






简介:论文提出一种新的视觉里程计算法,其直接利用带噪声的IMU数据和视觉特征位置来优化相机位姿。不同于对IMU和视觉数据运行分离的滤波器,这种算法将它们纳入联合的非线性优化框架中。视觉特征的透视重投影代价函数以及从IMU和位姿轨迹得到的加速度和角速度运动代价函数被联合优化。
一、算法的整体框架
文中提出的在线VIO算法,其限制优化窗口只包括最近的观测和参数。随着窗口尺寸的变化,估计精度和计算成本之间的权衡就会出现。这种算法属于利用优化框架的基于关键帧的方法,与之前方法相反的是,不边缘化之前的状态并优化局部窗口内的所有位姿。其主要的贡献是设计了局部优化代价函数,它不仅高效,而且尽可能的保证精度。算法的主要流程如下图:
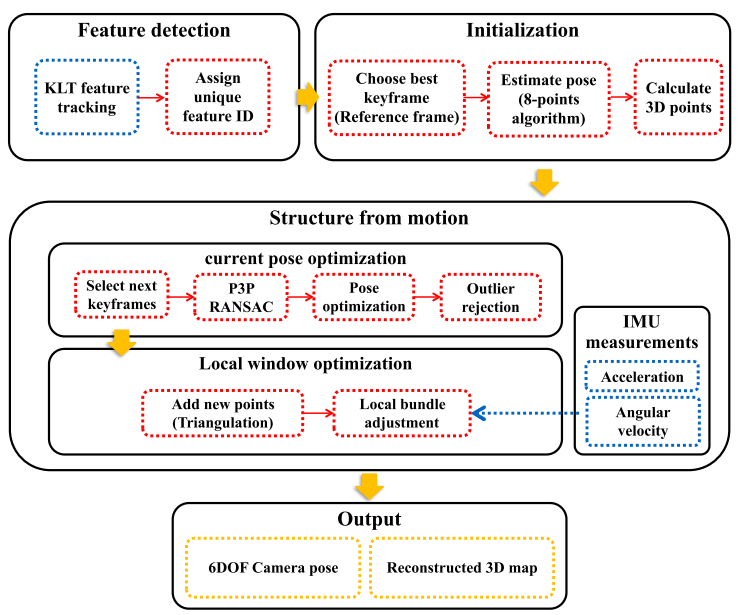
传统的视觉里程计系统包括特征捕捉、位姿估计和滤波或优化步骤。特征点的检测与跟踪贯穿于所有输入帧,然后帧(或者关键帧)之间的相机运动从特征运动计算出来。可视的特征被保留为3D路标,并且它们被用于计算或提高相机轨迹。文中提出的算法遵循了视觉里程计的基本步骤,并且融合了来自IMU的加速度和角速度测量值。
二、算法细节
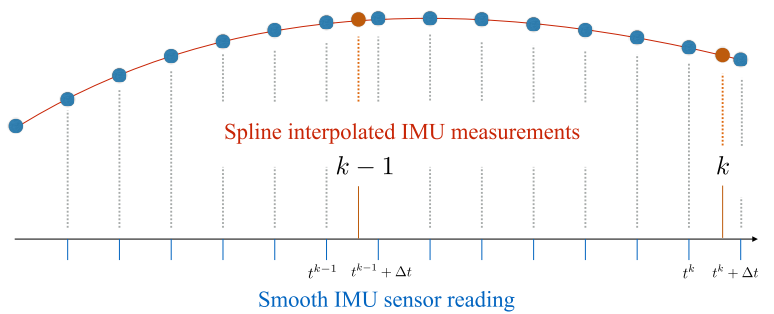
利用IMU数据存在几个问题,首先是IMU数据的获取频率与视频帧率不一致,并且远高于视频帧率。我们利用相机帧数k表示设备运动的参考时间索引。由于IMU测量频率远高于帧率,假设加入的IMU测量值(tk+∆t)紧接着帧k。独立的加速度和角速度Kalman滤波器被用来减轻传感器读数中的噪声,并且我们用样条内插法来计算在相机帧处的同步的IMU估计值(如下图)。IMU读数带有偏差并且必须对它们精准的建模和估计以避免偏移。不同于在滤波框架中对偏差进行建模,在优化中,偏差参数和相机位姿以及路标位置一起通过完整地利用视觉特征观测进行估计。
单目视觉里程计只能估计相机运动到尺度,在视觉惯性里程计中,来自IMU的加速度数据可以被用来确定度量尺度。然而IMU只提供带噪声的设备的加速度测量值,恢复移动的距离必须被双重积分。并且,原始的IMU加速度数据包括重力,其必须被消除以正确计算运动,这需要精确的垂直方向估计。
A、数学公式
相机在t时刻的六自由度位姿pt表示成旋转和位移矢量(rtT, ttT)T 。3×3旋转矩阵Rt可以和rt相互转换:Rt = R(rt)并且rt = rot(Rt)。相机位姿和路标位置在大地坐标系其z轴平行于重力方向。 IMU测量的加速度$\mathbf{\hat{a}}_t$包含重力和偏差。其在载体坐标系中。为了计算在大地坐标系下的加速度at,加速度偏差$\mathbf{\hat{b}}_t$ 和重力g必须被适当的减掉:
![]()
从三个利用视觉特征计算出的相机位姿,我们也可以计算加速度$\mathbf{\bar{a}}_t$ 如下:
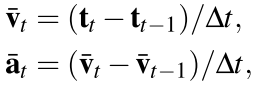
其中,Δt是两连续帧之间的时间。在我们的优化框架中的加速度误差即为从视觉特征得到的加速度和从IMU得到的加速度之间的差别:
![]()
角速度$\mathbf{\hat{ω}}_t$也通过IMU测量出来,并且角速度在大地坐标系下为:
![]()
其中,$\mathbf{\hat{b}}_t$是陀螺仪偏差。来自视觉特征的角速度$\mathbf{\bar{ω}}_t$ 为:
![]()
因而角速度误差$\mathbf{e}^ω_t$可以被定义为:
![]()
最后,重投影误差$\mathbf{e}^{proj}_{i,j}$通过利用相机位姿pj和路标xi位置计算:
![]()
其中,proj(x;p)是3D点在相机位姿p的投影图像坐标,并且fi,j是图像j中路标i的特征位置。
B、批量优化(用来做对比)
当视频帧和IMU测量值已知时,我们可以计算使得以上误差最小的相机轨迹。对于IMU读数$\{\mathbf{\hat{a}}_t, \mathbf{\hat{ω}}_t\}_T$以及跟踪的特征集合F = {fi,j},批量优化的代价函数为:

在相机位姿p1, …, pT,路标x1, …, xT,和偏差ba, bω处优化。||·||Σ是Mahalanobis距离,协方差为Σ。在论文中,协方差设为固定的方差$\mathbf{σ}_f^2, \mathbf{σ}_a^2, \mathbf{σ}_ω^2$的对角协方差矩阵。批量优化算法的结果显著地优于任何在线算法。批量优化可以生成最准确的结果,但是其要求所有的数据在处理之前就准备好,并且其需要长时间来收敛。
C、在线优化(滑动窗口法)
考虑应用目的,VIO必须能够实时地输出当前的相机位姿。为达到此目的,论文提出了简化的批量优化版本。在大多数视觉里程计系统中,当运动或视觉内容存在存在显著的改变时,选为关键帧。重投影误差项仅仅建立在关键帧和路标上。我们采取用了惯例,并利用关键帧来生成路标和位姿优化。在每一帧,相机位姿利用3维路标的图像位置计算出来,并且当相机移动较为明显时,帧被初始化为关键帧。建立在关键帧上的特征轨迹在优化中提供了足够多的相机位姿和路标位置上的约束。
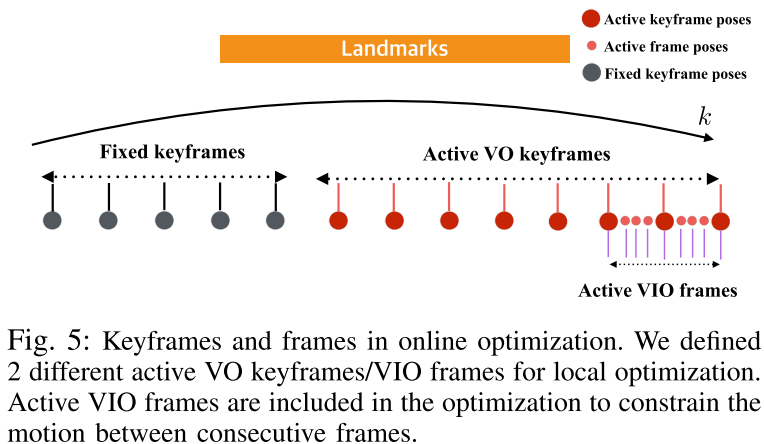
然而如果IMU测量值在关键帧之间平均可能就成问题,因为关键帧比帧更加稀疏。最近的一些关键帧之间的帧被包含在优化中以约束连续帧之间的运动。这些活动的VIO帧用惯性约束连接了关键帧。这些帧的特征位置没有在优化中利用,因为这样会增加计算成本,并且连续帧之间的特征运动并不明显。当关键帧添加后,在线优化在活动的VO关键帧Ka和活动的路标La以及活动的VIO帧Ta上执行:

其中Kf是固定VO关键帧,它被用来强制路标位置与局部优化窗口之外的观测保持一致。VIO在线优化过程概括如下:

D、实施细节
- 前端:对于VO或VIO系统,通常要么采用快速二进制描述子比如BRIEF或ORB,或者特征跟踪器比如KLT。论文采用Harris角点检测子和KLT用于特征跟踪。
- 初始化:绝对尺度可以从IMU数据恢复,但是在初始化期间只存在有限数量的带噪声的IMU数据。论文选择的初始化策略是:首先利用可得到的数据(视觉信息)大致正确地初始化模型,然后在在线优化过程中利用即将到来的测量值更新模型。为了确定初始尺度因子s首先通过积分IMU数据计算出最开始的两个关键帧之间的实际移动距离dIMU:
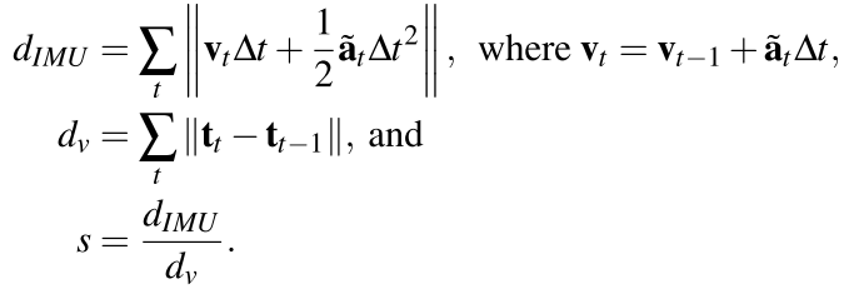 计算出的尺度s乘以相机和路标的位置,然后在两个关键帧以及关键帧之间的所有帧上执行在线优化以得到更加准确的初始化。
计算出的尺度s乘以相机和路标的位置,然后在两个关键帧以及关键帧之间的所有帧上执行在线优化以得到更加准确的初始化。















 1420
1420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









