





现代密码学理论与实践
The strength of a password is an important measurement of security for any system which uses password or PIN authentication. In this article, I will discuss the theoretical strength, and how it relates to the entropy of a password. Then, I will discuss the practical aspect compared to the theoretical approach — and highlight the big gap between theory and practice. This is an important pre-requisite to understand how to attack in practice a password authentication, and what strategies we can have to defend ourselves against those attacks.
对于使用密码或PIN身份验证的任何系统,密码的强度都是衡量安全性的重要指标。 在本文中,我将讨论理论强度以及它与密码的熵之间的关系。 然后,我将讨论与理论方法相比的实践方面,并强调理论与实践之间的巨大差距。 这是理解实践中如何攻击密码身份验证以及我们可以采取哪些策略防御这些攻击的重要先决条件。
一点组合 (A little bit of combinatorics)
To understand the strength of a password we need to go back to high school math and a bit of combinatorics. Basically, the strength of a password is the potential number of variations the attacker needs to try on average to find the password. If a password is a randomly chosen one, the attacker needs to go through on average half of all the existing variations. Let’s take an example: a 4-digit passcode code. Don’t be confused, passcodes are basically just numerical passwords.
要了解密码的强度,我们需要返回中学数学和一些组合语言。 基本上,密码的强度是攻击者平均需要尝试才能找到密码的变体数。 如果密码是随机选择的,则攻击者平均需要平均所有现有变体的一半。 让我们举个例子:一个4位数的密码。 请勿混淆,密码基本上只是数字密码。
There are 10 variations for each digit — we can also say, that the valid symbol set is 10 because we have 0, 1, 2, 3..9 as symbols. So, all potential variations of the passcode is 10 x 10 x 10 x 10, or 10^4 = 10,000.
每个数字有10种变化形式-我们也可以说有效的符号集是10,因为我们有0、1、2、3..9作为符号。 因此,密码的所有可能变化为10 x 10 x 10 x 10,或10 ^ 4 = 10,000。
If you can try out a passcode with a computer, 10,000 is not a lot, without any protection all variations could be tried out in a fraction of a second. A brute-force attack is trying out all variations.
如果您可以使用计算机尝试输入密码,那么10,000并不是很多,没有任何保护,可以在不到一秒钟的时间内试用所有变体。 蛮力攻击正在尝试所有变种。
I wrote that on average, half of the passwords need to be brute-forced by the attacker — that is because the attacker might get lucky, and find it after 100 tries, or they might need to go through all variations. All these possible cases even out in a way, that if the number of variations is 10,000, on average the attacker needs to try 5,000.
我写道,平均而言,一半的密码需要由攻击者强行使用-这是因为攻击者可能会很幸运,并在尝试100次后才能找到它,或者它们可能需要经过所有变体。 所有这些可能的情况都以某种方式平衡,如果变异数为10,000,则平均而言,攻击者需要尝试5,000。
To strengthen this passcode, we could increase the length or the number of symbols. If we increase the length of the passcode to 6 digits, that would mean 10⁶ variations, or 1,000,000. If we rather allow English alphabet characters (lowercase only), then we add 26 more symbols. That means 36 symbols altogether (including digits), which would mean 36⁴=1,679,616 variations for a 4 digit password. You can see, that even though the 4 character password is shorter, it has more variations than the 6 digit passcode — so, in this example, the one including characters is stronger.
为了加强此密码,我们可以增加符号的长度或数量。 如果我们将密码的长度增加到6位数字,则意味着10个变化或1,000,000。 如果我们宁愿允许英文字母字符(仅使用小写字母),那么我们还要添加26个符号。 这意味着总共有36个符号(包括数字),这意味着4位数密码的36个变化形式= 1,679,616。 您会看到,尽管4字符密码较短,但它比6位数密码具有更多的变化-因此,在此示例中,包含字符的密码更强。
All in all, the strength of the password, in theory, can be calculated with the following formula:
总而言之,理论上,密码强度可以使用以下公式计算:
Strength = Number of valid symbols^Length
强度=有效符号数^长度
or just simply
或者只是
S = N^L
S = N ^ L
密码的熵 (The entropy of a password)
From a security perspective, there is no real difference between 1,000,000 and 1,001,000 variations. Both numbers are in the same magnitude, while there is a significant difference between 10,000 (4 digit passcode) and 1,000,000 (6 digit passcode). For that reason, in practice, we are using the magnitude instead of the exact number of variations for password strength — the logarithm of the variations. We could use a 10-base logarithm (e.g. log10 10,000=4), but the industry rather uses binary logarithm. This number is called the entropy (H) and is measured in bits.
从安全性的角度看,1,000,000和1,001,000之间没有真正的区别。 两个数字的大小相同,而10,000(4位数字密码)和1,000,000(6位数字密码)之间存在显着差异。 因此,在实践中,我们使用幅度而不是确切的变体数量来表示密码强度-变体的对数。 我们可以使用以10为底的对数(例如log10 10,000 = 4),但是行业宁愿使用二进制对数。 此数字称为熵 (H),以位为单位。
H = log₂(Variations of passwords) = log₂ (N^L)
H = log 2(密码的变化)= log 2(N ^ L)
Why? First, we want to show off our nerdiness to the world that, we are working with computers so our brain also uses only 0s and 1s. Second, for computer-stored numbers binary base is much easier to use. Third, this number indicates what the length of an equally strong, binary-only password would be.
为什么? 首先,我们要向世界炫耀我们正在使用计算机,因此大脑也只使用0和1。 其次,对于计算机存储的数字,二进制数基更易于使用。 第三,此数字表示同样强度的仅二进制密码的长度。
Ha = log₂(10⁴)= log₂(10,000)=13.29 bits
Ha = log 2(10 6)= log 2(10,000)= 13.29位
Hb = log₂(10⁶)= log₂(1,000,000)=19.93 bits
Hb = log 2(10 4)= log 2(1,000,000)= 19.93位
Hc = log₂(36⁴)= log₂(1,679,616)=20.68 bits
Hc = log 2(36⁴)= log 2(1,679,616)= 20.68位
There might be cases when the formula for calculating the variations of the password is not that simple. For example, in a case when the first character of the password cannot be a number and must be a lowercase letter of the English alphabet, but the rest of the password can be lowercase characters or numbers. You need to calculate entropy in the same way — binary logarithm of all the potential variations. Sticking to the previous example of a 4-character password, this is log₂(26*36³).
在某些情况下,用于计算密码变化的公式不是那么简单。 例如,在密码的第一个字符不能为数字且必须为英语字母的小写字母的情况下,密码的其余部分可以为小写字符或数字。 您需要以相同的方式计算熵-所有潜在变化的二进制对数。 坚持前面的4个字符的密码示例,它是log²(26 *36³)。
实践中的问题 (The problem in practice)

Unfortunately, in practice, it works differently. The strength of a password is still the average number of variations an attacker has to try out before succeeding, but in reality, it cannot be easily calculated from the number of valid symbols and the potential length of the password. Why? Here is a big secret: average users don’t choose their passwords randomly.
不幸的是,实际上,它的工作方式有所不同。 密码的强度仍然是攻击者在成功之前必须尝试的平均变种次数,但是实际上,不能根据有效符号的数目和密码的潜在长度来轻松计算出密码的强度。 为什么? 这是一个很大的秘密:普通用户不会随机选择密码。
The above-mentioned combinatoric formulas could only be used for measuring the strength of the password if “%2tK2” as a password would be chosen by an average user with the same probability as “apple” for a 5 character password. But that is never going to happen. Never.
仅当普通用户以5个字符的密码与“苹果”具有相同的概率选择“%2tK2”作为密码时,上述组合公式才可以用于测量密码的强度。 但这永远不会发生。 决不。
By not choosing their passwords randomly, users lower the security of the system. But the question is, by how much? While there’s no simple answer, it’s definitely orders of magnitude. Here is an example: the Oxford English Dictionary has 171,476 words, the longest of which is 30 characters. If a user just picks any English word as a password, then the variations are 171,476 (note: we assume that a user picks “apple” with the same probability as “pseudopseudohypoparathyroidism”, which is a bit strong assumption about the average user’s vocabulary). If a user chose a random character string, which is maximum 30 characters long (meaning it can also be shorter), it is 26³⁰ + 26²⁹+ … +26²+26 = 2925726857336135756028965870800610381571030. Compared to 171,476, it is a pretty big difference.
通过不随机选择密码,用户会降低系统的安全性。 但是问题是,多少钱? 尽管没有简单的答案,但这肯定是几个数量级。 这是一个例子:牛津英语词典有171,476个单词,最长为30个字符。 如果用户只是选择一个英语单词作为密码,则变化为171,476(注意:我们假设用户选择“苹果”的可能性与“伪伪甲副甲状腺功能低下”的可能性相同,这是对普通用户词汇的强烈假设) 。 如果用户选择的随机字符串最长为30个字符(也可以更短),则为26³⁰+26²⁹+…+26²+ 26 =29257268573361357560289658708006103815710710。与171,476相比,这是一个很大的差异。
To demonstrate how much larger this number is than the number of words in the dictionary, let’s imagine the observable universe as a giant ball. Let’s imagine an even bigger, super-giant ball which is 2 million times larger in diameter. The ratio of the super-giant ball’s diameter to the width of a human hair is the same as the ratio calculated above for the word-based password vs. randomly chosen password.
为了说明这个数字比字典中的单词数大多少,让我们想象一下可观察的宇宙是一个巨大的球。 让我们想象一个更大的超级巨球,直径是200万倍。 超巨型球的直径与人发的宽度之比与上面针对基于单词的密码与随机选择的密码计算得出的比率相同。
Working with such huge numbers makes life difficult, and that is why we are using entropy, measured in bits to compare the number of variations: the dictionary has 17.4 bits entropy (log₂(171,476) = 17.4), the maximum 30 character long randomly chosen string has 141.1 bits entropy. 123.7 bits entropy difference doesn’t seem like much, but remember the previous example about the width of a human hair and the super-giant ball — that is the magnitude of the difference.
处理如此巨大的数字会给生活带来困难,这就是为什么我们要使用熵(以位为单位来比较变化数量)的原因:字典具有17.4位的熵(log 2(171,476)= 17.4),最长30个字符,随机选择字符串具有141.1位的熵。 123.7位的熵差看起来似乎并不多,但是请记住前面关于人发和超巨型球的宽度的示例,即差的大小。
You could say, that users may use more complex passwords than just one word from a dictionary, they can add numbers (which are not entirely random), special characters, etc. While that doesn’t make the password as strong as a randomly generated one, it definitely strengthens it — but how much?
您可能会说,用户使用的密码可能不只是字典中的一个单词,而是复杂的密码,他们可以添加数字(不完全是随机的),特殊字符等。尽管如此,密码的强度不如随机生成的密码强。第一,它肯定会加强它-但是多少呢?
在实践中测量密码熵 (Measuring password entropy in practice)
The National Institute of Standards and Technology issued a rule of thumb to estimate the entropy of a user-chosen password (Special Publication 800–63–2), based on the length of the password:
美国国家标准技术研究院发布了一条经验法则,根据密码的长度来估计用户选择的密码的熵(特殊出版物800–63–2):
char 1 → 4 bits
字符1→4位
char 2–8 → 2 bits (per char)
字符2–8→2位(每个字符)
char 9–20 → 1.5 bits (per char)
字符9–20→1.5位(每个字符)
char 21 and above → 1 bit (per char)
字符21及以上→1位(每个字符)
As an example, the entropy of an 8 character user-selected password is 4+2+2+2+2+2+2+2=18 bits, the entropy of a 30 character length user-selected password is 46 bits.
例如,用户选择的8个字符的密码的熵为4 + 2 + 2 + 2 + 2 + 2 + 2 + 2 + 2 = 18位,而用户选择的30个字符长度的密码的熵为46位。
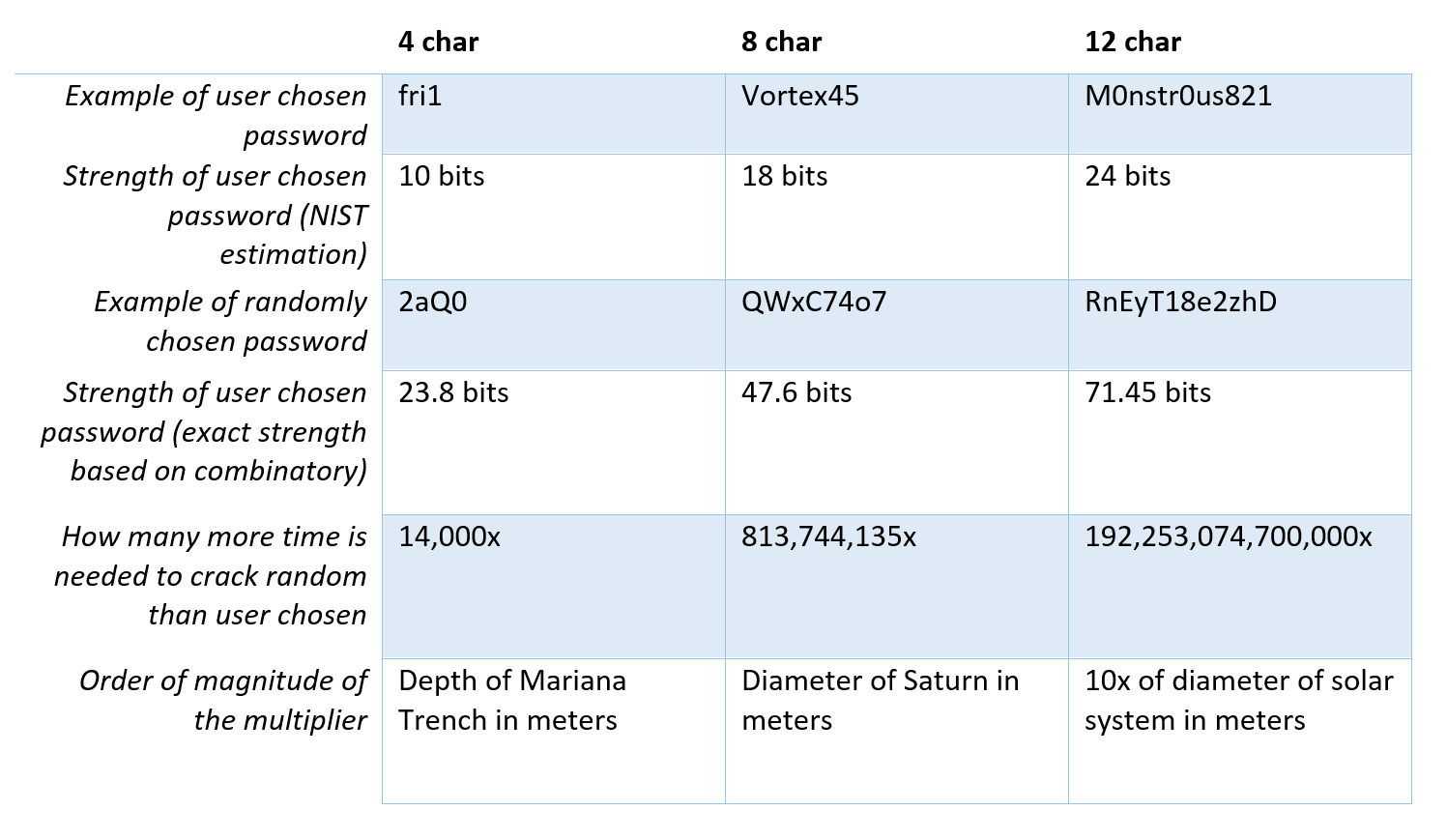
The NIST estimation is just one heuristic. It shows a high-level picture of users but not doesn’t help in measuring one particular user’s password. Even NIST dropped this approach in 2017 and suggested not to use it for estimating the strength of one particular user.
NIST估计只是一种试探法。 它显示了高级别的用户图片,但无助于衡量一个特定用户的密码。 甚至NIST在2017年也放弃了这种方法,并建议不要将其用于评估某个特定用户的实力。
There are other heuristics to measure the strength of a password chosen by the user, which really measures the effort the user puts in. These heuristics are looking for words in a dictionary, even for a partial match, checking simple numbers that might look like birthdays, etc. A great example is the Zxcvbn library. It’s worth noting that it uses an English dictionary by default, so non-English words will get higher entropy. If you want to use this with users from all around the globe, you need to add the extra dictionaries yourself.
还有其他启发式方法可以衡量用户选择的密码的强度,这实际上可以衡量用户所付出的努力。这些启发式方法是在字典中查找单词,甚至是部分匹配的单词,还会检查看起来像生日的简单数字等等。Zxcvbn库就是一个很好的例子。 值得注意的是,默认情况下它使用英语词典,因此非英语单词将具有更高的熵。 如果要与来自世界各地的用户一起使用,则需要自己添加额外的词典。

These low entropy numbers suggest that we cannot design a truly secure system based only on user passwords, and if we do not replace it, we are all doomed. Well, not entirely. One study found that an average user chooses a password with ~40 bits of entropy. While it’s not a big number, but it’s definitively better than the numbers we see above.
这些低熵值表明我们不能仅基于用户密码来设计真正安全的系统,如果不替换它,我们注定要失败。 好吧,不完全是。 一项研究发现,普通用户选择的熵密码约为40位。 虽然这不是一个很大的数字,但是绝对比我们上面看到的数字要好。
If an attacker tries to brute-force a ~40-bit password, with a brute-force rate of 100,000 passwords/second, it will still take 63 days to go through all the combinations. But if we can slow down the attacker to 1,000 passwords/second, then we will end up with 17.4 years. If we slow it even further down, to 1 password/second, than we can end up with 17,400 years. But if the attacker can try passwords faster, let’s say 100M passwords/second, then it will only take 1.5 hours to crack the password.
如果攻击者尝试以约100,000个密码/秒的强力破解暴力破解〜40位密码,则仍然需要63天才能完成所有组合。 但是,如果我们可以将攻击者的速度减慢到每秒1000个密码,那么最终的结果将是17.4年。 如果我们将其进一步降低至1密码/秒,那么最终的使用寿命将达到17,400年。 但是,如果攻击者可以更快地尝试密码,例如100M密码/秒,那么仅需1.5个小时即可破解密码。
The bottom line is: the attacker’s capabilities really do matter. Cracking a password in 90 minutes is an entirely different story than in 17,400 years. 40-bit entropy is low, but we can work with it if we manage to slow the attacker down significantly. But before that, it is essential to understand how an attacker can gain extremely high speed in user-generated passwords because understanding these tactics is essential if you want to design a system that can resist the attack. But that is a tale for a different post.
最重要的是:攻击者的能力确实很重要。 90分钟内破解密码与17400年完全不同。 40位熵很低,但是如果我们设法使攻击者的速度大大降低,我们可以使用它。 但是在此之前,必须了解攻击者如何以极高的速度生成用户生成的密码,因为如果您要设计一个可以抵抗攻击的系统,则必须了解这些策略。 但这是另一个帖子的故事。
现代密码学理论与实践















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









