






协变量偏移
介绍 (Introduction)
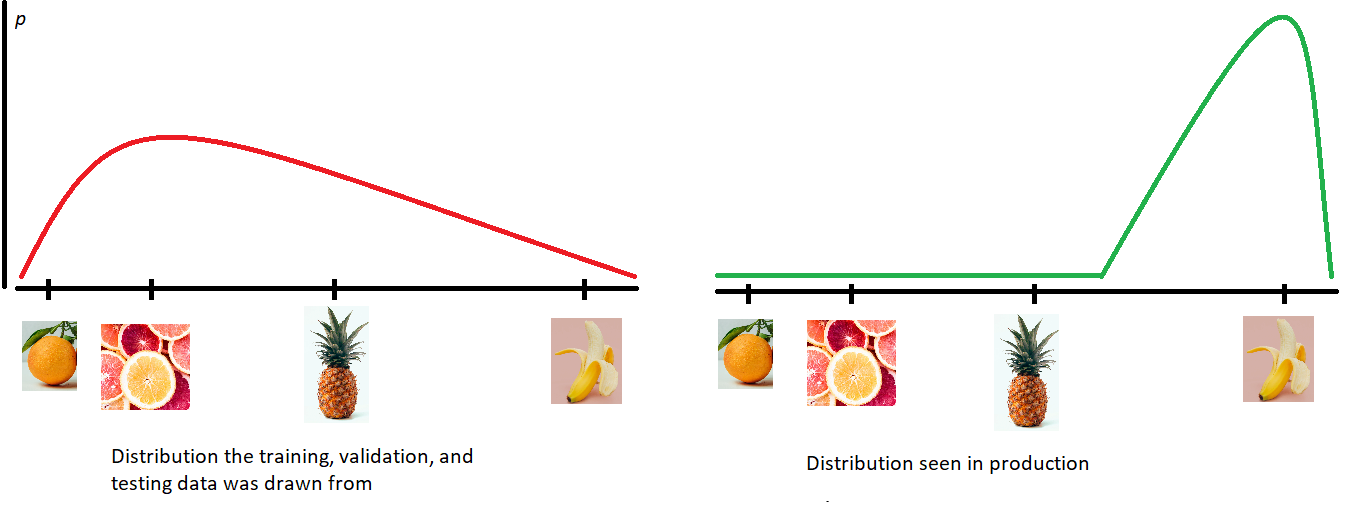
Covariate shift in the data-generating distribution lowers the usefulness of generalization error as a measure of model performance. By unpacking the definitions, the previous sentence translates to “high accuracy on the distribution of files we sampled our training set from (excluding the training set itself) does not always mean high accuracy on other important distributions (even if the true relationship between a sample and its label does not change).” A fruit classifier that had a single example of a banana in its training set might perform poorly on a sample set consisting solely of 10,000 variations of bananas, even if it did very well on a held-out test set sampled from the same distribution as its training set (where presumably bananas are scarce). This performance gap can be a problem because approximating generalization error with a held-out test set is the canonical way to measure a model’s performance.
数据生成分布中的协变量偏移降低了泛化误差作为模型性能度量的有用性。 通过解压缩定义,前一句翻译为“从中抽取训练集的文件分布的准确性很高(不包括训练集本身),并不总是意味着其他重要分布的准确性很高(即使样本之间的真实关系也是如此)并且其标签不变。” 在训练集中仅包含一个香蕉示例的水果分类器,在仅包含10,000个香蕉变体的样本集上,即使在与该样本相同分布的抽样测试集上做得非常好,其效果也可能很差训练集(大概缺少香蕉)。 这个性能差距可能是一个问题,因为使用保留的测试集来近似泛化误差是衡量模型性能的规范方法。
This concept is essential for malware classification, and many papers discuss it in the context of sampling bias, where the samples used for training are not randomly sampled from the same distribution as the samples used for testing. Anecdotally, the intuition that models with good generalization may have poor performance once deployed — due to the difference between the files the model was trained on and the files it scans — is held by many malware analysts I’ve worked with, including those with little ML experience. However, it’s not always clear how to identify and fix issues related to covariate shift: conventional regularization techniques that improve generalization may not help when good generalization isn’t enough. After spending 5 years reverse engineering and classifying malware (using traditional, non-ML based techniques), I developed lots of intuitions about malware classification that I wasn’t able to express until I grew a passion for machine learning. My goal with this blog is to explain these opinions in the more formal context of machine learning. As some of these attempts at formal explanations are imprecise (and possibly incorrect), another goal of this blog is to solicit discussion, feedback, and corrections. I pack in a lot of different concepts and background because I feel relating concepts to each other helps improve understanding, especially if they can be tied back to practical goals like malware classification.
这个概念对于恶意软件的分类至关重要,许多论文在抽样偏差的背景下进行了讨论,在抽样偏差中,用于训练的样本不是从与用于测试的样本相同的分布中随机抽样的。 有趣的是,由于模型的训练文件和扫描的文件之间存在差异,具有良好普遍性的模型一旦部署可能会导致性能下降,直觉是由我工作过的许多恶意软件分析师(包括那些分析很少的人)持有的。 ML经验。 但是,并不总是很清楚如何识别和修复与协变量移位相关的问题:如果良好的概括性不够,传统的提高泛化性的正则化技术可能无济于事。 经过5年的逆向工程和对恶意软件分类(使用传统的非基于ML的技术)后,我开发了许多关于恶意软件分类的直觉,直到对机器学习充满热情之前,我一直无法表达这些直觉。 我在此博客中的目标是在更正式的机器学习环境中解释这些观点。 由于其中一些尝试进行正式解释的方法不准确(并且可能不正确),因此本博客的另一个目标是征求讨论,反馈和更正。 我打包了许多不同的概念和背景,因为我觉得将概念相互关联有助于增进理解,尤其是如果可以将它们与诸如恶意软件分类之类的实际目标联系起来的话。
I hope that anyone interested in covariate shift can benefit from this blog, but the target audience is a person with some experience in machine learning who wants to apply it to computer security-related tasks, particularly “static” malware classification (where we want to classify a file given its bytes on disk, without running it). One of the key conclusions that I hope this blog supports is the importance of incorporating prior knowledge into a malware classification model. I believe prior knowledge is particularly relevant when discussing the ways a model might represent its input before the classification step. For example, I detail some domain knowledge that I believe is relevant to CNN malware classification models in this article: https://towardsdatascience.com/malware-analysis-with-visual-pattern-recognition-5a4d087c9d26#35f7-d78fef5d7d34
我希望对协变量转换感兴趣的任何人都可以从此博客中受益,但是目标受众是具有一定机器学习经验的人,他希望将其应用于与计算机安全相关的任务,尤其是“静态”恶意软件分类(在此我们希望根据文件在磁盘上的字节数对文件进行分类,而不运行它)。 我希望该博客支持的主要结论之一是将先验知识整合到恶意软件分类模型中的重要性。 我认为在讨论模型在分类步骤之前可能表示其输入的方式时,先验知识尤其重要。 例如,在本文中,我详细介绍了一些我认为与CNN恶意软件分类模型有关的领域知识: https : //towardsdatascience.com/malware-analysis-with-visual-pattern-recognition-5a4d087c9d26#35f7-d78fef5d7d34
I’ve included an appendix that provides additional background by going over some core concepts used in the main section (such as inductive bias, generalization, and covariate shift)
我提供了一个附录,该附录通过介绍主要部分中使用的一些核心概念(例如归纳偏差,泛化和协变量平移)提供了其他背景。
恶意软件分类的协变量偏移 (Covariate Shift in Malware Classification)
I do not think models that demonstrate good generalization on large sample sets are useless. If a model does not perform well on the distribution it was trained on, that’s a problem. There is plenty of empirical evidence in the security industry that a model that generalizes well without being super robust to changes in the input distribution can still provide value, especially if retrained frequently and targeted at specific customer environments. However, at this point, many models used in the industry demonstrate high accuracy on held-out test sets. I believe improving performance on samples from important new distributions, such as files created a month after the model was trained, has a more practical impact than making tiny marginal improvements in test set accuracy. The next few sections go over why these new distributions are essential and why they are an example of “covariate shift.” If you’re new to the concept of covariate shift, I’d recommend going through the background section in the appendix.
我认为对大型样本集进行良好概括的模型并不是没有用的。 如果模型在经过训练的分布上表现不佳,那就是一个问题。 在安全行业中,有大量的经验证据表明,一种模型能够很好地泛化而不会对输入分布的变化具有超强的鲁棒性,但仍然可以提供价值,尤其是在经常进行重新培训并针对特定客户环境的情况下。 但是,在这一点上,行业中使用的许多模型在保留的测试集上都显示出很高的准确性。 我相信,提高重要的新发行版中样本的性能(例如在训练模型后一个月创建的文件),比对测试集准确性进行微不足道的改善具有更大的实际影响。 接下来的几节将介绍为什么这些新分布是必不可少的,以及为什么它们是“协变量转变”的一个示例。 如果您不熟悉协变量移位的概念, 我建议您仔细阅读附录中的背景部分。
为什么p(x)变化 (Why p(x) changes)
In the case of malware classification, p(x) is the distribution of binary files analyzed by the model. Practical malware classifiers are never applied to the distribution they are trained on; they need to perform well on sets of samples in production environments that are continually evolving. For many antivirus vendors, that means performing well on files present on every machine with that antivirus, as well as samples submitted to other services like VirusTotal and antivirus review tests. There are two main reasons why generalization performance may not be a good predictor of how well a model performs on these samples:
对于恶意软件分类, p(x)是模型分析的二进制文件的分布。 实用的恶意软件分类器永远不会应用于对其进行训练的发行版; 他们需要在不断发展的生产环境中对一组样本执行良好的操作。 对于许多防病毒供应商而言,这意味着在具有该防病毒功能的每台计算机上存在的文件以及提交给其他服务(如VirusTotal和防病毒查看测试)的示例上,都表现出色。 泛化性能可能不能很好地预测模型在这些样本上的表现,主要有两个原因:
Sample selection bias: It is rare in the security industry to train models on a random selection of files that the model encounters when deployed. This is because accurate labeling is expensive: it often requires some level of manual human analysis, and it requires having access to all scanned files. It is normal to include files that analysts have labeled for other reasons, such as for the direct benefit of customers or files that have been supplied and labeled by third parties. If human analysis isn’t involved, there is a danger of feedback loops between multiple automated analysis systems. Because we can’t feasibly train the model on a truly random sample of the target distribution, the sample selection process is biased. Technically we can get around this by randomly sampling files our scanner encounters and labeling them with human analysts, but this would result in a small sample set of mostly clean files. I refer to the distribution of files that are encountered by the scanner after the model has been deployed as the “in-production distribution.”
样本选择偏差:在安全行业中,很少会在部署模型时随机选择模型时训练模型。 这是因为准确的标签非常昂贵:通常需要进行一定程度的手动人工分析,并且需要访问所有扫描的文件。 通常包含分析人员出于其他原因而标记的文件,例如为了客户的直接利益或由第三方提供并标记的文件。 如果不进行人工分析,则存在多个自动化分析系统之间存在反馈循环的危险。 因为我们无法在目标分布的真正随机样本上训练模型,所以样本选择过程存在偏差。 从技术上讲,我们可以通过对扫描仪遇到的文件进行随机采样并使用人工分析人员对其进行标记来解决此问题,但这将导致生成一小部分样本,其中大部分为干净文件。 我将模型部署后,扫描程序遇到的文件分发称为“生产中分发”。
Environment shift: Every time you copy, edit, update, download, or delete a file, you modify the distribution your malware scanner encounters. When summed across every machine, the shift in distribution can be significant enough to mean a classifier that performed well last week may degrade significantly this week. Malware classifiers also exist in an adversarial setting, where attackers make deliberate modifications to the input to avoid the positive classification. A typical strategy to mitigate this issue is constant retraining, but it is impossible to ever train on the actual in-production distribution (even if we did have labels for them) unless we never scan files created after we gathered our training set. This scenario produces a type of sample selection bias that is impractical to overcome: we cannot train on samples that will be created in the future.
环境转变:每次复制,编辑,更新,下载或删除文件时,您都会修改恶意软件扫描程序遇到的分布。 如果将每台机器的总和相加,分布的变化可能会非常明显,这意味着上周表现良好的分类器可能会在本周大幅下降。 恶意软件分类器也存在于对抗环境中,攻击者在其中故意对输入内容进行修改,以避免正面分类。 缓解此问题的一种典型策略是不断地进行再培训,但是除非在收集培训集之后再也不扫描创建的文件,否则就不可能对实际的生产发行版进行培训(即使我们确实有标签)。 这种情况会产生一种无法克服的样本选择偏见:我们无法训练将来将要创建的样本。
为什么p(y | x)不变 (Why p(y|x) does not change)
Covariate shift requires that p(y=malicious|x=file) does not change when p(x) does (see appendix). In the case of malware classification, p(y = malicious|x) is the probability a given file x is malicious. If p(y|x) and p(x) both change, it may be impossible to maintain accuracy. I can’t prove p(y|x) won’t change, but I argue that changes are generally, for certain classes of models, independent of p(x). Here p refers to the true data-generating distributions rather than a probabilistic classifier’s attempt to approximate p(y|x).
协变量平移要求p(x)不变时p(y = malicious | x = file )不变(请参见附录)。 在恶意软件分类的情况下, p(y =恶意| x)是给定文件x恶意的可能性。 如果p(y | x)和p(x)都改变,则可能无法保持精度。 我无法证明p(y | x)不会改变,但我认为对于某些类型的模型,改变通常独立于p(x) 。 在此, p指的是真实的数据生成分布,而不是概率分类器对p(y | x)进行近似的尝试。
There are two main reasons why p(y=malicious|x) would be anything other than 1 or 0:
p(y = malicious | x)不是1或0的原因有两个主要原因:
A. Uncertainty in the input: y is a deterministic function of some representation x’, but the input x the model uses does not contain all the relevant parts of x’. This concept is touched upon in the “deterministic vs stochastic classification” section in the appendix, but it’s a critical case, so I’ll expand on it in the next section. I use x’ to refer to inputs that can be mapped deterministically to a label and x to refer inputs that may or may not be deterministically mappable to a label.
A.输入中的不确定性: y是某些表示x'的确定性函数,但是模型使用的输入x并不包含x'的所有相关部分。 附录的“确定性与随机分类”一节中涉及了此概念,但这是一个关键案例,因此我将在下一节中对其进行扩展。 我用x”至指可以确定性地被映射到一个标签,并且x是指输入,其可以是或可以不是可映射确定性到标签输入。
B. Uncertainty in the label: The definition of y does not fully account for all inputs (grayware is an example in malware classification). I’ll leave a full explanation to the appendix section “Why p(y|x) does not change: Uncertainty in the label.”
B.标签中的不确定性: y的定义并未完全考虑所有输入(灰色软件是恶意软件分类中的一个示例)。 我将对附录部分“为什么p(y | x)不变:标签中的不确定性”进行完整的解释。
输入的不确定性 (Uncertainty in the input)
In this part, I argue that the bytes in a file correspond to x’.
在这一部分中,我认为文件中的字节对应于x'。
Here’s a simple example. I precisely define ‘eight’ to be a specific shape shown in Figure 1
这是一个简单的例子。 我将“八”精确定义为如图1所示的特定形状
and ‘three’ to be the shape shown in Figure 2
和“三个”的形状如图2所示
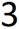
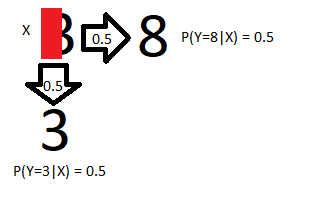
If we have access to the entire input (x’ = Figure 1 or Figure 2), we know with perfect certainty what the label should be. However, we may not have access to the full input as illustrated below, where some of the input is hidden with a red box:
如果我们可以访问整个输入( x' =图1或图2),则可以完全确定地知道标签应该是什么。 但是,我们可能无法访问完整的输入,如下所示,其中某些输入用红色框隐藏:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6798
6798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









