





 本文介绍了sim9000a模块如何在机器人操纵领域实现从模拟到现实(sim2real)的转换,探讨了这一技术在实际应用中的关键点。
本文介绍了sim9000a模块如何在机器人操纵领域实现从模拟到现实(sim2real)的转换,探讨了这一技术在实际应用中的关键点。
sim9000a sim
This article contains details on sim2real in robotic manipulation for following tasks:
本文包含有关用于以下任务的机器人操纵中sim2real的详细信息:
- Perception for manipulation (DOPE / SD-MaskRCNN). 操纵感知(DOPE / SD-MaskRCNN)。
- Grasping (Dex-Net 3.0 / 6DOF GraspNet). 抓取(Dex-Net 3.0 / 6DOF GraspNet)。
- End-to-end policies. (Contact rich manipulation tasks & In hand manipulation of rubik’s cube) 端到端策略。 (联系丰富的操作任务和魔方的手动操作)
- Guided domain randomization techniques (ADR / Sim-Opt). 引导域随机化技术(ADR / Sim-Opt)。
现实差距: (The reality gap:)
An increasingly impressive skills have been mastered by DeepRL algorithms over the years in simulation (DQN / AlphaGo / OpenAI Five). Both Deep learning and RL algorithms require super huge amounts of data. Moreover, RL algorithms there is risk to the environment or to the robot during the exploration phase. Simulation offers the promise of huge amounts of data (can be run in parallel and much faster than real time with minimal cost) and doesn’t break your robot during exploration. But these policies trained entirely in simulation fails to generalize on real robot. This gap between impressive performance in simulation and poor performance is known as the reality gap.
多年来,DeepRL算法已在模拟( DQN / AlphaGo / OpenAI Five )中掌握了越来越多的令人印象深刻的技能。 深度学习算法和RL算法都需要大量数据。 此外,RL算法在探索阶段会对环境或机器人造成风险。 仿真提供了海量数据的承诺(可以并行运行,并且比实时运行要快得多,而且成本最低),并且不会在探索过程中破坏您的机器人。 但是,这些完全在模拟中训练的策略无法推广到真实的机器人上。 仿真中令人印象深刻的性能与性能不佳之间的差距被称为现实差距。
Some of the ways to bridge the reality gap are:
弥合现实差距的一些方法是:
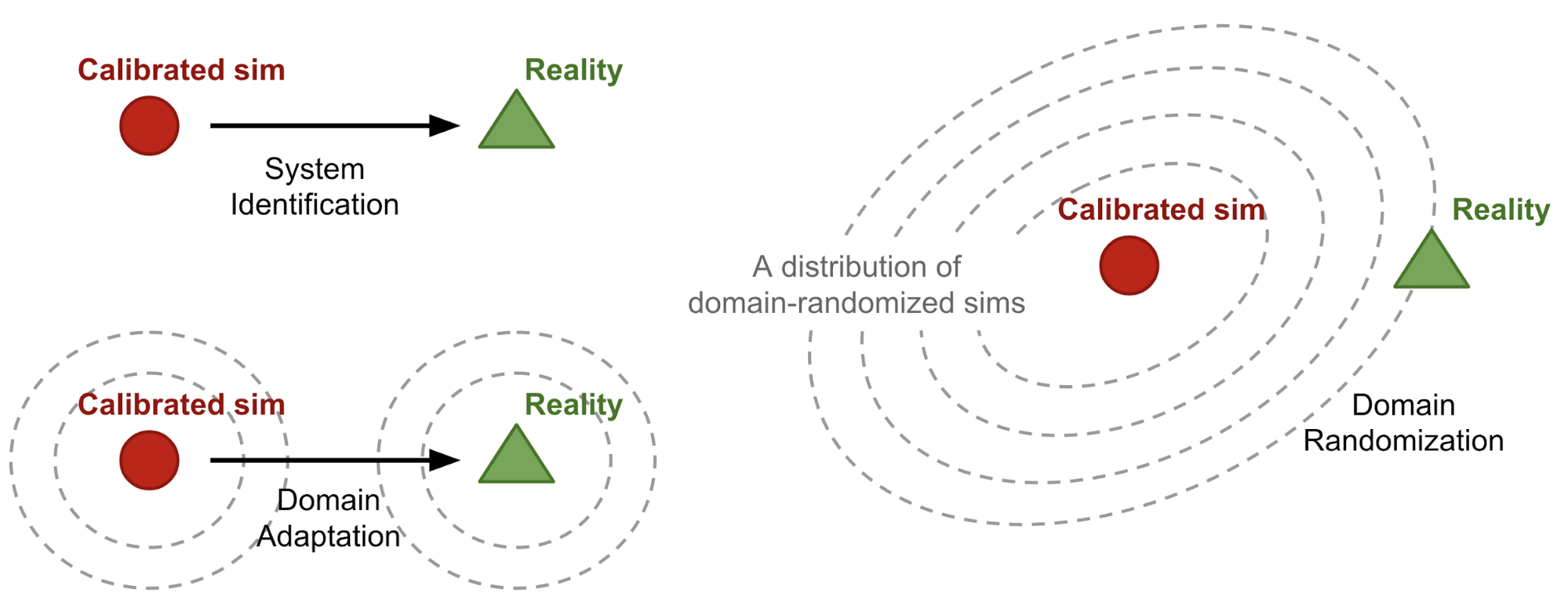
System Identification: Identify exact physical / geometrical / visual parameters of environment relevant to task and model it in simulation.
系统识别:识别与任务相关的环境的确切物理/几何/视觉参数,并在仿真中对其建模。
Domain Adaptation: Transfer learning techniques for transferring / fine-tuning the policies trained in simulation in reality.
领域适应:转移学习技术,用于转移/微调实际仿真中训练的策略。
Domain Randomization: Randomize the simulations to cover reality as one of the variations.
域随机化:将模拟随机化以将现实作为变体之一。
We’ll mainly be focussing on domain randomization techniques and their extension used in some of the recent and successful sim2real transfers in robotic manipulation.
我们将主要关注域随机化技术及其在机器人操纵中最近成功使用的sim2real传输中使用的扩展。
域随机化 (Domain Randomization)
Formally domain randomization is defined as:
正式的域随机化定义为:
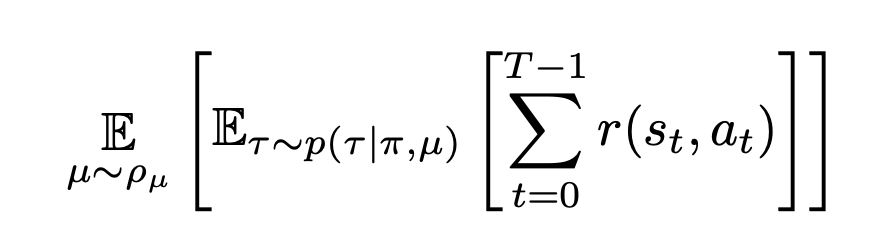
So effectively, domain randomization is trying to find a common policy π parameters that work across a wide range of randomized simulations P_{mu}. So the hope is that the policy that works across wide range of randomizations also works in the real world, assuming that the real world is just another randomization covered by randomization.
如此有效地,域随机化试图找到可在广泛的随机模拟P_ {mu}中工作的通用策略π参数。 因此,希望现实世界中的政策也可以在现实世界中工作,假设现实世界只是随机化所涵盖的另一个随机化。
Based on how these simulation randomization are chosen we have 2 types:
根据如何选择这些模拟随机化,我们有两种类型:
Domain randomization: Fixed randomization distributions over a range often chosen by hand. We will see how this has been used in perception & grasping tasks for data efficiency.
域随机化:通常在手动选择的范围内的固定随机化分布。 我们将看到如何将其用于感知和掌握任务以提高数据效率。
Guided domain randomization: Either simulation or real world experiments can be used to change the randomization distribution. We will see how this has been used in training end2end policies for contact rich and dexterous tasks. Some of the guided domain randomizations do appear like domain adaptation.
引导域随机化:可以使用仿真或真实世界的实验来更改随机化分布。 我们将看到如何在训练端到端策略中使用它来处理丰富而灵巧的联系人任务。 某些引导域随机化确实看起来像域适应。
域随机化: (Domain randomization:)
Some of the early examples of using domain randomizations was used for object localization on primitive shapes[2] and table top pushing[3]. We will look at examples of more advanced tasks such as segmentation and pose estimation with emphasis on what randomizations were chosen and how good are the transfer performance.
使用域随机化的一些早期示例被用于原始形状[2]和桌面推入[3]上的对象定位。 我们将看一些更高级的任务示例,例如分段和姿势估计,重点是选择了哪些随机化以及传输性能如何。
Domain Randomization in Perception:
感知领域随机化:
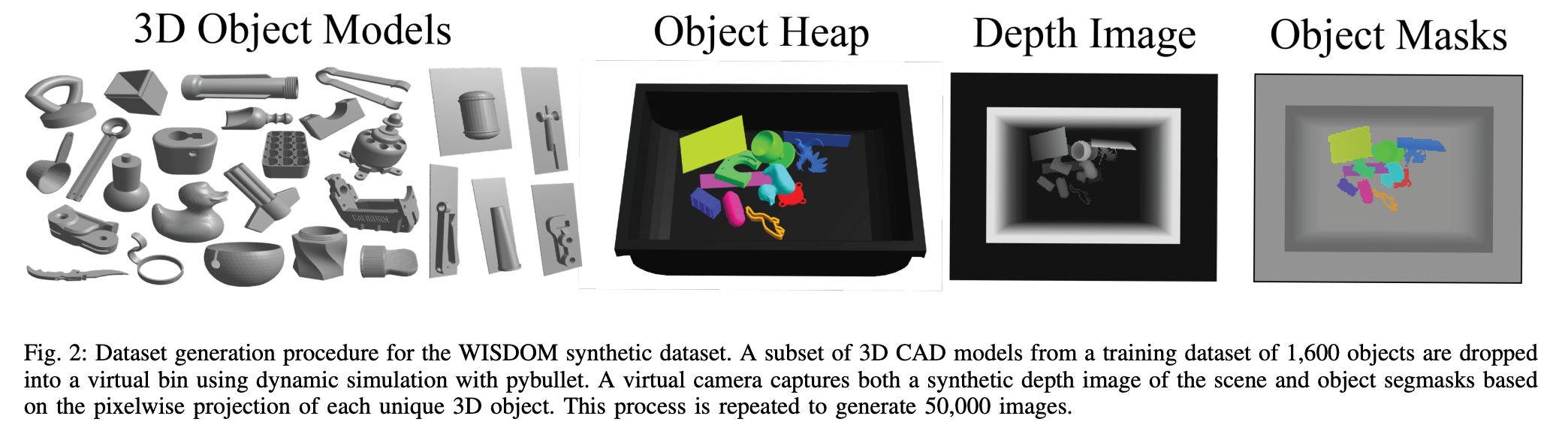
SD Mask R-CNN: SD (Synthetic Data) Mask R-CNN trains category agnostic instance segmentation entirely based on synthetic dataset with performance superior to that fine-tuned from COCO-dataset.
SD Mask R-CNN: SD(合成数据)Mask R-CNN完全基于合成数据集训练类别不可知实例分割,其性能优于从COCO数据集进行微调的性能。
Simulator: pybullet
模拟器: pybullet
Randomizations: Since this network uses depth images as inputs, the randomizations needed are quite minimal ( depth realistic images are easy to generate compared to photo realistic).
随机化:由于此网络使用深度图像作为输入,因此所需的随机化非常小(与照片真实感相比,深度真实感图像易于生成)。
- Sample a number n ∈ p(λ = 5) of objects and drop it in the bin using dynamic simulation. This will sample different objects and different object poses. 对数量为n∈p(λ= 5)的对象进行采样,然后使用动态模拟将其放入垃圾箱。 这将采样不同的对象和不同的对象姿势。
- Sample camera intrinsics K and camera extrinsic (R, t) ∈ SE(3) within a neighborhood of real camera intrinsics and extrinsic setup. 在真实的相机内部特性和外部设置附近,对相机内部特性K和相机外部(R,t)∈SE(3)进行采样。
- Render both the depth image D and foreground object masks M. 渲染深度图像D和前景对象蒙版M。
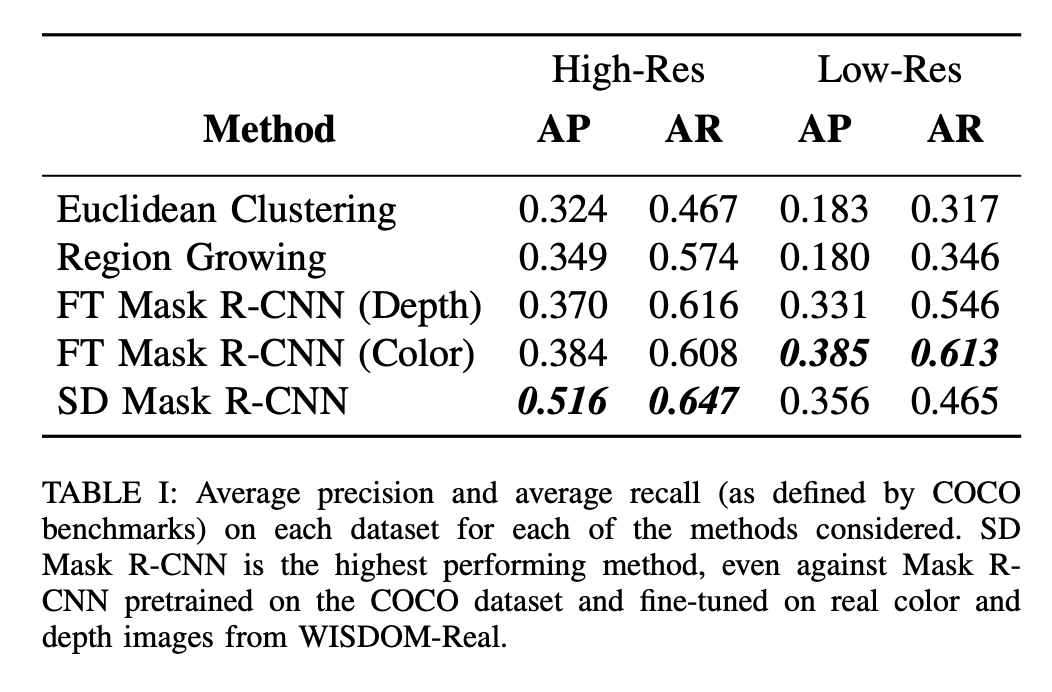
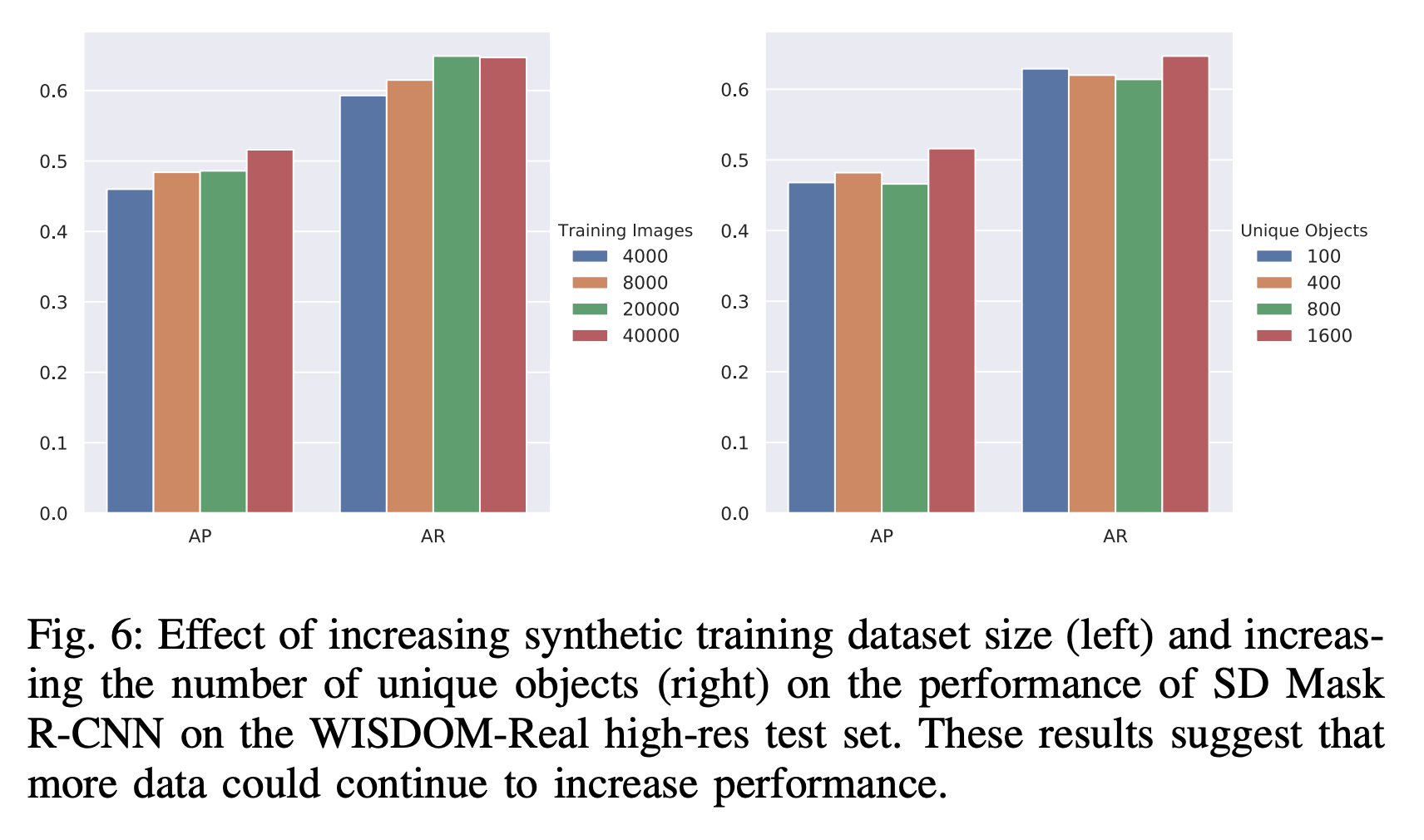
The Mask-RCNN trained on instance segmentation entirely on synthetic data (SD-Mask R-CNN) is compared against a couple of baseline segmentation methods and Mask R-CNN trained on COCO dataset & fine-tined (FT Mask R-CNN) on WISDOM-real-train. The test set WISDOM-real-test used here is the real world dataset collected using a high-res and low-res depth cameras and hand labelled segmentation masks.
将完全在合成数据上进行实例分割训练的Mask-RCNN(SD-Mask R-CNN)与几种基准线分割方法进行了比较,在COCO数据集上经过训练的Mask R-CNN进行了精细细分(FT Mask R-CNN) WISDOM真实火车。 这里使用的测试集WISDOM-real-test是使用高分辨率和低分辨率深度相机以及手工标记的分割蒙版收集的真实世界数据集。
From the ablation study, both metrics go up as number of synthetic data samples are increased indicating more data could help the improve the performance. However, increasing the number of unique objects has mixed results (may be due limited number of objects in WISDOM-real-test).
根据消融研究,随着合成数据样本数量的增加,这两个指标均上升,表明更多数据可以帮助改善性能。 但是,增加唯一对象的数量会产生不同的结果(可能是由于WISDOM真实测试中的对象数量有限)。
Some qualitative comparison of segmentation results from SD Mask R-CNN
SD Mask R-CNN分割结果的定性比较

DOPE (Deep Object Pose Estimation): DOPE solves the problem of pose estimation of YCB objects entirely using synthetic dataset that contain domain randomized and photorealistic RGB images.
DOPE(深对象姿势估计): DOPE完全使用包含域随机化和逼真的RGB图像的合成数据集解决了YCB对象的姿势估计问题。

Simulator: UE4 with NDDS Plugin.
模拟器: 带有NDDS插件的UE4。
Domain Randomizations:
域随机化:
- Number of / types / 3D poses / textures on distractor objects of primitive 3D shapes. 基本3D形状的干扰对象上的/类型/ 3D姿势/纹理的数量。
- Numbers / textures / 3D poses of objects of interest from YCB objects set. YCB对象集中感兴趣对象的数字/纹理/ 3D姿势。
- Uniform / textured or images from COCO as background images. 均匀/纹理或可可的图像作为背景图像。
- Directional lights with random orientation and intensity. 具有随机方向和强度的定向灯。
Photorealistic:
真实感:
- Falling YCB objects in photo realistic scenes from standard UE4 virtual environments. These scenes are captured with different camera poses. 从标准UE4虚拟环境中的逼真的场景中掉落的YCB对象。 这些场景是用不同的相机姿势捕获的。
Notice that camera intrinsics randomization wasn’t necessary here since the method regresses heat-maps of 3D box and vector fields to the centroid. It uses these predicted 2D information / camera intrinsics (explicitly) / object sizes to predict the 3D pose.
请注意,此处不需要相机固有的随机化,因为该方法会将3D框的热图和矢量场回归到质心。 它使用这些预测的2D信息/(显式地)相机固有函数/对象大小来预测3D姿势。
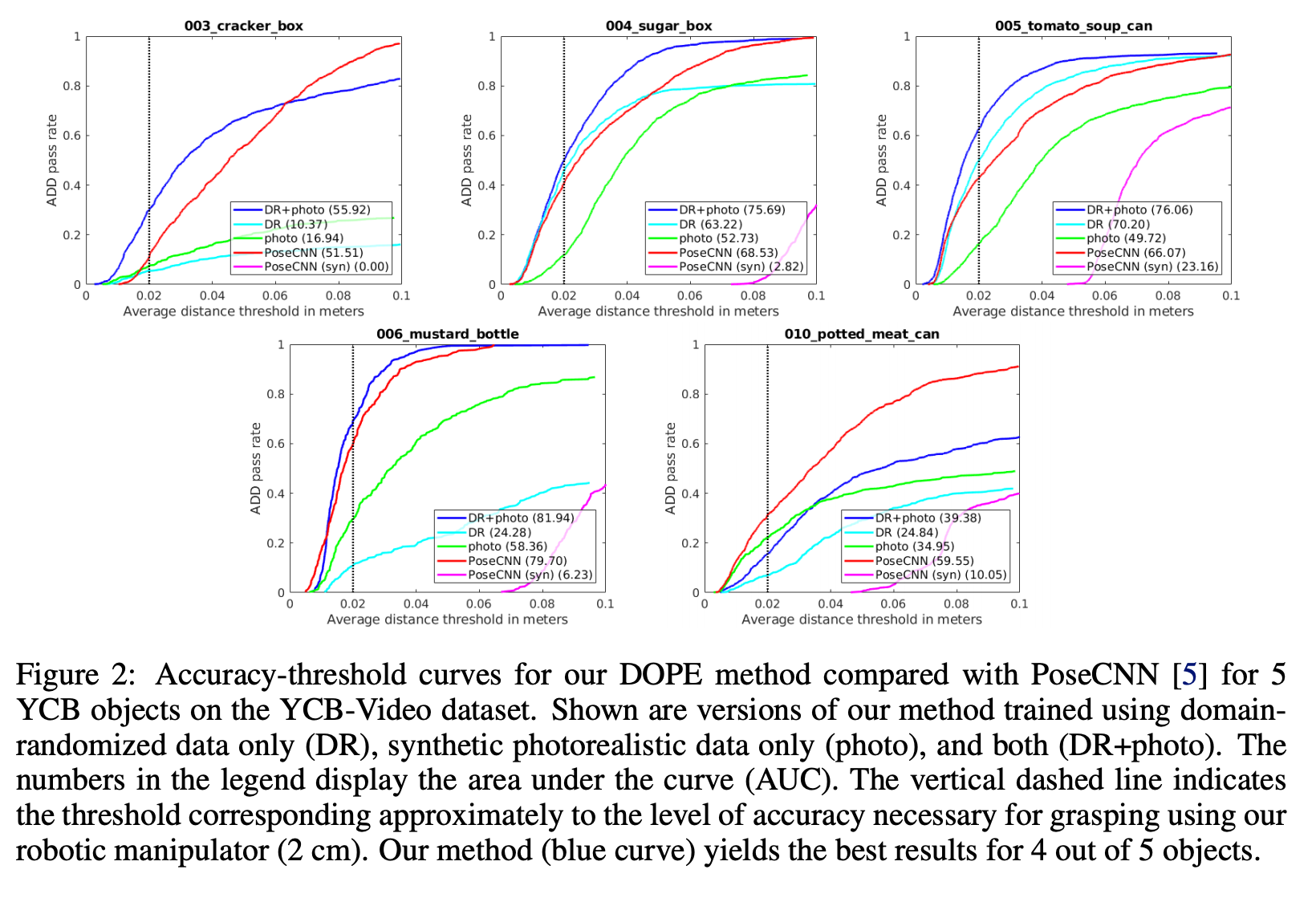
ADD (Average distance of 3D points on bounding boxes) pass rate vs distance threshold plots below measures successful pose detection within that threshold (higher is better). Notice how both DR and photorealistic images were necessary to get comparable performance to method trained on real world data (PoseCNN).
下方的ADD(边界框上3D点的平均距离)通过率与距离阈值的关系图衡量了该阈值内成功进行姿势检测的程度(越高越好)。 请注意,要获得与在现实世界数据上训练的方法(PoseCNN)相当的性能,DR和真实感图像都是必需的。
Some qualitative comparisons of DOPE with PoseCNN (real data) is shown below. Notice how DOPE produces tighter boxes and more robust to lighting conditions.
下面显示了DOPE与PoseCNN(真实数据)的一些定性比较。 注意DOPE如何生产更紧凑的盒子,并在光照条件下更坚固。

Domain Randomization in Grasping:
把握领域随机化:
Let’s look at some examples of domain randomizations applied to robotic grasping (both suction based and parallel jaw grasps) with emphasis on what aspects are randomized and their transfer success to real robot grasping.
让我们看一下应用于机器人抓握(基于吸力和平行下颌抓握)的领域随机化的一些示例,重点放在随机化哪些方面以及它们成功转移到实际机器人抓握上。
Dex-Net 3.0:
Dex-Net 3.0:
Suction GQ(Grasp Quality)-CNN takes in a depth image patch centered at suction point and outputs a quality measure. The process of generating the quality measure labels is illustrated below:
GQ(抓取质量)-CNN吸取以吸点为中心的深度图像块,并输出质量度量。 生成质量度量标签的过程如下所示:
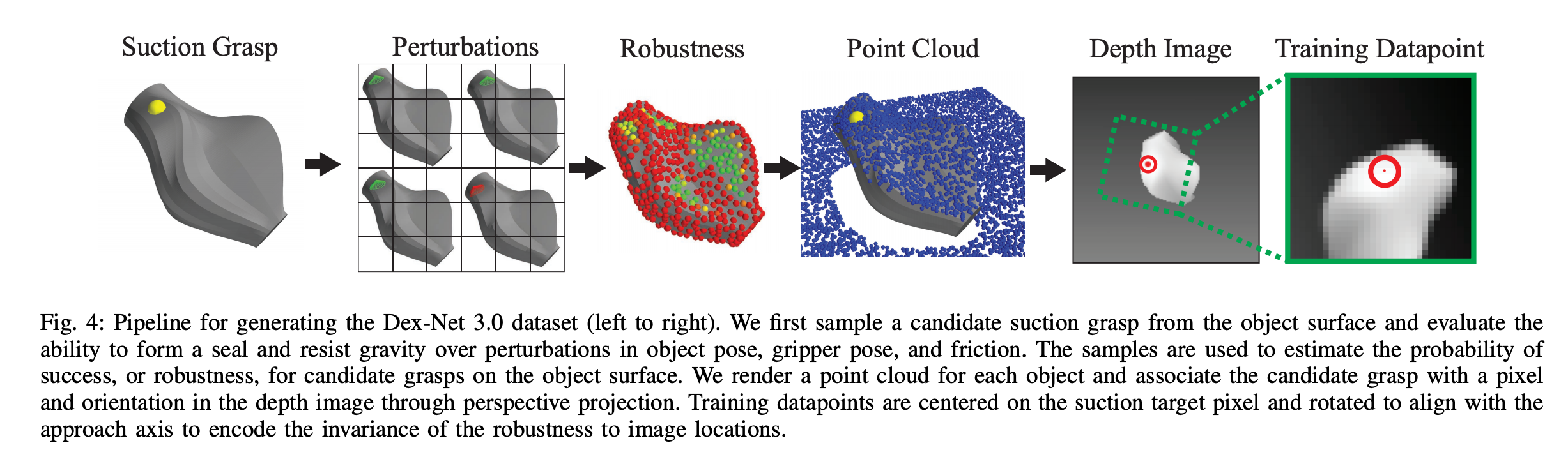
Here are examples of few more labels generated with grasp robustness annotated 3D models:
以下是使用抓地力标注的3D模型生成的一些其他标签的示例:

Simulator: Custom quasi-static physics model that simulates seal formation and ability to resist gravity and random external wrenches.
模拟器:定制的准静态物理模型,可模拟密封的形成以及抵抗重力和随机外力扳手的能力。
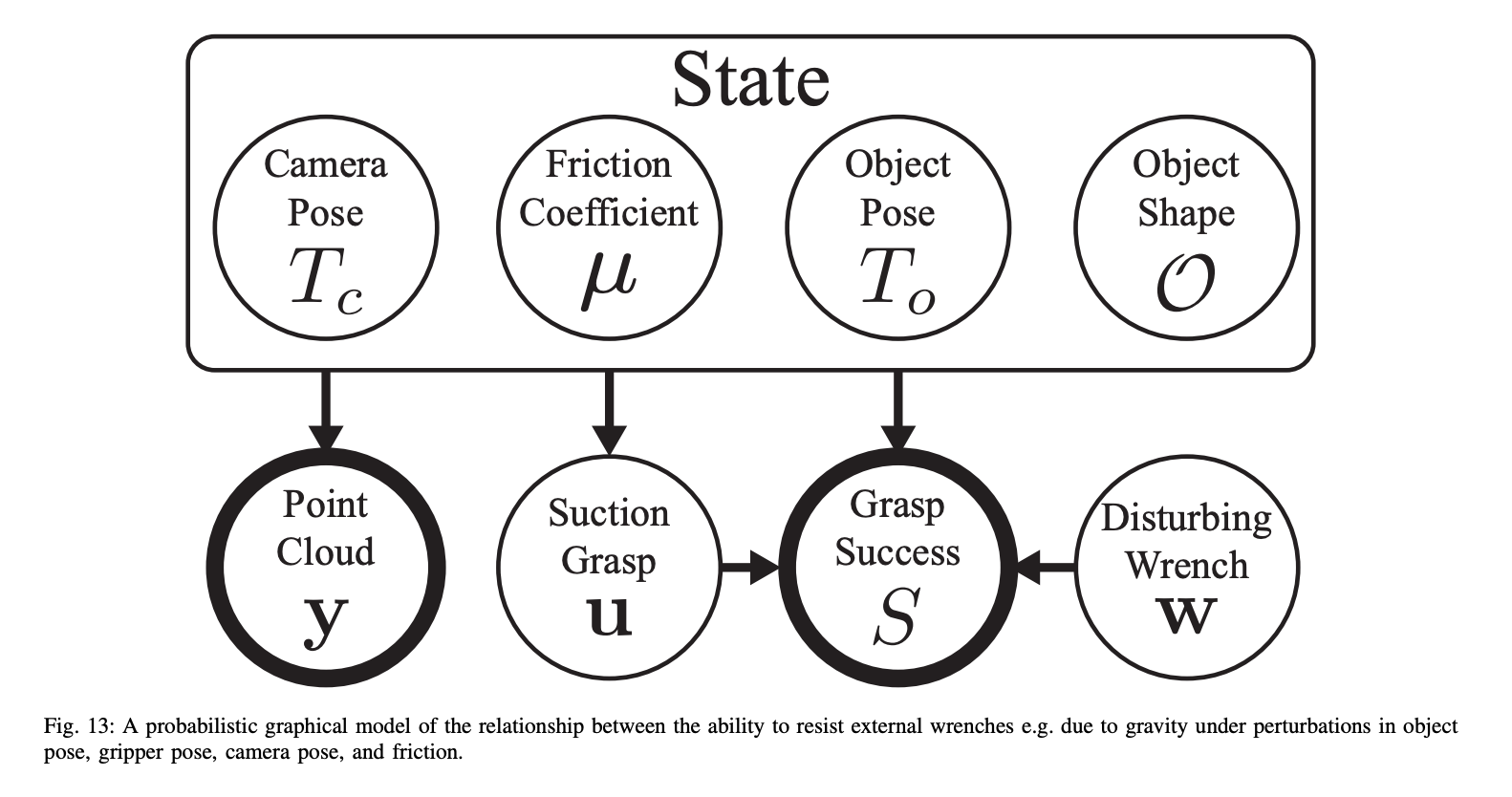
Randomizations: The graphical model shows the randomization parameters used in Dex-Net 3.0
随机化:图形模型显示了Dex-Net 3.0中使用的随机化参数
Here are the randomizations explicitly listed:
以下是明确列出的随机化:
- Sample a 3D object O uniformly from training set. 从训练集中均匀采样3D对象O。
- Sample a resting pose T_s and sample planar disturbance from U([-0.1, 0.1], [-1.0, 1.0], [0, 2π)) and apply the planar disturbance (x, y, θ) to T_s to obtain object pose T_o 采样一个静止姿态T_s并从U([-0.1,0.1],[-1.0,1.0],[0,2π))采样平面扰动并将平面扰动(x,y,θ)应用于T_s以获取目标姿态至
- μ coefficient of friction is sampled from N_+(0.5, 0.1) μ摩擦系数从N _ +(0.5,0.1)采样
- Camera pose T_c is sampled in spherical coordinates (r, θ, ϕ) ∈ U([0.5, 0.7], (0, 2π, 0.01π, 0.1π)) where the camera optical axis intersections the table. 在相机光轴与工作台相交的球坐标(r,θ,ϕ)∈U([0.5,0.7],(0,2π,0.01π,0.1π))中对相机姿态T_c进行采样。
- Suction grasps are uniformly sampled on object 3D mesh surface. 抽吸抓取均匀地采样在对象3D网格表面上。
For each such sampled grasp, the wrench resistance metric is computed and the point cloud for the 3D object mesh is rendered using sampled camera pose and known camera intrinsic.
对于每个这样的采样抓握,将计算扳手阻力度量,并使用采样的摄像头姿态和已知的摄像头本征来渲染3D对象网格的点云。
Zero shot transfer of policy (CEM) that optimizes the samples according to suction GQ-CNN is shown in video below:
以下视频显示了根据吸力GQ-CNN优化样本的零策略转移(CEM)。
6DOF GraspNet:
6DOF GraspNet:
The GraspNet framework has 2 components both of which take the point cloud corresponding to target object:
GraspNet框架具有2个组件,这两个组件均采用与目标对象相对应的点云:
- VAE (Variational Auto-Encoder) predicts 6-DOF grasp samples that has high coverage on the target object. VAE(可变自动编码器)可预测对目标对象具有高覆盖率的6自由度抓取样本。
- Grasp evaluator that takes 6-DOF grasp sample in addition to point cloud produced quality scores. Which is later used for refining the grasp sampled via VAE. 除点云外,还采用6自由度抓样的抓紧评估器可产生质量得分。 后来用于完善通过VAE采样的抓地力。
The gradient on the grasp evaluator can be used to further refine the sampled grasps.
抓地力评估器上的梯度可用于进一步完善采样的抓地力。
Training both networks require positive grasp labels, which are generated entirely in simulation.
训练两个网络都需要积极的抓地力标签,这些标签完全在模拟中生成。
Simulator: NVIDIA FleX simulator.
模拟器: NVIDIA FleX模拟器。
Synthetic grasp data generation:
综合掌握数据生成:
- An object is sampled from a subset of ShapeNet. 从ShapeNet的子集中采样一个对象。
- An approach based sampling scheme is used for generating grasp samples. Samples that are not in collision and non-zero object volume are selected for simulation. 基于方法的采样方案用于生成抓取样本。 选择非碰撞且对象体积非零的样本进行仿真。
- Object mesh and gripper in the sampled pose are loaded in simulation. Surface friction and object density are kept constant (No randomizations ! really ?). The gripper is closed and a predefined shaking motion is executed. Grasps that keep the object between the grippers are marked as positive grasps. 在仿真中加载采样姿势中的对象网格和抓手。 表面摩擦力和物体密度保持恒定(无随机! 抓具闭合,并执行预定义的摇动动作。 将物体保持在抓具之间的抓握标记为肯定抓握。
- Hard negative grasps are generated in neighborhood of positive grasps that are either in collision with gripper or zero object volume between grippers. 在与抓取器发生碰撞或抓取器之间的物体体积为零的正面抓取附近产生硬的负面抓取。
The visualization of the grasp data generation:
掌握数据生成的可视化:

Some of the positive grasp samples on bowls and boxes are shown below:
碗和盒子上的一些正面抓取样本如下所示:

The performance of 6-DOF GraspNet on previously unseen YCB objects:
6自由度GraspNet在以前看不见的YCB对象上的性能:
引导域随机化: (Guided domain randomization:)
Previously, we saw several examples of randomized simulations that lead to successful transfer to real robotic tasks. These randomizations were chosen carefully around the nominal real world values and often tuned for real world transfer. This either becomes tedious when there are large number of parameters to choose for and very wide randomizations often leads to infeasible / sub-optimal solutions in simulations. We will look at two strategies for automating this:
以前,我们看到了一些随机模拟的示例,这些示例可以成功地转移到实际的机器人任务上。 这些随机化是在名义上的真实世界值周围仔细选择的,并且经常针对真实世界的传输进行调整。 当有大量参数可供选择时,这要么变得很乏味,而且非常宽的随机化常常导致模拟中不可行/次优的解决方案。 我们将看一下两种自动化的策略:
- Automatic domain randomization in the context of solving Rubik’s code. 在解决Rubik代码的情况下自动进行域随机化。
- Sim-Opt in the context of contact rich manipulation tasks which uses real world rollouts of policy. Sim-Opt是在接触丰富的操纵任务的背景下使用实际策略发布的。
Automatic Domain Randomization (ADR):
自动域随机化(ADR):
Let’s take a brief look at the overall framework used for Rubik’s cube solving before delving into ADR algorithm. Here is a nice overview of the entire framework:
在深入研究ADR算法之前,让我们简要介绍一下用于Rubik多维数据集解决的总体框架。 这是整个框架的不错概述:
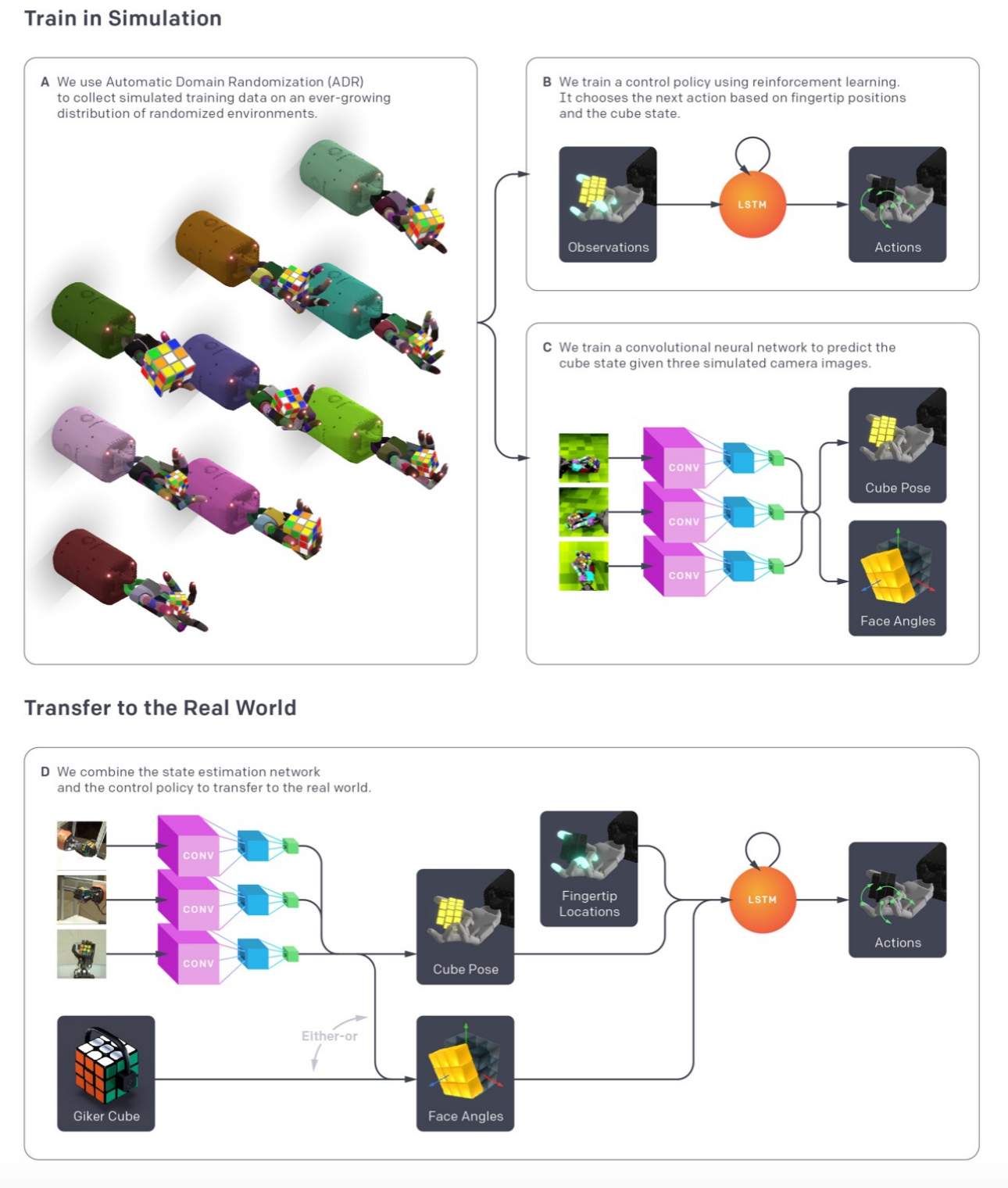
Although, the vision part of network is also trained entirely in simulation with ADR , let’s focus on hard controller policy part that manipulates the Rubik’s cube. Note that optimal sequence of rotations of Rubik’s cube faces are solved by Kociemba’s algorithm
虽然,网络的视觉部分也已经使用ADR在模拟中进行了全面培训,但我们还是将重点放在操纵Rubik立方体的硬控制器策略部分上。 注意,魔方表面的最佳旋转顺序由Kociemba算法求解
The task of solving the Rubik’s cube now reduces to the problem of successfully executing face rotations and flip actions to make sure the face to be rotated is on top.
解决魔方的任务现在减少了成功执行面部旋转和翻转动作以确保要旋转的面部在顶部的问题。
The shadow robotic hand is used for performing the flip and rotations on the Rubik’s cube. Here are the details of inputs and outputs of the policy network and reward functions.
阴影机械手用于在Rubik立方体上执行翻转和旋转。 以下是政策网络和奖励功能的输入和输出的详细信息。
Inputs: Observed fingertip positions, observed cube pose, goal cube pose, noisy relative cube orientations, goal face angles, noisy relative cube face angles.
输入:观察到的指尖位置,观察到的立方体姿势,目标立方体姿势,嘈杂的相对立方体方位,目标面部角度,嘈杂的相对立方体角度。
Outputs: shadow hand has 20 joints that can be actuated, and the policy outputs a discretized actions space of 11 bins per joint.
输出:影子手有20个可以激活的关节,并且该策略输出每个关节11个bin的离散操作空间。
Reward function: Combination of:
奖励功能:组合:
- Distance between present cube state to goal state. 当前立方体状态与目标状态之间的距离。
- Additional reward for achieving the goal. 实现目标的额外奖励。
- Penalty for dropping the cube. 丢下立方体的罚款。
Also, episodes are terminated based on 50 consecutive successes / dropping the cube or time out while trying to achieve the goal.
此外,情节会基于连续50次成功/终止多维数据集或尝试达到目标的超时而终止。
Simulator: MuJoCo
模拟器: MuJoCo
Also, a lot of effort has been put into simulating the details of Rubik’s cube dynamics and Shadow robot hand.
同样,在模拟Rubik立方体动力学和Shadow机器人手的细节方面也付出了很多努力。

ADR Algorithm:
ADR算法:
Compared to naive domain randomization:
与朴素域随机化相比:
Curriculum learning: ADR gradually increases the task difficult leading easier policy converge.
课程学习: ADR逐渐增加了任务难度,导致政策更容易收敛。
Automatic: Removes the need for manual tuning of parameters, that could be non-intuitive for large parameter set.
自动:无需手动调整参数,这对于大型参数集可能是不直观的。
Randomizations:
随机化:
- Simulator physics parameters such as friction between cube, robot hand, cube size, parameters of the hand model etc. 仿真器物理参数,例如立方体,机器人手,立方体大小,手模型参数等之间的摩擦。
- Custom physics parameters such as action latency, time step variance. 自定义物理参数,例如动作延迟,时间步长变化。
- Observation noise to cube poses, finger positions at episode level as well as each step level. 立方体姿势,情节级别以及每个步骤级别的手指位置的观察噪声。
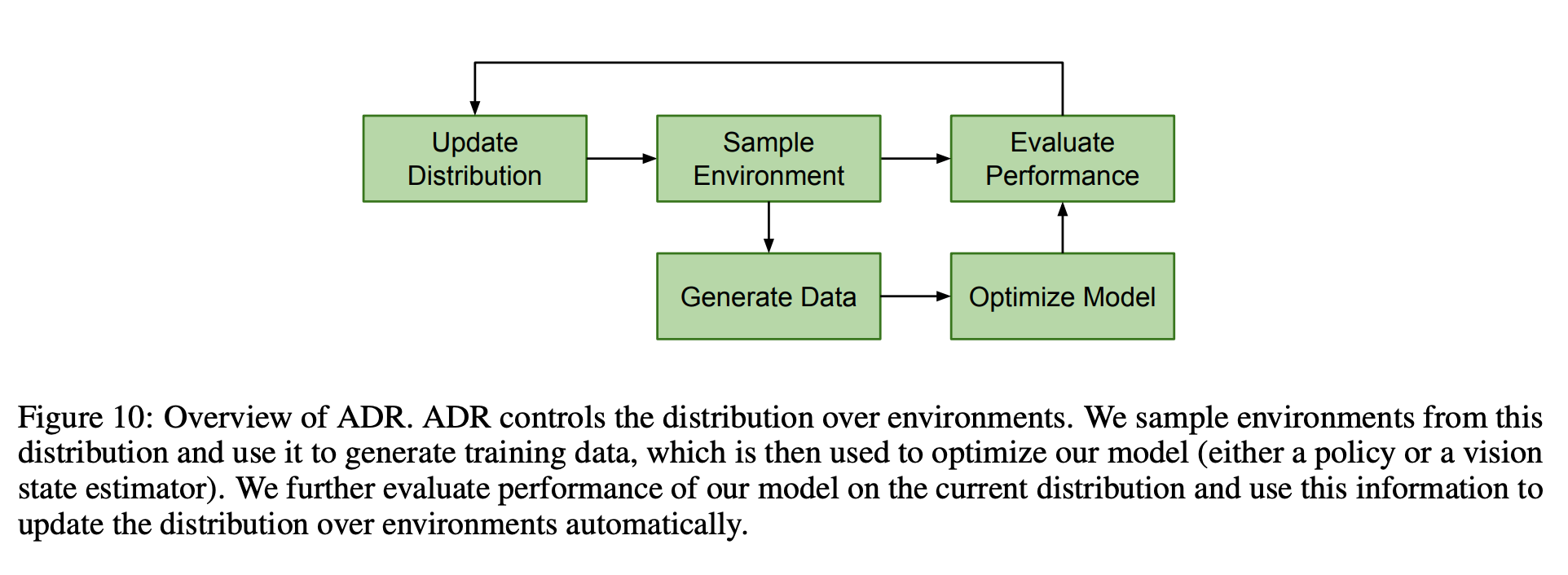
All simulation parameters are sampled from uniform distribution over a range (ϕ_L, ϕ_H). Thus is distribution of simulator parameters for d parameters is given by:
所有模拟参数均取自一定范围(ϕ_L,ϕ_H)内的均匀分布。 因此, d参数的仿真器参数分布由下式给出:
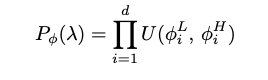
And entropy is used for measuring the complexity of training distribution, which for product of uniform distribution is:
熵用于测量训练分布的复杂度,对于均匀分布的乘积为:
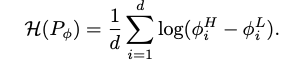
Task performance (i.e number of success in a given episode) thresholds (t_L, t_H) is used to adjust the parameters ϕ. ADR starts with a single simulation parameter value. At each iteration, one of the boundary (ϕ_L or ϕ_H) value of one of the randomization parameter ϕ_i is chosen and the performance is evaluated and added to a buffer (D_L or D_H). After the buffer is of adequate size, depending on whether the overall performance is above t_H or below t_L, ϕ_i range is increased or ϕ_i range is decreased respectively.
任务执行(即在给定情节中成功的次数)阈值(t_L,t_H)用于调整参数ϕ。 ADR从单个模拟参数值开始。 在每次迭代中,选择随机参数parameter_i之一的边界值(ϕ_L或ϕ_H)之一,并评估性能并将其添加到缓冲区(D_L或D_H)。 在缓冲区具有足够的大小之后,根据总体性能是高于t_H还是低于t_L,分别增大ϕ_i范围或减小ϕ_i范围。

Sim2Sim: The benefit of curricular learning was studied in the context of Sim2sim transfer of bringing the cube to goal orientation. The test set is previously hand tuned domain randomization scheme which was never presented to ADR. As can be seen, as the entropy of domain randomization goes up, as does the performance on the test simulation environment.
Sim2Sim:在Sim2sim转移的背景下研究了课程学习的好处,即将多维数据集置于目标方向。 测试集以前是手工调整的域随机化方案,从未提供给ADR。 可以看出,随着域随机化熵的增加,测试仿真环境的性能也随之提高。
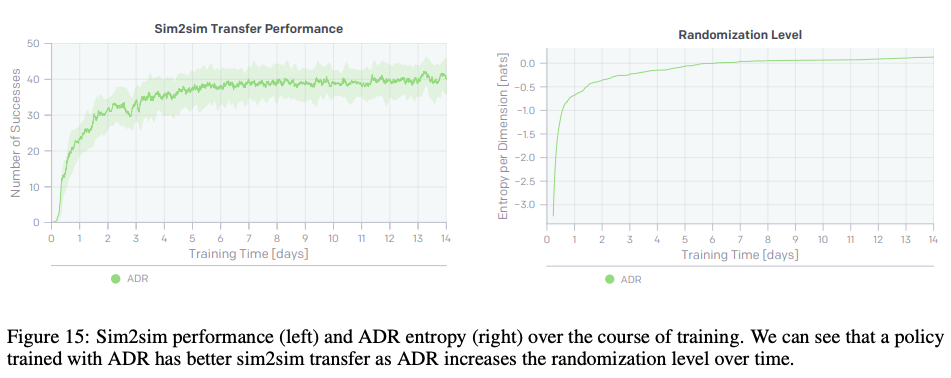
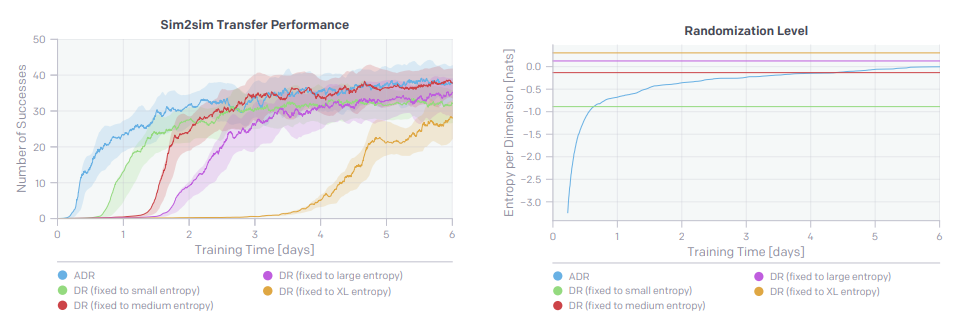
ADR is compared against several fixed randomization schemes that were reached via curriculum training, as can be seen ADR reaches higher performance quickly and asymptotically similar.
将ADR与通过课程培训达到的几种固定随机方案进行比较,可以看出ADR快速且渐近地达到了更高的性能。
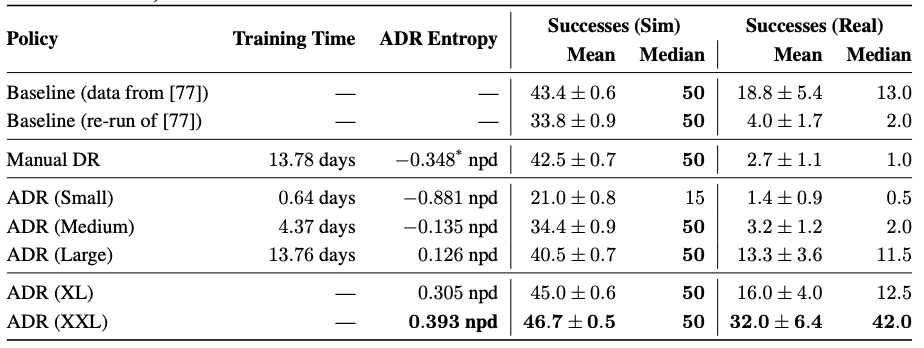
Sim2Real: The table below shows performance of ADR trained policy in Sim and in Real for different amounts of training. Notice how the entropy of P_ϕ keeps growing as the training progresses.
Sim2Real:下表显示了在不同的培训量下,ADR培训策略在Sim和Real中的性能。 注意,随着训练的进行,P_ϕ的熵如何保持增长。
Here is a successful execution of solving the Rubik’s cube from a random shuffle:
这是从随机混洗中成功解决魔方的成功执行:
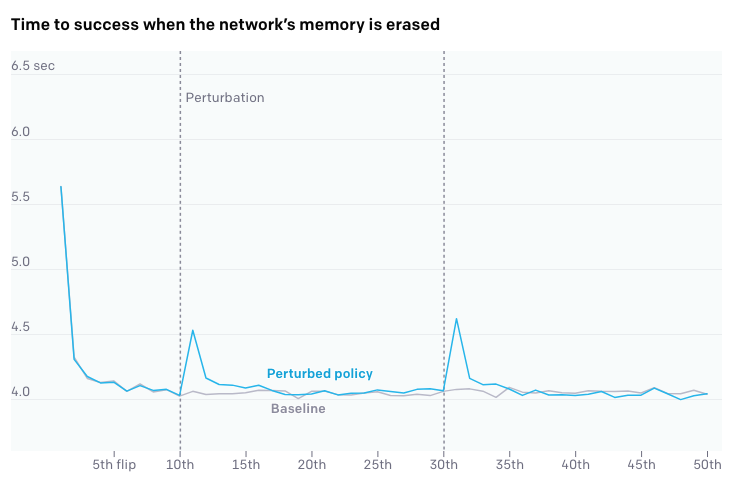
Meta-learning perspective: Because the LSTM policy doesn’t have enough capacity to remember all the variations of dynamics, it learns to adapt the policy to particular instantiations of dynamics during execution (i.e online system identification).
元学习观点:由于LSTM策略没有足够的能力来记住动态的所有变化,因此它学会了在执行过程中(例如在线系统识别)使策略适应动态的特定实例。
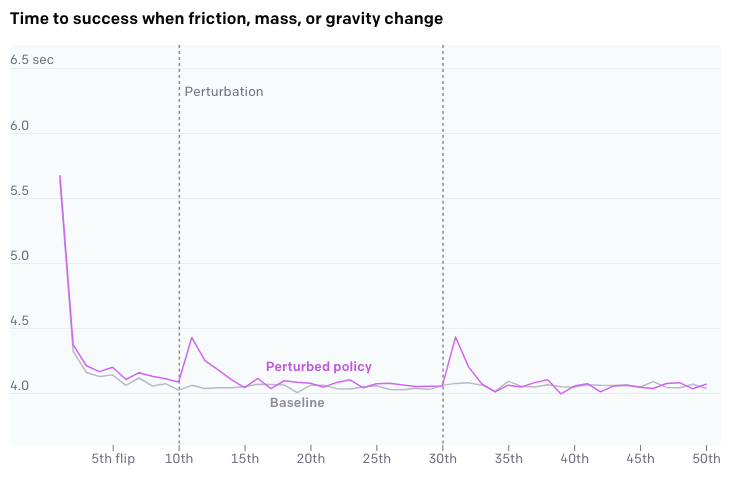
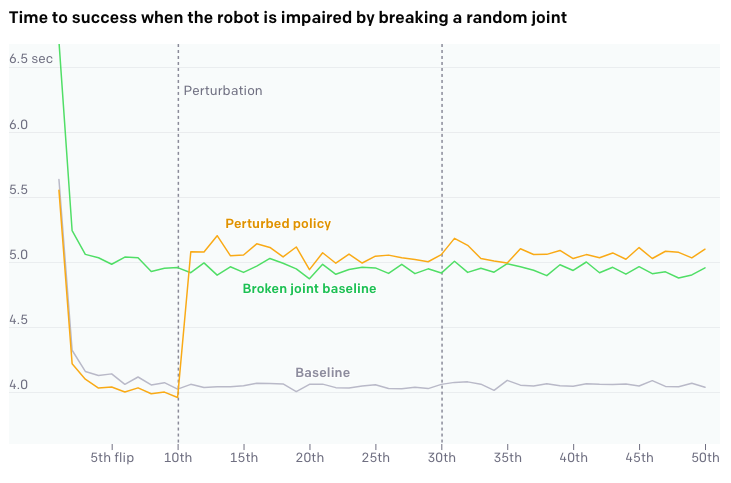
This is studied by perturbing the memory of LSTM / changing the dynamics on the fly or restraining a random joint. As can be seen each of the perturbations, the amount of time needed to complete the sub-goal suddenly goes up as the perturbation is introduced and after several executions the policy calibrates itself to new dynamics and the performance returns to it’s corresponding baseline.
这是通过扰动LSTM的内存/动态更改动力学或限制随机关节来研究的。 可以看出,每个扰动都会随着引入扰动而增加完成子目标所需的时间,并且在执行几次之后,策略会根据新的动态进行自我校准,性能会返回到其相应的基准。
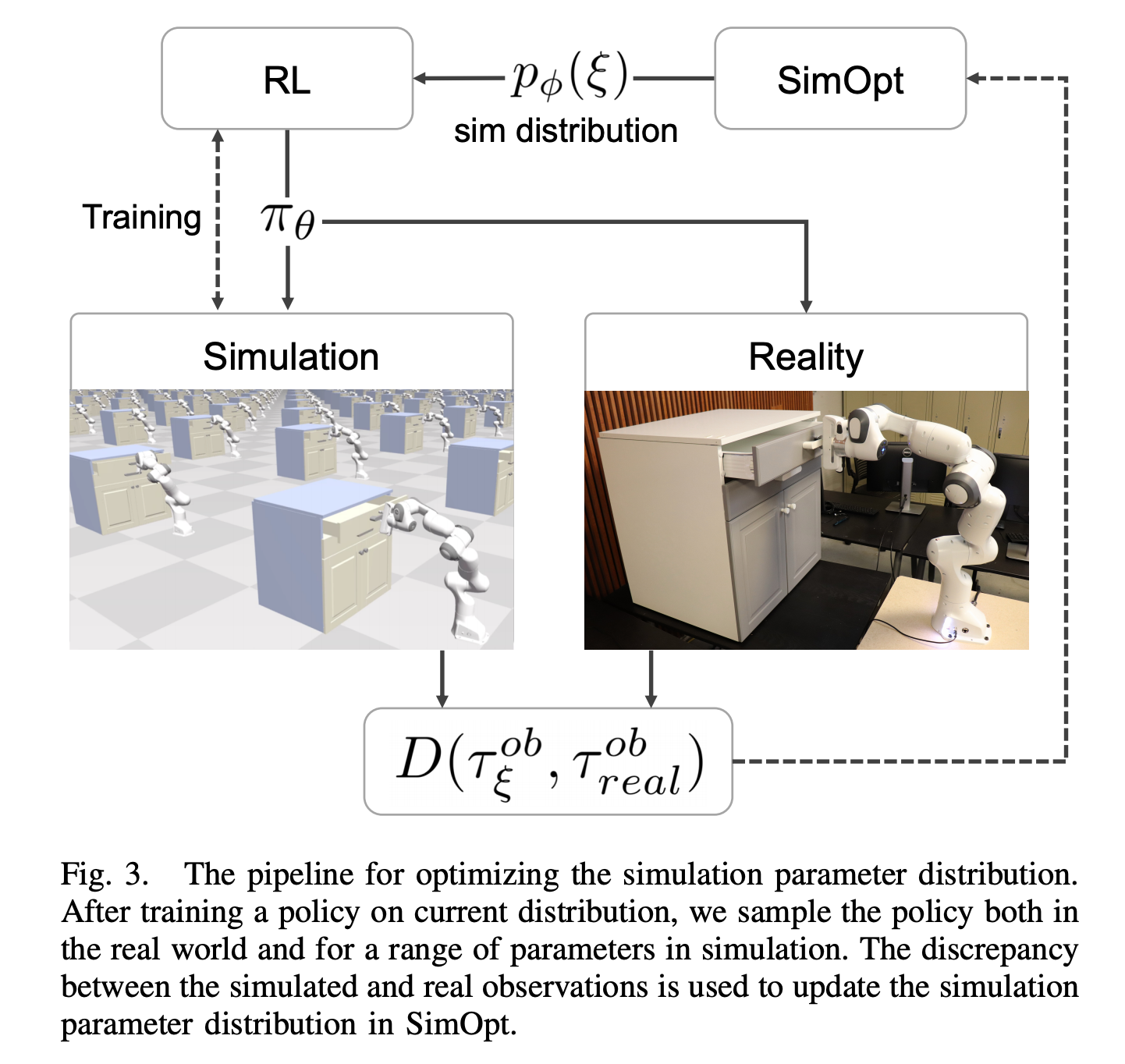
Sim-Opt: (Sim-Opt:)
Sim-opt framework is trying to find parameters of simulation distribution that makes discrepancy between observed trajectory in simulation vs in real world by executing the trained policy.
Sim-opt框架试图通过执行训练有素的策略来查找模拟分布的参数,从而使模拟的轨迹与实际的轨迹之间存在差异。
It showcases the approach with two real world robotic tasks on two separate robotic hands:
它通过在两个单独的机器人手上执行两个现实世界的机器人任务来展示该方法:
- Drawer opening with Franka Emika Panda. 抽屉与Franka Emika Panda一起开幕。
- Swing peg in hole task with ABB YuMi. 与ABB YuMi一起进行洞洞作业。

Here is the overview of SimOpt framework:
这是SimOpt框架的概述:
Just to recap domain randomization tries to find θ (the policy parameters) such that the same policy generalizes across several randomizations ξ ∈ P_ϕ of simulator dynamics.
概括地说,域随机化试图找到θ(策略参数),以使同一策略在模拟器动力学的多个随机化ξ∈P_ϕ中泛化。
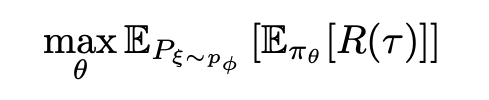
SimOpt tries to minimize the following objective w.r.t simulator parameters ϕ
SimOpt尝试最小化以下客观wrt模拟器参数ϕ
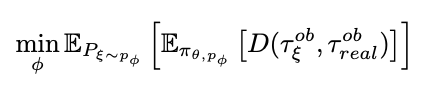
To reduce the amount of real world robot execution ϕ is only updated after a policy has fully converged in simulation. The iterative updates to ϕ is done as follows:
为了减少现实世界中机器人的执行量,仅在策略已完全融合到模拟中之后才更新execution。 ϕ的迭代更新如下进行:
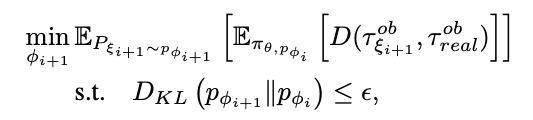
Here is the full algorithm for SimOpt:
这是SimOpt的完整算法:

The number of iterations of sim-opt iteration is just N=3 iterations.
sim-opt迭代的迭代次数仅为N = 3个迭代。
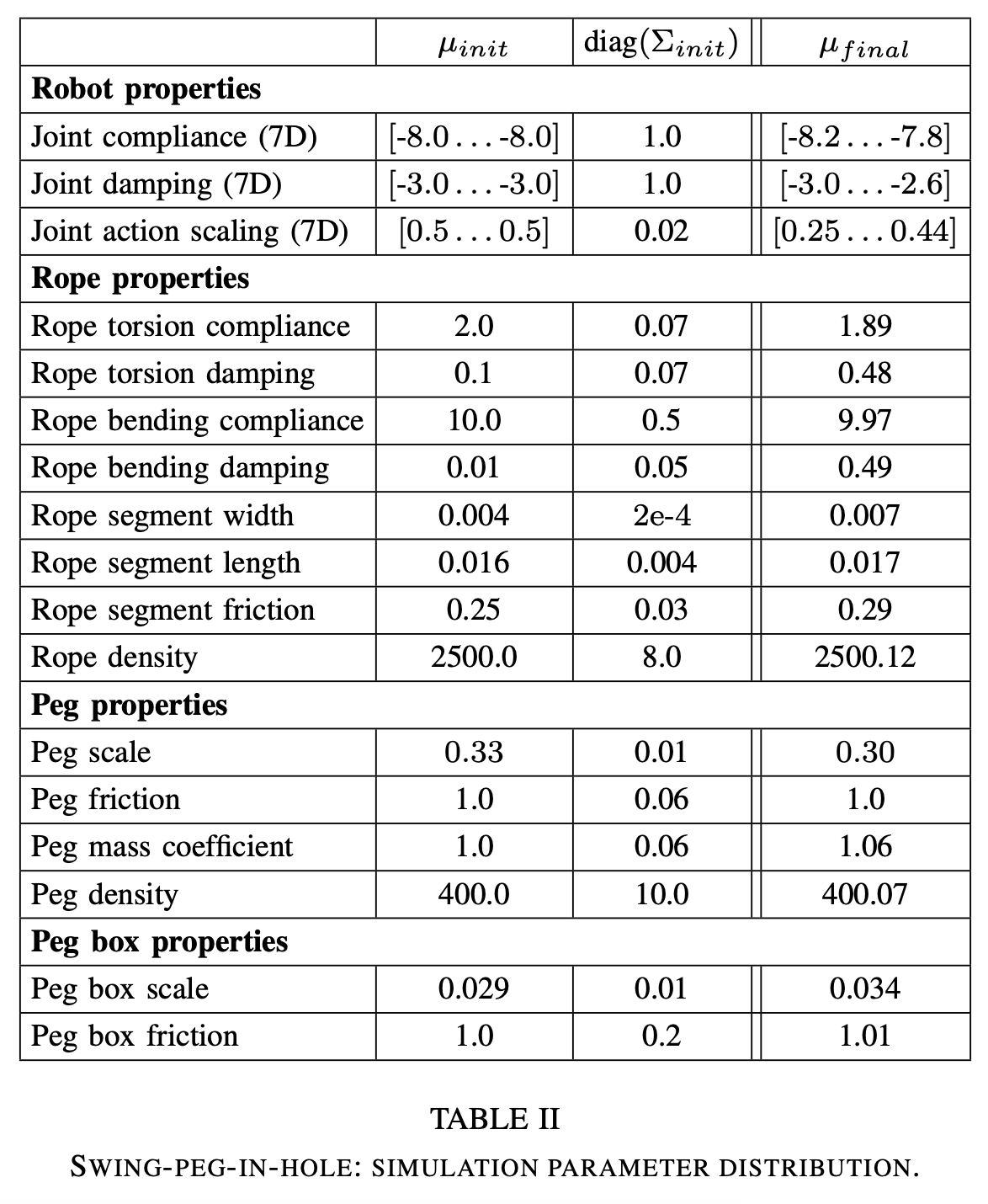
Here are some details of simulator randomizations. Let’s look at swing peg in hole task:
这是模拟器随机化的一些细节。 让我们看一下Kong任务中的摇摆钉:
Simulator: NVIDIA FleX
模拟器: NVIDIA FleX
Simulation Randomizations:
模拟随机化:
Swing peg in hole tasks:
挂钉在Kong任务中:
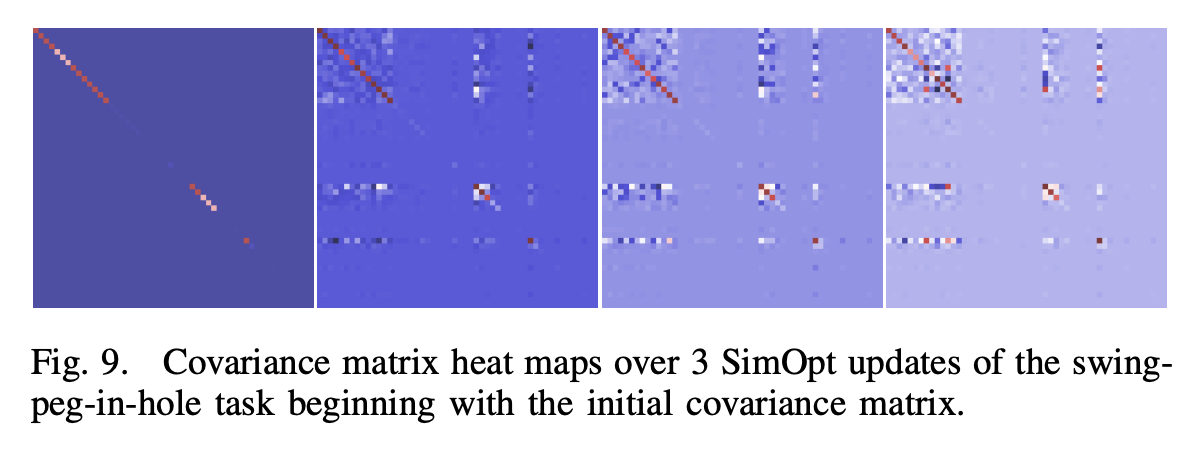
The adaptation of above simulation parameter covariance matrix and corresponding states at the end policy after fully trained.
经过充分训练后,上述仿真参数协方差矩阵和相应状态在最终策略下的适应性。

Although simulation parameters are quite exhaustive the policy inputs are quite minimal. 7 DoF joint positions and 3D position of the peg are inputs to the policy. The reward function is combination of distance from peg from hole, the angle alignment with hole and task success.
尽管仿真参数非常详尽,但是策略输入却很少。 7固定销的DoF联合位置和3D位置是该策略的输入。 奖励功能是到桩钉到Kong的距离,与Kong的角度对齐和任务成功的组合。
The fact that SimOpt needs to run the real robot execution in the training loop seems like it’s asking for a lot. However, notice that no reward function / no full state observations are needed in the real world execution step. All that is needed is to just run the learnt policy on the real robot. This seems like on the fly system identification such that policy trained on P_ϕ(ξ) generalizes on real robot.
SimOpt需要在训练循环中运行真实的机器人执行程序,这一事实似乎要求很高。 但是,请注意,在现实世界的执行步骤中不需要奖励功能/不需要完整状态的观察。 所需要做的只是在真实的机器人上运行学习到的策略。 这似乎是在飞行中的系统识别,使得在P_ϕ(ξ)上训练的策略可以推广到真实的机器人上。
The video below shows execution of policy trained via SimOpt
以下视频显示了通过SimOpt训练的策略的执行
结论: (Conclusion:)
We have seen several examples of successful transfers of sim2real for perception, grasping and feedback control policies. In all the examples, a lot of care has been taken to make the simulation as realistic as possible and choosing the parameters to randomize over. We also saw examples of guided domain randomizations, that simplify the task of manual tuning during sim2real transfer and avoids the policy convergence issues due to extra wide policy specifications.
我们已经看到了成功转移sim2real用于感知,掌握和反馈控制策略的几个示例。 在所有示例中,都采取了很多措施使模拟尽可能逼真并选择要随机化的参数。 我们还看到了引导域随机化的示例,该示例简化了在sim2real传输期间进行手动调整的任务,并避免了由于策略规范过宽而导致的策略收敛问题。
Finally, will leave you with a comic (or a cautionary tale ?)
最后,会给您留下漫画(或警示故事?)
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization
DOPE: Deep Object Pose Estimation for Semantic Robotic Grasping of Household Objects
6-DOF GraspNet: Variational Grasp Generation for Object Manipulation
[Dexterous] Learning dexterous in-hand manipulation.
[Dexterous] 学习灵巧的手操作。
[ADR] Solving Rubik’s Cube with a Robot Hand
[ADR] 用机械手解决魔方
Sim-Opt: Closing the Sim-to-Real Loop: Adapting Simulation Randomization with Real World Experience
翻译自: https://medium.com/@darshanhegde_5567/sim2real-in-robotic-manipulation-e42122bca941
sim9000a sim

















 6986
6986

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}