





亚马逊云ec2实例如何删除
Expedia Group Technology —软件 (EXPEDIA GROUP TECHNOLOGY — SOFTWARE)
Until recently, most companies didn’t care how much they spent on their cloud resources. But in a covid-19 world, companies like Expedia Group™ are reducing cloud spending where reasonable. While many Apache Spark tuning guides discuss how to get the best performance using Spark, none of them ever discuss the cost of that performance.
直到最近,大多数公司才不在乎他们在云资源上花费了多少。 但是,在19年代的世界中,像Expedia Group™这样的公司正在合理地减少云支出。 尽管许多Apache Spark调优指南都讨论了如何使用Spark获得最佳性能,但没有一个人讨论过该性能的成本。
This guide will discuss how to get the best performance with Spark at the most efficient cost. It will also discuss how to estimate the cost of your jobs and what makes up actual costs on AWS. In addition, the guide will recommend a cost tuning strategy that is entirely focused on executor configuration so that no code changes are necessary.
本指南将讨论如何以最有效的成本获得Spark的最佳性能。 它还将讨论如何估算您的工作成本以及AWS的实际成本。 另外,该指南将建议一种成本调整策略,该策略应完全集中在执行程序配置上,因此无需更改任何代码。
If you are an experienced Spark tuner, I will warn you that a paradigm shift is necessary from current tuning practices in order to reduce your Spark job costs on AWS. But I promise these techniques will work.
如果您是经验丰富的Spark调谐器,我会警告您,为了降低您在AWS上的Spark作业成本,有必要从当前的调整实践中进行范式转换。 但我保证这些技术会起作用。
In this guide, I will share the proven tuning principles that Expedia is using to reduce cloud spending by 30%-80% with our batch Spark jobs that run on AWS. There’s a lot to cover so this guide will be released as a multi-part series. The full series will consist of the following parts.
在本指南中,我将与我们在AWS上运行的批处理Spark作业共享Expedia用来减少30%-80%的云支出的行之有效的调整原则。 有很多要讨论的内容,因此本指南将分多个部分发布。 整个系列将包括以下部分。
Part 1: Cloud Spending Efficiency Guide for Apache Spark on EC2 Instances
第1部分:针对EC2实例上的Apache Spark的云支出效率指南
Part 3: Cost Efficient Executor Configuration for Apache Spark
Part 4: How to Migrate Existing Apache Spark Jobs to Cost Efficient Executor Configurations

减少云支出 (Reducing cloud spending)
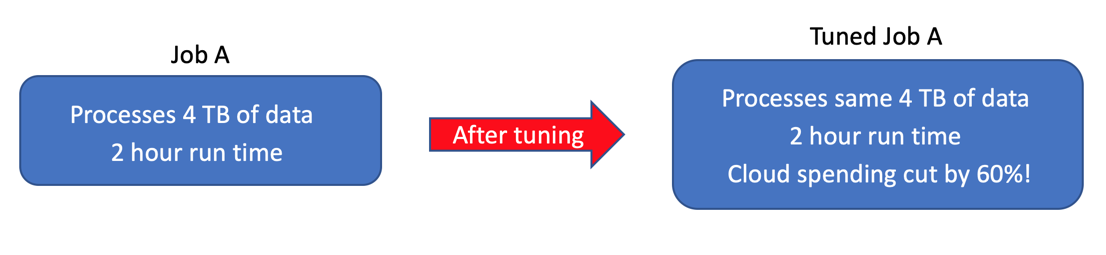
While Spark is easy to learn, it is also difficult to tune for efficient processing without a good knowledge of Spark internals. For example, take a job that I tuned which processed 4 TBs of data over two hours. After proper cost tuning, this job processed the same 4 TBs of data in the same amount of time but for a third of the cloud spending cost!
尽管Spark很容易学习,但是如果没有对Spark内部知识的充分了解,就很难进行有效的处理调整。 例如,请执行我调整过的工作,该工作在两个小时内处理了4 TB的数据。 经过适当的成本调整后,此作业在相同的时间内处理了相同的4 TB数据,但只花了三分之一的云计算费用 !
Spark执行器模型 (Spark Executor model)
In order to understand the key to tuning for cloud spending efficiency, you have to understand the Spark executor model. Here’s a brief overview of the Spark executor model for the non-data engineers reading this blog. Data engineers are welcome to scroll down to the “Key to cloud efficiency” section.
为了了解调整云支出效率的关键,您必须了解Spark执行程序模型。 这是供非数据工程师阅读此博客的Spark执行程序模型的简要概述。 欢迎数据工程师向下滚动至“云效率的关键”部分。
Every time a data engineer submits a Spark job, there are four parameters they usually submit that are crucial to determining how well the job performs.
数据工程师每次提交Spark作业时,通常都会提交四个参数,这些参数对于确定作业的执行情况至关重要。
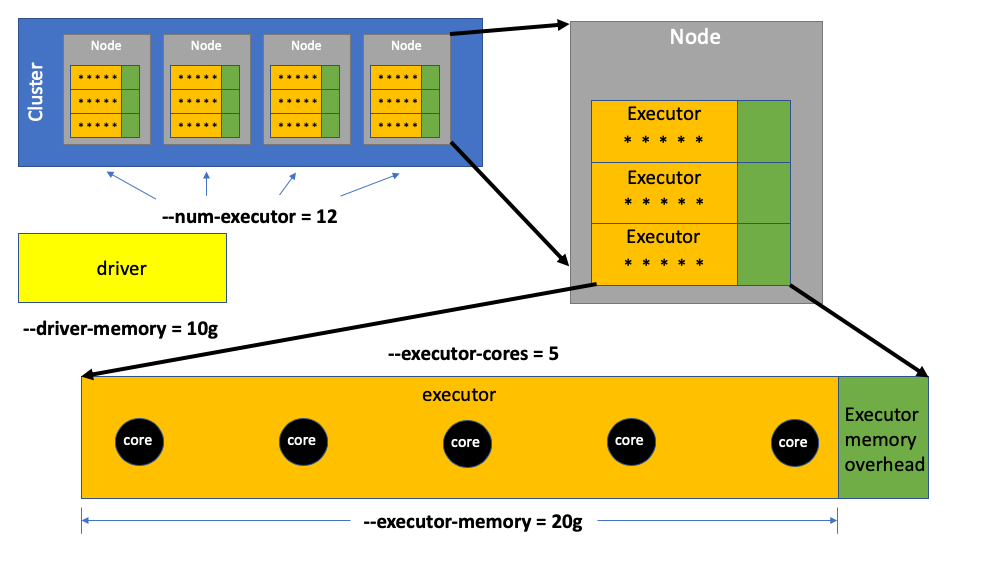
--num-executors determines how many executors are used to process the data.
--num-executors确定使用多少个执行器来处理数据。
--executor-cores specifies the number of Spark cores that make up each executor. Spark cores do all the work of processing data in an executor. In the above example, 12 executors with 5 Spark cores each equates to 60 Spark cores processing data.
--executor-cores指定组成每个执行程序的Spark内核数。 Spark核心完成了在执行器中处理数据的所有工作。 在上面的示例中,具有5个Spark核心的12个执行程序相当于60个处理数据的Spark核心。
The Spark cores within an executor use a pool of memory allocated to the executor by the data engineer using --executor-memory.
执行程序中的Spark核心使用由数据工程师使用--executor-memory分配给执行程序的内存池。
And then a driver coordinates the processing of data for all the executors using a memory pool allocated to the driver by the data engineer using --driver-memory.
然后,驱动程序使用数据驱动程序使用--driver-memory分配给该驱动程序的内存池来协调所有执行程序的数据处理。
Executors are allocated to individual EC2 instances (aka nodes) on a cluster until the physical memory on that node is consumed. When a new executor won’t fit in the node’s available memory, a new node will be spun up (depending on your auto-scaling policy) and added to the cluster to host that new executor. Each node has a fixed number of CPUs available for processing data by Spark cores. While executors can’t exceed the node’s available physical memory, they can have more Spark cores than available CPUs on that node.
执行器被分配给群集中的各个EC2实例(又名节点),直到该节点上的物理内存被消耗为止。 当新的执行程序不适合该节点的可用内存时,将旋转一个新节点(取决于您的自动扩展策略),并将其添加到群集中以托管该新的执行程序。 每个节点都有固定数量的CPU,可用于通过Spark内核处理数据。 尽管执行程序不能超过节点的可用物理内存,但执行者可以拥有比该节点上可用的CPU更多的Spark内核。

云效率的关键 (Key to cloud efficiency)
When the Spark cores of all executors on a node exceeds the available CPUs on that node, time-slicing occurs as each Spark core waits its turn to be processed by the overworked CPUs. Time-slicing is inefficient node utilization and should be avoided. Conversely, if the Spark cores of all executors on a node is lower than the available CPUs, then the node CPUs will be underutilized which is also inefficient node utilization. When your Spark core count for all executors on a node matches the number of available node CPUs, then you have efficient CPU utilization of that node.
当节点上所有执行程序的Spark核心超过该节点上的可用CPU时,会发生时间分片 ,因为每个Spark核心都等待轮流工作,以供过度使用的CPU处理。 时间分片是低效的节点利用率 ,应避免使用。 相反,如果节点上所有执行程序的Spark内核低于可用的CPU,则节点CPU的利用率将不足,这也将降低节点利用率 。 当节点上所有执行程序的Spark核心计数与可用节点CPU的数量匹配时,您就可以有效地使用该节点的CPU 。
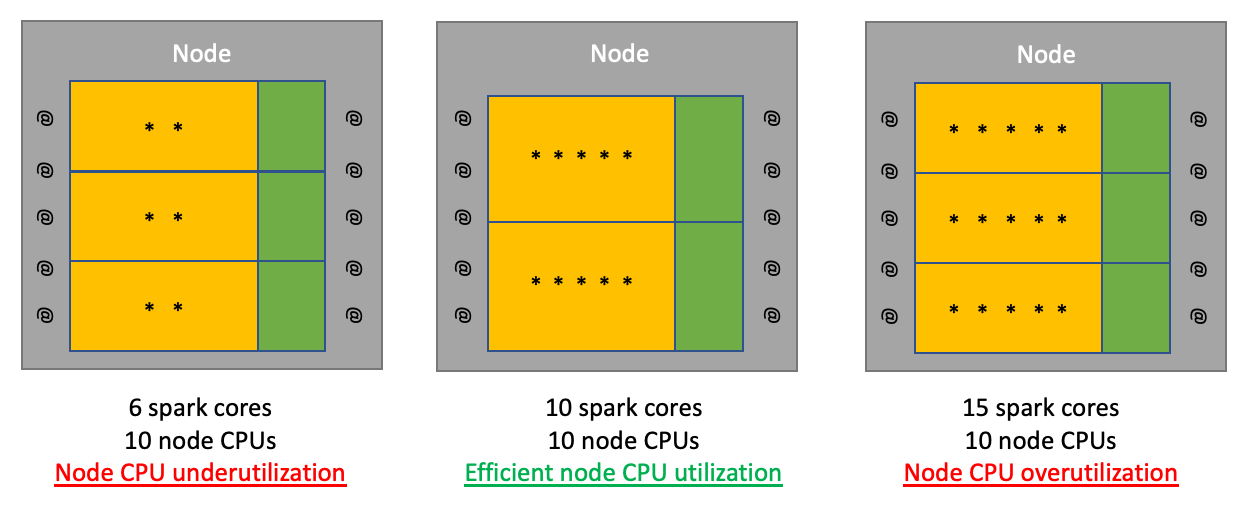
The goal for minimizing cloud spending when running Spark jobs is simple. You want to make sure your executors are configured so that Spark is efficiently utilizing all available node CPUs without time-slicing. The reason why is because AWS charges you on a per node per second basis for every Spark job that runs on a cluster. If a job runs on fewer nodes but completes in the same amount of time, then you save money for that job.
运行Spark作业时最小化云支出的目标很简单。 您要确保已配置执行程序,以使Spark可以高效利用所有可用的节点CPU,而无需进行时间分割 。 原因是因为AWS对群集上运行的每个Spark作业按每秒每个节点向您收费。 如果作业在较少的节点上运行,但在相同的时间内完成,则可以为该作业省钱。
The non-tuned job I mentioned earlier used only a third of the available CPUs on each node because of an inefficient executor configuration. As a result, the non-tuned job used three times as many nodes to process the same data as the tuned job. After the job was cost tuned the node count dropped by almost two thirds because the efficiently configured executors used every available CPU on each node. The tuned job had the same number of Spark cores as the untuned job, but that equal number of Spark cores were squeezed into fewer nodes.
由于执行器配置效率低下,我前面提到的非调整作业仅在每个节点上使用了三分之一的可用CPU 。 结果,未调整的作业使用的节点数是调整后的作业的三倍 。 在对成本进行成本调整之后,由于有效配置的执行程序使用了每个节点上的每个可用CPU,因此节点数减少了近三分之二 。 调整后的作业具有与未调整的作业相同数量的Spark内核,但是将相同数量的Spark核心压缩到更少的节点中。

在相同的运行时间下运行的节点减少60%=云计算支出减少60% (60% fewer nodes running with same run time = 60% reduction in cloud spending)
The challenge with squeezing the right number of Spark cores onto a node is that it’s how you configure your executor memory that determines how many Spark cores ultimately reside on your node. And in some cases, maximizing Spark cores on a node can actually make your job run slower (but still cheaper).
将正确数量的Spark内核压缩到一个节点上的挑战在于,这就是您 配置您的执行程序内存 ,该内存确定最终在您的节点上驻留多少Spark核心。 在某些情况下,最大化节点上的Spark内核实际上可以使您的工作运行得更慢(但仍然更便宜)。
In the next part of this series, I’ll look at some real examples of Spark jobs that were cost tuned at Expedia Group to see how much cost savings can be achieved when focused on CPU node efficiency using the strategies in this guide.
在本系列的下一部分中 ,我将看一下Expedia Group进行成本调整的Spark作业的一些实际示例,以了解使用本指南中的策略专注于CPU节点效率时可以节省多少成本。
亚马逊云ec2实例如何删除















 1642
1642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









