






 本文介绍了如何在Python中应用自适应套索回归方法,该方法源自一篇名为'An Adaptive Lasso'的文章,旨在通过套索正则化进行变量选择和模型简化。
本文介绍了如何在Python中应用自适应套索回归方法,该方法源自一篇名为'An Adaptive Lasso'的文章,旨在通过套索正则化进行变量选择和模型简化。
python 套索回归
This is my second post on the series about penalized regression. In the first one we talked about how to implement a sparse group lasso in python, one of the best variable selection alternatives available nowadays for regression models, but today I would like to go one step ahead and introduce the adaptive idea, that can convert your regression estimator into an oracle, something that knows the truth about your dataset.
这是我关于惩罚回归系列的第二篇文章。 在第一个中,我们讨论了如何在python中实现稀疏组套索 ,这是当今回归模型可用的最佳变量选择替代方案之一,但今天我想向前迈一步,介绍自适应思想 ,该思想可以转换您的回归估算器到oracle中 ,它可以知道有关数据集的真相。
Today we will see:
今天我们将看到:
What are the problems that lasso (and other non-adaptive estimators) face
套索 (和其他非自适应估计器)面临的问题是什么
What is the oracle property and why you should use oracle estimators
什么是oracle属性以及为什么应使用oracle估计器
How to obtain the adaptive lasso estimator
如何获得自适应套索估计
How to implement an adaptive estimator in python
如何在python中实现自适应估计器
套索处罚的问题 (Problems of lasso penalization)
Let me start with a brief introduction of lasso regression. Imagine you are working with a dataset in which you know that only a few of the variables are truly related with the response variable but you do not know which ones. Maybe you are dealing with a high dimensional dataset with more variables than observations, in which a simple linear regression model cannot be solved. For example, a genetic dataset formed by thousands of genes but in which just a few genes are related with a disease.
首先让我简单介绍一下套索回归 。 假设您正在使用一个数据集,在该数据集中您知道只有少数几个变量与响应变量真正相关 ,但是您不知道哪个变量。 也许您正在处理的高维数据集具有比观测值更多的变量,其中无法解决简单的线性回归模型。 例如,由数千个基因组成的遗传数据集,但其中只有少数基因与疾病有关。
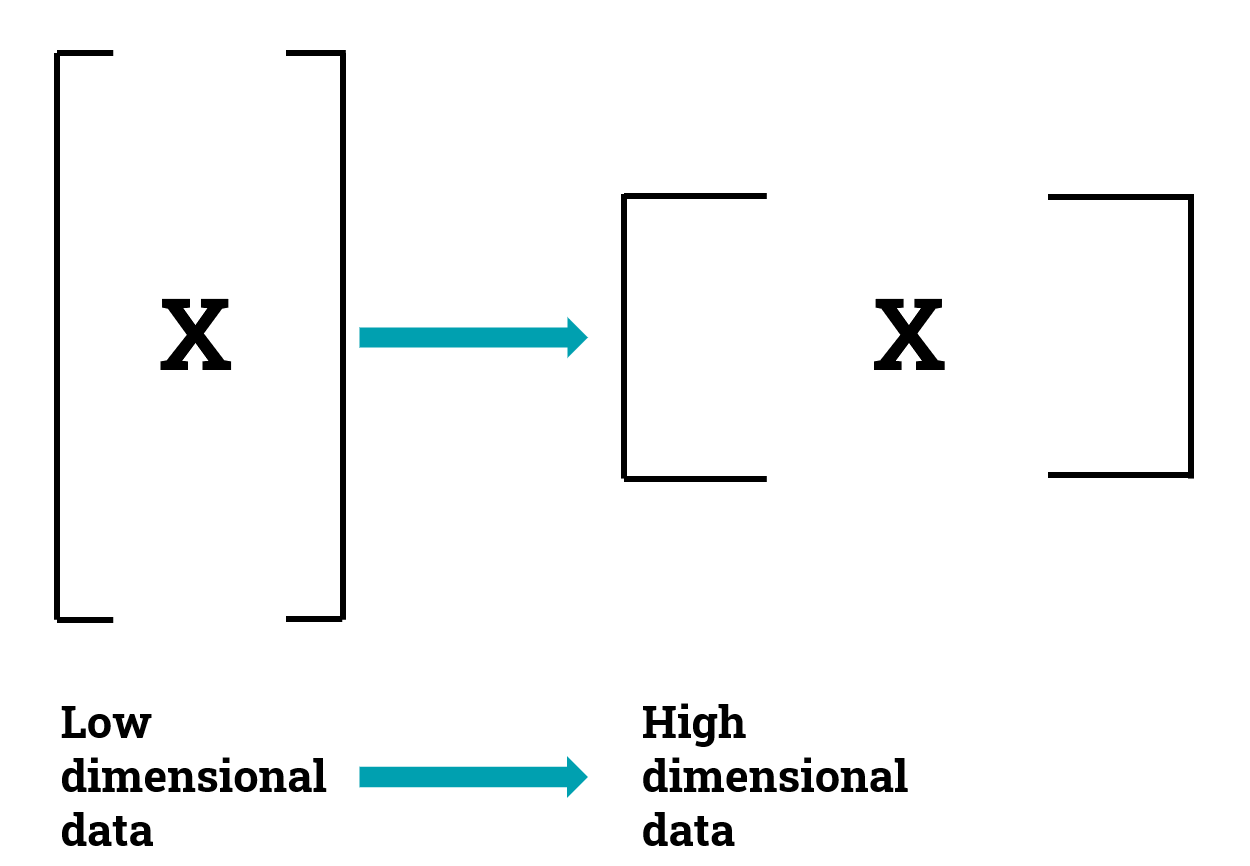
So you decide to use lasso, a penalization that adds an L1 constraint to the β coefficients of the regression model.
因此,您决定使用套索,这是对回归模型的β系数添加L1约束的惩罚。

This way, you obtain solutions that are sparse, meaning that many of the β coefficients will be sent to 0 and your model will make predictions based on the few coefficients that are not 0.
这样,您将获得稀疏的解决方案,这意味着许多β系数将被发送为0,并且您的模型将基于少数几个非0的系数进行预测。
You have potentially reduced the predic
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









