





 本文介绍了如何利用潜在狄利克雷分配(LDA)进行收益电话的主题建模,通过Python实现来探索文本数据中的隐藏主题。
本文介绍了如何利用潜在狄利克雷分配(LDA)进行收益电话的主题建模,通过Python实现来探索文本数据中的隐藏主题。
lda隐含狄利克雷分布
Most listed US companies host earnings calls every quarter. These are conference calls where management discusses financial performance and company updates with analysts, investors and the media. Earnings calls are important — they highlight valuable information for investors and provide an opportunity for interaction through Q&A sessions.
大多数美国上市公司每个季度都会召开一次收益电话会议 。 这些是电话会议,管理层与分析师,投资者和媒体讨论财务绩效和公司更新。 收益电话很重要-它们可以为投资者突出有价值的信息,并通过问答环节提供互动的机会。
There are hundreds of earnings calls held each quarter, often with the release of detailed transcripts. But the sheer volume of those transcripts makes analyzing them a daunting task.
每个季度都会举行数百次收益电话会议,通常会发布详细的成绩单。 但是,这些成绩单的数量之多使得对其进行分析是一项艰巨的任务。
Topic modeling is a way to streamline this analysis. It’s an area of natural language processing that helps to make sense of large volumes of text data by identifying the key topics or themes within the data.
主题建模是简化此分析的一种方法。 这是自然语言处理的一个领域,它通过识别数据中的关键主题或主题来帮助理解大量文本数据。
In this article, I show how to apply topic modeling to a set of earnings call transcripts. I use a popular topic modeling approach called Latent Dirichlet Allocation and implement the model using Python.
在本文中,我将展示如何将主题建模应用于一组收益电话记录。 我使用一种流行的主题建模方法,称为Latent Dirichlet Allocation,并使用Python实施该模型。
I also show how topic modeling can require some judgement, and how you can achieve better results by adjusting key parameters.
我还将展示主题建模如何需要一些判断,以及如何通过调整关键参数来获得更好的结果。
什么是主题建模? (What is topic modeling?)
Topic modeling is a form of unsupervised learning that can be applied to unstructured data. In the case of text documents, it identifies words or phrases that have a similar meaning and groups them into ‘topics’ using statistical techniques.
主题建模是一种无监督学习的形式,可以应用于非结构化数据。 对于文本文档,它识别具有相似含义的单词或短语,并使用统计技术将它们分组为“主题”。
Topic modeling is useful for organizing text documents based on the topics within them, and for identifying the words that make up each topic. It can be helpful in automating a process for classifying documents or for uncovering concealed meaning (hidden semantic structures) within text data.
主题建模对于根据文本文档中的主题组织文本文档以及识别组成每个主题的单词非常有用。 它有助于自动化文档分类过程或揭示文本数据中的隐藏含义(隐藏的语义结构)。
When applied to natural language, topic modeling requires interpretation of the identified topics — this is where judgment plays a role. The goal is to ensure that the topics and their allocations make sense for the context and purpose of the modeling exercise.
当应用于自然语言时,主题建模需要对识别出的主题进行解释-这是判断力所起作用的地方。 目的是确保主题及其分配对于建模练习的上下文和目的有意义。
潜在狄利克雷分配(LDA) (Latent Dirichlet Allocation (LDA))
Latent Dirichlet Allocation (LDA) is a popular approach for topic modeling. It works by identifying the key topics within a set of text documents, and the key words that make up each topic.
潜在狄利克雷分配 (LDA)是用于主题建模的流行方法。 它通过识别一组文本文档中的关键主题以及组成每个主题的关键字来工作。
Under LDA, each document is assumed to have a mix of underlying (latent) topics, each topic with a certain probability of occurring in the document. Individual text documents can therefore be represented by the topics that make them up. In this way, LDA topic modeling can be used to categorize or classify documents based on their topic content.
在LDA下,假定每个文档都包含基础(潜在)主题,每个主题在文档中都有一定的发生概率。 因此,各个文本文档可以由组成它们的主题来表示。 这样,LDA主题建模可用于基于文档的主题内容对文档进行分类或分类。
Each LDA topic model requires:
每个LDA主题模型都要求:
- A set of documents for training the model — the training corpus 一组用于训练模型的文档-训练语料库
- A dictionary of words to form the vocabulary used in the model — this can be derived from the training corpus 构成模型中使用的词汇的单词词典-这可以从训练语料库中得出
Once a model has been trained, it can be applied to a new set of documents to identify the topics in those new documents.
训练模型后,可以将其应用于一组新文档,以标识这些新文档中的主题。
In this article, I show how to implement LDA using the gensim package in Python. This is a powerful yet accessible package for topic modeling.
在本文中,我将展示如何使用python中的gensim包来实现LDA。 这是用于主题建模的功能强大但可访问的软件包。
模型开发,评估和部署 (Model development, evaluation and deployment)
In the following, I step through the process of training, evaluating, refining and applying an LDA topic model, with associated segments of code (Python v3.7.7).
在下文中,我将逐步训练,评估,改进和应用LDA主题模型以及相关的代码段(Python v3.7.7)。
For a full listing of the code, please see the expanded version of this article
有关代码的完整列表,请参见本文的 扩展版本。
导入库 (Importing libraries)
We’ll need to first import libraries for requesting and parsing earnings call transcripts (requests and BeautifulSoup), text pre-processing (SpaCy), displaying results (matplotlib, pprint and wordcloud) and LDA (gensim).
我们将需要首先导入库,以请求和解析收入电话成绩单(请求和BeautifulSoup),文本预处理(SpaCy),显示结果(matplotlib,pprint和wordcloud)和LDA(gensim)。
import requests
from bs4 import BeautifulSoup
import gensim
import gensim.corpora as corpora
from gensim import models
import matplotlib.pyplot as plt
import spacy
from pprint import pprint
from wordcloud import WordCloud
from mpl_toolkits import mplot3d
import matplotlib.pyplot as pltnlp = spacy.load("en_core_web_lg")
nlp.max_length = 1500000 #Ensure sufficient memory采购收益通话记录 (Sourcing earnings call transcripts)
Earnings call transcripts are available from company websites or through third-party providers. One popular source is the Seeking Alpha website, from which recent transcripts are freely available.
可从公司网站或通过第三方提供商获得收入电话记录。 Seeking Alpha网站是一个受欢迎的资源,可以免费获取最新成绩单。

Individual transcripts can be parsed directly through URL links. The following is an example for a Dell earnings call transcript. I store the resulting text in a variable called ECallTxt.
单个成绩单可以直接通过URL链接进行解析。 以下是Dell收入电话会议记录的示例。 我将结果文本存储在名为ECallTxt的变量中。
URL_text = r'https://seekingalpha.com/article/4371280-dell-technologies-inc-dell-management-on-q2-2021-results-earnings-call-transcript' #Dell Q2 2021#Grab the response
response = requests.get(URL_text)#Parse the response
soup = BeautifulSoup(response.content, 'lxml')#Extract the text portion of the transcript
ECallTxt = soup.find('article').textUnfortunately, this approach doesn’t always work, based on my experience with the Seeking Alpha website. This could be due to site protection mechanisms. Either way, it can be quite disruptive. To get around it, I’ve separately downloaded transcripts and stored them in local text files.
不幸的是,根据我在Seeking Alpha网站上的经验,这种方法并不总是有效。 这可能是由于站点保护机制所致。 无论哪种方式,它都可能造成破坏。 为了解决这个问题,我单独下载了成绩单并将其存储在本地文本文件中。
FilePath = r'<your local file path>'I downloaded a set of 36 earnings call transcripts for this exercise, covering a range of different companies and industries. I list them in a variable called DocList. These will form the training corpus of our model.
我为此练习下载了36个收入电话会议记录,涵盖了不同的公司和行业。 我在一个名为DocList的变量中列出了它们。 这些将构成我们模型的训练语料库。
#Transcripts to form training corpus (36 in total)
DocList = ['ADSK-Q2-2021', 'ANF-Q2-2020', ... 'ECC-Q2-2020']文字预处理 (Text pre-processing)
We prepare our transcripts for topic modeling by cleaning them (removing special characters and extra spaces), removing stop words and punctuation, lemmatizing and selecting the parts-of-speech that we wish to retain. We’ll keep nouns, adjectives and verbs — this seems to work well.
我们通过清理记录(删除特殊字符和多余的空格),删除停用词和标点符号,对词进行词形化并选择要保留的词性,来准备用于主题建模的记录本。 我们将保留名词,形容词和动词-看来效果很好。
You can learn more about text pre-processing for natural language processing workflows in this introductory article.
您可以在此 介绍性文章中 了解有关自然语言处理工作流程的文本预处理的更多信息 。
We prepare each transcript in turn, by looping through DocList and collecting the results in two lists:
我们依次遍历DocList并将结果收集到两个列表中,从而依次准备每个成绩单:
A list of lists, made up of the 36 transcripts forming the training corpus, with each transcript being a list of words. I call this
ECallDocuments.列表列表,由构成训练语料库的36个成绩单组成,每个成绩单是单词列表。 我称之为
ECallDocuments。A single list of all the words in the 36 transcripts, which I use later for illustrating the training corpus as a word cloud. I call this
ECallWordCloud.这36个笔录中所有单词的一个列表,稍后我将其用于说明训练语料库为单词云。 我称之为
ECallWordCloud。
# Topic modeling text pre-processing
ECallDocuments = [] #List to store all transcripts in the training corpus (list of lists)
ECallWordCloud = [] #Single list version of the training corpus documents for word cloud
#Loop through all transcripts in the training corpus
for doc in DocList:
ECallTxt = open(FilePath + doc + '.txt', 'r').read() #Open text file, including the 'read' flag to convert string
#Clean text
ECallTxt = ECallTxt.strip() #Remove white space at the beginning and end
ECallTxt = ECallTxt.replace('\n', ' ') #Replace the \n with space
ECallTxt = ECallTxt.replace('\r', '') #Replace the \r with null
ECallTxt = ECallTxt.replace(' ', ' ') #Replace ' ' with space
ECallTxt = ECallTxt.replace(' ', ' ') #Replace ' ' with space
while ' ' in ECallTxt:
ECallTxt = ECallTxt.replace(' ', ' ') #Remove extra spaces
#Parse with SpaCy
ECall = nlp(ECallTxt)
ECallDoc = [] #Temporary list to store individual transcripts
#Further cleaning and selection of text characteristics
for token in ECall:
if token.is_stop == False and token.is_punct == False and (token.pos_ == "NOUN" or token.pos_ == "ADJ" or token.pos_ =="VERB"): #Retain words that are neither a stop word nor punctuation, and only if a Noun, Adjective or Verb
ECallDoc.append(token.lemma_.lower()) #Lemmatize and convert to lower case
ECallWordCloud.append(token.lemma_.lower()) #Build the word cloud list
ECallDocuments.append(ECallDoc) #Build the training corpus (list of lists)检查训练语料库 (Inspecting the training corpus)
It’s helpful to have an idea of what the training corpus looks like — there are various ways to do this, but I tend to like word clouds.
了解训练语料库的外观会很有帮助-有多种方法可以执行此操作,但是我倾向于喜欢词云。
#Generate and plot word cloud of training corpus
wordcloud = WordCloud(background_color="white").generate(','.join(ECallWordCloud)) #The 'join' method converts the training corpus list to textplt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()The word cloud of the training corpus shows a number of words that you might expect to see in company earnings calls — words related to customers, earnings periods (“quarter”), financials (“increase” and “growth”) and words to express opinions (“think” and “expect”).
培训语料库的词云显示了您可能期望在公司收益电话中看到的许多词-与客户有关的词,收益期(“季度”),财务(“增长”和“增长”)以及要表达的词意见(“思考”和“期望”)。

训练LDA模型 (Training the LDA model)
To train our LDA model, we first need to form a dictionary by mapping the training corpus to word IDs. We then convert the words in each transcript to numbers (text representation) using a bag-of-words approach (for more information about bag-of-words and other text representations, see this introductory article).
要训练我们的LDA模型,我们首先需要通过将训练语料库映射到单词ID来形成字典。 然后,我们使用词袋方法将每个成绩单中的词转换为数字(文本表示)( 有关词袋和其他文本表示的更多信息,请参见此 介绍性文章 )。
#Map training corpus to IDs
ID2word = corpora.Dictionary(ECallDocuments)#Convert all transcripts in training corpus using bag-of-words
train_corpus = [ID2word.doc2bow(doc) for doc in ECallDocuments]We use the gensim package to generate our LDA model. This requires training the model using our training corpus and selecting the number of topics as an input. Since we don’t know how many topics are likely to emerge from the training corpus, let’s start with 5.
我们使用gensim包来生成我们的LDA模型。 这需要使用我们的训练语料库训练模型并选择主题数作为输入。 由于我们不知道培训语料库可能会出现多少个主题,因此从5开始。
NUM_topics = 5 #Set number of topics#Train the LDA model on the training corpus
lda_model = gensim.models.LdaMulticore(corpus=train_corpus, num_topics=NUM_topics, id2word=ID2word, passes=100)The passes flag refers to the number of iterations through the corpus during training — the higher, the better for defining topics, albeit at the cost of extra processing time. We set the flag at passes=100 to produce better results.
passes标志是指训练过程中语料库的迭代次数-越高,定义主题越好,尽管这会花费额外的处理时间。 我们将标志设置为passes=100以产生更好的结果。
I use the LdaMulticore version of the model which makes use of parallelization for faster processing. If your machine cannot accommodate this, you can use the standard LDA model offered by gensim instead.
我使用模型的LdaMulticore版本,该版本利用并行化来加快处理速度。 如果您的机器不能满足此要求,则可以使用gensim提供的标准LDA模型 。
观察主题 (Observing the topics)
We can observe the key words in each topic that results from the training.
我们可以观察到培训产生的每个主题中的关键词。
pprint(lda_model.print_topics(num_words=4))We use pprint to print in an easier-to-read format. The above code prints the top 4 keywords in each of the 5 topics generated through training:
我们使用pprint以易于阅读的格式进行打印。 上面的代码在通过培训生成的5个主题中的每个主题中打印前4个关键字:
[(TOPIC 0,
[( 主题0 ,
‘0.023*”customer” + 0.019*”year” + 0.014*”think” + 0.012*”quarter”’),
'0.023 *“客户” + 0.019 *“年” + 0.014 *“思考” + 0.012 *“季度”'),
(TOPIC 1,
( 主题 1 ,
‘0.017*”quarter” + 0.015*”year” + 0.012*”store” + 0.011*”customer”’),
'0.017 *“季度” + 0.015 *“年” + 0.012 *“商店” + 0.011 *“客户”'),
(TOPIC 2,
( 主题2 ,
‘0.015*”test” + 0.010*”think” + 0.009*”go” + 0.009*”question”’),
'0.015 *“测试” + 0.010 *“思考” + 0.009 *“执行” + 0.009 *“问题”'),
(TOPIC 3,
( 主题3 ,
‘0.020*”quarter” + 0.014*”think” + 0.013*”year” + 0.010*”market”’),
'0.020 *“季度” + 0.014 *“思考” + 0.013 *“年” + 0.010 *“市场”'),
(TOPIC 4,
( 主题4 ,
‘0.020*”cloud” + 0.016*”year” + 0.015*”™” + 0.010*”customer”’)]
'0.020 *“云” + 0.016 *“年” + 0.015 *“™” + 0.010 *“客户”')]
Also shown is the frequency of each keyword (the decimal number next to each keyword).
还显示了每个关键字的频率(每个关键字旁边的十进制数字)。
How good are these topics?
这些主题有多好?
To answer this question, let’s evaluate our model results.
为了回答这个问题,让我们评估一下模型结果。
模型评估 (Model evaluation)
There are several ways to evaluate LDA models, and they’re not all based on numbers. Context has a role to play, as does the practical usefulness of the generated topics.
有几种评估LDA模型的方法,它们并非全部基于数字。 上下文可以发挥作用,所生成主题的实用性也可以发挥作用。
In terms of quantitative measures, a common way to evaluate LDA models is through the coherence score.
在定量度量方面,评估LDA模型的常用方法是通过一致性得分。
The coherence score of an LDA model measures the degree of semantic similarity between words in each topic [1]. All else equal, a higher coherence score is better, as it indicates a higher degree of likeness in the meaning of the words within each topic.
LDA模型的连贯性评分衡量每个主题中单词之间的语义相似度[1]。 在所有其他条件相同的情况下,较高的连贯性评分较好,因为这表明每个主题中单词的含义具有较高的相似度。
We can measure our model’s coherence using the CoherenceModel within gensim.
我们可以使用gensim中的CoherenceModel来测量模型的相干性。
#Set up coherence model
coherence_model_lda = gensim.models.CoherenceModel(model=lda_model, texts=ECallDocuments, dictionary=ID2word, coherence='c_v')# Calculate and print coherence
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score:', coherence_lda)We choose coherence='c_v' as our coherence method, which has been shown to be effective [2] and is a popular choice. Using this method, coherence scores between 0 and 1 are typical.
我们选择coherence='c_v'作为我们的相干方法,这已被证明是有效的[2],并且是一种流行的选择。 使用此方法,典型的相干分数在0和1之间。
The coherence score of our model is:
我们模型的一致性得分为:
Coherence Score: 0.289907
相干分数:0.289907
This does not appear to be very high… is it possible to improve this?
这似乎不是很高……可以改善这一点吗?
模型改进 (Model improvement)
LDA models can be improved by adjusting the text representation stage or by changing model parameters.
可以通过调整文本表示阶段或更改模型参数来改进LDA模型。
Text representation:
文字表示:
We used a bag-of-words approach to convert our words to numbers. Whilst straightforward, bag-of-words tends to produce representations that have low information content (sparse vectors). This can lead to poor results.
我们使用词袋法将词转换为数字。 虽然简单,但词袋往往会产生具有低信息内容(稀疏向量)的表示形式。 这可能导致不良结果。
An alternative approach is TF-IDF. This adjusts for words that appear frequently but have low semantic value, relative to words that appear infrequently but with higher semantic value. This tends to produce better results.
另一种方法是TF-IDF。 相对于不经常出现但具有较高语义值的单词,这会针对频繁出现但具有较低语义值的单词进行调整。 这往往会产生更好的结果。
We can apply TF-IDF to our model by recalculating our corpus.
我们可以通过重新计算语料库将TF-IDF应用于模型。
#Convert all transcripts in training corpus using TF-IDF
train_corpus = [ID2word.doc2bow(doc) for doc in ECallDocuments]TFIDF = models.TfidfModel(train_corpus) # Fit TF-IDF model
trans_TFIDF = TFIDF[train_corpus] # Apply TF-IDF modelOur training corpus now becomes trans_TFIDF.
我们的训练语料库现在变为trans_TFIDF 。
We can now re-train our model and observe the updated coherence score:
现在,我们可以重新训练模型并观察更新的一致性得分:
Coherence Score: 0.437026
相干分数:0.437026
That’s an improvement!
这是一个进步!
Model parameters:
型号参数:
The parameters that we will change to try and improve our model’s coherence are:
我们将尝试更改以提高模型一致性的参数为:
Number of topics — We had arbitrarily selected 5 as a starting point, but we can adjust this.
主题数 -我们已任意选择5个起点,但是我们可以对此进行调整。
Random seed — If this is not set to a specific number, the model results will vary with each run. We can set this to a number that leads to better coherence.
随机种子 -如果未将其设置为特定数字,则每次运行的模型结果都会有所不同。 我们可以将其设置为可以提高一致性的数字。
Alpha — This determines the document-topic density [3], ie. the extent to which topics are distributed amongst documents. It will be chosen automatically unless we specify it. A low value of alpha results in fewer topics per document, and a high value of alpha results in more topics per document. This is an area where some judgement is helpful — having better topic distributions can make it easier to differentiate documents in cases where a single topic would otherwise dominate. This implies the selection of a higher alpha in such cases, even if it results in lower coherence scores.
Alpha-确定文档主题密度[3],即。 主题在文档中分布的程度。 除非我们指定,否则它将自动选择。 较低的alpha值将导致每个文档的主题减少,而较高的alpha值将导致每个文档的主题增加。 在这个领域中,有些判断是有帮助的-具有更好的主题分布可以使在单个主题原本会占优势的情况下更容易区分文档。 这意味着在这种情况下选择较高的alpha,即使它导致较低的相干分数。
Eta — This determines the topic-word density, ie. the extent to which words are distributed amongst topics. It will also be chosen automatically unless we specify it. With a high Eta, topics are made up of more words from the corpus than with a low Eta.
Eta —确定主题词的密度,即。 单词在主题之间分布的程度。 除非我们指定,否则也会自动选择它。 Eta较高时,主题比Eta较低时由语料库中更多的单词组成。
We can explore the effect of changing the above parameters by calculating our model’s coherence for a range of different parameter values and plotting the results [4]. The code below illustrates the case for the ‘number of topics’ parameter, but you can modify it to accommodate different parameters as required.
我们可以通过计算模型在不同参数值范围内的相干性并绘制结果来探索更改上述参数的效果[4]。 下面的代码说明了“主题数”参数的情况,但是您可以根据需要修改它以适应不同的参数。
#Coherence values for varying the number of topics
def compute_coherence_values(corpus, dictionary, alpha, seed, texts, start, limit, step):
coherence_values = []
model_list = []
for num_topics in range(start, limit, step):
model = gensim.models.LdaMulticore(corpus=corpus, id2word=dictionary, alpha=alpha, num_topics=num_topics, random_state=seed, passes=100)
model_list.append(model)
coherencemodel = gensim.models.CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
model_list, coherence_values = compute_coherence_values(corpus=trans_TFIDF, dictionary=ID2word, alpha=ALPHA, seed=SEED, texts=ECallDocuments, start=2, limit=10, step=1)
#Plot graph
limit=10; start=2; step=1;
x = range(start, limit, step)
plt.plot(x, coherence_values)
plt.xlabel("Number of Topics")
plt.ylabel("Coherence score")
plt.legend(("coherence"), loc='best')
plt.show()You may need to use some trial-and-error as you explore the effects of changing parameters. This is because of interaction between parameters — changing any one parameter affects the coherence scores generated by the other parameters, and vice-versa.
在探索更改参数的效果时,可能需要使用一些反复试验。 这是由于参数之间的交互作用-更改任何一个参数都会影响其他参数生成的相干得分,反之亦然。
In our model’s case, the coherence scores for different parameter values are shown below:
在我们模型的情况下,不同参数值的相干得分如下所示:
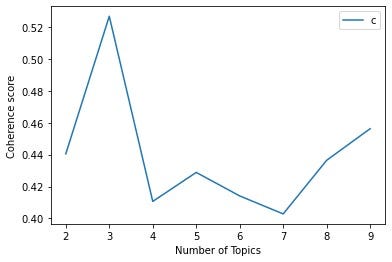

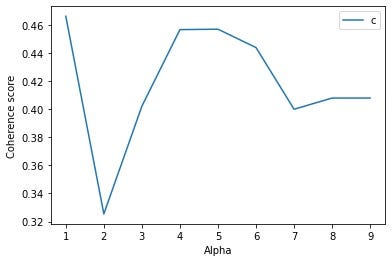

Balancing the effects of the different parameter choices, and using a bit of judgement (particularly with alpha — weighing coherence against document-topic density), I chose the following parameters:
为了平衡不同参数选择的影响,并使用一些判断力(尤其是使用alpha -权衡相干性对文档主题密度),我选择了以下参数:
- Number of topics = 3 主题数= 3
- Random seed = 75 随机种子= 75
- Alpha = 0.9 阿尔法= 0.9
- Eta = 0.35 估计值= 0.35
With these parameter choices, what does our model’s coherence now look like?
通过这些参数选择,我们的模型的连贯性现在看起来像什么?
Coherence Score: 0.535576
相干分数:0.535576
That’s looking good!
看起来不错!
模型结果 (Model results)
Now that we’ve fine-tuned our model and have selected our parameters, let’s take a look at the topics that it generates (remembering there are now 3 topics). Once again, we can use word clouds.
现在,我们已经微调了模型并选择了参数,让我们看一下它生成的主题(记住现在有3个主题)。 再一次,我们可以使用词云。
#Generate topic word clouds
topic = 0 # Initialize counterwhile topic < NUM_topics:
topic_words_freq = dict(lda_model.show_topic(topic, topn=50))
topic += 1 # Generate Word Cloud for topic using frequencies
wordcloud = WordCloud(background_color="white").generate_from_frequencies(topic_words_freq)
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()


How do these topics look? At first glance, they appear to have some intuitive sense.
这些主题看起来如何? 乍一看,它们似乎具有一定的直觉。
LDA modeling won’t label topics for you. In fact, it won’t tell you much about the topics other than their word distributions and certain metrics like coherence. What the topics imply in a practical sense depends on how you wish to interpret them.
LDA建模不会为您标记主题。 实际上,除了主题的词分布和诸如连贯性之类的某些度量标准外,它不会告诉您太多其他主题。 主题在实际意义上暗示的内容取决于您希望如何解释它们。
For our 3 topics, let’s take a closer look. We’ll generate the document-topic densities across the 36 documents in our training corpus.
对于我们的3个主题,让我们仔细看看。 我们将在我们的训练语料库中的36个文档中生成文档主题密度。
#Generate document-topic density across training corpus
doc_no = 0 #Set document counterfor doc in ECallDocuments:
TFIDF_doc = TFIDF[corpus[doc_no]] #Apply TFIDF model
print(lda_model.get_document_topics(TFIDF_doc))
doc_no += 1Below are the document-topic densities for 3 of the transcripts in the training corpus:
以下是训练语料库中3个笔录的文档主题密度:
Highest Topic 0: [(0, 0.8202308), (1, 0.0998479), (2, 0.07992126)]
最高主题0: [( 0,0.8202308 ),(1,0.0998479),(2,0.07992126)]
Highest Topic 1: [(0, 0.07596862), (1, 0.8596242), (2, 0.06440719)]
最高主题1: [(0,0.07596862),( 1,0.8596242 ),(2,0.06440719)]
Highest Topic 2: [(0, 0.21165603), (1, 0.31834567), (2, 0.46999827)]
最高主题2: [(0,0.21165603),(1,0.31834567),( 2,0.46999827 )]
The above 3 transcripts have the highest allocations to Topics 0, 1 and 2 respectively.
以上3个成绩单分别对主题0、1和2分配最高。
The first transcript (highest Topic 0) is from NVIDIA Corporation. This is a technology company that manufactures computer hardware and peripherals. NVIDIA’s GPUs are in fact prominent in hardware setups for modern deep learning applications. Not surprisingly, NVIDIA’s earnings call features plenty of discussion around cloud computing, servers and related areas of technology. This suggests that Topic 0 may be technology-related.
第一个成绩单(最高主题0)来自NVIDIA Corporation 。 这是一家制造计算机硬件和外围设备的技术公司。 实际上,NVIDIA的GPU在现代深度学习应用程序的硬件设置中很突出。 毫不奇怪,NVIDIA的电话会议围绕云计算,服务器和相关技术领域进行了大量讨论。 这表明主题0可能与技术有关。
The second transcript (highest Topic 1) is from Kohl’s Corporation. This is a retail products and department store company. Kohl’s earnings call discusses ‘comps’ (financial metric comparisons between earnings periods), retail stores, holiday periods (sales figures) and retail brands. This suggests that Topic 1 is retail-related.
第二份成绩单(最高主题1)来自Kohl's Corporation 。 这是一家零售产品和百货公司。 Kohl的收益电话讨论了“ comps”(收益期之间的财务指标比较),零售商店,假期(销售数字)和零售品牌。 这表明主题1与零售相关。
The third transcript (highest Topic 2) is from StealthGas Incorporated. This company specializes in transporting petrochemical and gas products. Stealth’s earnings call features plenty of discussion around vessels, charters, ships, voyages and (cubic) capacity. This suggests that Topic 2 is related to logistics.
第三份成绩单(最高主题2)来自StealthGas Incorporated 。 该公司专门从事石油化工和天然气产品的运输。 Stealth的收益电话包含有关船只,租赁,船舶,航次和(立方)容量的大量讨论。 这表明主题2与物流有关。
Based on these observations, we can label the 3 topics as follows:
基于这些观察,我们可以将3个主题标记如下:
Topic 0 — IT & Technology
主题0 — IT与技术
Topic 1 — Retail & Customer Management
主题1 — 零售与客户管理
Topic 2 — Logistics
主题2- 物流
We’ve now successfully trained our LDA topic model and have identified sensible topics. The model is now ready to deploy on new earnings call transcripts which do not form a part of the training corpus.
现在,我们已经成功地训练了LDA主题模型,并确定了明智的主题。 现在,该模型可以部署在不构成培训语料库一部分的新收入电话会议记录上。
在新的成绩单上部署模型 (Deploying the model on new transcripts)
I selected 6 new earnings call transcripts to assess our newly trained topic model.
我选择了6个新的收入通话记录,以评估我们新训练的主题模型。
We go through a similar process of preparing these new transcripts as we did for the training corpus, ie. cleaning, removing stop words and punctuation, lemmatizing and selecting the parts-of-speech to retain. Please see the expanded version of this article for the code to do this.
我们经历了与准备训练语料库相同的准备这些新成绩单的过程。 清洁,删除停用词和标点符号,词形修饰并选择要保留的词性。 请参阅本文的 扩展版本 以获取执行此操作的代码 。
We can then apply our trained model to the new transcripts.
然后,我们可以将训练有素的模型应用于新的成绩单。
#Apply trained model to new transcripts
NewDocumentTopix = [] #For plotting the new document topicsdoc_no = 0 #Set document counterfor doc in NewDocuments:
new_corpus = [ID2word.doc2bow(doc) for doc in NewDocuments]
new_TFIDF = models.TfidfModel(new_corpus)
TFIDF_doc = TFIDF[new_corpus[doc_no]]
NewDocumentTopix.append(lda_model.get_document_topics(TFIDF_doc))
doc_no += 1Here, I calculate new_corpus and new_TFIDF for the new transcripts. I also create a list called NewDocumentTopix to store the new document-topic densities. This is for plotting and investigating the topic distributions for the new transcripts.
在这里,我为新的成绩单计算了new_corpus和new_TFIDF 。 我还创建了一个名为NewDocumentTopix的列表来存储新的文档主题密度。 这是用于绘制和调查新成绩单的主题分布。
观察新成绩单的文档主题密度 (Observing the document-topic densities of the new transcripts)
Let’s see how our new transcripts are allocated to our topics. An easy way to do this is to plot the topic distributions.
让我们看看如何将新的成绩单分配给我们的主题。 一种简单的方法是绘制主题分布。
#Plotting topic distributions of the new transcripts
#Initialize 3D plot
ax = plt.axes(projection='3d')
#Get data points
x_data = []
y_data = []
z_data = []
count = 0 # Counter for loop
for data_point in NewDocumentTopix:
#'data_point' is an element in NewDocumentTopix (level 1), each of which has 3 elements (level 2), each of which in turn has 2 elements (level 3)
x_data.append(data_point[0][1]) #'x axis' data is always the first of the 3 elements (level 2) and the topic allocation is the 2nd element (level 3)
y_data.append(data_point[1][1]) #'y axis' data is always the second of the 3 elements (level 2)
z_data.append(data_point[2][1]) #'y axis' data is always the third of the 3 elements (level 2)
count += 1
#Plot topics data 3D
ax.scatter3D(x_data, z_data, y_data) #Reversed 'y' and 'z' axes to place topics 0 & 1 in the 'base' and topic 2 as 'height', matching the 2D graphs
plt.xlabel("Topic 0")
plt.ylabel("Topic 2")
plt.legend(("Topic Distribution"), loc='best')
plt.show()
#Plot topics data 2D (x and y axes only)
plt.scatter(x_data, y_data, marker='o')
plt.xlabel("Topic 0")
plt.ylabel("Topic 1")
plt.legend(("Topic Distribution"), loc='best')
plt.show()
#Plot topics data 2D (z and y axes only)
plt.scatter(z_data, y_data, marker='o')
plt.xlabel("Topic 2")
plt.ylabel("Topic 1")
plt.legend(("Topic Distribution"), loc='best')
plt.show()The above code plots a 3D graph (since there are 3 topics) and two 2D graphs (2 topics at at time) to assist our intuition.
上面的代码绘制了一个3D图形(因为有3个主题)和两个2D图形(一次有2个主题),以帮助我们理解。
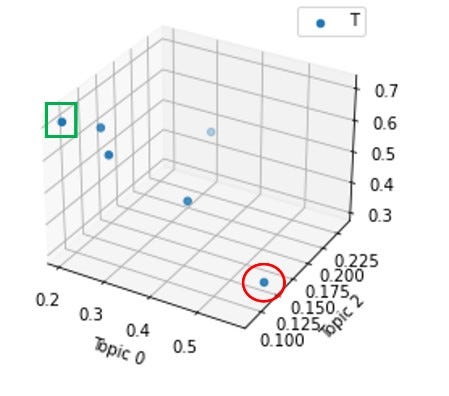
The 3D graph shows how our 6 new transcripts are allocated amongst the 3 topics (each dot represents 1 transcript). If we think of the 3D graph as a cube, the vertical axis (not labelled) is for Topic 2, while the two horizontal axes forming the ‘base’ of the cube (labelled) are for Topic 0 and Topic 1.
3D图显示了我们的6个新成绩单是如何在3个主题之间分配的(每个点代表1个成绩单)。 如果我们将3D图形视为一个立方体,则垂直轴(未标记)用于主题2,而构成立方体“基部”的两个水平轴(已标记)用于主题0和主题1。
Based on the 3D graph, we see that there’s a good distribution of topics amongst the transcripts. This implies decent grounds for differentiation between the transcripts based on the topic allocations.
基于3D图,我们看到成绩单之间的主题分布很好。 这意味着基于主题分配在成绩单之间进行区分的合理基础。
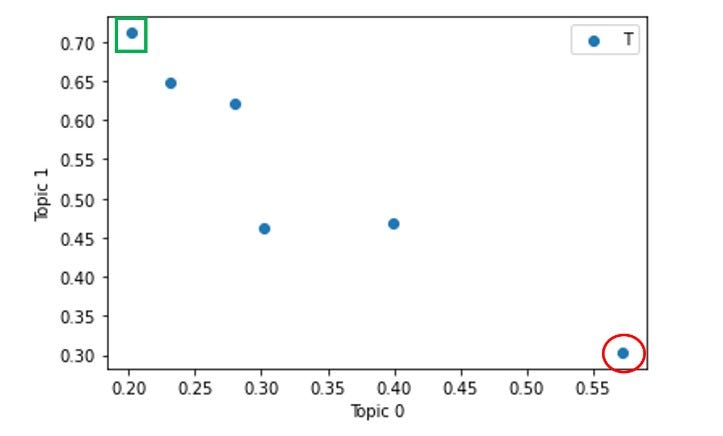
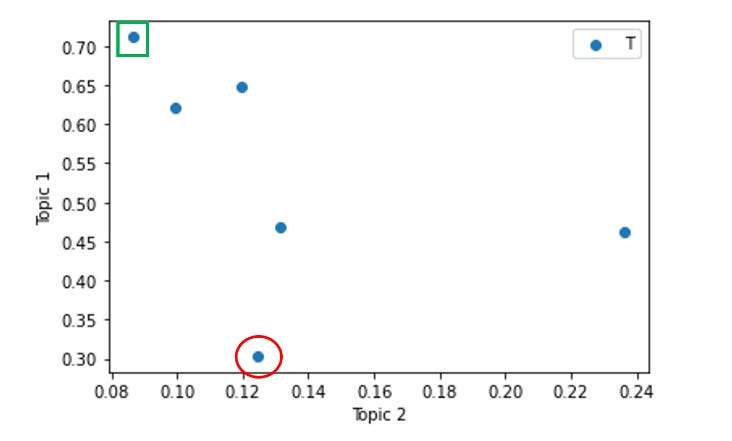
I’ve marked two of the 6 transcripts in the above charts — one with a (red) circle and the other with a (green) square. Let’s look closer at these two transcripts to see if our topic model makes sense.
在上面的图表中,我已经标记了6个成绩单中的两个-一个带有(红色)圆圈,另一个带有(绿色)正方形。 让我们仔细看看这两个笔录,看看我们的主题模型是否有意义。
The red circle transcript is for Titan Pharmaceuticals. This has a topic distribution of 57% Topic 0, 31% Topic 1 and 12% Topic 2. This implies that the majority of the earnings call discussed technology-related areas and most of the remainder discussed retail or customer-related issues. Although not quite as obvious as for NVIDEA, the Titan earnings call did spend some time discussing digital communications, testing, design and commercial operations. There is also some discussion on branding and customers. So, the topic distribution seems reasonable.
红色圆圈的成绩单是泰坦制药的。 这具有主题分布为57%的主题0、31%的主题1和12%的主题2。这意味着大多数盈余电话讨论了与技术相关的领域,其余大部分讨论了与零售或客户相关的问题。 尽管与NVIDEA相比不太明显,但Titan的电话会议确实花了一些时间讨论数字通信,测试,设计和商业运营。 关于品牌和客户也有一些讨论。 因此,主题分布似乎是合理的。
The green square transcript is for Sundial Growers, a cannabis grower and distributor. This has a topic distribution of 20% Topic 0, 71% Topic 1 and 9% Topic 2. This implies a majority discussion around Topic 1, retail and customer management, in the earnings call. There is indeed lots of discussion around retail stores, customers, earnings period comparisons and branding on the Sundial Growers transcript. This topic distribution certainly seems credible.
绿色方形的抄本是给大麻种植者和分销商日d种植者的。 这具有20%的主题0、71%的主题1和9%的主题2的主题分布。这意味着在收益调用中围绕主题1,零售和客户管理的多数讨论。 在日d种植者笔录上确实有很多有关零售店,客户,收益期比较和品牌的讨论。 这个主题分布肯定是可信的。
Our new transcripts therefore appear to have been sensibly allocated to topics based on our trained model.
因此,我们的新成绩单似乎已经根据我们训练有素的模型合理地分配给了主题。
Better results can be achieved, of course, with a larger training corpus and more attention to parameter fine-tuning. Nevertheless, this simple exercise demonstrates how effective topic modeling can be, with good results being achievable with relative ease by using tools such as gensim.
当然,通过更大的训练语料库和更多地关注参数微调,可以获得更好的结果。 但是,此简单练习演示了如何有效地进行主题建模,并且可以通过使用诸如gensim之类的工具相对容易地获得良好的结果。
结论 (Conclusion)
Topic modeling is an evolving area of natural language processing. It helps with streamlining the analysis and classification of text documents through identifying their underlying semantic structure.
主题建模是自然语言处理的一个不断发展的领域。 通过识别文本文档的潜在语义结构,它有助于简化文本文档的分析和分类。
Using the popular LDA approach, implemented in Python, I show how to apply topic modeling to company earnings call transcripts.
通过使用在Python中实现的流行的LDA方法,我展示了如何将主题建模应用于公司的收益电话记录。
We see that, with a relatively simple process, we can train a model with a small set of transcripts and use the model to successfully classify new (unseen) transcripts based on their topic distributions.
我们看到,通过一个相对简单的过程,我们可以训练带有少量成绩单的模型,并使用该模型根据主题分布将新的(看不见的)成绩单成功分类。
Topic modeling has a bright future in the evolution of natural language processing. Along with other emerging technologies, it has the potential to improve countless processes that involve the organization and interpretation of text data.
主题建模在自然语言处理的发展中有着光明的前景。 与其他新兴技术一起,它具有改进无数涉及文本数据组织和解释的过程的潜力。
This article was originally published in the High Demand Skills blog
本文最初发表在“ 高需求技能”博客上
lda隐含狄利克雷分布

















 6825
6825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









