





r语言 并行
Loops are, by definition, repetitive tasks. Although it is not part of the definition, loops also tend to be boring. Luckily for us, computers are good at performing repetitive tasks, and they never complain about boredom.
根据定义,循环是重复性任务。 尽管它不是定义的一部分,但循环也很无聊。 对我们来说幸运的是,计算机擅长执行重复性任务,并且从不抱怨无聊。
When the tasks are complex, or if the number of repetitions is high, loops may take a lot of time to run even on a computer. There are several strategies to increase the execution speed of loops. In this short tutorial, we will talk about one of them: parallelization.
当任务很复杂,或者重复次数很多时,即使在计算机上运行循环也可能要花费很多时间。 有几种策略可以提高循环的执行速度。 在这个简短的教程中,我们将讨论其中之一:并行化。
先决条件 (Prerequisites)
R is required, and RStudio is recommended. Additionally, some libraries may be required. If you are missing any, you can install it running install.package('<library-name>'), where <library-name> stands for the name of the library (for instance, install.package('parallel')).
R是必需的,建议使用RStudio。 此外,可能需要一些库。 如果缺少任何内容,可以运行install.package('<library-name>') ,其中<library-name>代表<library-name> (例如, install.package('parallel') ) 。
If you prefer to execute it line-by-line, you may be interested in visiting the vignette version of this tutorial.
如果您希望逐行执行它,则可能有兴趣访问本教程的小插图版本 。
为什么要并行化? (Why parallelizing?)
Modern laptops typically have 4 or 8 cores. Each of them can be loosely thought of as an independent mini-computer, capable of doing tasks independently of the other ones. The number of cores in your computer can be retrieved from R with the command:
现代笔记本电脑通常具有4或8核。 可以将它们每个人大致地看作是一台独立的微型计算机,能够独立于其他微型计算机执行任务。 可以使用以下命令从R检索计算机中的内核数:
numCores <- parallel::detectCores() # Requires library(parallel)
print(numCores)# In my case, this prints 8When a program runs serially (as they usually do by default), only one core is recruited for performing the program’s task. Recruiting more than one core for a given task is known as parallelization. The desired result of parallelizing a task is a reduction in its execution time. An analogy could be to build a wall by laying bricks alone, one by one (serial) as opposed to building it with the help of three friends (parallel with 4 “cores”).
当程序以串行方式运行时(如通常情况下默认运行),只会招募一个内核来执行程序的任务。 为给定任务招募多个内核称为并行化。 并行执行任务的期望结果是减少了执行时间。 打个比方,可以是一个人(一连串)单独砌砖砌墙,而不是在三个朋友(平行于四个“核”)的帮助下砌墙。
In the figure below, we see the CPU usage over time of my computer performing the same task serially (highlighted in green) and in parallel (in red). Both processes performed the very same task and produced the same result, but the parallel one, recruiting more cores, ran roughly three times faster.
在下图中,随着时间的推移,我们可以看到计算机连续(以绿色突出显示)和并行(以红色突出显示)执行相同任务时的CPU使用率。 这两个进程执行的任务非常相同,并且产生相同的结果,但是并行的进程(招募更多的内核)的运行速度大约快了三倍。
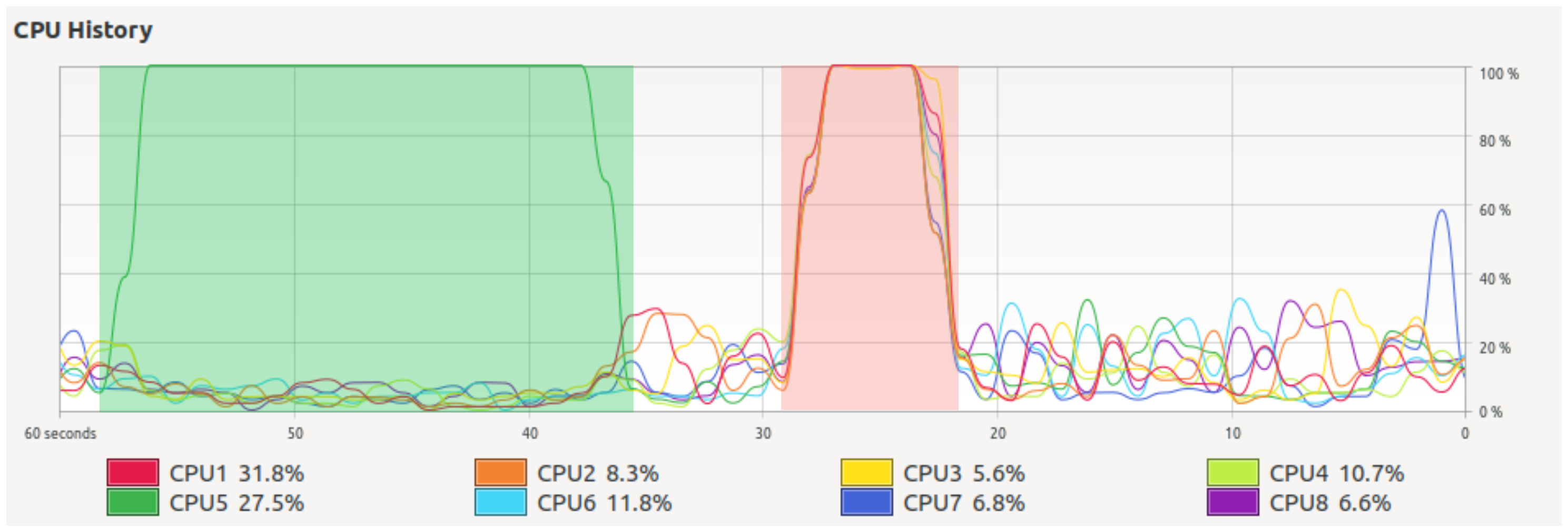
It may be surprising to notice that using 8 cores instead of one didn’t multiply the speed by 8. This is normal. Parallelization rarely behaves as linearly as we would like. A reason for this is that the code, and often also the data, has to be copied to each of the cores. The output of each core also has to be put together, and this also consumes time. Following the analogy of the 4 brick-layers, it is clear that building a wall with friends requires a bit of planning and coordination before starting laying the bricks (at least if we want the wall to be one wall, and not four disconnected pieces). Intuition also tells us that, while perhaps asking for the help of 4 friends may be a good idea, calling 256 friends could be an organizational nightmare. For a more formal approach to these ideas, check Amdahl’s law.
可能令人惊讶地注意到,使用8个内核而不是1个内核并未使速度乘以8。这是正常的。 并行化很少像我们希望的那样线性运行。 这样做的原因是必须将代码(通常还有数据)复制到每个内核。 每个内核的输出也必须放在一起,这也很费时间。 遵循4个砖层的类比,很明显,与朋友一起建造一堵墙需要在开始铺设砖之前进行一些计划和协调(至少如果我们希望该墙成为一堵墙,而不是四个断开的部分) 。 直觉还告诉我们,虽然寻求4个朋友的帮助可能是个好主意,但打电话给256个朋友可能是组织上的噩梦。 有关这些想法的更正式方法,请查看阿姆达尔定律 。
More importantly, some repetitive tasks are not parallelizable at all. For instance, what if instead of a brick wall we want to make a brick stack? There is no point in laying the 3rd brick if the 1st and 2nd are not there already!
更重要的是,某些重复性任务根本无法并行化。 例如,如果我们要代替砖墙而不是砖墙,该怎么办? 如果没有第一块和第二块,那就没必要铺设第三块了!
But don’t worry about these details now. The example I’ve prepared for you is going to work fine.
但是现在不用担心这些细节。 我为您准备的示例可以正常工作。
我们需要一项任务来执行 (We need a task to perform)
In this short introduction, I want to show different approaches, some of them serial and some of them parallel, to approach a parallelizable problem. A good example task for showing the advantages of parallelization would be one that:
在这个简短的介绍中,我想展示不同的方法,其中一些是串行的,而有些是并行的,以解决可并行化的问题。 显示并行化优点的一个很好的示例任务是:
- Is simple. 很简单。
- Takes an appreciable amount of CPU time to be completed. 需要相当多的CPU时间才能完成。
The problem of deciding if a large integer is prime or not fulfills both characteristics.
确定大整数是否为质数的问题同时满足了这两个特征。
It will be a good idea to split our task into a function (describing WHAT to do) and an input (describing to WHOM).
将我们的任务分为一个功能 (描述要做什么)和一个输入 (描述WHOM)将是一个好主意。
In our case, the function performs a test on primality (if you think this is a silly function, you are right, but please see Notes at the end of this tutorial).
在我们的例子中,该函数对素数进行测试(如果您认为这是一个愚蠢的函数,那是对的,但是请参阅本教程结尾的注释)。
fun <- function(x) {
numbers::isPrime(x) # Requires the package numbers
}And the input is just a vector containing 1000 large integers (that I created programmatically just to not have to type then one-by-one).
输入只是一个包含1000个大整数的向量(我是通过编程方式创建的,不必键入那么一个一个)。
# Generate some large integers
N <- 1000 # Number of integers
min <- 100000 # Lower bound
max <- 10000000000 # Upper boundinputs <- sample(min:max, N) # List of N random large integers (between 1e5 and 1e10)These two objects, fun and inputs, define the homework we want to assign to our computer (in this case, to decide which integers from the list of inputs are prime). We also want our computer to store the results. We will do this in six different ways, two of them parallel. Later, we’ll compare their performance.
这两个对象( fun和inputs )定义了我们要分配给计算机的作业 (在这种情况下,要确定输入列表中的哪些整数是素数)。 我们还希望我们的计算机存储结果。 我们将以六种不同的方式执行此操作,其中两种并行。 稍后,我们将比较它们的性能。
可能性0:连续运行 (Possibility 0: run serially)
In this section, we’ll see three different ways of solving our problem by running serially. That is, without using parallelization. The user is likely to be familiar with at least some of them.
在本节中,我们将看到通过串行运行来解决问题的三种不同方式。 即,不使用并行化。 用户可能至少熟悉其中一些。
0.1循环循环运行 (0.1 Run serially with a loop)
This is the most straightforward approach, although not very efficient. The basic structure is given in the snippet below.
尽管不是很有效,但这是最直接的方法。 基本结构在下面的代码段中给出。
results <- rep(NA, N) # Initialize results vector
for (i in 1:N) { # Loop one by one along the input elements
results[i] <- fun(inputs[i])
} 0.2与foreach串行运行 (0.2 Run serially with foreach)
Theforeachpackage saves us the explicit typing of the index (compare with the for loop in the previous example). The output of foreach is, by default, a list. We used the parameter .combine = "c" (concatenate) to return the output as a vector.
foreach包为我们节省了索引的显式类型(与上一个示例中的for循环相比)。 默认情况下, foreach的输出是一个列表。 我们使用参数.combine = "c" (并置)将输出作为矢量返回。
# Load the required libraries
library(foreach)foreach (val = inputs, .combine = "c") %do% {
fun(val) # Loop one-by-one using foreach
} -> results 0.3与lapply连续运行 (0.3 Run serially with lapply)
lapply is usually preferred over explicit for or foreach loops.
通常, lapply优于显式for或foreach循环。
results <- lapply(inputs, fun) # Use lapply instead of for loop并行执行! (Do it in parallel!)
And now, we’ll finally use parallel programming to solve our problem.
现在,我们最终将使用并行编程来解决我们的问题。
可能性1:与mclapply并行运行(仅Linux) (Possibility 1: run in parallel with mclapply (Linux only))
mclapply is part of the parallel library. Rule of thumb: use it instead of lapply. If the code is parallelizable, it will do the magic:
mclapply是parallel库的一部分。 经验法则:使用它代替lapply 。 如果代码是可并行化的,那么它将发挥作用:
# Load the required libraries
library(parallel)# Run parallel
results <- mclapply(inputs, fun, mc.cores = numCores)
# Note that the number of cores is required by mclapplyUnfortunately, this approach only works on Linux. If you are working on a Windows machine, it will perform as a serial lapply.
不幸的是,这种方法仅适用于Linux。 如果您在Windows计算机上工作,它将作为串行lapply执行。
可能性2:与doParallel + foreach并行运行 (Possibility 2: run in parallel with doParallel + foreach)
Rule of thumb: doParallel transforms a foreach loop into a parallel process. Provided, of course, the underlying process is parallelizable.
经验法则: doParallel将foreach循环转换为并行过程。 当然,只要基础过程是可并行的。
# Load the required libraries
library(iterators)
library(doParallel)# Initialize
registerDoParallel(numCores)# Loop
foreach(val = inputs, .combine = "c") %dopar% {
fun(val)
} -> results可能性3:利用向量功能 (Possibility 3: take advantage of vector functions)
Most (but not all) of R functions can work with vectorized inputs. This means that the function accepts a vector of inputs and returns an equally sized vector of outputs. This allows hiding the whole loop in a single, easy-to-read line.
R函数的大多数(但不是全部)可以与矢量化输入一起使用。 这意味着该函数接受输入向量,并返回大小相等的输出向量。 这样可以将整个循环 隐藏在单个易于读取的行中。
results <- fun(inputs)More importantly, although running serially, vector functions often run faster than parallel schemes. Why not use them always then? The quick answer is: we are not always lucky enough to have a function that accepts a vector input.
更重要的是,矢量函数虽然串行运行,但通常比并行方案运行得更快。 那么为什么不总是使用它们呢? 快速的答案是:我们并不总是幸运地拥有接受矢量输入的功能。
比较结果 (Compare results)
In the figure below we plot the execution times of each of the six methods we tried. We also provide a summary table for each of them.
在下图中,我们绘制了我们尝试的六个方法的执行时间。 我们还提供了每个表格的摘要表。

We notice that the parallel methods performed significantly better than the serial ones. We also notice that the vector method performed even better (but keep in mind not all functions are vectorizable).
我们注意到并行方法的性能明显好于串行方法。 我们还注意到向量方法的执行效果更好(但请注意,并非所有函数都可以向量化)。
Pro tip: what about using vectorization AND parallelization?
专业提示:使用向量化和并行化怎么办?
尝试并行化不可并行化的代码 (Trying to parallelize non-parallelizable code)
In this subsection we’ll use the expression below as an example:
在本小节中,我们将使用以下表达式作为示例:

It is just a recipe to build a list of numbers by adding 1 to the previous number in the list. It is easy to see that, when initialized with x0=0, this iterator yields {0,1,2,3,4,…}. Note that in order to obtain the value a given x in position n, we need to know the value of the previous x (that in position n-1; remember the analogy of building a stack of bricks). This operation is thus intrinsically serial.
只是通过在列表中的前一个数字上加1来构建数字列表的方法。 很容易看到,当用x 0 = 0初始化时,此迭代器产生{0,1,2,3,4,…}。 请注意,为了获得位置n处给定x的值,我们需要知道前一个x的值(位置n-1中的值;请记住类似的方法,即构造一堆砖块)。 因此,该操作本质上是串行的。
In this case, our function and inputs look like:
在这种情况下,我们的函数和输入如下所示:
fun <- function(x) {x + 1}N <- 6
inputs <- rep(NA, N) # Initialize as (0, NA, NA, ..., NA)
inputs[1] <- 0Using a serial loop everything works fine:
使用串行循环,一切正常:
foreach(i = 2:N) %do% {
inputs[i] <- fun(inputs[i-1])
}# The result is the expected: 0 1 2 3 4 5But what if we insist on parallelizing? After all, our serial loop is very similar to the foreach + doParallel one, so it is tempting to at least try. And what happens then? As expected, it simply doesn’t work properly. And more worryingly, doesn’t throw an error either!
但是,如果我们坚持并行化怎么办? 毕竟,我们的串行循环与foreach + doParallel十分相似,因此至少可以尝试一下。 那会发生什么呢? 不出所料,它根本无法正常工作。 更令人担忧的是,也不会引发错误!
inputs <- rep(NA, N) # Initialize again
inputs[1] <- 0foreach(i = 2:N) %dopar% {
inputs[i] <- fun(inputs[i-1])
}# The result in this case is a disastrous 0 NA NA NA NA NAAnd that was it. This is just a quick starting guide to a complicated topic. If you want to know more, I suggest you go directly to the future library.
就是这样。 这只是一个复杂主题的快速入门指南。 如果您想了解更多信息,建议您直接转到将来的库。
笔记 (Notes)
The astute reader may have noticed that our function fun is a mere renaming of the function isPrime contained in the package numbers. The reason for that is merely pedagogical: we want the readers to:
精明的读者可能已经注意到,我们的函数fun只是对包含在包装numbers中的函数isPrime重命名。 这样做的原因仅仅是教学上的:我们希望读者:
- Notice that the structure input -> function -> results is indeed VERY general. 注意,结构输入->函数->结果的确非常通用。
Be able to try their own pieces of slow code inside the body of
fun(this can be done comfortably using our vignette).能够在
fun程序内尝试自己的慢速代码(可以使用我们的插图轻松地完成此操作)。
您是否更喜欢Python? (Are you more into Python?)
We can also help with that! Check out this other tutorial: Parallel program in Python.
我们也可以提供帮助! 查看其他教程: Python中的并行程序 。
致谢 (Acknowledgments)
I want to say thanks to Lourens Veen, Peter Kalverla and Patrick Bos. Their useful comments definitely improved the clarity of the final text.
我要感谢Lourens Veen , Peter Kalverla和Patrick Bos 。 他们的有用评论无疑提高了最终文本的清晰度。
翻译自: https://blog.esciencecenter.nl/parallel-r-in-a-nutshell-4391d45b5461
r语言 并行















 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









