的多个列,如下所示。
Selecting multiple columns by label
通过标签选择多列
→ df[list_of_strings]
→df [list_of_strings]
# select multiple columns by passing in a list with the column names to the indexing operator
df_employees[['division', 'salary']]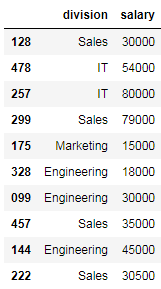
As shown above, the result is a DataFrame object containing only the columns provided in the list.
如上所示,结果是一个DataFrame对象,该对象仅包含列表中提供的列。
3.按数据类型选择列 (3. Selecting columns by data type)
We can use the pandas.DataFrame.select_dtypes(include=None, exclude=None) method to select columns based on their data types. The method accepts either a list or a single data type in the parameters include and exclude. It is important to keep in mind that at least one of these parameters (include or exclude) must be supplied and they must not contain overlapping elements.
我们可以使用pandas.DataFrame.select_dtypes(include = None,exclude = None)方法根据列的数据类型选择列。 该方法在include和exclude参数中接受列表或单个数据类型。 重要的是要记住,必须至少提供这些参数之一(包括或排除),并且它们不得包含重叠的元素。
Selecting columns by data type
按数据类型选择列
→ df.select_dtypes(include=None, exclude=None)
→df.select_dtypes(包括=无,排除=无)
In the example below, we select the numeric columns (both integers and floats) of the data frame by passing in the np.number object to the include parameter. Alternatively, we can obtain the same results by providing the string ‘number’ as input.
在下面的示例中,我们选择数字列(整数和浮点数) 通过将np.number对象传递给include参数来确定数据帧的大小。 或者,我们可以通过提供字符串“ number”作为输入来获得相同的结果。
As you can observe, the select_dtypes() method returns a DataFrame object including the dtypes in the include parameter and excluding the dtypes in the exclude parameter.
如您所见, select_dtypes()方法返回一个DataFrame对象,该对象包括include参数中的dtypes并排除exclude参数中的dtypes。
import numpy as np
# select numeric columns - numpy object
numeric_inputs = df_employees.select_dtypes(include=np.number)
# check selected columns with the .columns attribute
numeric_inputs.columns
# Index(['salary'], dtype='object')
# the method returns a DataFrame object
print(type(numeric_inputs))
# <class 'pandas.core.frame.DataFrame'>
# select numeric columns - string
numeric_inputs_2 = df_employees.select_dtypes(include='number')
# check selected columns with the .columns attribute
numeric_inputs_2.columns
# Index(['salary'], dtype='object')
# the method returns a DataFrame object
print(type(numeric_inputs_2))
# <class 'pandas.core.frame.DataFrame'>
# visualize the data frame
numeric_inputs
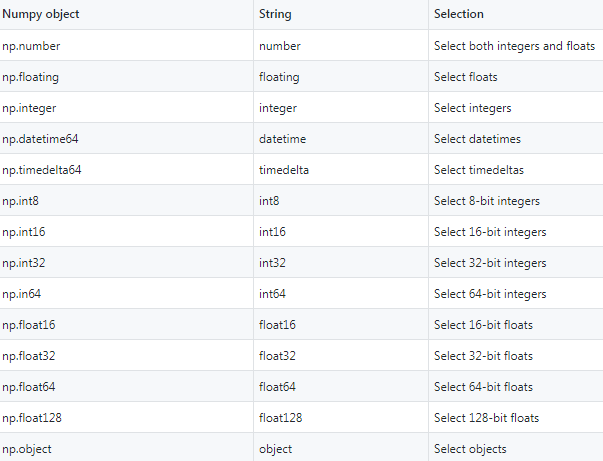
As mentioned before, the select_dtypes() method can take both strings and numpy objects as input. The following table shows the most common ways of referring to data types in Pandas.
如前所述, select_dtypes()方法可以同时使用字符串和numpy对象作为输入。 下表显示了在Pandas中引用数据类型的最常用方法。
As a reminder, we can check the data types of the columns using pandas.DataFrame.info method or with pandas.DataFrame.dtypes attribute. The former prints a concise summary of the data frame, including the column names and their data types, while the latter returns a Series with the data type of each column.
提醒一下,我们可以使用pandas.DataFrame.info检查列的数据类型。 方法或带有pandas.DataFrame.dtypes属性。 前者打印数据框的简要摘要,包括列名称及其数据类型,而后者返回带有每个列数据类型的Series 。
# concise summary of the data frame, including the column names and their data types
df_employees.info()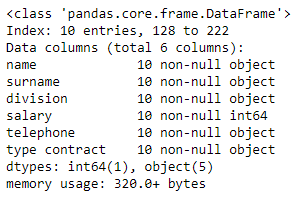
# check the data types of the columns
df_employees.dtypes
4.按标签选择单行(4. Selecting a single row by label)
DataFrames and Series do not necessarily have numerical indexes. By default, the index is an integer indicating the row position; however, it can also be an alphanumeric string. In our current example, the index is the id number of the employee.
DataFrame和Series不一定具有数字索引。 默认情况下,索引是一个整数,指示行的位置; 但是,它也可以是字母数字字符串。 在我们当前的示例中,索引是员工的ID号。
# we can check the indexes of the data frame using the .index method
df_employees.index
# Index(['128', '478', '257', '299', '175', '328', '099', '457', '144', '222'], dtype='object')
# the index is the id number of the employee (categorical variable - type object)To select a single row by id number, we can use the .loc[] indexer providing as input a single string (index name).
要通过ID号选择单个行,我们可以使用.loc []索引器,以提供单个字符串(索引名称)作为输入。
Selecting a single row by label
通过标签选择单行
→ df.loc[string]
→df.loc [字符串]
The code below shows how to select the employee with id number 478.
下面的代码显示了如何选择ID号为478的员工。
# select the employee with id number 478 with the .loc[] indexer
df_employees.loc['478']
As shown above, when a single row is selected, the .loc[] indexer returns a Series object. However, we can also obtain a single-row DataFrame by passing a single-element list to the .loc[] method as follows.
如上所示,当选择单行时, .loc []索引器将返回Series对象。 但是,我们还可以通过将单元素列表传递给.loc []方法来获得单行DataFrame ,如下所示。
# select the employee with id number 478 with the .loc[] indexer, providing a single-element list
df_employees.loc[['478']]
5.按标签选择多行(5. Selecting multiple rows by label)
We can select multiple rows with the .loc[] indexer. Besides a single label, the indexer also accepts as input a list or a slice of labels.
我们可以使用.loc []索引器选择多行。 除单个标签外,索引器还接受列表或标签切片作为输入。
Selecting multiple rows by label
通过标签选择多行
→ df.loc[list_of_strings]
→df.loc [list_of_strings]
→ df.loc[slice_of_strings]
→df.loc [slice_of_strings]
Next, we obtain a subset of our data frame containing the employees with id number 478 and 222 as follows.
接下来,我们获取数据框的子集,其中包含ID号为478和222的员工,如下所示。
# select the employees with id number 478 and 222 with the .loc[] indexer
df_employees.loc[['478', '222']]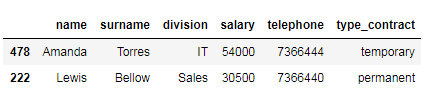
Notice that, the end index of .loc[] method is always included, meaning the selection includes the last label.
注意,始终包含.loc []方法的结束索引,这意味着选择包括最后一个标签。
6.按位置选择一行 (6. Selecting a single row by position)
The .iloc[] indexer is used to index a data frame by position. To select a single row with the .iloc[] attribute, we pass in the row position (a single integer) to the indexer.
.iloc []索引器用于按位置索引数据帧。 要选择具有.iloc []属性的单行,我们将行位置(单个整数)传递给索引器。
Selecting a single row by position
按位置选择单行
→ df.iloc[integer]
→df.iloc [整数]
In the following block of code, we select the row with index 0. In this case, the first row of the DataFrame is returned because in Pandas indexing starts at 0.
在下面的代码块中,我们选择索引为0的行。在这种情况下,将返回DataFrame的第一行,因为在Pandas中索引从0开始。
# select the first row of the data frame
df_employees.iloc[0]
Additionally, the .iloc[] indexer also supports negative integers (starting at -1) as relative positions to the end of the data frame.
此外, .iloc []索引器还支持负整数(从-1开始)作为与数据帧末尾的相对位置。
# select the last row of the data frame - input: integer - output: series
df_employees.iloc[-1]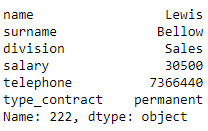
As shown above, when a single row is selected, the .iloc[] indexer returns a Series object that has the column names as indexes. However, as we did with the .loc[] indexer, we can also obtain a DataFrame by passing a single-integer list to the indexer in the following way.
如上所示,当选择单行时, .iloc []索引器将返回一个以列名作为索引的Series对象。 但是,就像我们对.loc []索引器所做的那样,我们还可以通过以下方式将单整数列表传递给索引器来获得DataFrame 。
# select the last row of the data frame - input: list - output: data frame
df_employees.iloc[[-1]]
Lastly, keep in mind that an IndexError is raised when trying to access an index that is out-of-bounds.
最后,请记住,尝试访问超出范围的索引时会引发IndexError 。
# shape of the data frame - 10 rows and 6 columns
df_employees.shape
# (10, 6)
# an IndexError is raised when trying to access an index that is out-of-bounds
df_employees.iloc[10]
# IndexError7.按位置选择多行(7. Selecting multiple rows by position)
To extract multiple rows by position, we pass either a list or a slice object to the .iloc[] indexer.
要按位置提取多行,我们将列表或切片对象传递给.iloc []索引器。
Selecting multiple rows by position
按位置选择多行
→ df.iloc[list_of_integers]
→df.iloc [list_of_integers]
→ df.iloc[slice_of_integers]
→df.iloc [slice_of_integers]
The following block of code shows how to select the first five rows of the data frame using a list of integers.
以下代码块显示如何使用整数列表选择数据帧的前五行。
# select the first five rows of the dataframe using a list
df_employees.iloc[[0, 1, 2, 3, 4]]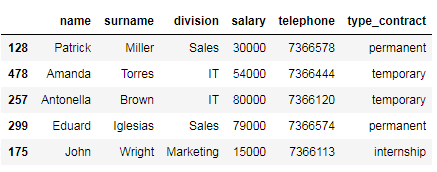
Alternatively, we can obtain the same results using slice notation.
或者,我们可以使用切片符号获得相同的结果。
# select the first five rows of the dataframe using slice notation
df_employees.iloc[0:5]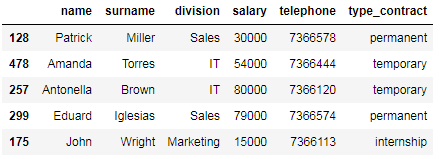
As shown above, Python slicing rules (half-open interval) apply to the .iloc[] attribute, meaning the first index is included, but not the end index.
如上所示, Python切片规则(半开间隔)适用于.iloc []属性,这意味着包括第一个索引,但不包括结束索引。
8.同时选择行和列 (8. Selecting rows and columns simultaneously)
So far, we have learnt how to select rows in a data frame by label or position using the .loc[] and .iloc[] indexers. However, both indexers are not only capable of selecting rows, but also rows and columns simultaneously.
到目前为止,我们已经学习了如何使用.loc []和.iloc []索引器按标签或位置选择数据帧中的行。 但是,两个索引器不仅能够选择行,而且还能同时选择行和列。
To do so, we have to provide the row and column labels/positions separated by a comma as follows:
为此,我们必须提供以逗号分隔的行和列标签/位置,如下所示:
Selecting rows and columns simultaneously
同时选择行和列
→ df.loc[row_labels, column_labels]
→df.loc [行标签,列标签]
→ df.iloc[row_positions, column_positions]
→df.iloc [行位置,列位置]
where row_labels and column_labels can be a single string, a list of strings, or a slice of strings. Likewise, row_positions and column_positions can be a single integer, a list of integers, or a slice of integers.
其中row_labels和column_labels可以是单个字符串,字符串列表或字符串切片。 同样, row_positions和column_positions可以是单个整数,整数列表或整数切片。
The following examples show how to extract rows and columns at once using the .loc[] and .iloc[] indexers.
下面的示例演示如何使用.loc []和.iloc []索引器一次提取行和列。
Selecting a scalar value
选择标量值
We select the salary of the employee with the id number 478 by position and label in the following manner.
我们按职位选择ID号为478的员工的工资,并按以下方式进行标签。
# select the salary of the employee with id number 478 by position
df_employees.iloc[1, 3]
# select the salary of the employee with id number 478 by label
df_employees.loc['478', 'salary']
# 54000In this case, the output of both indexers is an integer.
在这种情况下,两个索引器的输出都是整数。
Selecting a single row and multiple columns
选择单行和多列
We select the name, surname, and salary of the employee with id number 478 by passing a single value as the first argument and a list of values as the second argument, obtaining as a result a Series object.
我们通过传递单个值作为第一个参数,并通过值列表作为第二个参数,选择ID号为478的员工的姓名,姓氏和薪水,从而获得Series对象。
# select the name, surname, and salary of the employee with id number 478 by position
df_employees.iloc[1, [0, 1, 3]]
# select the name, surname, and salary of the employee with id number 478 by label
df_employees.loc['478', ['name', 'surname', 'salary']]
Selecting disjointed rows and columns
选择脱节的行和列
To select multiple rows and columns, we need to pass two list of values to both indexers. The code below shows how to extract the name, surname, and salary of employees with id number 478 and 222.
要选择多个行和列,我们需要将两个值列表传递给两个索引器。 下面的代码显示了如何提取ID号为478和222的员工的姓名,姓氏和薪水。
# select the name, surname, and salary of the employees with id number 478 and 222 by position
df_employees.iloc[[1, 9], [0, 1, 3]]
# select the name, surname, and salary of the employees with id number 478 and 222 by label
df_employees.loc[['478', '222'], ['name', 'surname', 'salary']]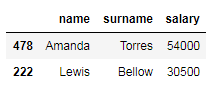
Unlike before, the output of both indexers is a DataFrame object.
与以前不同,两个索引器的输出都是一个DataFrame对象。
Selecting continuous rows and columns
选择连续的行和列
We can extract continuous rows and columns of the data frame by using slice notation. The following code snippet shows how to select the name, surname, and salary of employees with id number 128, 478, 257, and 299.
我们可以使用切片符号提取数据帧的连续行和列。 以下代码段显示了如何选择ID号为128、478、257和299的员工的姓名,姓氏和薪水。
# select the name, surname, and salary of the employees with id number 128, 478, 257, 299 by position
df_employees.iloc[:4, [0, 1, 3]]
# select the name, surname, and salary of the employees with id number 128, 478, 257, 299 by label
df_employees.loc[:'299', ['name', 'surname', 'salary']]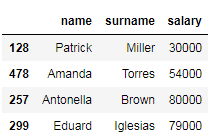
As shown above, we only employ slice notation to extract the rows of the data frame since the id numbers we want to select are continuous (indexes from 0 to 3).
如上所示,由于我们要选择的ID号是连续的(索引从0到3),因此我们仅采用切片符号来提取数据帧的行。
It is important to remember that the .loc[] indexer uses a closed interval, extracting both the start label and the stop label. On the contrary, the .iloc[] indexer employs a half-open interval, so the value at the stop index is not included.
重要的是要记住, .loc []索引器使用一个封闭的间隔,同时提取开始标签和停止标签。 相反, .iloc []索引器使用半开间隔,因此不包括停止索引处的值。
9.使用.at []和.iat []索引器选择标量值 (9. Selecting a scalar value using the .at[] and .iat[] indexers)
As mentioned above, we can select a scalar value by passing two strings/integers separated by a comma to the .loc[] and .iloc[] indexers. Additionally, Pandas provides two optimized functions to extract a scalar value from a data frame object: the .at[] and .iat[] operators. The former extracts a single value by label, while the latter access a single value by position.
如上所述,我们可以通过将两个逗号分隔的字符串/整数传递给.loc []和.iloc []索引器来选择标量值。 此外,熊猫提供了两个优化函数来从数据帧中提取对象的标量值:所述.AT []和.iat []运算符。 前者按标签提取单个值,而后者按位置访问单个值。
Selecting a scalar value by label and position
通过标签和位置选择标量值
→ df.at[string, string]
→df.at [字符串,字符串]
→ df.iat[integer, integer]
→df.iat [整数,整数]
The code below shows how to select the salary of the employee with the id number 478 by label and position with the .at[] and .iat[] indexers.
下面示出了如何通过标签和位置与.AT []和.iat []索引选择与ID号478的雇员的工资的代码。
# select the salary of the employee with id number 478 by position
df_employees.iat[1, 3]
# select the salary of the employee with id number 478 by label
df_employees.at['478', 'salary']
# 54000We can use the %timeit magic function to calculate the execution time of both Python statements. As shown below, the .at[] and .iat[] operators are much faster than the .loc[] and .iloc[] indexers.
我们可以使用%timeit magic函数来计算两个Python语句的执行时间。 如下所示, .at []和.iat []运算符比.loc []和.iloc []索引器要快得多。
# execution time of the loc indexer
%timeit df_employees.loc['478', 'salary']
# execution time of the at indexer
%timeit df_employees.at['478', 'salary']
# execution time of the iloc indexer
%timeit df_employees.iloc[1, 3]
# execution time of the iat indexer
%timeit df_employees.iat[1, 3]
Lastly, it is important to remember that the .at[] and .iat[] indexers can only be used to access a single value, raising a type error when trying to select multiple elements of the data frame.
最后,重要的是要记住, .at []和.iat []索引器只能用于访问单个值,从而在尝试选择数据帧的多个元素时引发类型错误。
# an exception is raised when trying to select multiple elements
df_employees.at['478', ['name', 'surname', 'salary']]
# TypeError10.使用布尔选择选择行(10. Selecting rows using Boolean selection)
So far, we have filtered rows and columns in a data frame by label and position. Alternatively, we can also select a subset in Pandas with boolean indexing. Boolean selection consists of selecting rows of a data frame by providing a boolean value (True or False) for each row.
到目前为止,我们已经按照标签和位置过滤了数据框中的行和列。 或者,我们也可以使用布尔索引在熊猫中选择一个子集。 布尔选择包括通过为每一行提供布尔值(真或假)来选择数据帧的行。
In most cases, this array of booleans is calculated by applying to the values of a single or multiple columns a condition that evaluates to True or False, depending on whether or not the values meet the condition. However, it is also possible to manually create an array of booleans using among other sequences, Numpy arrays, lists, or Pandas Series.
在大多数情况下,此布尔数组是通过将一个条件的值应用于True或False来计算的,具体取决于值是否满足条件。 但是,也可以使用其他序列,Numpy数组,列表或Pandas系列手动创建布尔数组。
Then, the sequence of booleans is placed inside square brackets [], returning the rows associated with a True value.
然后,将布尔值序列放在方括号[]中,返回与True值关联的行。
Selecting rows using Boolean selection
使用布尔选择来选择行
→ df[sequence_of_booleans]
→df [sequence_of_booleans]
根据单列的值进行布尔选择 (Boolean selection according to the values of a single column)
The most common way to filter a data frame according to the values of a single column is by using a comparison operator.
根据单个列的值过滤数据帧的最常见方法是使用比较运算符。
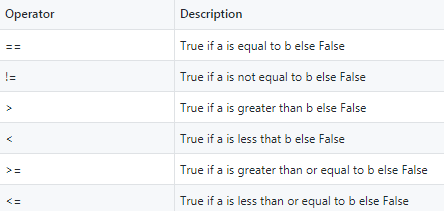
A comparison operator evaluates the relationship between two operands (a and b) and returns True or False depending on whether or not the condition is met. The following table contains the comparison operators available in Python.
比较运算符评估两个操作数(a和b)之间的关系,并根据是否满足条件返回True或False。 下表包含Python中可用的比较运算符。
These comparison operators can be used on a single column of the data frame to obtain a sequence of booleans. For instance, we determine whether the salary of the employee is greater than 45000 euros by using the greater than operator as follows.
这些比较运算符可用于数据帧的单个列上,以获取布尔值序列。 例如,我们使用“大于”运算符确定员工的薪水是否大于45000欧元,如下所示。
# employees with a salary greater than 45000
df_employees['salary'] > 45000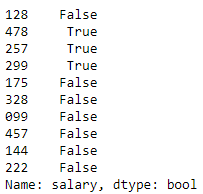
The output is a Series of booleans where salaries higher than 45000 are True and those less than or equal to 45000 are False. As you may notice, the Series of booleans has the same indexes (id number) as the original data frame.
输出是一系列布尔值,其中高于45000的薪水为True,小于或等于45000的薪水为False。 您可能会注意到,布尔值系列具有与原始数据帧相同的索引(标识号)。
This Series can be passed to the indexing operator [] to return only the rows where the result is True.
该系列可以传递给索引运算符[],以仅返回结果为True的行。
# select employees with a salary higher than 45000 euros
df_employees[df_employees['salary'] > 45000]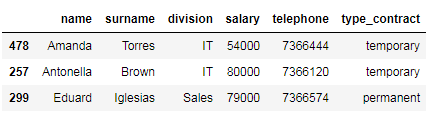
As shown above, we obtain a data frame object containing only the employees with a salary higher than 45000 euros.
如上所示,我们获得一个仅包含薪水高于45000欧元的员工的数据框对象。
根据多列的值进行布尔选择 (Boolean selection according to the values of multiple columns)
Previously, we have filtered a data frame according to a single condition. However, we can also combine multiple boolean expression together using logical operators. In Python, there are three logical operators: and, or, and not. However, these keywords are not available in Pandas for combining multiple boolean conditions. Instead, the following operators are used.
以前,我们是根据单个条件过滤数据帧的。 但是,我们也可以使用逻辑运算符将多个布尔表达式组合在一起。 在Python中,存在三个逻辑运算符:和,或,和不。 但是,这些关键字在Pandas中不可用于组合多个布尔条件。 而是使用以下运算符。

The code below shows how to select employees with a salary greater than 45000 and a permanent contract combining two boolean expressions with the logical operator &.
下面的代码显示了如何选择薪水大于45000并具有两个布尔表达式和逻辑运算符&的永久合同的雇员。
# select employees with a salary higher than 45000 euros and a permanent contract
df_employees[(df_employees['salary'] > 45000) & (df_employees['type_contract'] == 'permanent')]
As you may know, in Python, the comparison operators have a higher precedence than the logical operators. However, it does not apply to Pandas where logical operators have higher precedence than comparison operators. Therefore, we need to wrap each boolean expression in parenthesis to avoid an error.
如您所知,在Python中,比较运算符的优先级高于逻辑运算符。 但是,它不适用于逻辑运算符的优先级高于比较运算符的熊猫。 因此,我们需要将每个布尔表达式包装在括号中以避免错误。
使用Pandas方法进行布尔选择 (Boolean selection using Pandas methods)
Pandas provides a wide range of built-in functions that return a sequence of booleans, being an appealing alternative to more complex boolean expressions that combine comparison and logical operators.
Pandas提供了广泛的内置函数,这些函数返回一系列布尔值,是结合了比较和逻辑运算符的更复杂的布尔表达式的一种吸引人的选择。
The isin method
isin方法
The pandas.Series.isin method takes a sequence of values and returns True at the positions within the Series that match the values in the list.
大熊猫系列 方法采用一系列值,并在Series中与列表中的值匹配的位置返回True。
This method allows us to check for the presence of one or more elements within a column without using the logical operator or. The code below shows how to select employees with a permanent or temporary contract using both the logical operator or and the isin method.
此方法使我们无需使用逻辑运算符or即可检查一列中是否存在一个或多个元素。 下面的代码显示了如何同时使用逻辑运算符或和isin方法来选择具有永久或临时合同的员工。
# select employees with a permanent or temporary contract using the logical operaror or
df_employees[(df_employees['type_contract'] == 'temporary') | (df_employees['type_contract'] == 'permanent')]
# select employees with a permanent or temporary contract using the isin method
df_employees[df_employees['type_contract'].isin(['temporary', 'permanent'])]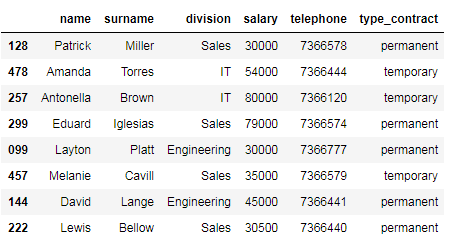
As you can see, the isin method comes in handy for checking multiple or conditions in the same column. Additionally, it is faster!
如您所见,isin方法可用于检查同一列中的多个或条件。 此外,它更快!
# execution time with the logical operator |
%timeit df_employees[(df_employees['type_contract'] == 'temporary') | (df_employees['type_contract'] == 'permanent')]
# execution time with the isin method
%timeit df_employees[df_employees['type_contract'].isin(['temporary', 'permanent'])]
The between method
之间的方法
The pandas.Series.between method takes two scalars separated by a comma which represent the lower and upper boundaries of a range of values and returns True at the positions that lie within that range.
的 熊猫之间的系列 方法采用由逗号分隔的两个标量,它们代表一个值范围的上下边界,并在该范围内的位置处返回True。
The following code selects employees with a salary higher than or equal to 30000 and less than or equal to 80000 euros.
以下代码选择薪水高于或等于30000且小于或等于80000欧元的员工。
# employees with a salary higher than or equal to 30000 and less than or equal to 80000 euros
df_employees[df_employees['salary'].between(30000, 80000)]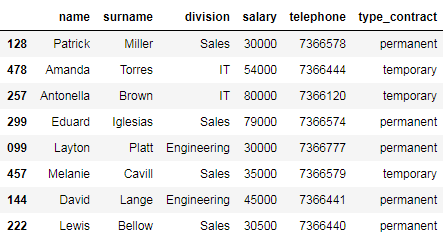
As you can observe, both boundaries (30000 and 80000) are included. To exclude them, we have to pass the argument inclusive=False in the following manner.
如您所见,两个边界(30000和80000)都包括在内。 要排除它们,我们必须按以下方式传递参数inclusive = False 。
# employees with a salary higher than 30000 and less than 80000 euros
df_employees[df_employees['salary'].between(30000, 80000, inclusive=False)]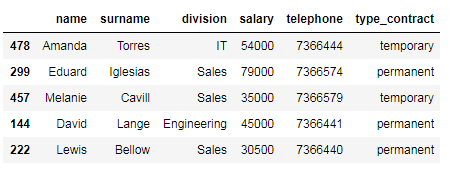
As you may noticed, the above code is equivalent to writing two boolean expressions and evaluate them using the logical operator and.
您可能会注意到,上面的代码等效于编写两个布尔表达式并使用逻辑运算符and对其求值。
# employees with a salary higher than or equal to 30000 and less than or equal to 80000 euros
df_employees[(df_employees['salary']>=30000) & (df_employees['salary']<=80000)]String methods
字符串方法
Additionally, we can also use boolean indexing with string methods as long as they return a sequence of booleans.
此外,我们还可以对字符串方法使用布尔索引,只要它们返回布尔序列即可。
For instance, the pandas.Series.str.contains method checks for the presence of a substring in all the elements of a column and returns a sequence of booleans that we can pass to the indexing operator to filter a data frame.
例如, pandas.Series.str。包含 方法检查列的所有元素中是否存在子字符串,并返回布尔值序列,我们可以将其传递给索引运算符以过滤数据帧。
The code below shows how to select all telephone numbers that contain 57.
下面的代码显示如何选择包含57的所有电话号码。
# select all telephone numbers that contain 57
df_employees[df_employees['telephone'].str.contains('57')]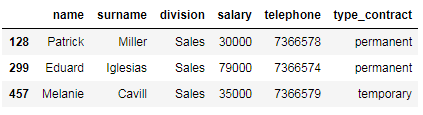
While the contains method evaluates whether or not a substring is contained in each element of a Series, the pandas.Series.str.startswith function checks for the presence of a substring at the beginning of a string. Likewise, the pandas.Series.str.endswith tests if a substring is present at the end of a string.
虽然contains方法将评估Series的每个元素中是否包含子字符串,但pandas.Series.str.startswith 函数检查字符串开头是否存在子字符串。 同样, pandas.Series.str.endswith 测试字符串的末尾是否存在子字符串。
The following code shows how to select employees whose name starts with ‘A’.
以下代码显示了如何选择名称以“ A”开头的员工。
# select employees whose name starts with 'A'
df_employees[df_employees['name'].str.startswith('A')]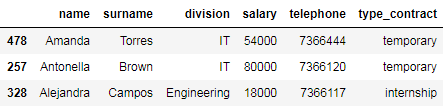
概要(Summary)
In this article, we have covered the most common operations for selecting a subset of data from a Pandas data frame. Additionally, we have provided multiple usage examples. Now! it is the time to put in practice those techniques when cleaning your own data! ✋
在本文中,我们介绍了从Pandas数据框中选择数据子集的最常见操作。 此外,我们提供了多个用法示例。 现在! 现在是时候在清理自己的数据时实践这些技术了! ✋
Besides data filtering, the data cleaning process involves many more operations. If you are still interested in knowing more about data cleaning, take a look at these articles.
除了数据过滤之外,数据清理过程还涉及许多其他操作。 如果您仍然想了解有关数据清理的更多信息,请阅读以下文章。
Thanks for reading 👐
感谢您阅读👐
Amanda ❤️
阿曼达❤️
翻译自: https://towardsdatascience.com/filtering-data-frames-in-pandas-b570b1f834b9
熊猫数据集















 1870
1870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









