





可检测异常和不可检测异常
Have you ever thought about what happens when someone’s social media account, bank account or any other account/ profile get hacked? How do some systems automatically detect such activities and notify them to relevant authorities or suspend the account immediately? That is mainly done through the process called Anomaly Detection (AKA Outlier Detection). In fact, the above particular example is called Fraud Detection and it is a popular application of anomaly detection in lots of domains. So let’s dive into anomaly detection terminology.
您是否想过当某人的社交媒体帐户,银行帐户或任何其他帐户/个人资料遭到黑客入侵时会发生什么? 某些系统如何自动检测到此类活动并将其通知相关部门或立即中止帐户? 这主要是通过称为异常检测 (AKA 离群值检测 )的过程完成的。 实际上,以上特定示例称为欺诈检测,它是异常检测在许多域中的流行应用。 因此,让我们深入研究异常检测术语。
Anomaly detection or outlier detection is the process of identifying rare items, observations, patterns, outliers, or anomalies which will significantly differ from the normal items or the patterns. Anomalies are sometimes referred to as outliers, novelties, noise, deviations or exceptions. According to some literature, three categories of anomaly detection techniques exist. They are Supervised Anomaly Detection, Unsupervised Anomaly Detection, and Semi-supervised Anomaly Detection.
异常检测或异常值检测是识别稀有项,观察值,模式,异常值或异常的过程,这些异常项,观察值,模式,异常值或异常与正常项目或模式有很大不同。 异常有时称为异常值,新颖性,噪音,偏差或例外。 根据一些文献,存在三类异常检测技术。 它们是有监督的异常检测 , 无监督的异常检测和半监督的异常检测 。
有监督与无监督异常检测 (Supervised vs Unsupervised Anomaly Detection)
The most common version of anomaly detection is using the unsupervised approach. In there, we train a machine-learning model to fit to the normal behavior using an unlabeled dataset. In that process, we make an important assumption that the majority of the data in the training set are normal examples. However, there can be some anomalous data points among them (a small proportion). Then any data point which differs significantly from the normal behavior will be flagged as an anomaly. In supervised anomaly detection, a classifier will be trained using a dataset that has been labeled as ‘normal’ and ‘abnormal’. When a new data point comes, it will be a typical classification application. There are pros and cons in both of these methods. The supervised anomaly detection process requires a large number of positive and negative examples. Obtaining such a dataset will be very difficult since anomalous examples are rare. Even though you obtain such a dataset, you would only be able to model the abnormal patterns in the gathered dataset. However, there are many different types of anomalies in any domain and also future anomalies may look nothing like the examples seen so far. It will be very hard for any algorithm to learn from anomalous examples; what the anomalies look like. That is why the unsupervised approach is popular. Capturing the normal behavior is much easier than capturing the many different types of abnormalities.
异常检测的最常见版本是使用无监督方法。 在这里,我们使用未标记的数据集训练机器学习模型以适应正常行为。 在此过程中,我们做出一个重要的假设,即训练集中的大多数数据都是正常的例子 。 但是,其中可能会有一些异常的数据点(一小部分)。 然后,任何与正常行为明显不同的数据点都将被标记为异常。 在监督异常检测中,将使用已标记为“正常”和“异常”的数据集训练分类器。 当出现新数据点时,它将是典型的分类应用程序。 这两种方法都各有利弊。 有监督的异常检测过程需要大量的正面和负面例子。 由于很少有异常示例,因此获取此类数据集将非常困难。 即使获得了这样的数据集,您也只能对收集的数据集中的异常模式进行建模。 但是,在任何域中都有许多不同类型的异常,并且未来的异常可能看起来与到目前为止看到的示例完全不同。 任何算法都很难从异常示例中学习。 异常是什么样的。 这就是为什么无监督方法很受欢迎的原因。 捕获正常行为比捕获许多不同类型的异常要容易得多 。
异常检测背后的术语 (Terminology Behind Anomaly Detection)
Now let’s dive into the idea behind unsupervised anomaly detection. The process will be referred to as anomaly detection rather than unsupervised anomaly detection throughout the article. Before start discussing the anomaly detection algorithm, there is something called the Gaussian (Normal) Distribution, which the entire algorithm has been built on. In statistics, a Gaussian or a Normal Distribution is a form of continuous probability distribution for a real-valued random variable. The probability function is calculated using the below formula. 𝝁 is the mean and 𝝈^2 is the variance.
现在,让我们深入探讨无监督异常检测背后的想法。 在整个文章中,该过程将被称为异常检测,而不是无监督的异常检测。 在开始讨论异常检测算法之前,有一个称为高斯(正态)分布的东西 ,它是整个算法的基础。 在统计中,高斯分布或正态分布是实值随机变量的连续概率分布形式。 使用以下公式计算概率函数。 𝝁是均值,𝝈 ^ 2是方差。

The probability distribution is symmetric about its mean and non-zero over the entire real line. The normal distribution is sometimes called the bell curve because the density graph looks like a bell.
概率分布在整个实线上均值对称且非零。 正态分布有时称为钟形曲线,因为密度图看起来像钟形。

The basic idea of anomaly detection is to find a probability function to capture the normal behavior and discover a probability threshold such that, the data points far away from that threshold are considered anomalies. Considering the probability function as p(x) and threshold as ε, this can be depicted as below. The data points are represented by the crosses.
异常检测的基本思想是找到一个概率函数以捕获正常行为并发现一个概率阈值,从而使远离该阈值的数据点被视为异常。 将概率函数视为p(x),将阈值视为ε,则可以如下所示。 数据点由叉号表示。

In the basic anomaly detection algorithm, we assume that each feature is distributed according to its own Gaussian Distribution with some set of means and variances. So using the training dataset, we fit a set of parameters 𝝁1, 𝝁2, …, 𝝁n and 𝝈1^2, 𝝈2^2, …, 𝝈n^2 with respect to features x1, x2, …, xn. Then the probability function p(x) is calculated as the probability of x1 times the probability of x2 times the probability of x3 and so on up to the probability of xn. That is the machine learning model for anomaly detection. When a new data point comes in, we simply calculate the probability p(x) and flag it as an anomaly if the probability is less than ε. Finding the correct value for ε is an optimization objective and I’m not going to explain it in this article.
在基本的异常检测算法中,我们假设每个特征是根据其自身的高斯分布以及一组均值和方差来分布的。 因此,使用训练数据集,我们针对特征x1,x2,…,xn拟合了一组参数𝝁1,,2,…,𝝁n和𝝈1 ^ 2,𝝈2 ^ 2,…,𝝈n ^ 2。 然后将概率函数p(x)计算为x1的概率乘以x2的概率乘以x3的概率,依此类推,直至xn的概率。 这是用于异常检测的机器学习模型。 当一个新的数据点进入时,我们简单地计算概率p(x),如果概率小于ε,则将其标记为异常。 为ε找到正确的值是一个优化目标,在本文中我将不作解释。

有关异常检测的更多信息 (More on Anomaly Detection)
An important fact is to choose a set of features that are indicative of anomalies. That is to choose a set of features in which the features might take on an unusually large or small value in the presence of an anomaly. On the other hand, there might be some sort of drawback since we have to manually create the features. Also, this algorithm could only detect a few anomaly scenarios. For example, how can we detect anomalies when the data is distributed as below.
一个重要的事实是选择一组指示异常的特征。 也就是说,选择一组特征,其中在出现异常的情况下,这些特征可能会具有异常大或小的值。 另一方面,由于我们必须手动创建功能,因此可能存在某种缺陷。 而且,该算法只能检测一些异常情况。 例如,当数据分布如下时,我们如何检测异常。
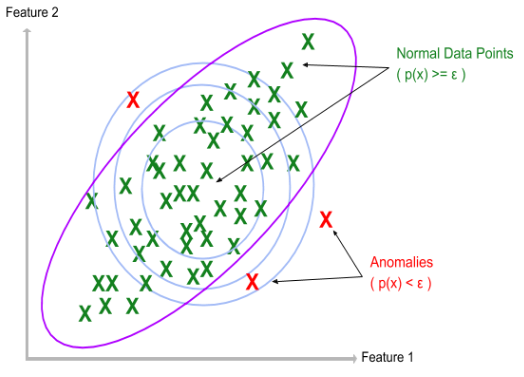
As you can see, the earlier model using the Gaussian Distribution flag some of the normal data points as anomalies and some anomalous examples as normal data points (blue boundaries in the above figure). In fact, we need an advanced shaped boundary for this sort of data distribution (maybe boundary in purple color). This particular problem is addressed using Multivariate Gaussian Distribution. In there, instead of modeling each feature in its own Gaussian distribution and multiplying the probabilities, all the features are modeled into one common distribution called the Multivariate Gaussian Distribution.
如您所见,使用高斯分布的早期模型将一些正常数据点标记为异常,将一些异常示例标记为正常数据点(上图中的蓝色边界)。 实际上,对于这种数据分布,我们需要一个高级的成形边界(也许是紫色边界)。 使用多元高斯分布可解决此特定问题。 在这里,不是将每个特征建模在自己的高斯分布中并乘以概率,而是将所有特征建模到一个称为多变量高斯分布的公共分布中。
流行技术 (Popular Techniques)
Today, when implementing an anomaly detection algorithm you don’t have to worry about the above details. The popular libraries like scikit-learn (for python) provides much easier ways to implement anomaly detection algorithms. Here are some of the popular techniques used for anomaly detection.
今天,在实施异常检测算法时,您不必担心上述细节。 诸如scikit-learn(适用于python)之类的流行库提供了实现异常检测算法的简便得多的方法。 以下是一些用于异常检测的流行技术。
- Density-based techniques (KNN, Local Outlier Factor, Isolation Forest, etc) 基于密度的技术(KNN,局部离群因子,隔离林等)
- Cluster analysis based techniques (KMeans, DBSCAN, etc) 基于聚类分析的技术(KMeans,DBSCAN等)
- Bayesian Networks 贝叶斯网络
- Neural networks, autoencoders, LSTM networks 神经网络,自动编码器,LSTM网络
- Support vector machines 支持向量机
- Hidden Markov models 隐马尔可夫模型
- Fuzzy logic based outlier detection 基于模糊逻辑的离群值检测
一些应用 (Some Applications)
- Fraud detection (Ex: network, manufacturing, credit card fraud, etc) 欺诈检测(例如:网络,制造,信用卡欺诈等)
- Intrusion detection 入侵检测
- Fault detection 故障检测
- System health monitoring 系统健康监控
- Detect ecosystem disturbances 检测生态系统干扰
- Anomaly detection for product quality 产品质量异常检测
结论 (Conclusion)
Anomaly detection is a technique of finding rare items or data points that will differ significantly from the rest of the data. Even though the terminology behind anomaly detection uses the probability theory and some statistics, there are many techniques to easily implement an anomaly detection algorithm.
异常检测是一种发现与其他数据有显着差异的稀有物品或数据点的技术。 即使异常检测背后的术语使用概率论和一些统计数据,也有许多技术可以轻松实现异常检测算法。
翻译自: https://towardsdatascience.com/introduction-to-anomaly-detection-c651f38ccc32
可检测异常和不可检测异常















 862
862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









