






搬来了可学习的类激活方法,通过设计适当损失来迫使注意机制学习有效CAM输出,并只需一次前向推理。
论文链接:https://arxiv.org/abs/2209.11189
类激活图(CAM)致力于解释卷积神经网络的“黑盒”属性。本文首次提出可学习的类激活方法,通过设计适当损失来迫使注意机制学习有效CAM输出,并只需一次前向推理。在ImageNet上与流行类激活方法比较,取得了优异且有趣的实验结果。最后针对分类错误的情况,作者等人进行了细致而全面的分析。
类激活方法与Motivation简述
深度卷积神经网络对相关决策的可解释性不强,这种“黑盒”属性影响了该技术在安全、医疗等领域的商业应用。由类激活图(CAM)生成的显著图SM(saliency map)描述了对模型决策贡献最大的图像区域,因此是一种为“黑盒”提供可解释理论的方法。
以往的CAM方法分为基于梯度和基于扰动两种,如下图所示:
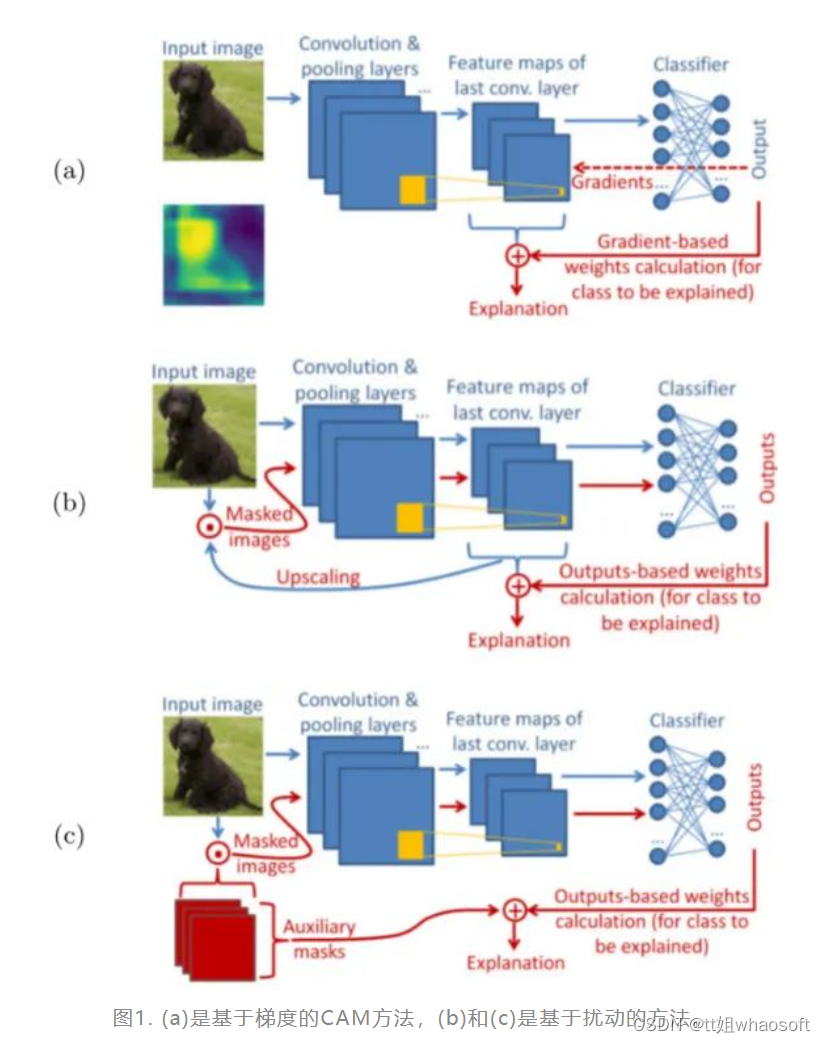
在图1 (a) 中,基于梯度的方法使用从outputs反向传播的梯度计算最后一个卷积层中特征权重,并将特征图加权聚合得到CAM,explanation代表由CAM产生的SM。(常见的有Grad-CAM、GradCAM++)
在图1 (b) 中,基于扰动的方法通常选取模型中不同深度的特征图,或随机扰动图(图1 (c) ),作为掩码与输入图像点乘,得到扰动输入,最后通过前向传递扰动输入来生成SM。(常见方法有SIDU、Score-CAM、SISE、ADA-SISE、RISE)
然而这些方法要么基于反向传播梯度,要么在推理阶段需要多次前向传递,因此引入了大量的计算开销。另外,这些方法在关注模型解释的同时,忽略了对训练集的有效利用。
因此本文提出了一种仅需一次前向传递的方法,同时引入注意机制,用可学习的方法,使训练集得到了充分利用。
可学习注意机制的理论推导——通俗易懂

接着,为有效训练注意机制的参数,将注意机制放在模型的最后卷积层的输出位置,并提出以下两种不同的学习方式,如图2和图3:
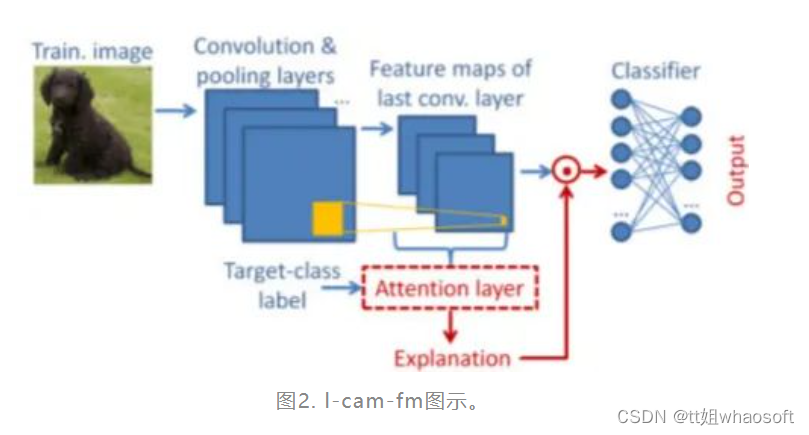
由注意机制得到的CAM与最后一次特征图元素点乘(做乘法前先用sigmoid归一化),以重新加权对应特征图的元素,其作用相当于一个自注意的“遮罩”,用来罩住或露出相应特征图的决策影响区域。
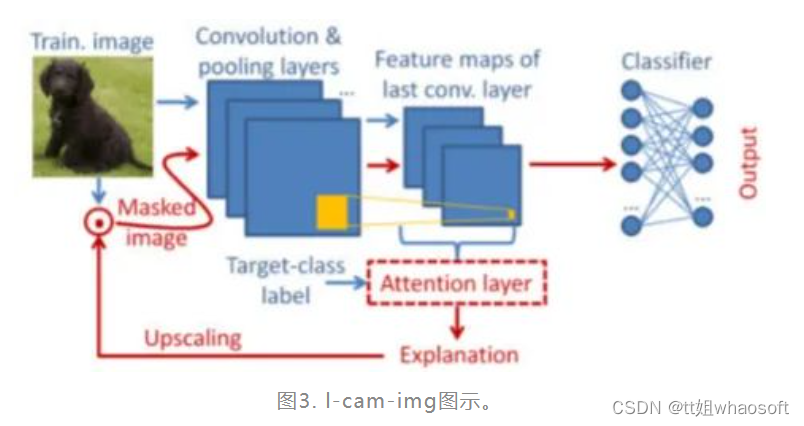
由注意机制得到的CAM被缩放到与输入图片一致的维度,sigmoid + 点乘运算后,其结果作为扰动图前向传递,相当于CAM被应用到了每个特征图的每个通道。
最后是本文方法的核心,上述两种方案通过梯度下降算法进行参数更新,在训练注意机制时,冻结原模型,即仅训练注意机制,从而使该方法适用于大部分卷积神经网络。在训练过程中,作者等人应用了所提出的以下损失函数:
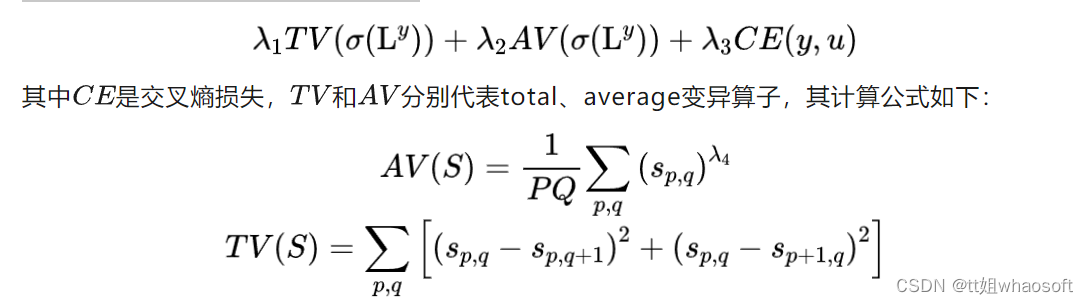
上述公式中,均为正则化参数,该损失函数的优化目标是:使总损失最小化,同时使不同的损失分量处于相同的数量级,从而确保所有损失分量对损失函数的贡献相似。在推理阶段,本文方法仅需一次前向传递,得到CAM后,与其他类激活方法一致,通过最小-最大归一化算子导出SM。
效果展示
对比方法基于VGG-16和ResNet-50两种模型,数据集为ImageNet。正则化参数皆凭在训练集上的经验选择,实验结果展示如下表:
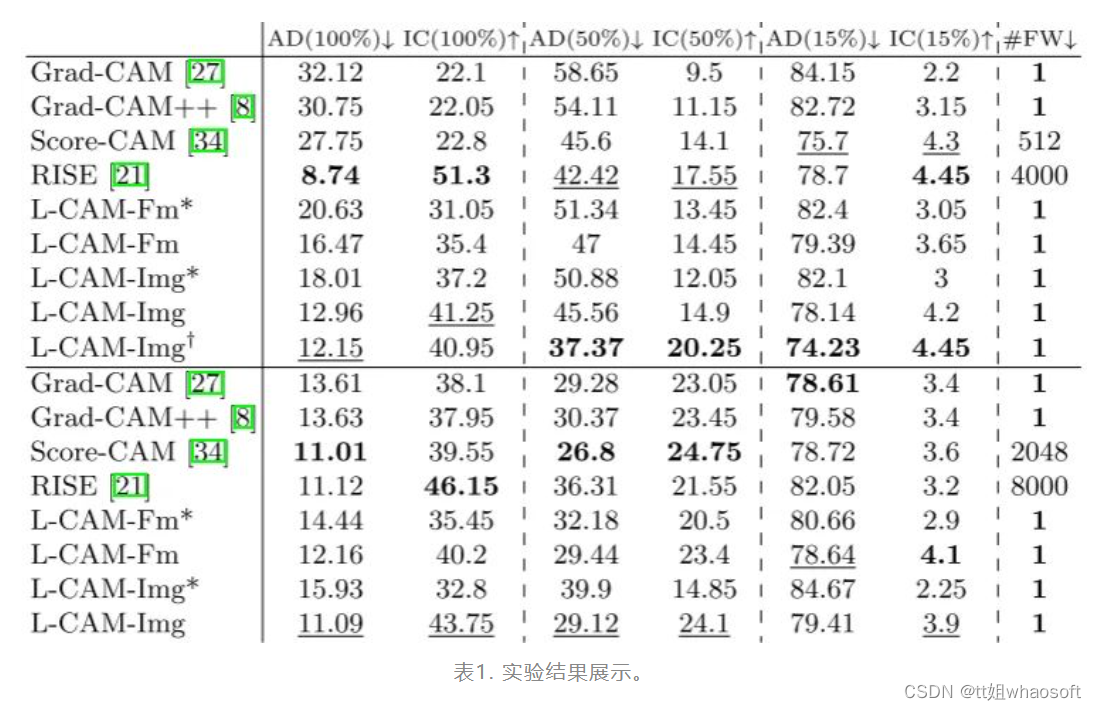
两个常用的性能评价指标:置信度增加 (IC) ,越大越好。平均下降 (AD),越小越好。一个复杂度评价指标:推理阶段的前向传递次数FW。
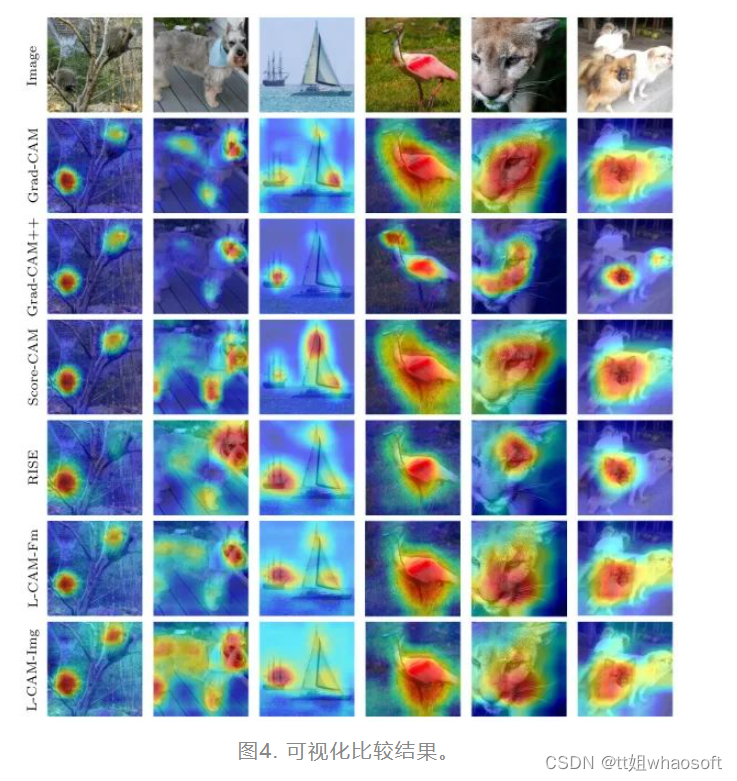
一些可视化的比较结果如下图所示:
错误类分析
在表1中可以明显看出本文方法在有些时候并非最优,然而一次前向推理的复杂度成为最大亮点。作者等人对该方法的错误分类原因进行了详细的探讨。
首先,ImageNet中许多类别实例在语义、外观上都非常接近,如下图所示:

如“goose”与“drake”,“coach”与“minibus”,这种情况下,本文方法得到的SM与真实标签所对应的SM是极其相似的,因此本文所提出的注意机制会聚焦于相同的图像区域,进而推断对应标签。
其次,单标签数据集ImageNet的某些图片包含了多个类别标签,而且这些标签在ImageNet的其他图片中已经确定存在。如下图所示:

比如图6中第一列,该图片对应的标签为“tennis ball”,然而在先前的训练中,本文方法已经确定了在ImageNet中存在的“Tibetan Terrier”这一标签,从而导致分类错误。
最后,ImageNet中的某些类别存在一些细微的偏差,如下图所示:

这种情况下,尽管真实标签为“rugby ball”,但由于分类器已经确定或学会了“rugby match”这一预测,因此在分类时会更偏向后者这一更广泛的标签。
本文为进一步解释“黑盒”模型,提出了一种可学习的CAM方法,并产生了具有竞争性的实验结果。但是有两个问题笔者不得其解。
第一个问题就是,本文方法通过训练集大量训练获得四个经验下的正则化参数,那么相比其他方法,是否存在额外增加了实现成本?另外,如果将此参数应用于其他数据集上是否能保持原有性能,到时候如果不能是不是又要重新从训练集中获取呢?
第二,对于ImageNet中的某些包含多标签图像,错误分类的原因是分类器已经对某些类别形成既定的学习认知。那么假如没有训练这个环节,是不是就能减少对某些已确定类别的错误识别呢,或者说,有没有其他方法能减少这种情况的发生呢。















 925
925

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









