









 文章详细介绍了深度学习在搜索、广告和推荐系统中的应用,包括样本和特征处理、模型训练与预测、分布式模型服务以及匹配算法。重点讨论了增量训练优化模型更新、线上实时特征落盘提升性能和不同阶段的匹配流程。同时,提到了分布式机器学习对于处理大规模流量的重要性。
文章详细介绍了深度学习在搜索、广告和推荐系统中的应用,包括样本和特征处理、模型训练与预测、分布式模型服务以及匹配算法。重点讨论了增量训练优化模型更新、线上实时特征落盘提升性能和不同阶段的匹配流程。同时,提到了分布式机器学习对于处理大规模流量的重要性。
兜率宫小道童的个人空间-兜率宫小道童个人主页-哔哩哔哩视频(如下是该视频课系列的笔记)
1-深度学习在搜索、广告、推荐系统中的应用-业务问题建模_哔哩哔哩_bilibili
其他章节
目录
分布式机器学习 GitHub - dmlc/ps-lite: A lightweight parameter server interface
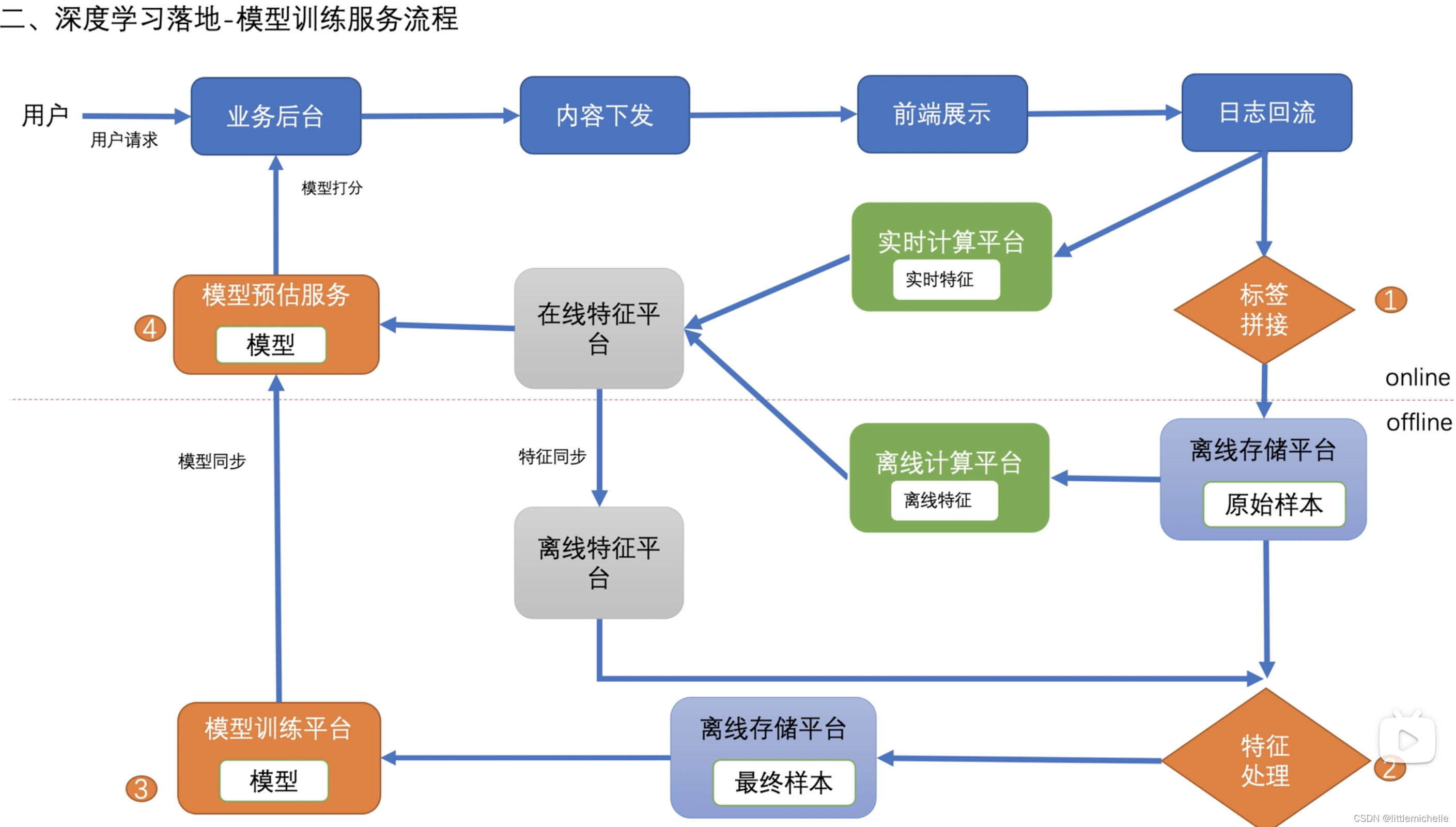
一天访问量会有百亿级别,单机是无法满足服务,做分布式模型服务
分布式模型服务-> 无状态,机器间不会被依赖
一些结论
- 增量训练
用历史上一个训练好的模型做初始化,
用过去一个月,或者是三个月的样本做全量训练。 但此时,训练量是很大的,
比如,今天用前30天的样本进行训练,
明天用新增数据做增量训练,极大加快了模型的训练速度。有利于把最新的样本反应到 model 里面去,
对用户、商品冷启都有好的效果。
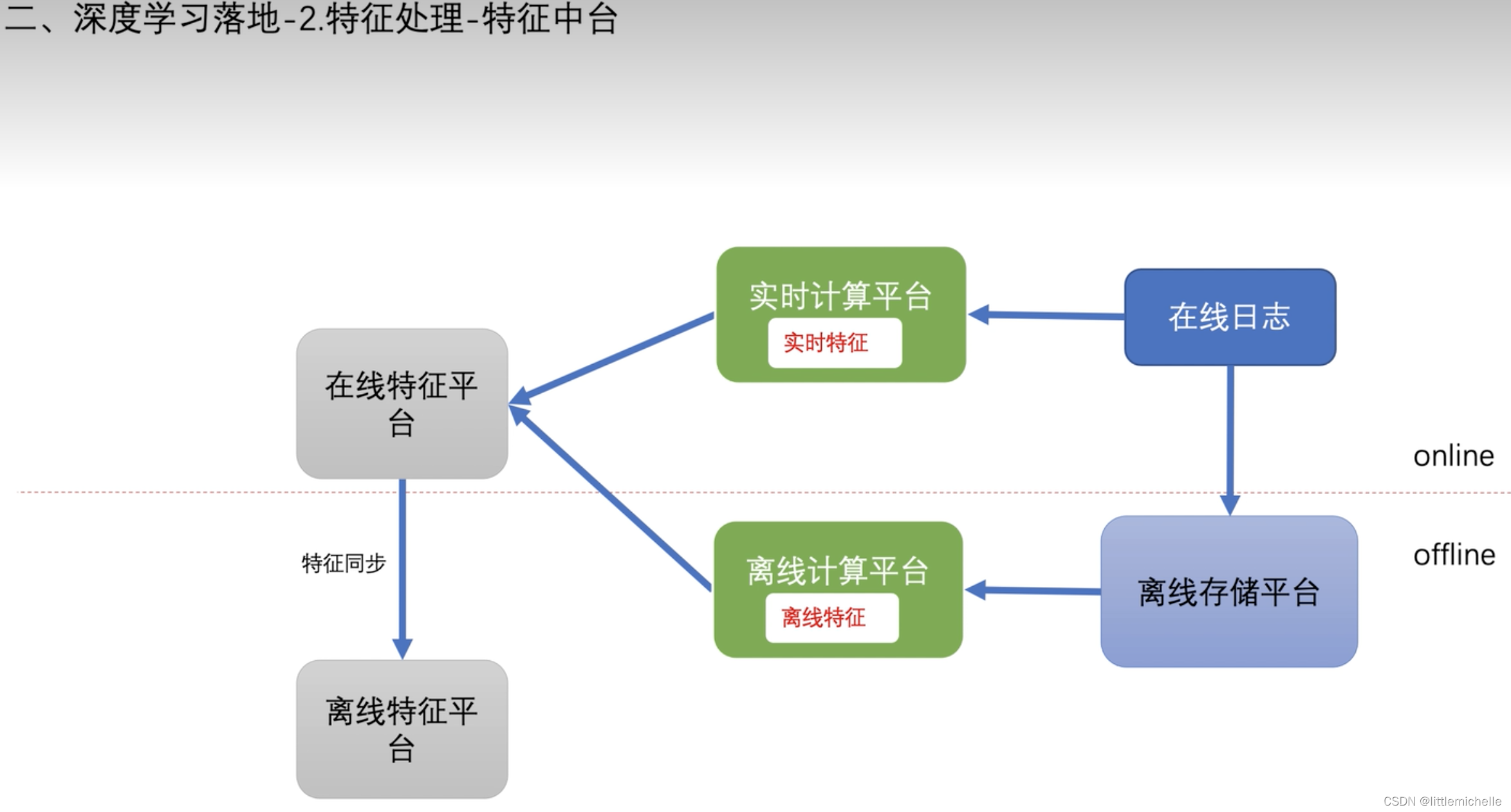
- 线上实时特征落盘
为什么在线特征定期同步给离线平台?——节约性能
当我们在线上发起一次预估请求,会将 model所需的成百上千特征都收集好,送给 model去预测。
我们希望将这成百上千特征都存下来,直接离线做明文特征抽取。
因为特征很多,会导致用来存储特征的线上包很大,会影响线上的性能+从在线到离线的存储过程中,会产生大量的时间开销。
由此产生:
只将线上的实时特征落盘过来,将时间不敏感的特征用离线特征平台拼接给样本。一方面节省线上开销,离线可以并行提高处理速度。
- 交叉熵 衡量两个部分的差异。
- NHSW的损失是比较小的,检索效率高。
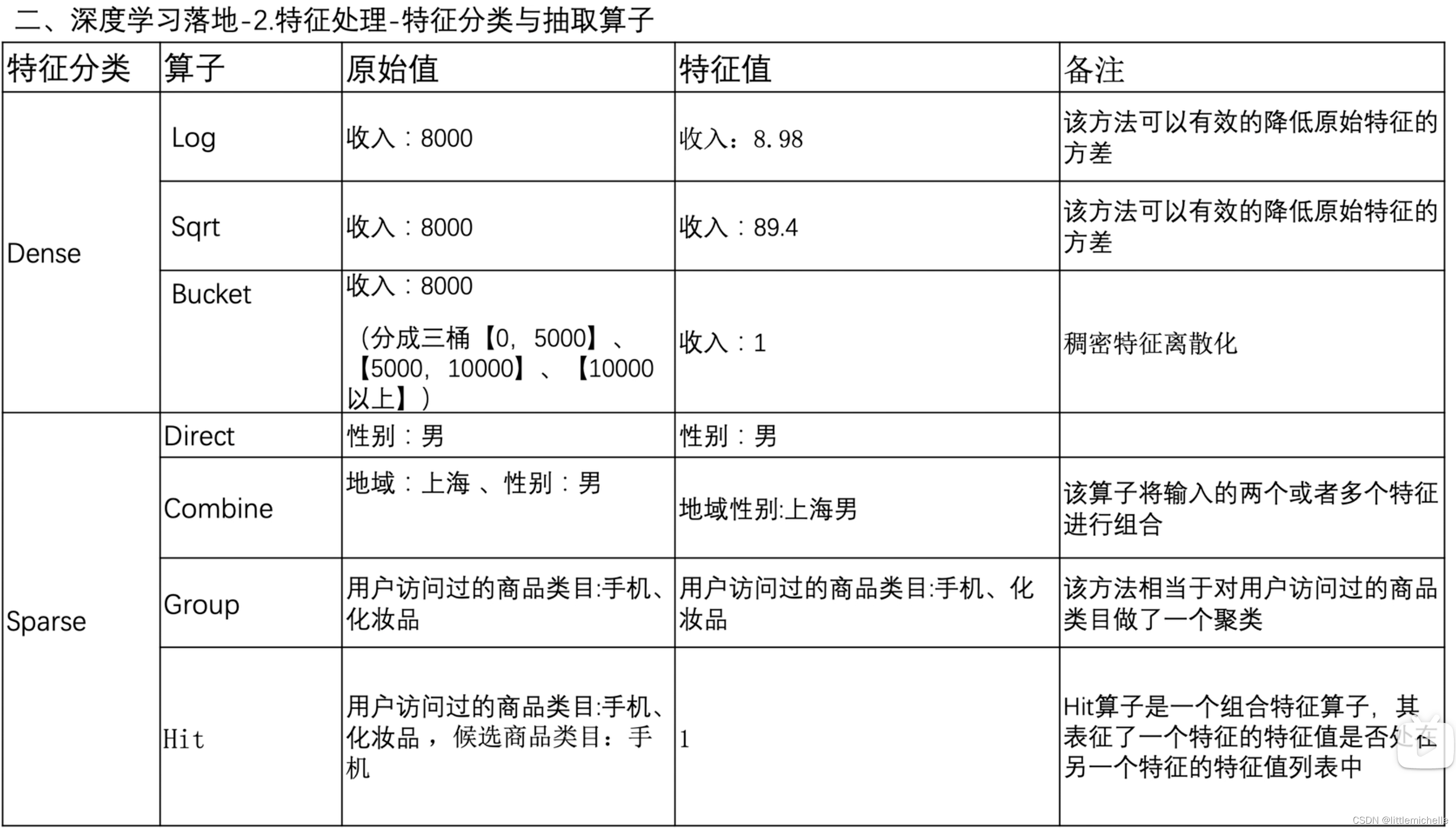
- 特征方差比较大,会造成 model梯度颠簸,会影响模型收敛速度和效果,所以要做归一化/log 等。
- 近线系统:model 是天级别更新的,但是特征是天级别、小时级别更新的。???
二、深度学习落地
如何在检索匹配中使用深度学习?
2.1-深度学习在搜索、广告、推荐系统中的应用-样本和特征处理_哔哩哔哩_bilibili
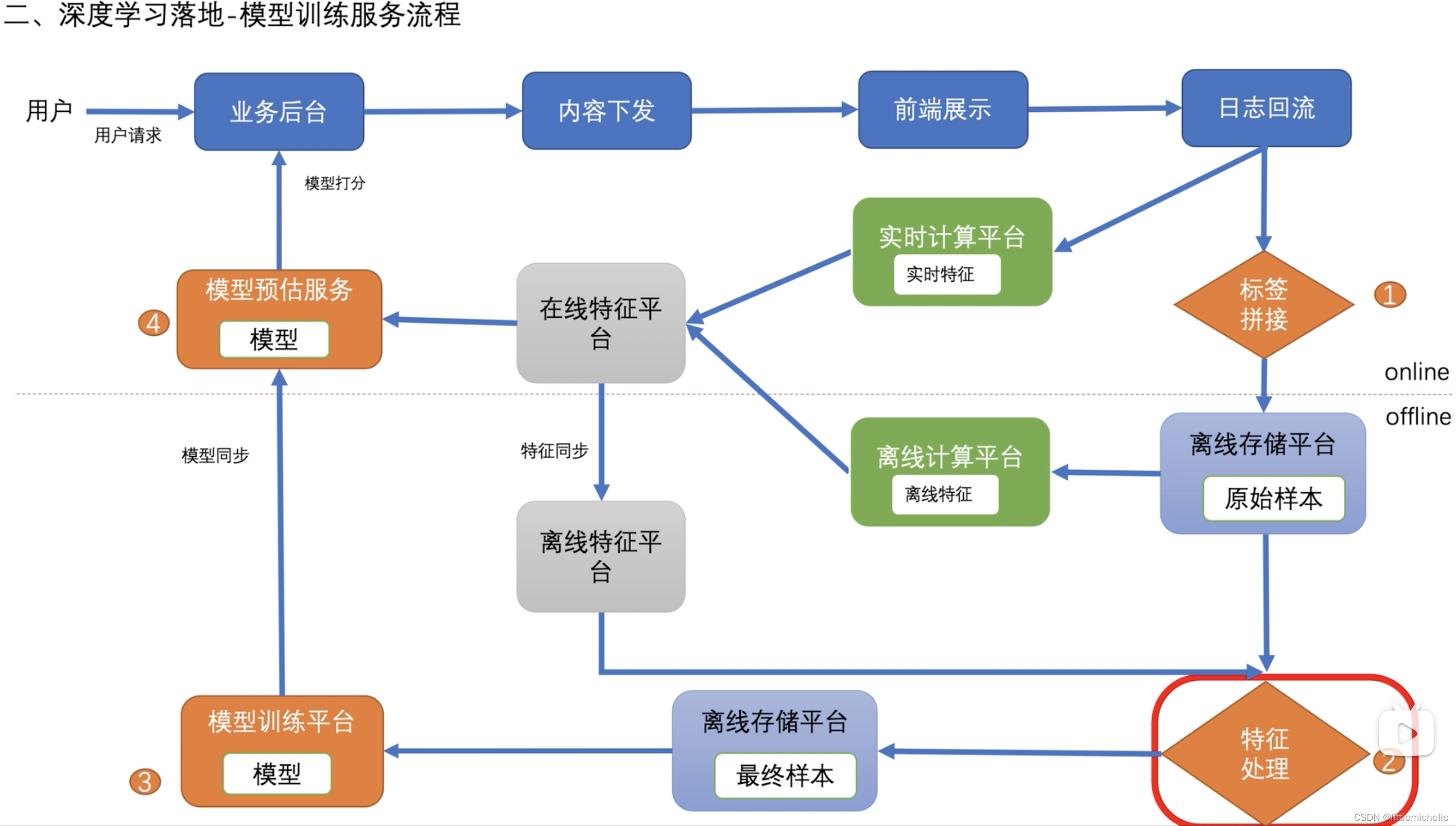
模型训练服务流程
1-样本生成-标签拼接

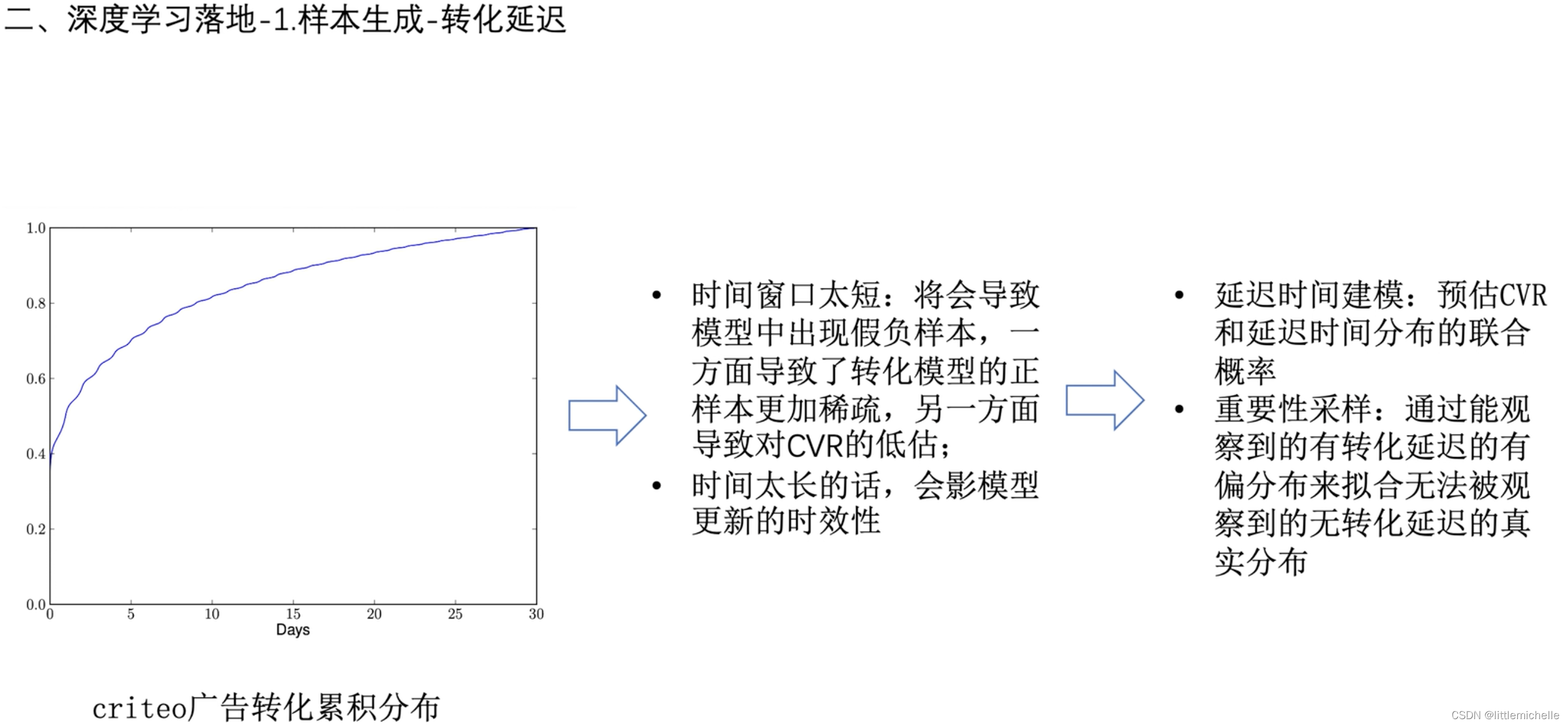
1-样本生成-转化延迟
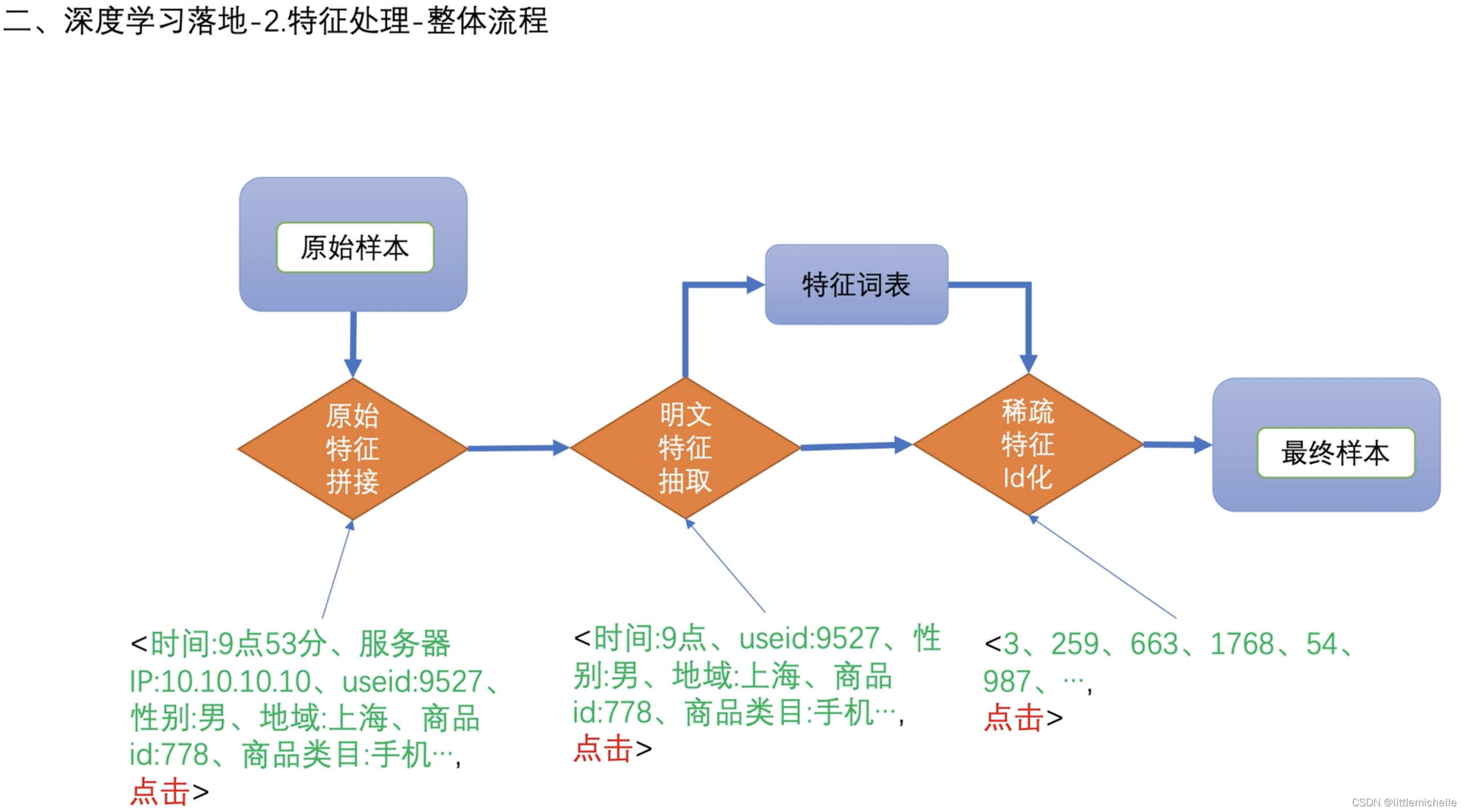
2-特征处理-整体流程
2-特征处理-特征中台
2-特征处理-原始特征拼接

2-特征处理-特征分类与抽取算子
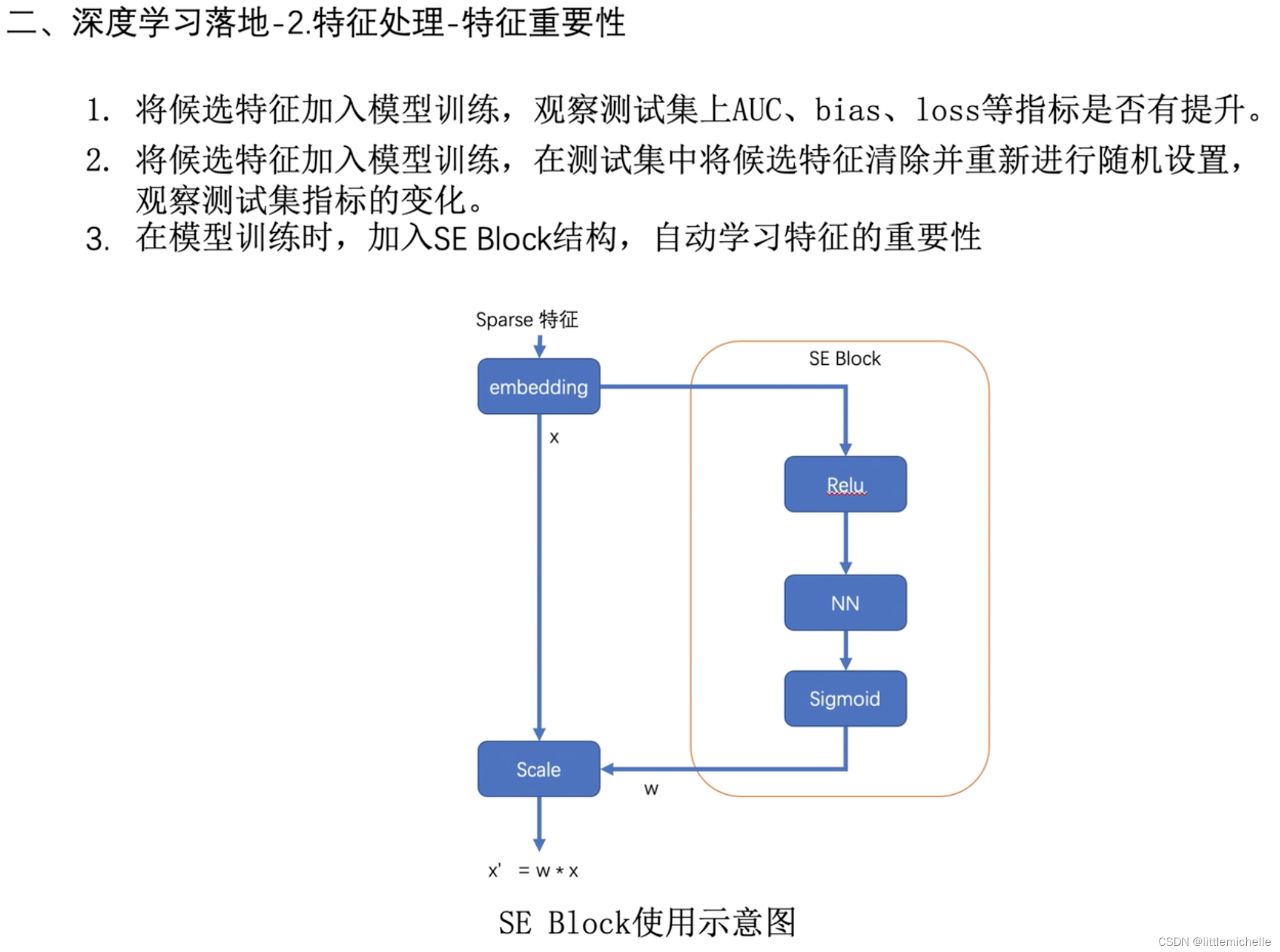
2-特征处理-特征重要性
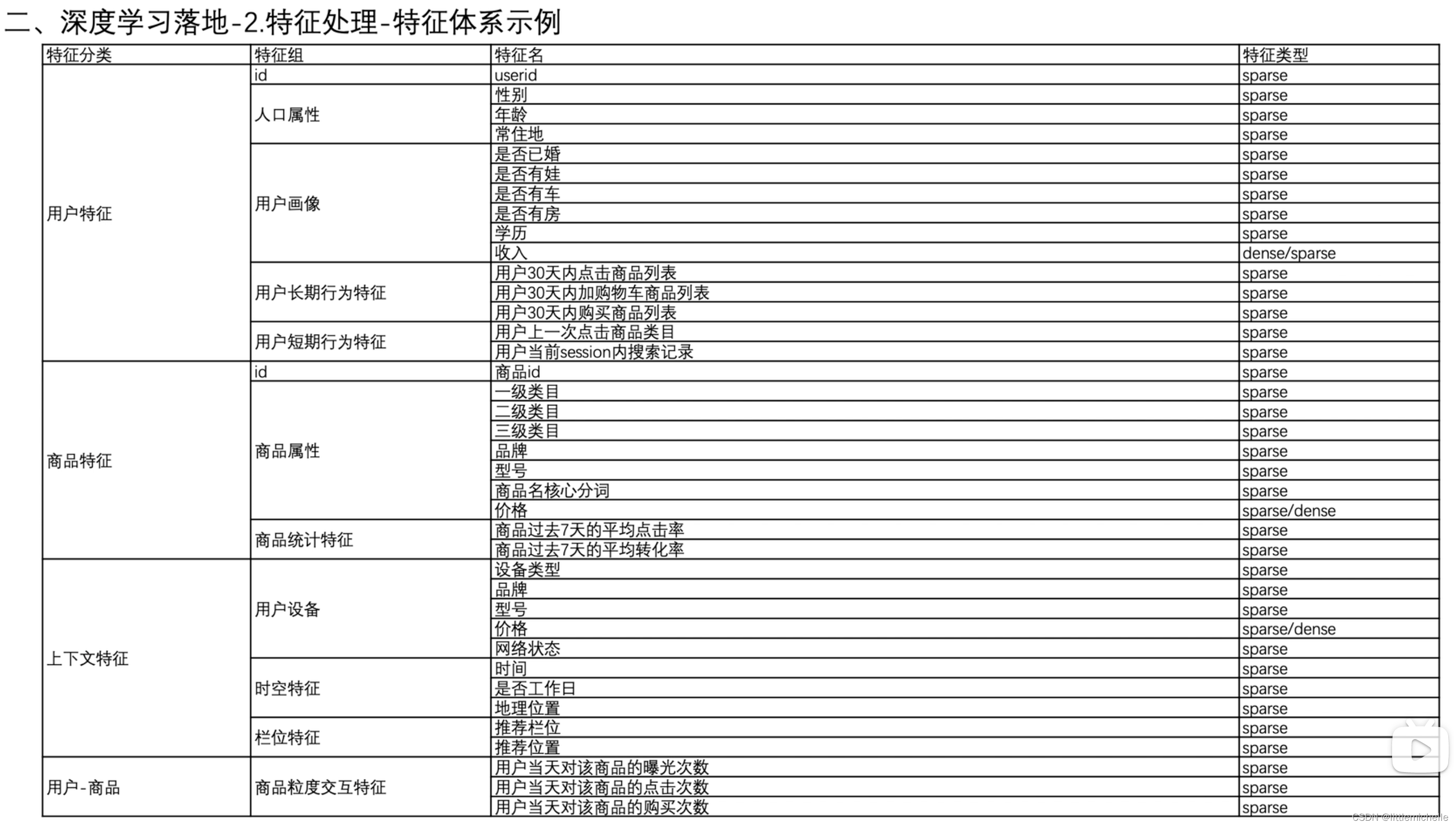
2-特征处理-特征体系示例
2.2-深度学习在搜索、广告、推荐系统中的应用-模型训练和预测_哔哩哔哩_bilibili
3-模型训练平台-模型构建

3-模型训练平台-模型构建-模型结构
3-模型训练平台-模型构建-损失函数
3-模型训练平台-模型构建-优化器

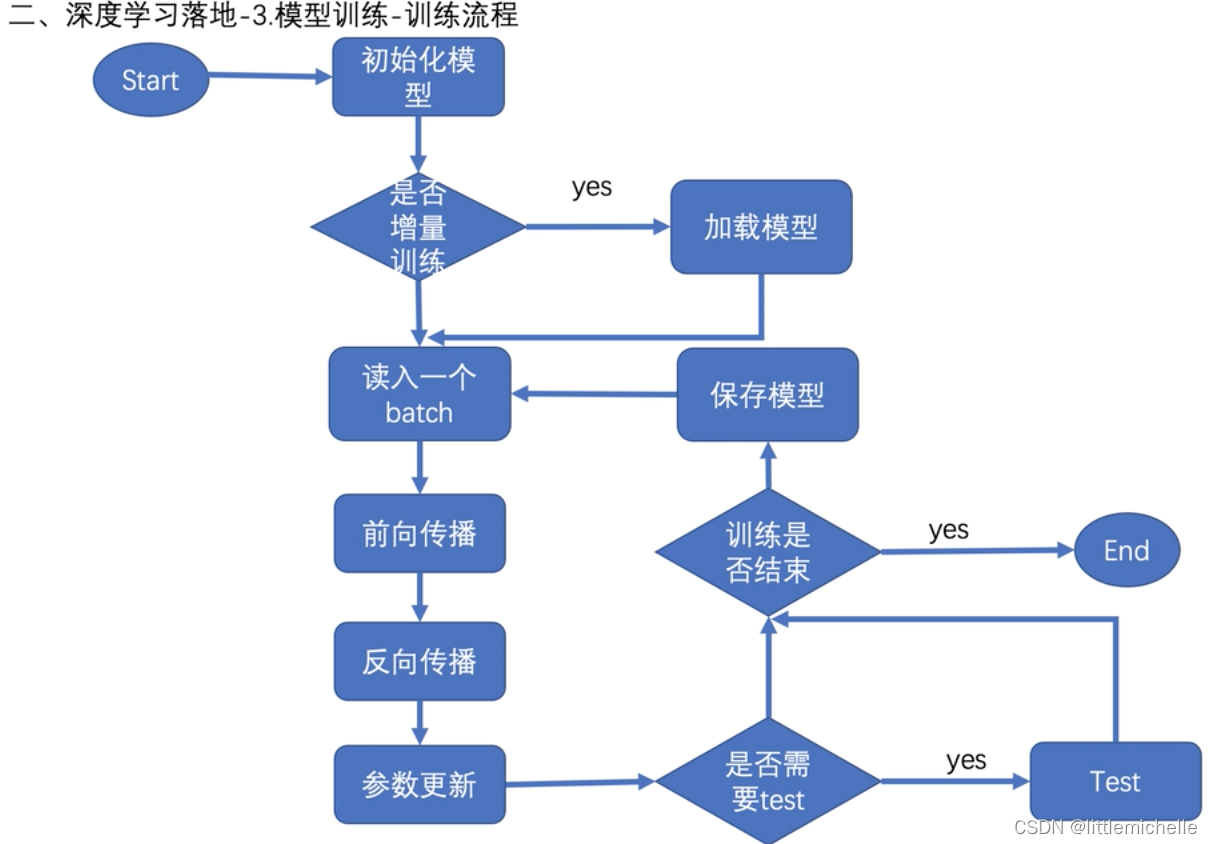
3-模型训练-训练流程
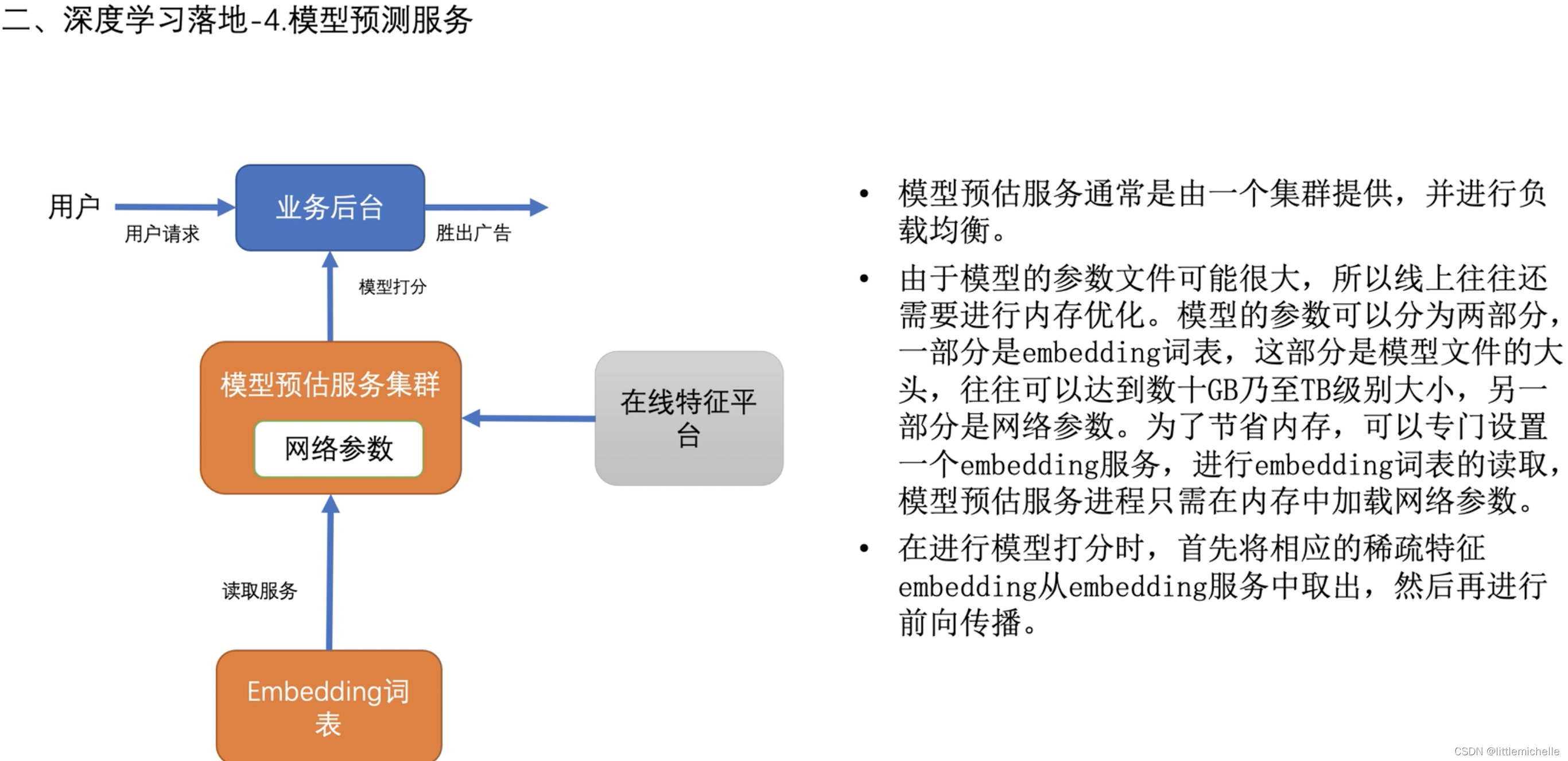
4-模型预测服务
模型文件:1、emb词表;2、model 的网络参数;
网络参数是可以加载到内存里的,但是 emb 不行。
实际预测时,model 后台会将这次预测用到的所有特征收集好,进行特征处理之后,将处理之后的稀疏特征的 emb 读取回来,再将 emb 和dense特征一起送给 model 预估的机器做预测。
考虑线上的流量比较大,一天会有百亿级别,单机无法满足,往往会做一个分布式的模型服务。
服务是无状态的,各个机器之间不依赖。不用写,只读,会比较简单。
三、深度学习算法进阶
复杂深度学习模型在检索匹配中的应用?
3.1-深度学习在搜索、广告、推荐系统中的应用-算法进阶-匹配算法分类_哔哩哔哩_bilibili
检索算法分类
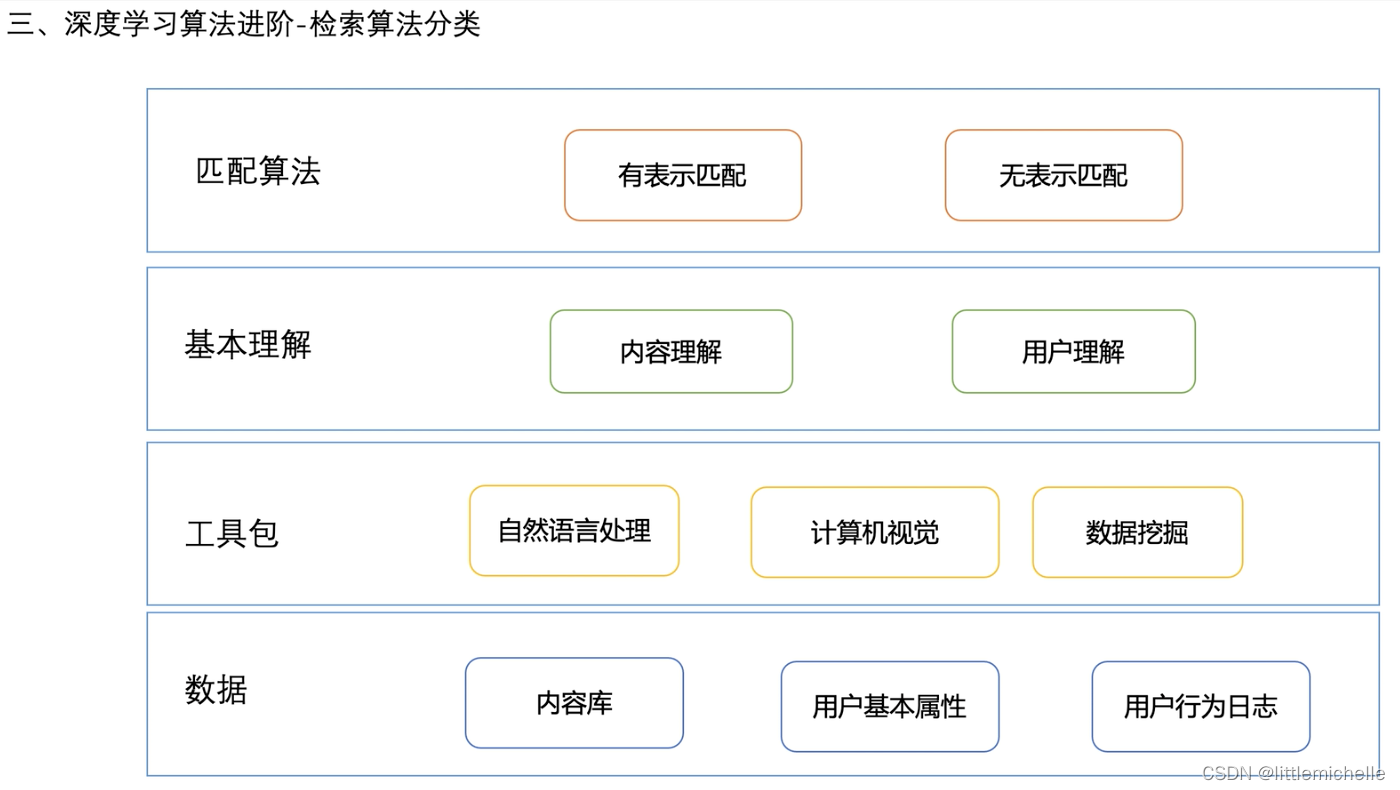
1-匹配算法分类
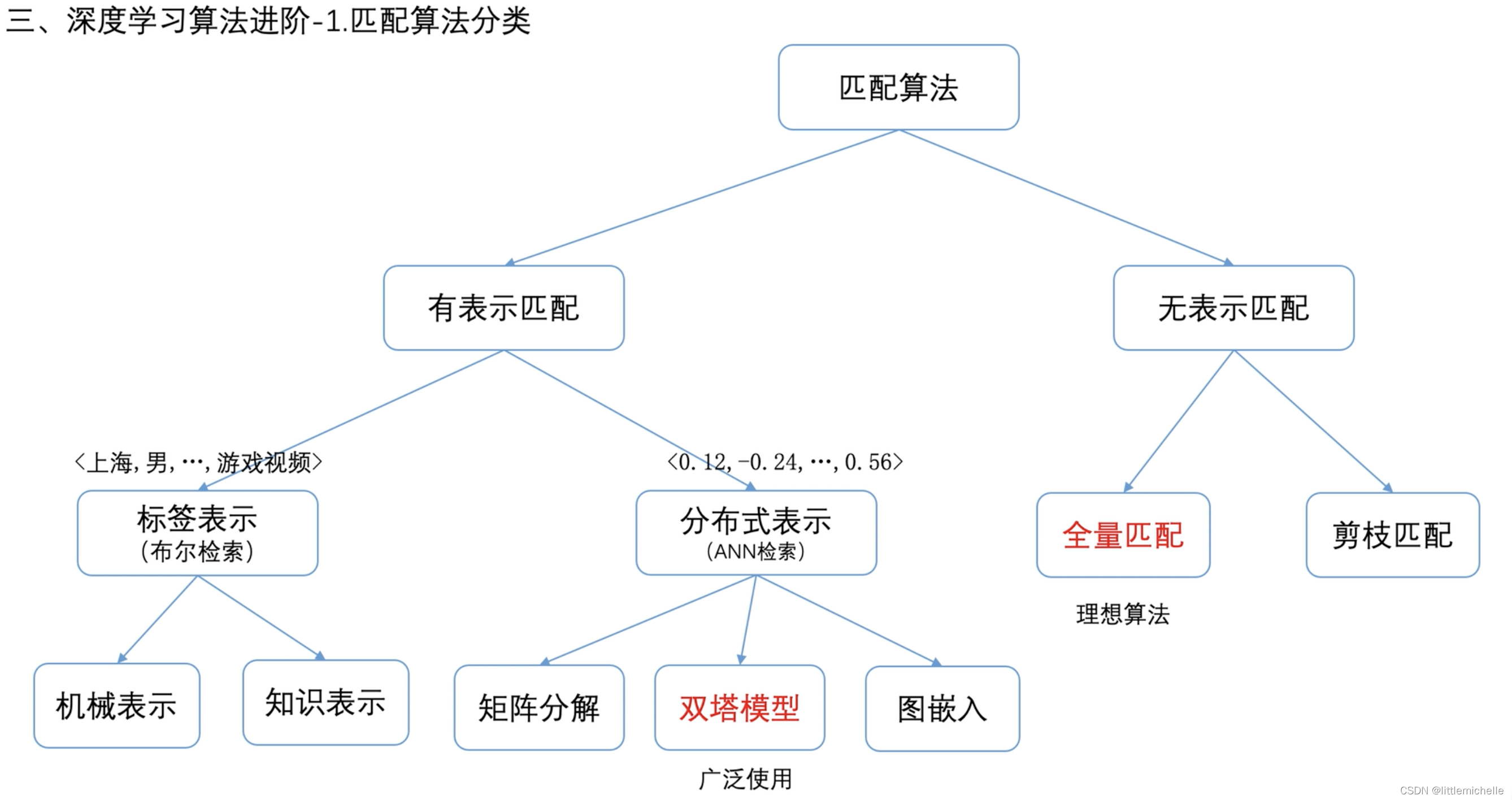
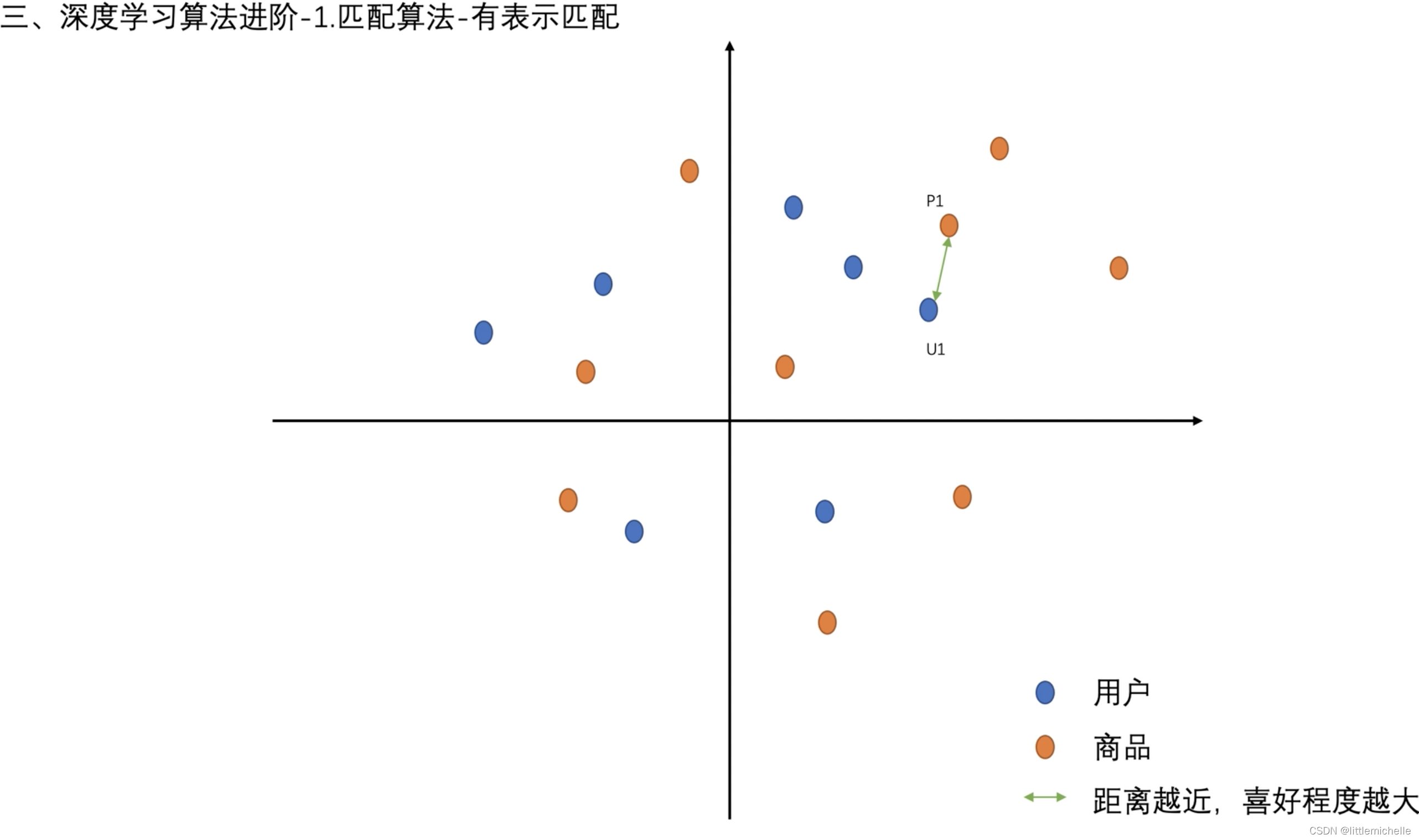
1-匹配算法-有表示匹配
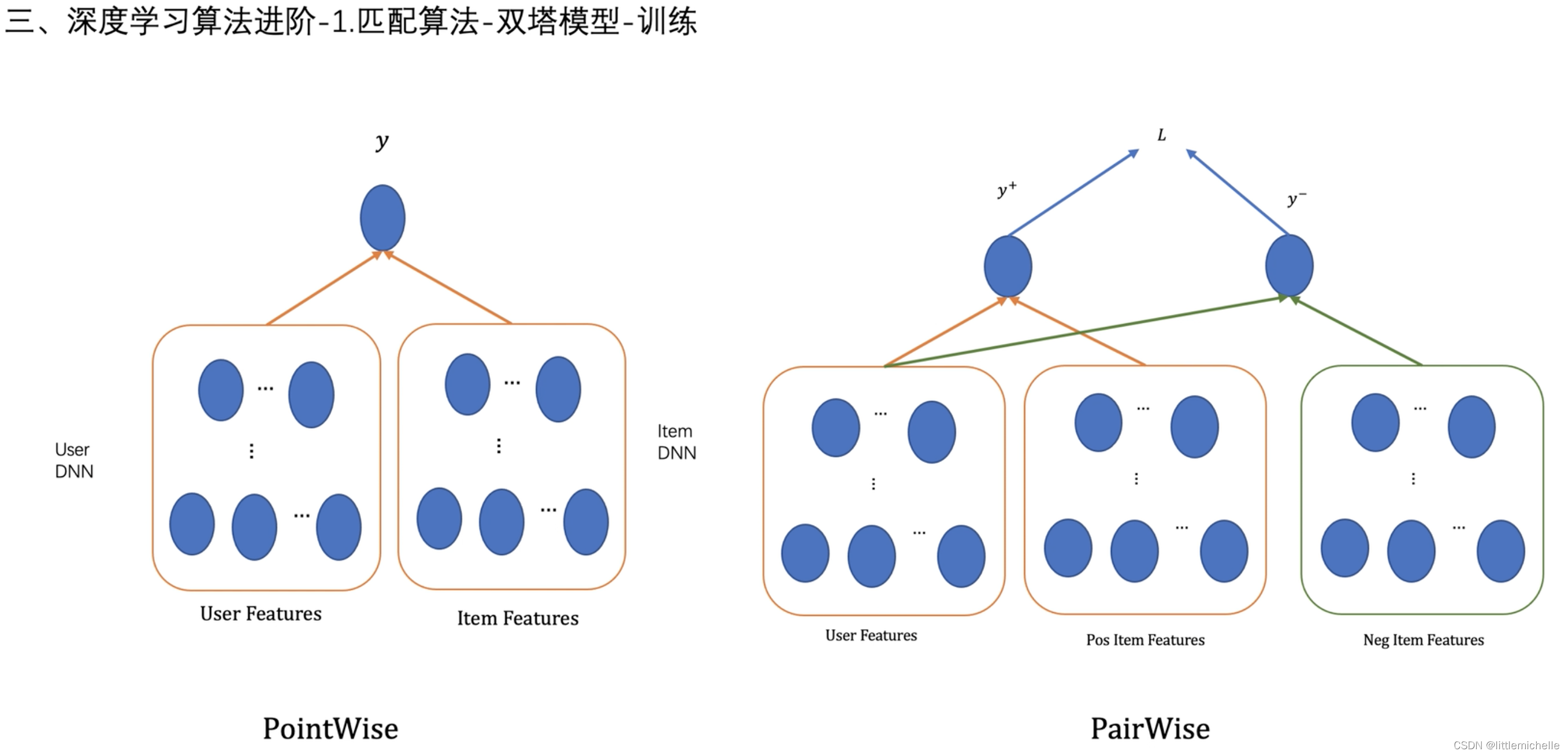
1- 匹配算法-双塔模型-训练
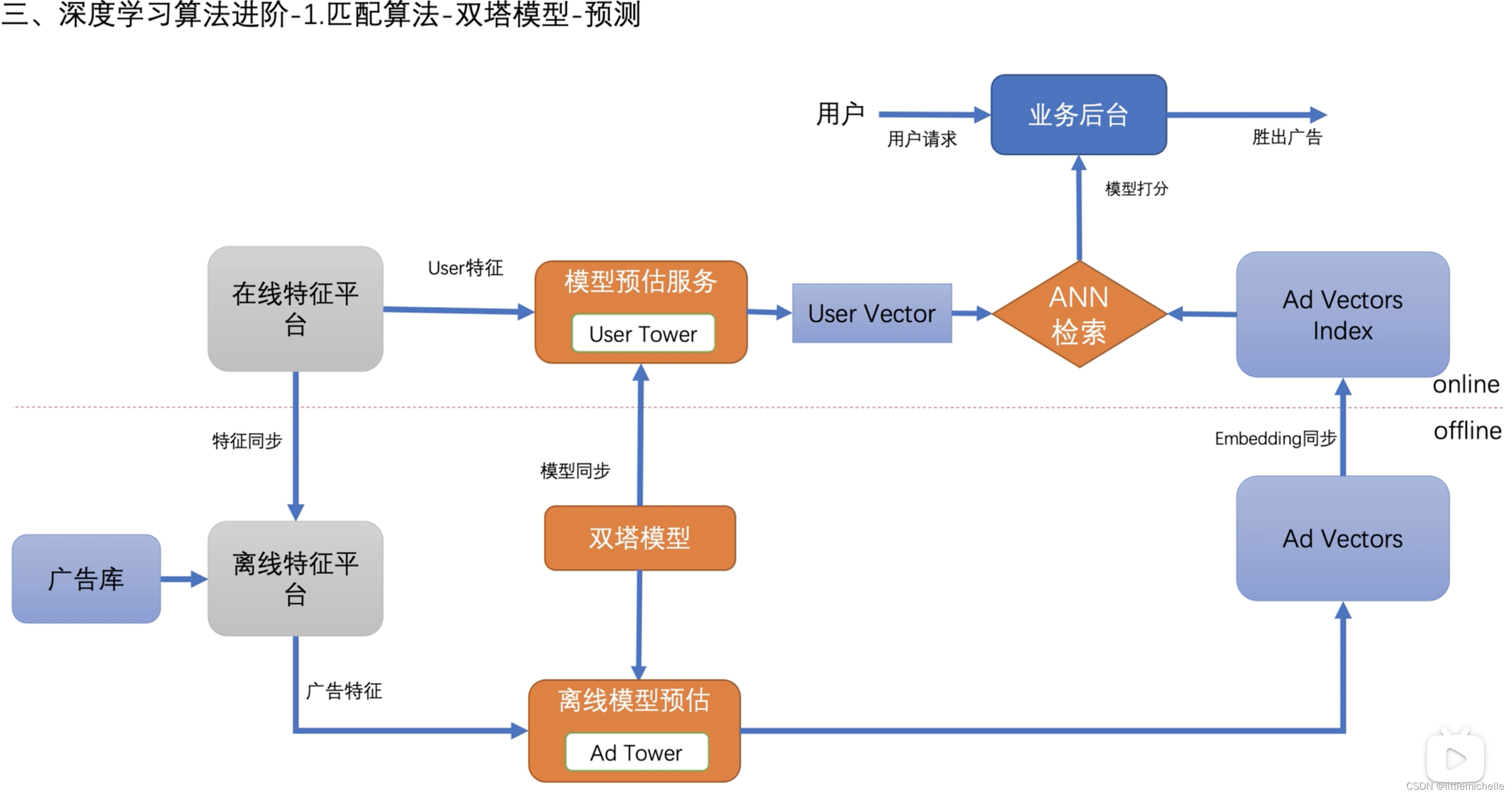
1-匹配算法-双塔模型-预测
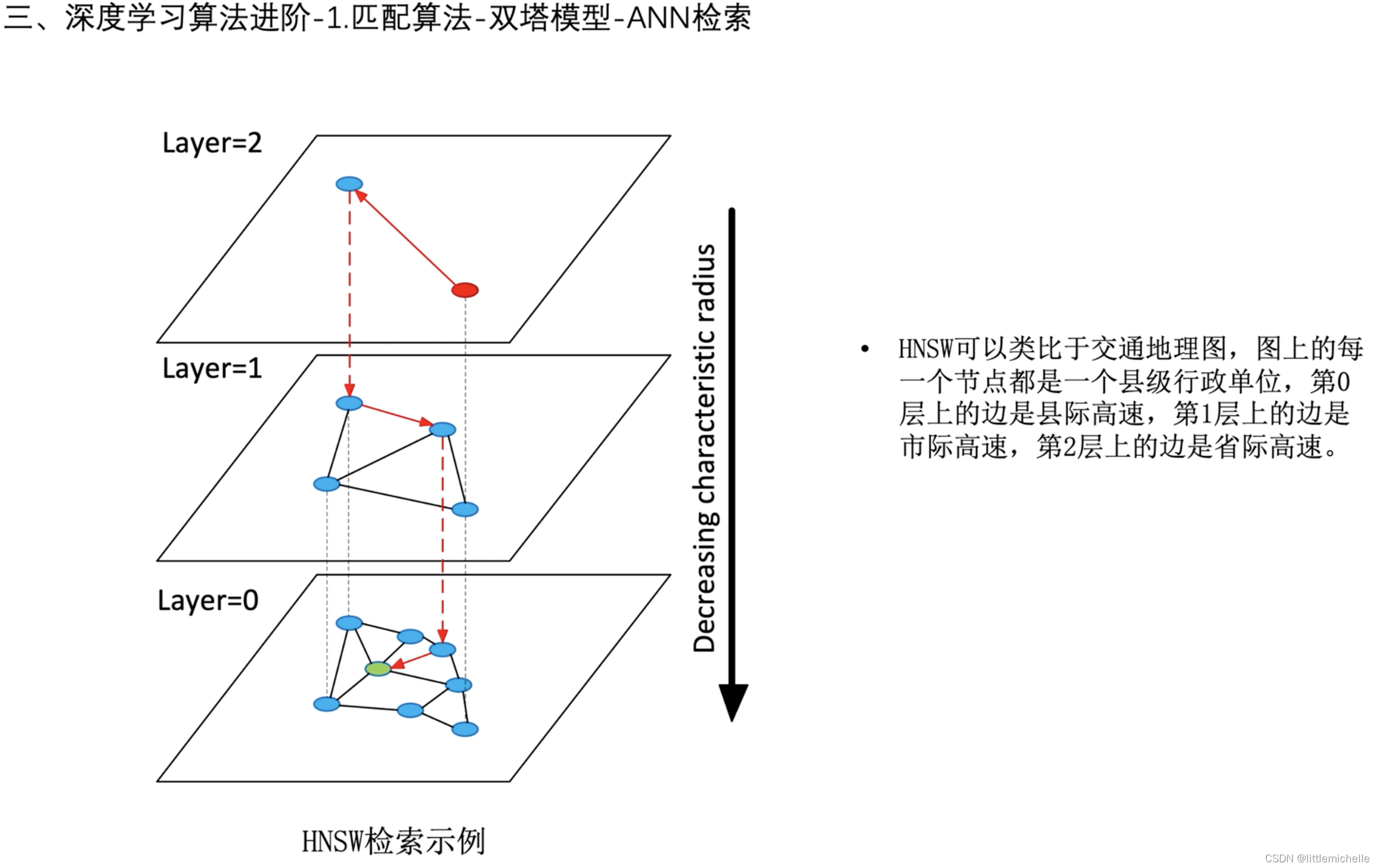
1-匹配算法-双塔模型-ANN 检索
 3.2-深度学习在搜索、广告、推荐系统中的应用-算法进阶-分阶段演进_哔哩哔哩_bilibili
3.2-深度学习在搜索、广告、推荐系统中的应用-算法进阶-分阶段演进_哔哩哔哩_bilibili
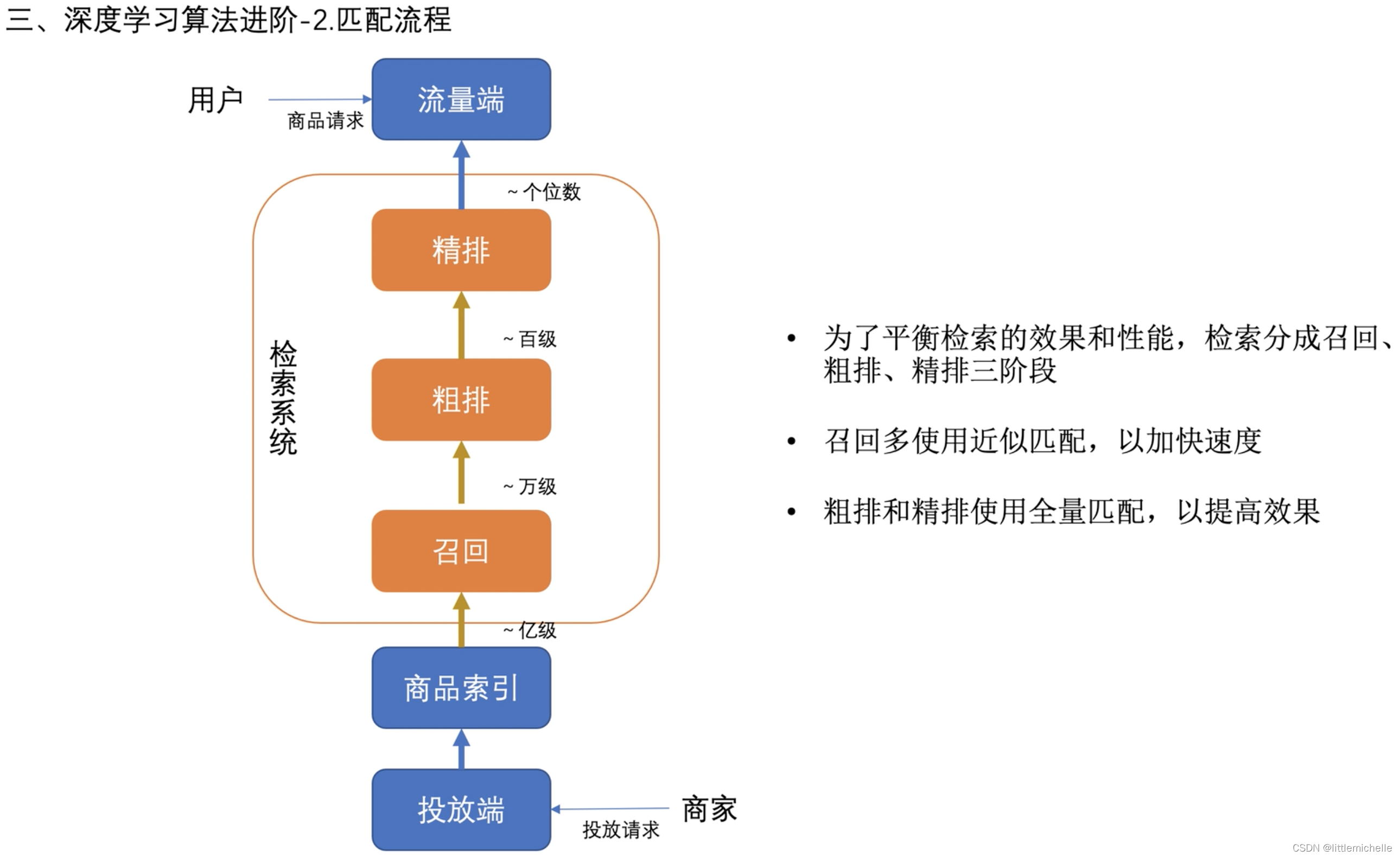
2-匹配流程
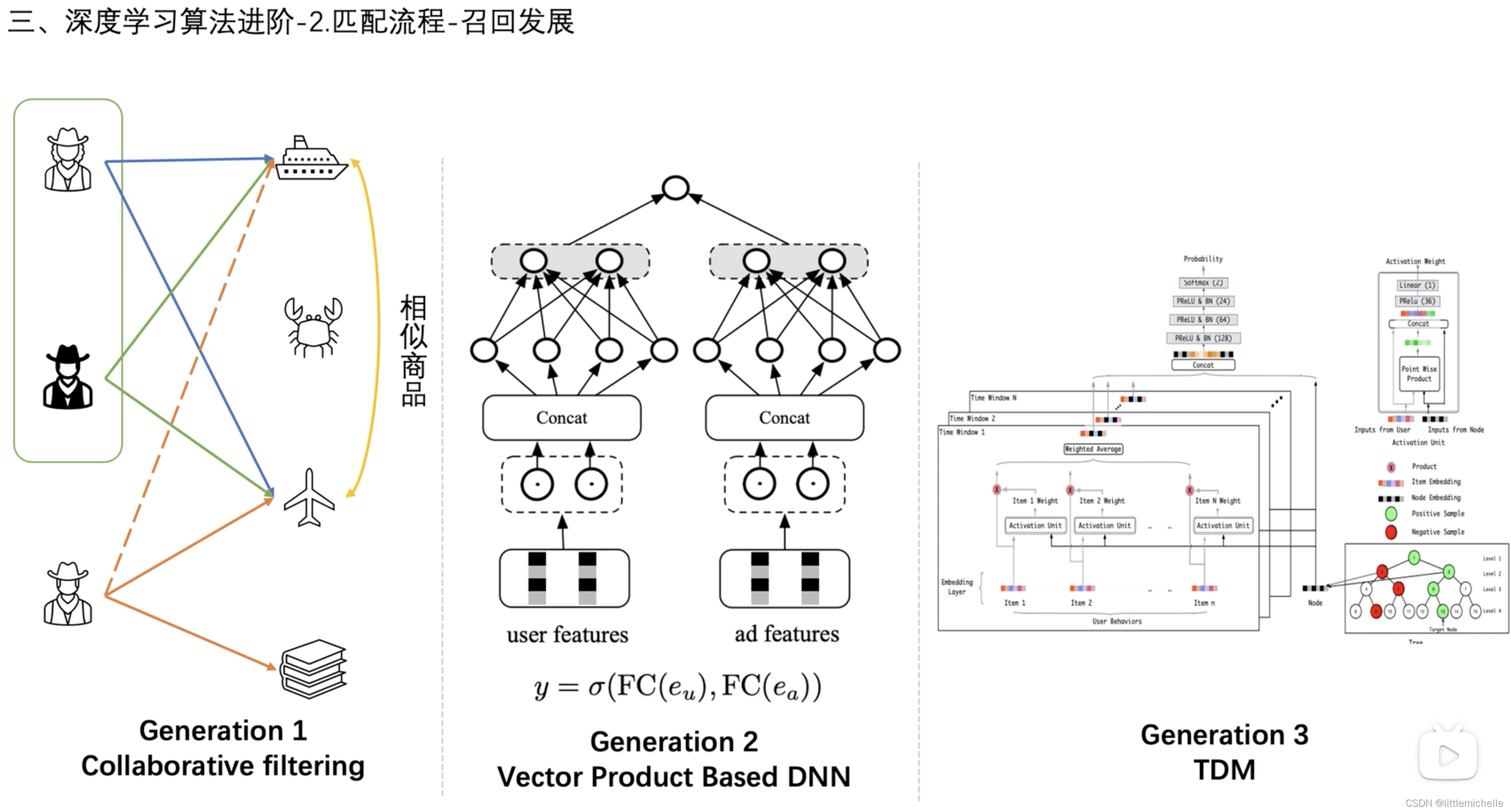
2-匹配流程-召回发展
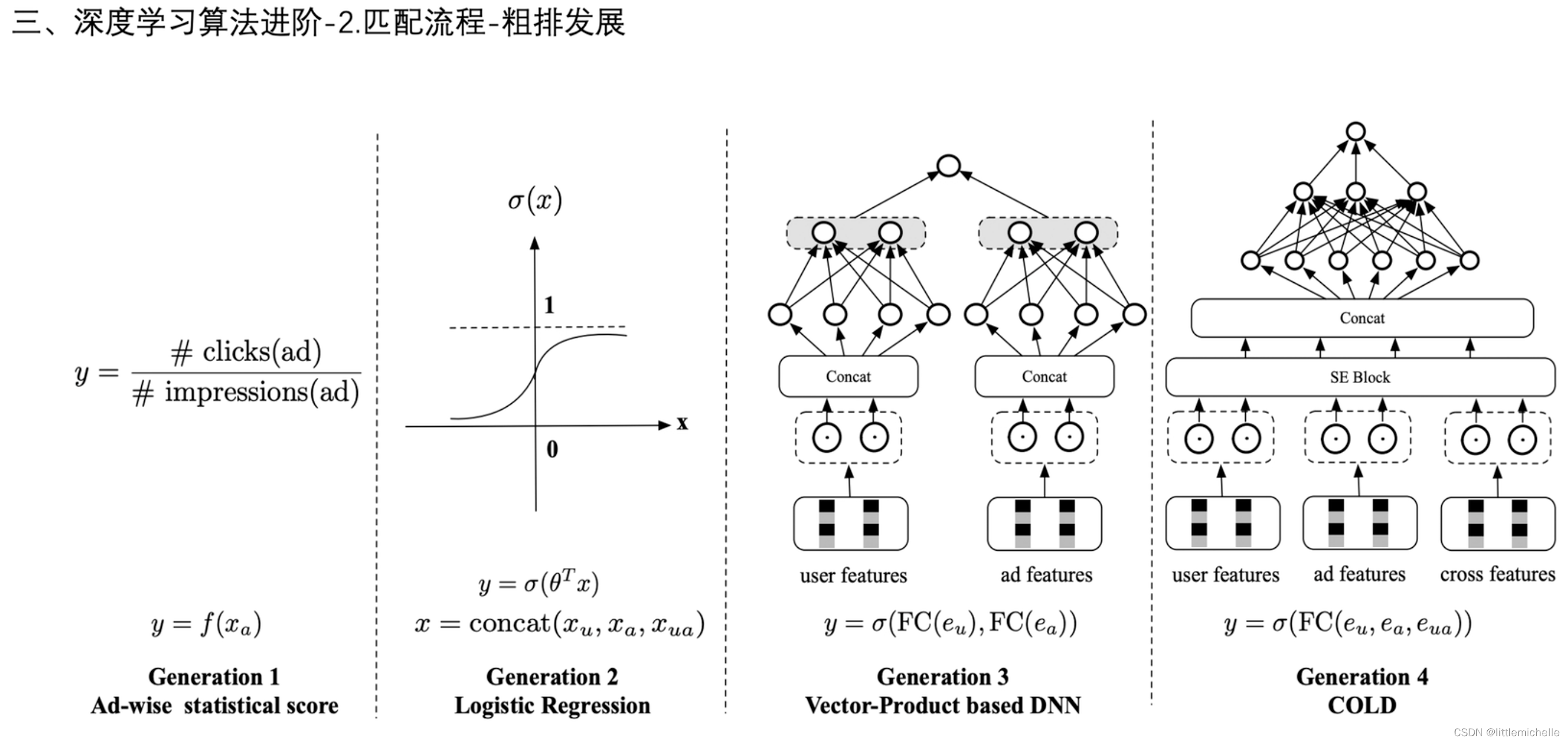
2-匹配流程-粗排发展
2-匹配流程-精排发展-1

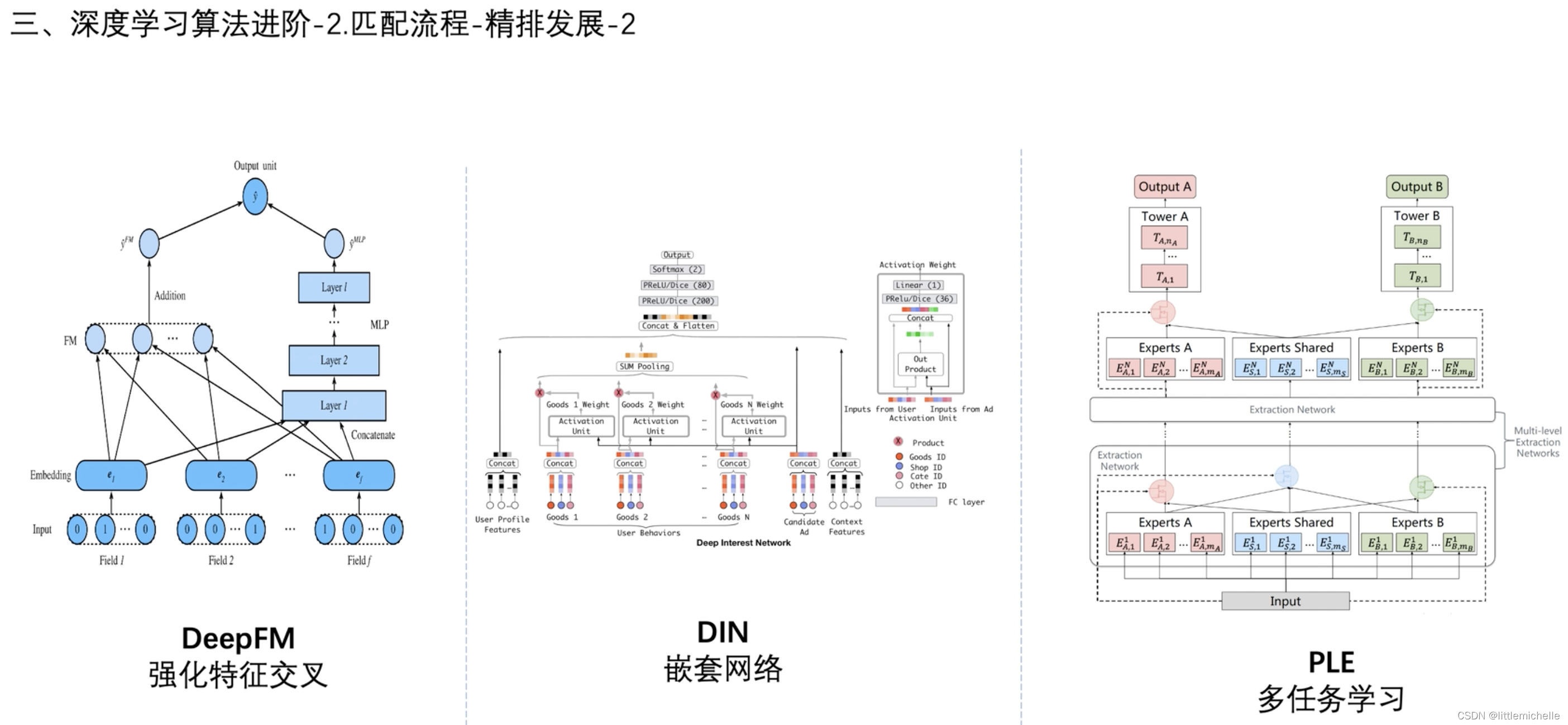
2-匹配流程-精排发展-2

















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









