





aws big data
There are varying definitions of a Data Lake on the internet. Some sites define it as a centralized repository to store structured and unstructured data, others talk about storing data in raw formats so that it can be processed later using schema on read. All good…but I would like to add something very important regarding the storage and computing layers.
互联网上数据湖的定义各不相同。 一些站点将其定义为存储结构化和非结构化数据的集中式存储库,另一些站点则谈论以原始格式存储数据,以便以后可以使用读取时的模式对其进行处理。 一切都很好……但是我想在存储和计算层上添加一些非常重要的内容。
Last few years I have been part of several Data Lake projects where the Storage Layer is very tightly coupled with the Compute Layer. Although this design works well for infrastructure using on-premises physical/virtual machines. However it may not be the best idea for cloud infrastructures — resources need to be on 24x7.
最近几年,我参与了多个Data Lake项目,其中存储层与计算层紧密结合 。 尽管此设计对于使用本地物理/虚拟机的基础结构非常有效。 但是,对于云基础架构而言,这可能不是最好的主意-资源必须全天候24x7。
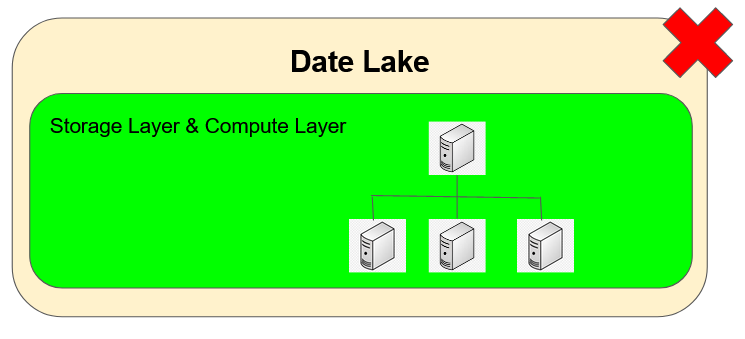
存储很便宜,但是计算很昂贵—解耦存储和计算 (Storage is cheap but Compute is expensive — Decouple Storage and Compute)
As an alternative I support the idea of decoupling storage and compute. This way the only the non-expensive storage layer needs to on 24x7 and yet the expensive compute layer can be created on demand only for the period when it is required.
作为替代方案,我支持将存储和计算分离的想法。 这样,唯一的非昂贵存储层就需要24x7全天候运行,而昂贵的计算层只能在需要时按需创建。

I demonstrated how this can be done in one of my previous article (link below).
我在上一篇文章(下面的链接)中演示了如何做到这一点。
DataOps — Fully Automated, Low Cost Data Pipelines using AWS Lambda and Amazon EMR
DataOps —使用AWS Lambda和Amazon EMR的全自动,低成本数据管道
Since we support the idea of decoupling storage and compute lets discuss some Data Lake Design Patterns on AWS. I have tried to classify each pattern based on 3 critical factors:
由于我们支持将存储和计算脱钩的想法,因此让我们讨论AWS上的一些Data Lake设计模式。 我尝试根据3个关键因素对每种模式进行分类:
- Cost 成本
- Operational Simplicity 操作简便
- User Base 用户群
简单 (The Simple)
The Data Collection process continuously dumps data from various sources to Amazon S3. Using a Glue crawler the schema and format of data is inferred and the table metadata is stored in AWS Glue Catalog. For data analytics users can use Amazon Athena to query data using standard SQL.
数据收集过程不断将数据从各种来源转储到Amazon S3。 使用Glue搜寻器,可以推断数据的架构和格式,并将表元数据存储在AWS Glue Catalog中。 对于数据分析,用户可以使用Amazon Athena通过标准SQL查询数据。

Low cost, operationally simple (server-less architecture). Querying using standard SQL makes analysts, business intelligence developers and ad-hoc reporting users pretty happy. Not so for data scientists, machine learning/AI engineers. They typically want to fetch data from files, preferably large ones and binary formats like Parquet, ORC and Avro.
低成本,操作简单(无服务器架构)。 使用标准SQL查询使分析师,商业智能开发人员和即席报告用户非常满意。 对于数据科学家,机器学习/人工智能工程师而言并非如此。 他们通常希望从文件中获取数据,最好是大文件和二进制格式(如Parquet,ORC和Avro)。
正好 (Just Right)
The Data Collection process continuously dumps data from various sources to Amazon S3. A Glue ETL job curates/transforms data and writes data as large Parquet/ORC/Avro. Using a Glue crawler the schema and format of curated/transformed data is inferred and the table metadata is stored in AWS Glue Catalog. For data analytics users have an option of either using Amazon Athena to query data using standard SQL or fetch files from S3.
数据收集过程不断将数据从各种来源转储到Amazon S3。 Glue ETL作业负责整理/转换数据,并将数据写入大型Parquet / ORC / Avro。 使用Glue搜寻器,可以推断策展/转换数据的架构和格式,并将表元数据存储在AWS Glue Catalog中。 对于数据分析,用户可以选择使用Amazon Athena通过标准SQL查询数据或从S3获取文件。

Economically priced, operationally simple (server-less architecture). Analysts, business intelligence developers have the option of using Amazon Athena. Data scientists, machine learning/AI engineers can fetch large files in a suitable format that is best for their needs. Everyone is happy…sort of.
价格经济,操作简单(无服务器架构)。 分析师,商业智能开发人员可以选择使用Amazon Athena。 数据科学家,机器学习/人工智能工程师可以以最适合其需求的合适格式来获取大文件。 每个人都很高兴……有点。
The drawback of this pattern is that it pushes the complex transformations and joining data operations to be handled either by Amazon Athena or assumes that these operations will be programmatically handled by the data scientists and machine learning/AI engineers. Both of these options are not desirable in some cases because of degraded performance as well as non-standard and non-reusable data.
这种模式的缺点是,它将推动复杂的转换和联接数据操作,由Amazon Athena处理,或者假定这些操作将由数据科学家和机器学习/ AI工程师以编程方式处理。 在某些情况下,由于性能下降以及非标准和不可重用的数据,这两个选项都不可取。
精致的 (The Sophisticated)
The Data Collection process continuously dumps data from various sources to Amazon S3. A Glue ETL job curates/transforms data and writes data as large Parquet/ORC/Avro. This data is copied into Amazon Redshift tables which stores data in tables which span across multiple nodes using key distribution. Users can utilize Amazon Redshift not only for Ad-hoc reporting but also for complex transformation and joining data sets. Additionally, the transformed and joined version of data can be dumped to large files for consumption by data scientists and machine learning/AI engineers. Everyone is more than happy.
数据收集过程不断将数据从各种来源转储到Amazon S3。 Glue ETL作业负责整理/转换数据,并将数据写入大型Parquet / ORC / Avro。 将此数据复制到Amazon Redshift表中,该表使用密钥分发将数据存储在跨多个节点的表中。 用户不仅可以将Amazon Redshift用于临时报告,还可以用于复杂的转换和联接数据集。 此外,经过转换和合并的数据版本可以转储为大文件,供数据科学家和机器学习/ AI工程师使用。 每个人都很高兴。

Higher priced, operationally still relatively simple (server-less architecture). Performs all computations using distributed & parallel processing so performance is pretty good. Everyone gets what they need, in the format they need it in. The higher price may be justified because it simplifies complex transformations by performing them in a standardized and reusable way.
价格更高,操作上仍然相对简单(无服务器架构)。 使用分布式和并行处理执行所有计算,因此性能相当不错。 每个人都能以他们需要的格式获得他们所需要的东西。较高的价格是合理的,因为它通过以标准化和可重用的方式执行来简化复杂的转换。
I hope the information above helps you choose the right data lake design for your business. I am always open to chat if you need further help.
我希望以上信息可以帮助您为业务选择正确的数据湖设计。 如果您需要进一步的帮助,我会随时与您聊天。
aws big data















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









