






ST-MoE 的目的是设计稳定可迁移的稀疏专家模型。文章从稳定训练探索、微调性能假设、微调性能实践以及设计稀疏模型等多个方面为大家介绍稀疏专家模型。
ST-MoE 的目的是设计稳定可迁移的稀疏专家模型,做了这么几个工作:
1 对影响 MoE 模型训练质量-稳定性 trade-off 的一些稳定性技术做了大规模的研究。
2 引入一种 router z-loss,解决训练不稳定的问题,同时轻微提升模型质量。
3 Sparse 和 Dense 模型的微调分析,重点是超参数的分析。本文表明:不好的超参数使得 Dense 模型相比于 Sparse 模型几乎没有微调增益。
4 设计 Pareto Efficient 的稀疏模型的架构、路由和模型设计的原则。
5 token 路由决策的定性分析。
6 一个 269B 参数的稀疏模型 (计算代价与 32B dense encoder-decoder Transformer 接近,因此取名为 Stable Transferable Mixture-of-Experts, ST-MoE-32B),在多个自然语言处理任务中实现 SOTA 性能。
1 ST-MoE:设计稳定可迁移的稀疏专家模型
论文名称:ST-MoE: Designing Stableand Transferable Sparse Expert Models
论文地址:https//arxiv.org/pdf/2202.08906.pdf
- 1 ST-MoE 论文解读:
1.1 背景:提高稀疏模型的实用性和可靠性
稀疏专家神经网络 (Sparse expert neural networks) 是一种在保证模型训练和推理的成本不显著增加的情况下,大幅度提升模型容量的方法,这种方法可以说很好地体现了大模型的优势,并为当今常用的静态神经网络架构提供了有效的替代方案。
这种方法的特点是:不是对所有输入应用相同的参数,而是动态选择每个输入使用哪些参数。这就可以使得我们极大地扩展模型的 Param.,同时保持每个 token 的 FLOPs 大致恒定。但是,稀疏专家神经网络的缺点之一是其上游预训练和下游微调任务性能之间存在差异,比如在 Switch Transformer[1]里面,作者训练了一个 1.6T 参数量的稀疏模型,但是在 SuperGLUE 等常见基准上进行微调时,其性能却落后于较小的模型。
因此,本文的目的是提高稀疏模型的实用性和可靠性,并为稀疏专家模型提出了额外的分析和设计指南。
1.2 MoE 基本概念汇总
稀疏专家模型 (MoE) 通常是使用一组 Expert 来替换一个神经网络层,每个 Expert 都有各自的权重,输入不是被所有的 Expert 处理,而是只会被一部分 Expert 来处理。因此,必须添加一些机制来决定该把每个输入送给哪个 Expert。一般来讲,会有一个 路由器 (router) 或者门控网络 (gating 网络) 来解决这个问题。
在自然语言处理里面,混合专家层 (Mixture-of-Experts, MoE) 的输入是 token x ,然后使用 router 把它分配 (route) 给最合适的 k 个 Expert。
router 的做法是这样:

下面是关于 MoE 的一些术语的解释:
术语 | 定义 |
Expert | 通常是一个 MLP 网络,每个 Expert 的权重独立 |
Router | 计算每个 token 发送到每个 Expert 的概率的网络 |
Top-n Routing | 是一个路由算法,每个 token 被发送到 n 个 Expert |
Load Balancing Loss | 鼓励每一组 token 被均匀分发给各个 Expert 的辅助损失函数,有利于加速器并行处理数据块来提高硬件效率 |
Group Size | 全局批量大小被分成更小的 Group。每个 Group 被考虑用于 Expert 之间的负载平衡。增加它会增加内存、计算和通信 |
比如 Batch Size 为 B,Group 数量为 G,则每个组有 B/G token | |
Capacity Factor (CF) | 每个 Expert 只能处理固定数量的 token,Capacity 常是通过均匀地划分 Expert、token 的数量来设置的:Capacity=token/Expert。但是有些时候可以通过设置 CF 来改变 Capacity,使之变为:CF×token/Expert |
如果 CF 增加,会创建一些额外的 Buffer,当负载不平衡时丢弃更少的 token。但是,增加 CF 也会带来额外的内存和计算的开销 | |
FFN | 线性层,激活函数,线性层 |
Encoder-Decoder | Transformer 架构的变体,由 Encoder 和 Decoder 组成,Encoder 的注意力机制会 Attention 所有的 token,Decoder 的注意力机制是自回归的方式 |
1.3 稀疏模型的稳定训练探索1:结构上的微调
如下图1所示,稀疏模型通常会受到训练不稳定性的影响,比标准 Dense 的 Transformer 中稳定性更差。
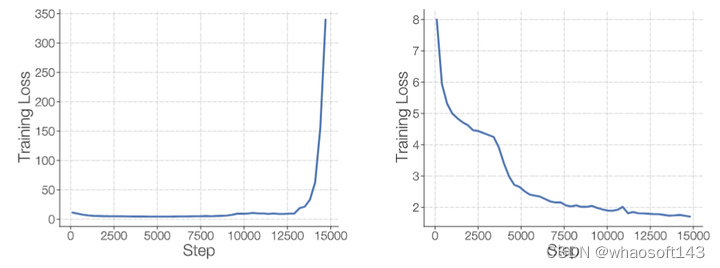
图1:左:不稳定的稀疏模型训练。右:稳定的稀疏模型训练
下面作者介绍了一些 Transformer 模型的改进,这些改进会提高 MoE 模型的质量,但是会影响训练的稳定性。
1 GELU Gated Linear Units (GEGLU)
就是使用 GELU 激活函数:

作者在图2中通过实验表明,去掉 GEGLU 层,或者是 RMS scale 参数都会提升训练的稳定性,但是会很大程度地影响模型的质量。

图2:去掉 GEGLU 层,或者是 RMS scale 参数的结果
1.4 稀疏模型的稳定训练探索2:训练时加噪声

可以发现:输入抖动和 Dropout 都提高了稳定性,但会导致模型质量显着下降。
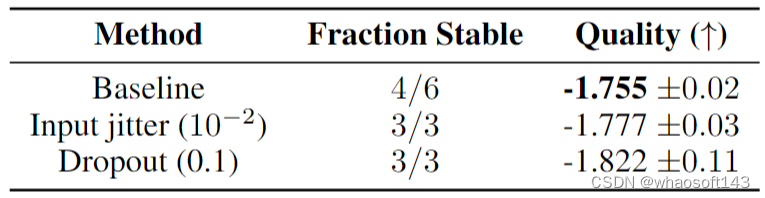
图3:训练时加噪声的实验结果
1.5 稀疏模型的稳定训练探索3:Router Z-Loss
作者在训练 ST-MoE 的时候使用了3个目标函数的加权混合:



1.6 稀疏模型的微调性能假设:一个泛化性问题
性能最好的语言模型通常是通过 (1) 对大量数据 (如互联网数据) 进行预训练然后 (2) 对感兴趣的任务 (如 SuperGLUE) 进行微调来获得的。
作者对稀疏模型的泛化性能做了一个假设,即:稀疏模型容易过拟合,通过 SuperGLUE 中的 Commitment Bank 和 ReCORD 两个任务来说明这个问题。Commitment Bank 有 250 个训练样本,而 ReCORD 有超过 100,000 个,很适合研究这个问题。
如下图4所示,作者比较了 Dense L 和 ST-MoE-L 模型的微调性能。每个模型都对来自 C4 语料库的 500B 个标记进行预训练,这两个模型的 FLOPs 与 770M 参数的 T5-Large encoder-decoder 大致接近。ST-MoE 模型有 32 个 Expert,Expert 频率为 1/4 (每4个 FFN 层被 MoE 层替换)。
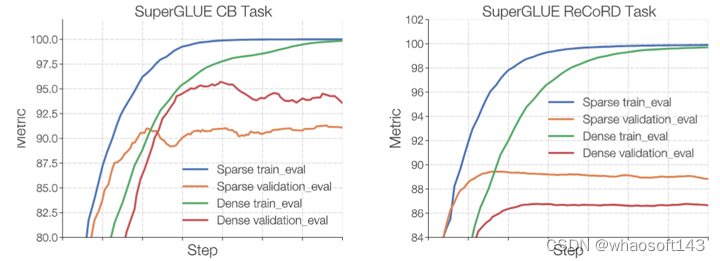
图4:稀疏模型更容易过拟合
实验结果如上图4所示。可以看到不论是使用更大的数据集 ReCORD,还是更小的数据集 Commitment Bank,稀疏模型都比对标的密集模型更快地实现训练精度 100%。但是对于小数据集 Commitment Bank,密集模型的验证集微调性能更好,对于大数据集 ReCORD,稀疏模型的验证集微调性能更好。
这说明,稀疏模型在小数据集上面的泛化性能有待加强。
1.7 稀疏模型的微调性能实践1:微调参数的子集提升泛化性
为了对抗过度拟合,作者尝试在微调期间仅更新模型参数的子集,分别尝试了这么几种:更新所有参数,只更新非 MoE 参数,只更新 MoE 参数,只更新 Self-Attention 参数和 Encoder-Decoder 的 Attention 参数,只更新非 MoE 的 FFN 参数。实验结果如下图5所示,只更新 MoE 参数的效果是最差的,其他的效果都差不多。而只更新非 MoE 参数可能是加速和减少内存进行微调的有效方法。
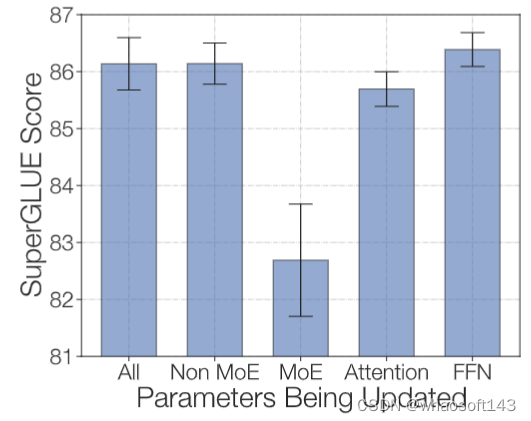
图5:微调参数的子集的实验结果
1.8 稀疏模型的微调性能实践2:微调策略的影响
作者希望探究稀疏和密集模型对微调协议的敏感性,因此研究了2个超参数:Batch Size 和学习率。作者在 C4 的500B 令牌上预训练 Dense-L 和 ST-MoE-L,然后在 SuperGLUE 上进行微调,实验结果如下图6所示。稀疏和密集模型在不同的 Batch Size 和学习率之间具有截然不同的性能。
稀疏模型受益于较小的 Batch Size 和更高的学习率。与过拟合假设一致,这两种变化都可能在微调期间通过更高的噪声来提高泛化能力。
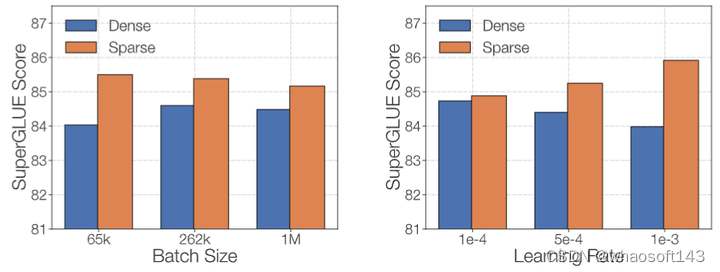
图6:微调策略对稀疏模型和密集模型的影响
1.9 设计一个稀疏模型
作者给出了一些设计稀疏模型的结论,为了叙述方便这里直接说结论了:
- 推荐使用 top-2 routing,即每个 token 给2个 Expert 处理,Capacity Factor 设置为 1.25。
- 在评测过程中可以改变 Capacity Factor,以适应新的内存/计算要求。
- 在每个稀疏层之前或之后使用 Dense FFN 可以提高模型质量。
1.10 实验结果
作者设计和训练 269B 稀疏参数模型 (FLOPs 与 32B 密集模型匹配)。评测的基准是 SuperGLUE benchmark,它包含下面这些子任务:
- sentiment analysis (SST-2)
- word sense disambiguation (WIC)
- sentence similarity (MRPC, STS-B, QQP)
- natural language inference (MNLI, QNLI, RTE, CB)
- question answering (MultiRC, RECORD, BoolQ)
- coreference resolution (WNLI, WSC)
- sentence completion (COPA)
- sentence acceptability (CoLA)
模型架构的配置:
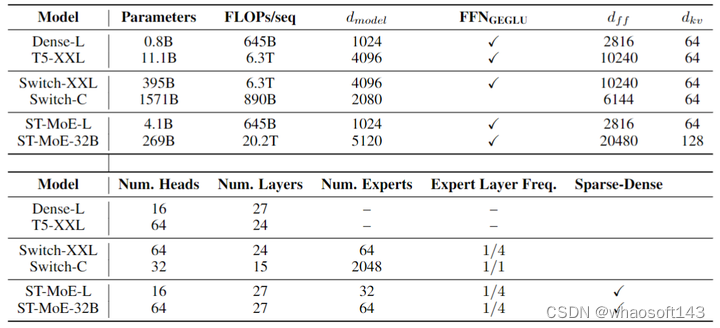
图7:模型架构配置
如下图8所示是 ST-MoE-L 模型实验结果。模型是稀疏和密集的 T5-Large (L),在 C4 数据集上预训练 500k steps。可以观察到,在大多数任务上面 ST-MoE-L 模型都取得了提升。
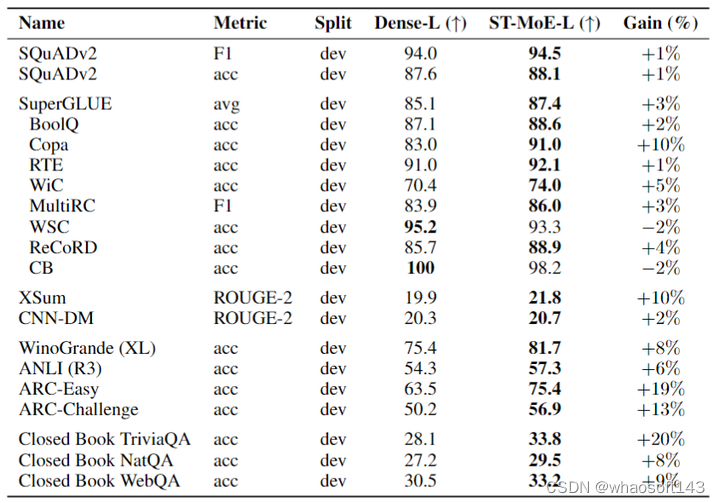
图8:ST-MoE-L 模型实验结果
ST-MoE-32B 模型的训练数据集是图9,一共 1.5T tokens,每个 Batch 是 1M tokens,优化器默认使用的是 Adafactor,10k steps 的学习率 warm-up,学习率 scheduler 是 inverse square root decay。
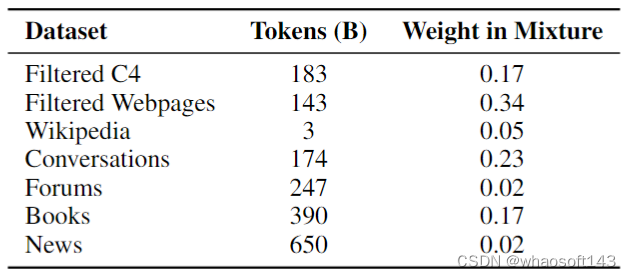
图9:ST-MoE-32B 模型预训练数据
实验结果如下图10所示。在 SuperGLUE 上,ST-MoE-32B 模型超过了之前最先进的模型,在测试集上实现了 91.2 的平均分数。对于摘要数据集 XSum 和 CNN-DM,ST-MoE-32B 模型实现了 SOTA 的性能,而无需对训练或微调进行额外的更改。在3个 closed book QA 任务中的2个上,ST-MoE-32B 模型改进了之前的最新技术,分别是 Closed book WebQA 和 Closed book NatQA。
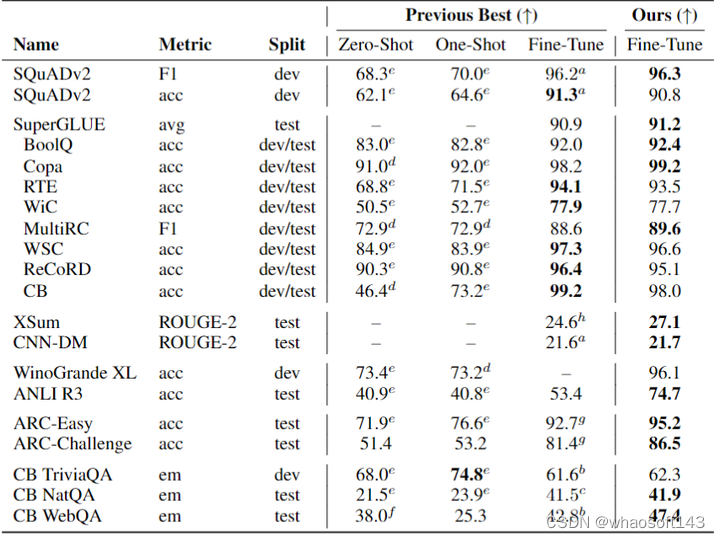
图10:ST-MoE-32B 模型实验结果
但是,ST-MoE-32B 的模型还是有一些缺点的,比如在小一点的数据集 SQuAD 上面的性能是 90.8,并未超过之前的 91.3。同样的小数据集 CB, WSC, ReCoRD 的性能也是同样如此。Closed Book Trivia QA 的性能也没能达到最好。















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









