





gcp iot 使用
项目概况 (Project Overview)
I work in a retail company and we’ve contracted a new software to forecast sales and replenishment.
我在一家零售公司工作,我们已经签约了一个新软件来预测销售和补货。
After some months we started to extract some data from them and arrived the moment to extract the forecasted sales.
几个月后,我们开始从中提取一些数据,然后到了提取预测销售额的时刻。
We are forecasting for the next year, on a daily level, for all combinations of location-product which resulted in a file with almost 1.4 billion rows weighing 50 GB, and at the end, it would be ingested into our Data Lake.
我们预测,明年将每天使用定位产品的所有组合生成一个文件,该文件包含近14亿行重达50 GB的文件,最后将其提取到我们的Data Lake中。
提取过程 (The Extraction Process)
The development team from the software has created a job that downloads and compresses the desired file into a .gz of 4.5 GB and sends it to us via a File Transfer Protocol (FTP).
该软件的开发团队创建了一个工作,可以下载所需文件并将其压缩为4.5 GB的.gz,然后通过文件传输协议 (FTP)发送给我们。
Once the file is on the FTP we have a python script on Google Cloud Platform (GCP) that downloads, uncompresses, and sends it to a Bucket (a basic container that holds your data on Cloud Storage).
将文件保存在FTP上后,我们就会在Google Cloud Platform (GCP)上拥有一个python脚本,该脚本可以下载,解压缩并将其发送到Bucket (将数据存储在Cloud Storage上的基本容器)。
After all, we use a javascript file to ingest the uncompressed file into our Data Lake in Google Big Query (GQB).
毕竟,我们使用javascript文件将未压缩的文件提取到Google Big Query (GQB)中的Data Lake中。
安装 (Installation)
One of the possible ways to upload a file to a bucket in GCP is using the Google Cloud Software Development Kit (GC SDK), which is a tool that lets us interact with products and services of GCP with power shell commands.
将文件上传到GCP中存储桶的一种可能方法是使用Google Cloud软件开发工具包 (GC SDK),该工具可让我们使用Power Shell命令与GCP的产品和服务进行交互。
Here is what you need to do to download it:
这是您需要下载的内容:
- Access the link below: 访问以下链接:
- Choose the environment 选择环境
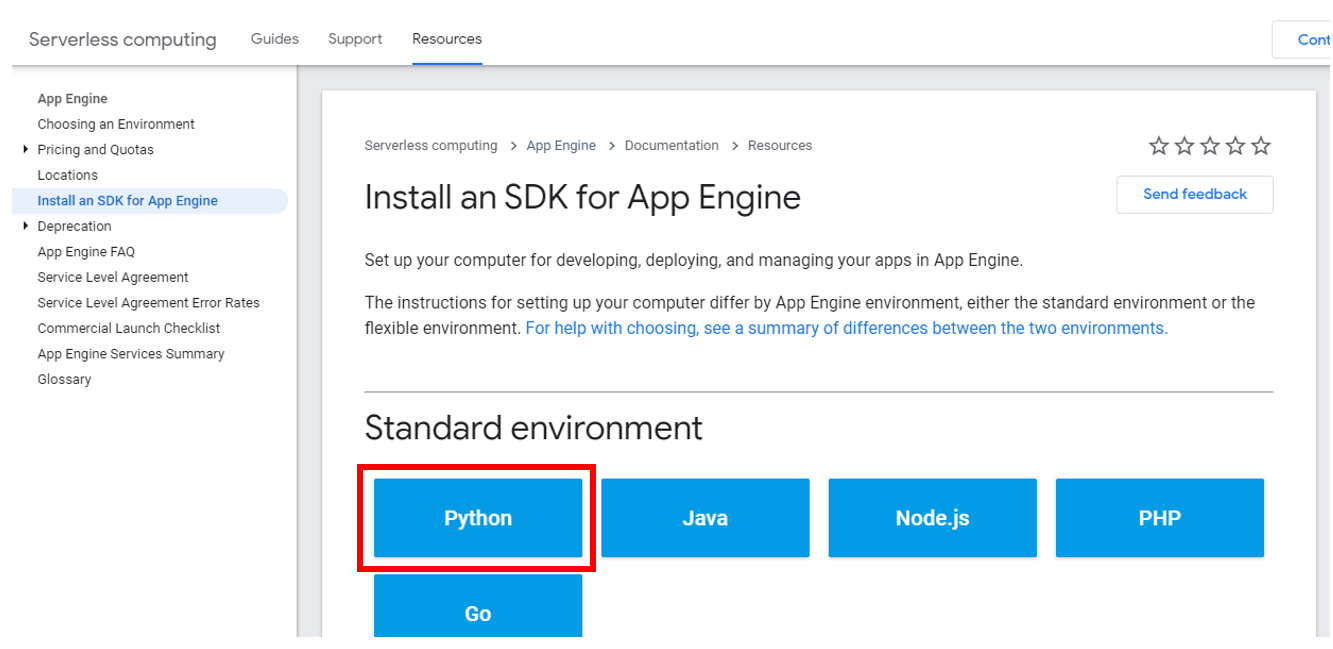
- Click on download 点击下载
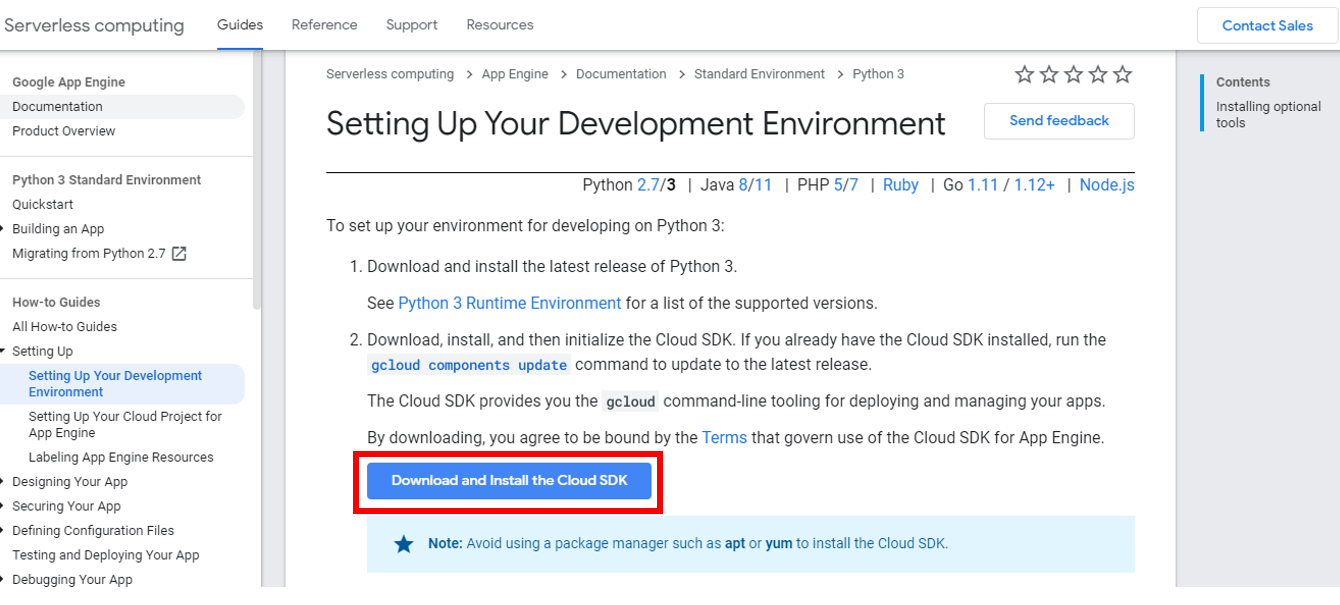
- Select the operating system (OS) that you have and click on Cloud SDK 选择您拥有的操作系统(OS),然后单击Cloud SDK
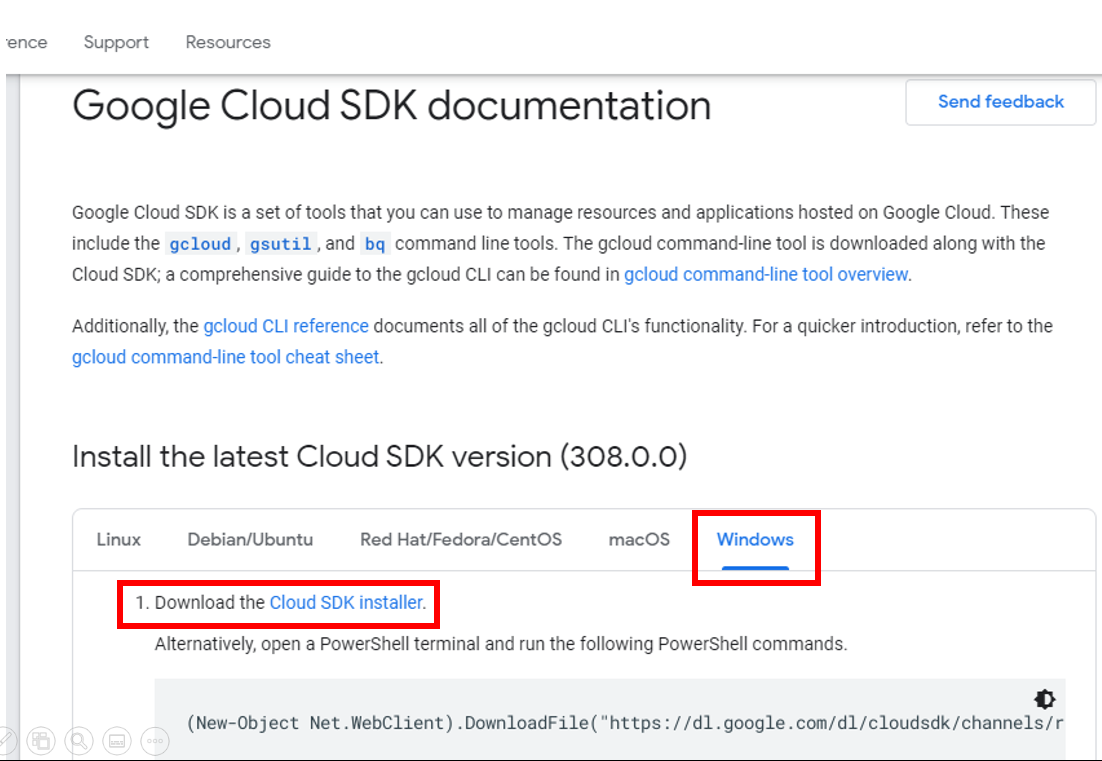
- Open the downloaded .exe 打开下载的.exe
- Click on all “Accept” and “Next” buttons that appear to you 单击显示给您的所有“接受”和“下一步”按钮
- Click on Finish 点击完成
Cool, now you have this installed you can use/send commands to GC SDK with Python.
太好了,现在您已经安装了该程序,可以将命令与Python一起使用/发送到GC SDK。
权限 (Permissions)
One important thing about the methods I’ll talk about it that the user that you are going to use to connect to GCP and upload the file must have enabled the permissions to create and visualize objects on bucket, and also the admin permission.
关于方法的一件重要事情是,您将用来连接到GCP并上传文件的用户必须已启用创建和可视化存储桶上对象的权限以及admin权限。
Only when the user has these three permissions we will be able to create the file properly using the functions below.
只有当用户拥有这三个权限时,我们才可以使用以下功能正确创建文件。
编码 (Coding)
Cool, now you’ve reached the interesting part!
太酷了,现在您已经达到了有趣的部分!
For this development, we’ll have two files: constants.py and main.py.
对于此开发,我们将有两个文件: 常量 .py和main .py。
Inside constants.py we store the three dictionaries, one with the information about the file you want to search in the FTP, another describing the google cloud authorization, and by the last one with the bucket name and folders path inside of it.
在常量 .py中,我们存储了三个字典,一个字典包含有关您要在FTP中搜索的文件的信息,另一个字典描述了Google云授权,最后一个字典中包含了存储桶名称和文件夹路径。
Now, in main.py we have four main functions:
现在,在main .py中,我们具有四个主要功能:
- read_file_from_ftp read_file_from_ftp
def read_file_from_ftp(dict_ftp, file_name_temp, file_format, destination_folder_path):
"""download a file from a FTP
Parameters
----------
dict_ftp : dict
dictionary with the key to connect with the FTP
{'host' : '', 'user' : '', 'password' : '', 'path' : ''}
file_name_temp : str
template of the desired file name file you want to download: order_parameters_export_2020-06-28_420348.csv,
template example: order_parameters_export_2020-06-28
file_format : str
Extension of the file, it could be '.csv', '.pdf', etc...
destination_folder_path : str
The folder where the
'C:\\Users\\Documents\\your_folder'
Returns
-------
None
"""
print(f'{time.ctime()}, Start download file from FTP process')
download_ind = False
# connect to FTP
ftp = ftplib.FTP(dict_ftp['host'])
# log in to FTP
ftp.login(dict_ftp['user'], dict_ftp['password'])
print(f'{time.ctime()}, FTP connection stablished')
# change directory in FTP
ftp.cwd(dict_ftp['path'])
print(f'{time.ctime()}, Access output directory')
# for each file in the directory
for file in ftp.nlst():
# check file name for file name template
if file.find(file_name_temp) >= 0:
print(f"{time.ctime()}, File found")
while not download_ind:
print(f"{time.ctime()}, Start downloading file")
# define local file name
localfile = os.path.join(destination_folder_path, file)
localfile = open(localfile, 'wb')
try:
ftp.retrbinary("RETR " + file, localfile.write)
download_ind = True
print(f"{time.ctime()}, File downloaded")
except Exception as e:
print(f"{time.ctime()}, File could not be downloaded, an error has occurred")
print(f"{time.ctime()}, Error Message: {e}")
# delete what is inside the file
localfile.truncate(0)
# close file
localfile.close()
print(f"{time.ctime()}, File created to recieve data was deleted")
# close FTP connection
ftp.quit()
print(f"{time.ctime()}, FTP connection closed")
print(f'{time.ctime()}, End download file from FTP process')We are talking about files of daily or weekly extractions probably it may have a pattern at the file name, so this function is going to download a file based on a template name.
我们谈论的是每日或每周提取的文件,它的文件名可能带有模式,因此此功能将根据模板名称下载文件。
Be cautious with the template name because if it is too generic you may end downloading more files than desired.
请谨慎使用模板名称,因为如果名称太笼统,您可能会下载过多的文件。
This is not the most impressive thing in this article, but it is cool to salient too, this FTP download function has a nice performance.
这不是本文中最令人印象深刻的事情,但是突出也很酷,此FTP下载功能具有良好的性能。
As I said before, the compressed file we downloaded weighs 4.5 GB and it took 6 minutes and 33 seconds to download it.
就像我之前说的,我们下载的压缩文件重4.5 GB,花了6分33秒下载。
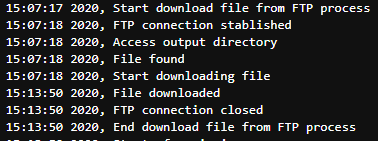
Obviously it depends a lot on your internet connection, but it was a non-expected victory to us.
显然,这在很大程度上取决于您的互联网连接,但这对我们来说是意外的胜利。
- unzip_gz_file unzip_gz_file
def unzip_gz_file(folder_path_in, folder_path_out, desired_file_name):
"""unzip a compressed .gz file
Parameters
----------
folder_path_in : str
full path to the .gz file
folder_path_out : str
path to the desired destination folder
desired_file_name : str
the name that you want to the extracted file have, don't forget the file format
Returns
-------
None
"""
print(f'{time.ctime()}, Start of unzipping process')
# create a list with the name of the files that exist in this folder
file_name = os.listdir(folder_path_in)
# ignore files that were created by the notebook execution
thing = '.ipynb_checkpoints'
if thing in file_name: file_name.remove(thing)
# define the index of the most recent file
last_file_index = len(file_name) - 1
# create the full path to this file
path_to_gz_file = os.path.join(folder_path_in, file_name[last_file_index])
# define the full path to the unzipped file
path_to_csv_file = os.path.join(folder_path_out, desired_file_name)
print(f'{time.ctime()}, Folders defined')
print(f'{time.ctime()}, Start unzipping file')
# open the .gz file
with gzip.open(path_to_gz_file, 'rb') as f_in:
# create the uncompressed file on the desired path
with open(path_to_csv_file, 'wb') as f_out:
# file the file with the data inside the .gz
shutil.copyfileobj(f_in, f_out)
print(f'{time.ctime()}, File unzipped')Well, this is quite obvious, you will say where the .gz file is and where you want to the unzipped file be, and with which name.
好吧,这很明显,您将说出.gz文件在哪里,以及要解压缩后的文件在哪里,以及使用哪个名称。
It took 10 minutes and 42 seconds to read the compressed file with 4.5 GB and create the extracted file with 50 GB.
花了10分42秒来读取4.5 GB的压缩文件并创建50 GB的提取文件。
- upload_file_to_bucket and upload_file_to_bucket_sdk upload_file_to_bucket和upload_file_to_bucket_sdk
These two functions do exactly the same thing, but using different approaches that are using the API (first function) or using the GC SDK (second function).
这两个函数的作用完全相同,但是使用的是使用API(第一个函数)或GC SDK(第二个函数)的不同方法。
via API
通过API
def upload_file_to_bucket(path_key_json, file_path, bucket_name, bucket_folder=None):
"""upload a file to a bucket on Cloud Storage at Google Cloud Platform, it could be at root or at a folder of the bucket
Parameters
----------
path_key_json : str
path to GCP service key, the key must be at .json format
file_path : str
full path to the desired file, example: 'C:\\Documents\\Data\\result\\test.csv'
bucket_name : str
name of the bucket that you want to ingest a file
bucket_folder : str
name of the folder of the bucket that you want to ingest a file
Returns
-------
None
"""
print(f"{time.ctime()}, Start upload file to Cload Storage Bucket process")
# get the file name
lst_file_path = file_path.split(f"\\")
file_name = lst_file_path[len(lst_file_path)-1]
# instantiates a client
storage_client = storage.Client.from_service_account_json(path_key_json)
print(f"{time.ctime()}, GCP storage client logon successful")
# get bucket object
bucket = storage_client.get_bucket(bucket_name)
print(f"{time.ctime()}, Bucket object got")
# define the blob path
if bucket_folder:
blob_path = bucket_folder + "/" + file_name
else:
blob_path = file_name
# create the blob
blob = bucket.blob(blob_path)
print(f"{time.ctime()}, Bucket blob {blob_path} created")
print(f"{time.ctime()}, Start uploading file {file_name}")
# upload the files in GCS
blob.upload_from_filename(file_path)
print(f"{time.ctime()}, File {file_name} uploaded")via SDK
通过SDK
def upload_file_to_bucket_sdk(file_path, dict_gc_auth, bucket_name, lst_bucket_folder=None):
"""upload a file to a bucket in Google Cloud Platform using Google Cloud Software Development Kit
Parameters
----------
file_path : str
complete file path with directory, folder, file name and file format
dict_gc_auth : dict
dict that stores Google Cloud authorization data.
{'email' : '', 'cred_json_file_path' : '', 'project_id' : '',}
bucket_name : str
name of the bucket
lst_bucket_folder : list
list with the names of the folders of the bucket
Returns
-------
None
"""
print(f'{time.ctime()}, Start of file upload process')
# define the bucket path
bucket_path = f'gs://{bucket_name}/'
if len(lst_bucket_folder):
for name in lst_bucket_folder:
bucket_path = bucket_path + name + '/'
try:
print(f'{time.ctime()}, Start GCP loging')
# # command line to run a cmd command on jupyter notebook
# !gcloud auth activate-service-account {dict_gc_auth['email']} --key-file={dict_gc_auth['cred_json_file_path']}
# try to logging in your google account on GCP using a GC SDK command line (works on .py files)
os.system(
f"gcloud auth activate-service-account {dict_gc_auth['email']} --key-file={dict_gc_auth['cred_json_file_path']}")
print(f'{time.ctime()}, GCP logged in')
except Exception as e:
print(f'{time.ctime()}, An error has occurred during the last step: {e}')
sys.exit()
try:
print(f'{time.ctime()}, Start uploading file')
# !gsutil -m cp {file_path} {bucket_path}
# try to upload a file to a bucket in GCP using a GC SDK command line (works on .py files)
os.system(f'gsutil -m cp {file_path} {bucket_path}')
print(f'{time.ctime()}, File uploaded')
except Exception as e:
print(f'{time.ctime()}, An error has occurred during the last step: {e}')
sys.exit()
print(f'{time.ctime()}, End of file upload process')So, which of them you should use?
那么,您应该使用其中哪个?
Well, if you don’t want to or just can’t install GC SDK you can use the API version to solve your problem, but I really recommend you to install it because it has decreased a lot the time spent on this process.
好吧,如果您不想或者根本无法安装GC SDK,则可以使用API版本来解决问题,但是我真的建议您安装它,因为它减少了此过程的时间。
Just to compare:
只是比较一下:
Uploading manually the file to the bucket took 12 hours to complete.
手动将文件上传到存储桶需要12个小时才能完成。
Uploading via API took 2 hours and a half.
通过API上传需要2个半小时。
By last, uploading via GC SDK took 11 minutes and 44 seconds.
最后,通过GC SDK上传花费了11分44秒。

I’ve completed the code with a cleaning step on the begging and on the end of the process, so you don’t have to store a huge file on computer’s hard disk unnecessarily.
在乞求过程中以及结束时,我已经完成了清理步骤,因此您不必不必要地在计算机硬盘上存储一个大文件。
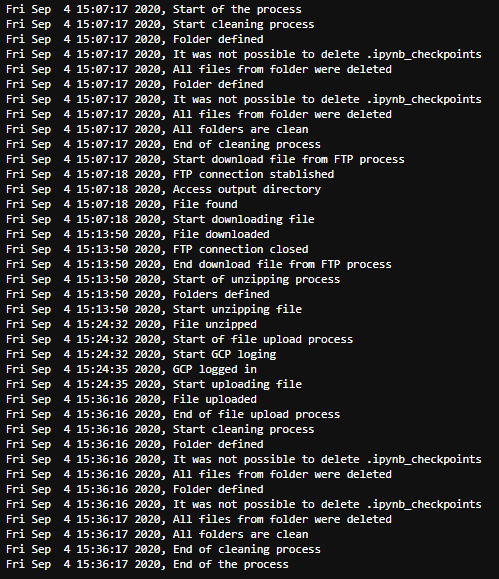
So, today the whole process spent 29 minutes to download, unzip and upload the file.
因此,今天整个过程花费了29分钟来下载,解压缩和上传文件。
If you got interested in these files you can see them in my Git Hub with the link below:
如果您对这些文件感兴趣,可以在我的Git Hub中通过以下链接查看它们:
就是这样! (And this is it!)
Well, with this I think you can now use Python to upload files really fast to a Bucket in GCP with a little more ease!
好吧,有了这个,我想您现在可以使用Python更加轻松地将文件真正快速地上传到GCP中的存储桶了!
I hope this article has helped you!
希望本文对您有所帮助!
Special thanks to Bruno Motta and Antonio Rodrigues who put up with me while I cleared a million of questions about buckets and GC SDK with them
特别感谢Bruno Motta和Antonio Rodrigues在我清除了数以百万计的有关存储桶和GC SDK的问题时支持我
资料来源: (Sources:)
gcp iot 使用

















 711
711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









