





学习spark scala
Before continue, There is Introduction to Apache Spark from me. You can head to the link if you are new to Apache SparkWelcome to some practical explanations to Apache Spark with Scala. There is even Python supported Spark is available which is PySpark. For the sake of this post, I am continuing with Scala with my windows Apache Spark installation.
欢迎使用Scala对Apache Spark进行一些实用的解释。 甚至提供了受Python支持的Spark,即PySpark。 为了这篇文章的缘故,我将在Windows Apache Spark安装中继续使用Scala。
Spark ShellGo to the Spark installation directory and cd to bin folder. type spark-shell, enter. You will see Spark Session being started and showing some logs which are very important.
Spark Shell转到Spark安装目录,并cd到bin文件夹。 输入spark-shell ,输入。 您将看到Spark Session正在启动,并显示一些非常重要的日志。
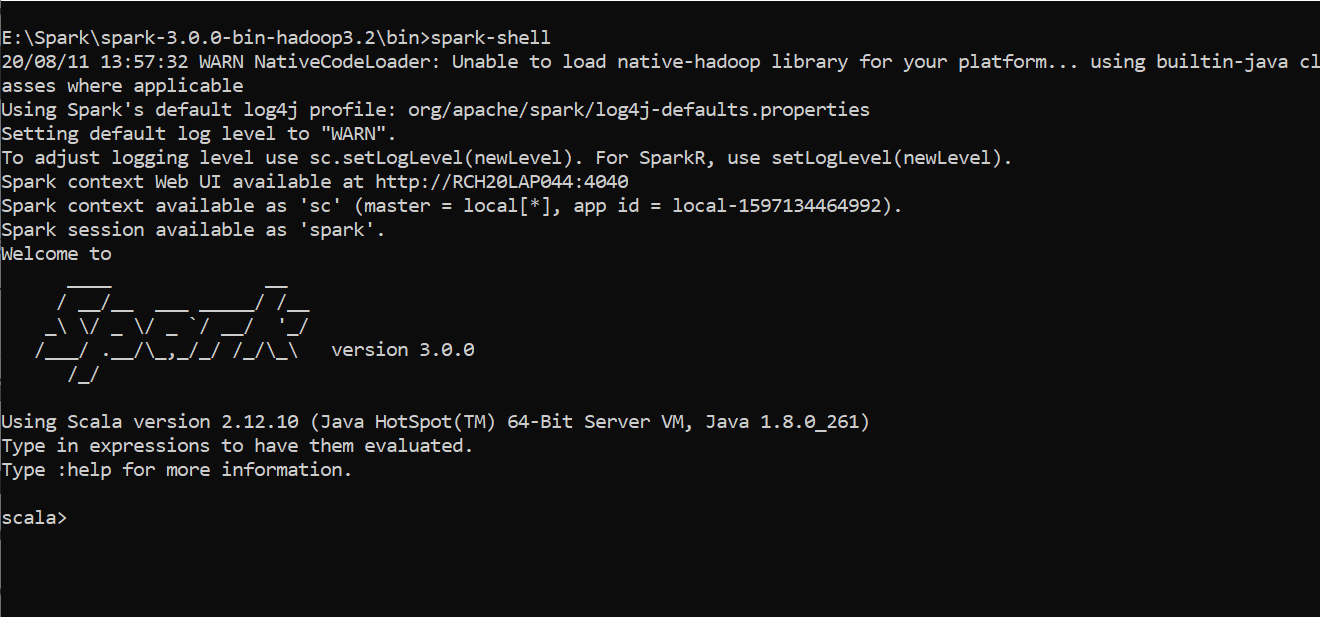
spark-shell command provides a simple way to learn the Spark API, as well as a powerful tool to analyze data interactively. It is available in either Scala or Python
火花壳 命令提供了学习Spark API的简单方法,以及强大的工具以交互方式分析数据。 它可以在Scala或Python中使用
Let's discuss some terms logged for spark-shell command.
让我们讨论一下spark-shell命令记录的一些术语。
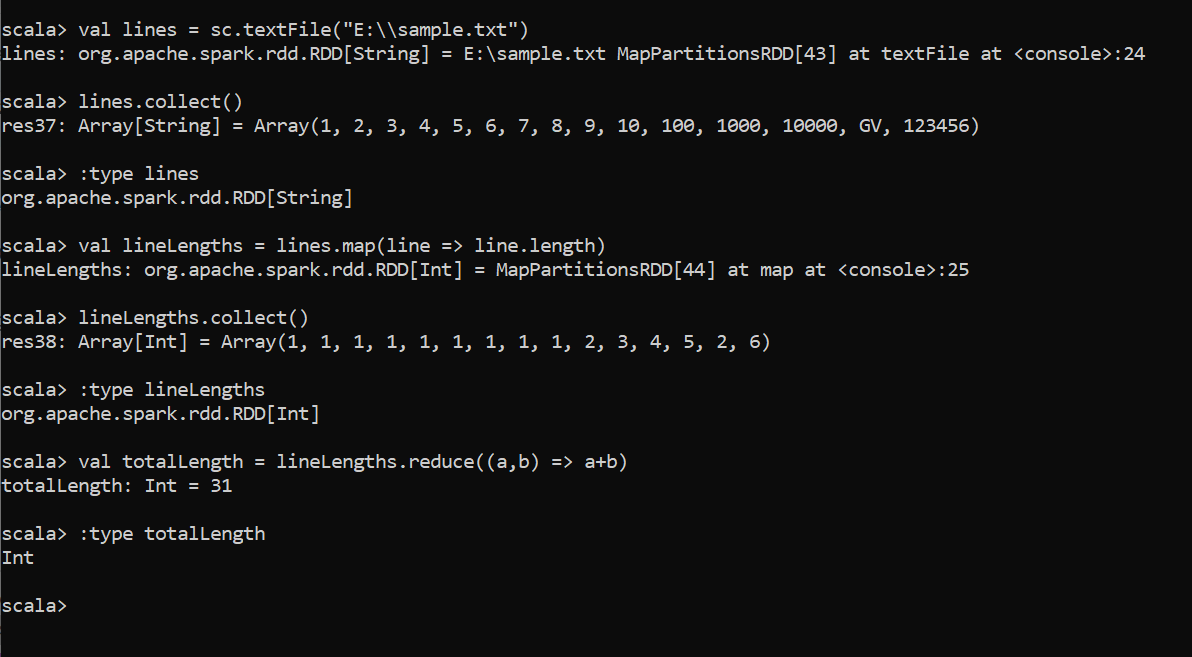
SparkContext(sc) is the entry point for Spark functionality. A Spark Context represents the connection to a Spark cluster and can be used to create RDDs in the cluster. Only one SparkContext should be active per JVM. All about Sparck Context constructors and Methods can be found here official link.SparkContext(sc)是Spark功能的入口点。 Spark上下文表示与Spark集群的连接,可用于在集群中创建RDD。 每个JVM仅应激活一个SparkContext。 有关Sparck Context构造函数和方法的所有信息都可以在此处找到官方链接 。SparkSession(spark) is the entry to programming Spark with the Dataset and DataFrame API. It is one of the very first objects you create while developing a Spark SQL applicationSparkSession(火花)是使用Dataset和DataFrame API对Spark进行编程的条目 。 它是您在开发Spark SQL应用程序时创建的第一批对象之一We can see the Spark UI from http://rch20lap044:4040/jobs/. This address can be different for each system. This UI gives all the details about the currently running job, storage details, Executors details, and more.
我们可以从http:// rch20lap044:4040 / jobs /看到Spark UI。 每个系统的该地址可以不同。 该UI提供了有关当前正在运行的作业的所有详细信息,存储详细信息,执行程序详细信息等等。
Spark-Shell Commands:
Spark-Shell命令:
:help
:救命
Prints all the options available given by spark-shell.
打印spark-shell给定的所有可用选项。
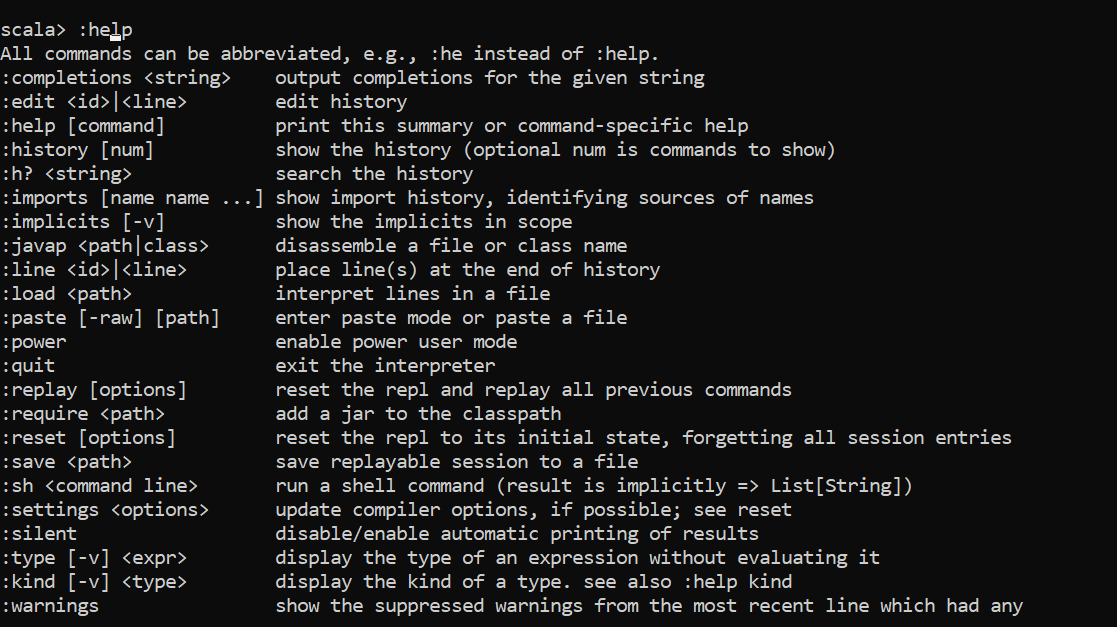
We have already seen that two variables are given by the spark to the console sc and spark. To know the type of these variables, :type option can be used. These variables are given from Spark by default.
我们已经看到,spark给控制台sc和spark提供了两个变量。 要知道这些变量的类型,可以使用:type选项。 默认情况下,这些变量是由Spark提供的。
We can see the history of the commands used by :history. Spark provides an autocomplete feature with a tab button.
我们可以看到:history使用的命令的历史记录。 Spark通过选项卡按钮提供了自动完成功能。
- Let's have some hands-on on RDD. RDS is the basic data unit of Apache Spark on top of which all the operations performed. RDDs are immutable objects means once RDD created, We can modify it. RDD can be of any type supported by the language used with Spark, here it is Scala. 让我们亲身体验RDD。 RDS是Apache Spark的基本数据单元,在其上面执行所有操作。 RDD是不可变的对象,这意味着一旦创建了RDD,我们就可以对其进行修改。 RDD可以是Spark使用的语言支持的任何类型,这里是Scala。
Create RDD:There are three methods available to create RDD.Those are,
创建RDD:可以使用三种方法来创建RDD。

Parallelized Connection:
并行连接:
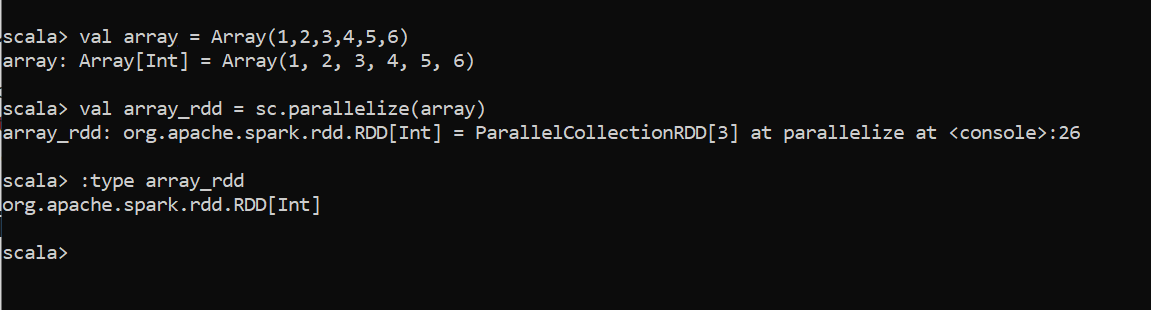
Parallelized collections are created by calling
通过调用创建并行集合
SparkContext’sparallelizemethod on an existing collection in your driver program. In the below image, With the array object, RDD can be created using SparkContext’s parallelize method.驱动程序中现有集合上的
SparkContext的parallelize方法。 在下图中,使用数组对象,可以使用SparkContext的parallelize方法创建RDD。
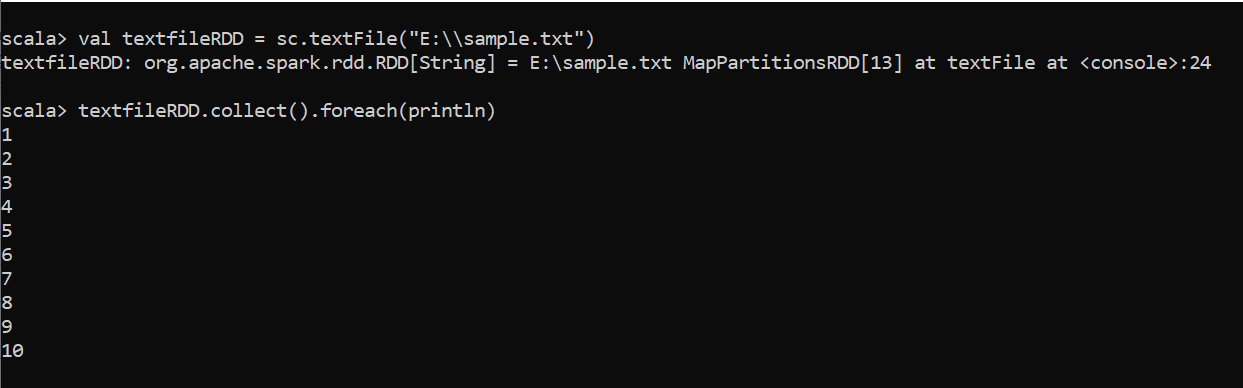
External data: Spark can create distributed datasets from any storage source supported. The text file also can be read into RDD using context’s textFile method.
外部数据: Spark可以从支持的任何存储源创建分布式数据集。 也可以使用上下文的textFile方法将文本文件读入RDD。
The collect function used to get the data from RDD.
收集功能用于从RDD获取数据。
From RDDs:RDDs can be created from already existing RDDs using transformations functions available in Spark.
从RDD:可以使用Spark中可用的转换功能从现有RDD创建RDD。
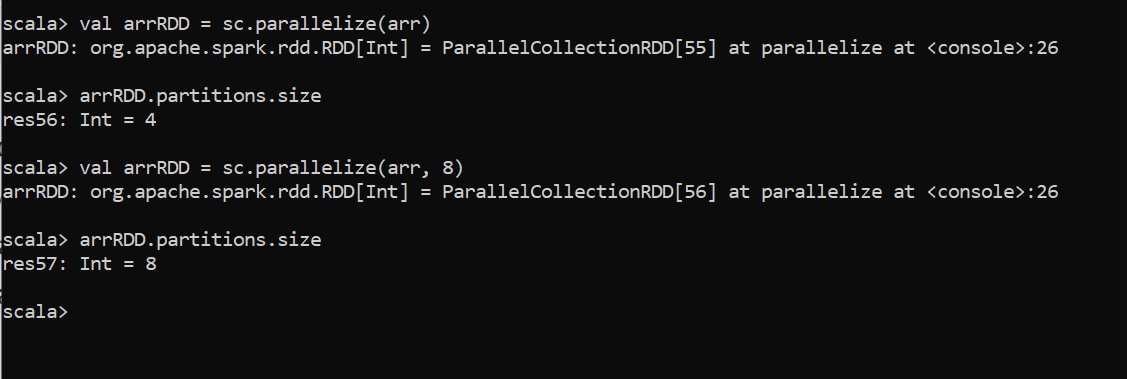
Partitions in RDD:When we create RDD, By default, RDDs will be divided into partitions. RDD has an attribute named partitions which give lots of methods to get the information about the partitions on RDD.
RDD中的分区:创建RDD时,默认情况下,RDD将分为多个分区。 RDD具有一个名为partitions的属性,该属性提供了许多方法来获取有关RDD上的分区的信息。
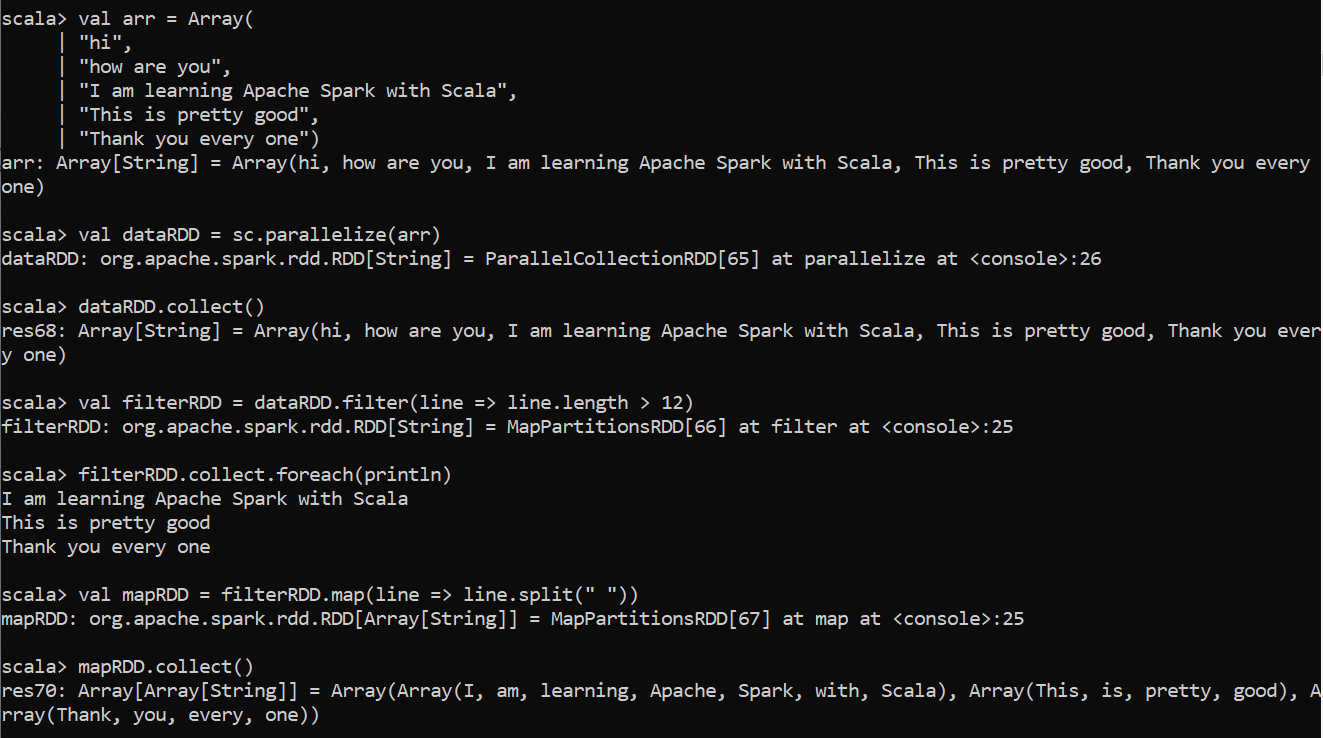
RDD Transformations:RDD Transformations creates new RDD from existing RDD. Transformation functions can be applied to RDD at any point in time. Since Spark accepts Lazy Loading attitude, Transformations will be Started only when Action been called in the program. The below example shows filter and map transformation functions.
RDD转换: RDD转换从现有RDD创建新的RDD。 转换函数可以在任何时间点应用于RDD。 由于Spark接受“延迟加载”态度,因此仅在程序中调用Action时才会启动转换。 以下示例显示了过滤器和地图转换功能。
There are two transformations available in Spark.Narrow Transformations & Wide Transformations
Spark有两种可用的转换。 窄变和宽变
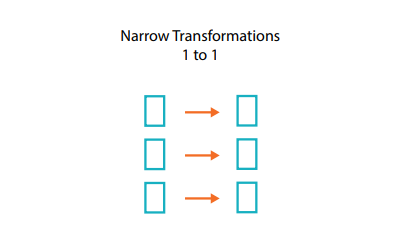
It means that one input partition in the RDD will contribute to only one partition of output RDD. Narrow transformations are the result of map(), filter() functions.
这意味着RDD中的一个输入分区将仅贡献输出RDD的一个分区。 窄转换是map(),filter()函数的结果。
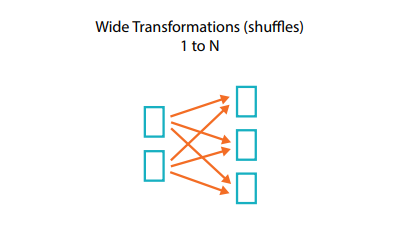
In this type, Input partitions contributing to many output partitions. Wide transformations are the result of groupbyKey() and reducebyKey() functions.
在这种类型中,输入分区有助于许多输出分区。 广泛的转换是groupbyKey()和reducebyKey()函数的结果。
Important Transformation Functions:
重要的转换功能:
map:Map function iterates over the RDD applies the given function or action to all the elements in the RDD. Map function changes all the elements in the RDD means that Map transforms an RDD of length N into another RDD of length N. The input and output RDDs will typically have the same number of records.
map:在RDD上迭代的Map函数将给定的函数或操作应用于RDD中的所有元素。 映射函数更改在RDD意味着地图变换长度N的RDD为长度N的另一RDD 输入和输出 RDDS通常将具有相同数目的记录的所有元素。
scala> val array = Array(1,2,3,4,5,6,7,8,9,10)
array: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)scala> val arrayRDD = sc.parallelize(array)
arrayRDD: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[71] at parallelize at <console>:26scala> val rddTransformed = arrayRDD.map(element => element * 10)
rddTransformed: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[72] at map at <console>:25scala> rddTransformed.collect()
res73: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)2. flatmap:flatmap transformation can give many outputs to the RDD. Map and flatMap are similar in the way that they take a line from input RDD and apply a function on that line. The key difference between map() and flatmap() is map() returns only one element, while flatMap() can return a list of elements.
2. flatmap: flatmap转换可以为RDD提供许多输出。 Map和flatMap的相似之处在于它们从输入RDD中获取一条线并在该线上应用函数。 密钥d map()和flatmap之间。差分()是图()只有一个元件返回,而flatMap()可以返回元素的列表。
scala> val array = Array(
| "Spark is a processing Engine",
| "It follows lazy loading concept",
| "Means transformation functions will not be processed until action called",
| "Because of this, Memory handling can be done effectively",
| "Spark also stored RDD in multiple partitions",
| "this will allow spark to do multiprocessing",
| "It makes Spark Faster",
| "Spark can be used in Scala, Python, Java, and R.",
| "Spark itsef written in Scala.")val rdd = sc.parallelize(array)
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[85] at parallelize at <console>:26scala> val maprdd = rdd.map(element => element.split(" "))
maprdd: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[86] at map at <console>:25scala> maprdd.collect()
res82: Array[Array[String]] = Array(Array(Spark, is, a, processing, Engine), Array(It, follows, lazy, loading, concept), Array(Means, transformation, functions, will, not, be, processed, until, action, called), Array(Because, of, this,, Memory, handling, can, be, done, effectively), Array(Spark, also, stored, RDD, in, multiple, partitions), Array(this, will, allow, spark, to, do, multiprocessing), Array(It, makes, Spark, Faster), Array(Spark, can, be, used, in, Scala,, Python,, Java,, and, R.), Array(Spark, itsef, written, in, Scala.))scala> val flatmaprdd = rdd.flatMap(element => element.split(" "))
flatmaprdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[87] at flatMap at <console>:25scala> flatmaprdd.collect()
res83: Array[String] = Array(Spark, is, a, processing, Engine, It, follows, lazy, loading, concept, Means, transformation, functions, will, not, be, processed, until, action, called, Because, of, this,, Memory, handling, can, be, done, effectively, Spark, also, stored, RDD, in, multiple, partitions, this, will, allow, spark, to, do, multiprocessing, It, makes, Spark, Faster, Spark, can, be, used, in, Scala,, Python,, Java,, and, R., Spark, itsef, written, in, Scala.)From the above small example, clear that Map can give only a single output on the other hand flatmap can give any number of outputs from a single input.
从上面的小示例中,可以清楚地看到Map只能提供单个输出,而平面图可以从单个输入提供任何数量的输出。
3. filter:filter function only returns the element that meets the condition given. The number of elements in the input RDD need not be equal in the output RDD when the filter function is applied.
3. filter: filter函数仅返回满足给定条件的元素。 应用过滤器功能时,输入RDD中的元素数量不必与输出RDD中的元素数量相等。
scala> val array = Array(1,2,3,4,2,6,7,2,9,10)
array: Array[Int] = Array(1, 2, 3, 4, 2, 6, 7, 2, 9, 10)scala> val rdd = sc.parallelize(array)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[92] at parallelize at <console>:26scala> val filterRDD = rdd.filter(element => element!=2)
filterRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[93] at filter at <console>:25scala> filterRDD.collect()
res87: Array[Int] = Array(1, 3, 4, 6, 7, 9, 10)4. mapPartitions:Both map and mapPartitions doing the same process, the only change is map function is iterating over all the elements of RDD, mapPartions function iterates all partitions in the RDD.
4. mapPartitions: map和mapPartitions都执行相同的过程,唯一的变化是map函数对RDD的所有元素进行迭代,mapPartions函数对RDD中的所有分区进行迭代。
scala> val mapRDD = rdd.map(element => element*100)
mapRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[101] at map at <console>:25scala> mapRDD.collect()
res94: Array[Int] = Array(100, 200, 300, 400, 200, 600, 700, 200, 900, 1000)scala> val mapRDD = rdd.mapPartitions(element => element.map(x => x*100))
mapRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[102] at mapPartitions at <console>:25scala> mapRDD.collect()
res95: Array[Int] = Array(100, 200, 300, 400, 200, 600, 700, 200, 900, 1000)We can see here that, Map function will take every element in the RDD for processing. But mapPartions iterating over partitions. So I wrote one more map function on the iterated partition to iterate over it.
我们在这里可以看到,Map函数将采用RDD中的每个元素进行处理。 但是mapPartions遍历分区。 因此,我在迭代分区上编写了另一个map函数以对其进行迭代。
mapPartitionsWithIndex is a function that does the same as mapPartitions but is also gives index value of the partitions means that map() is applied on partition index wise one after the other.
mapPartitionsWithIndex是一个与mapPartitions相同的函数,但它还提供了分区的索引值,这意味着map()一个接一个地应用于分区索引。
5. union, intersection, and distinct:union returns new RDD contains all the elements in source and argument RDDs.intersection returns common elements in both the RDDsdistinct returns the distinct elements in the RDD.
5. 并集,交集和不同:并集返回新的RDD,其中包含源RDD和自变量RDDs中的所有元素。交集返回RDDs中的公共元素。distinct返回RDD中的不同元素。
scala> val rdd1 = sc.parallelize(Array(1,2,3,4,1,2))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[122] at parallelize at <console>:24scala> val rdd2 = sc.parallelize(Array(3,4,5,6))
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[123] at parallelize at <console>:24scala> val union_rdd = rdd1.union(rdd2)
union_rdd: org.apache.spark.rdd.RDD[Int] = UnionRDD[124] at union at <console>:27scala> union_rdd.collect()
res100: Array[Int] = Array(1, 2, 3, 4, 1, 2, 3, 4, 5, 6)scala> val intersection_rdd = rdd1.intersection(rdd2)
intersection_rdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[130] at intersection at <console>:27scala> intersection_rdd.collect()
res101: Array[Int] = Array(4, 3)scala> val distinct_rdd = rdd1.distinct()
distinct_rdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[133] at distinct at <console>:25scala> distinct_rdd.collect()
res102: Array[Int] = Array(4, 1, 2, 3)These are some basic Transformation functions available in Spark. But there is much more. We can head into official doc to learn all the functions out there.
这些是Spark中可用的一些基本转换功能。 但是还有更多。 我们可以进入官方文档学习那里的所有功能。
That's all about Spark with Scala hands-on. I know there is much more. But I hope this guide will give some bottom touch. Have a great day. ta ta 😉
这就是关于Scala与动手实践的Spark的全部内容。 我知道还有更多。 但我希望本指南能给您带来些帮助。 祝你有美好的一天。 ta ta😉
翻译自: https://medium.com/swlh/apache-spark-hands-on-with-scala-83cf94dde196
学习spark scala















 2299
2299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









