








一、自动编码器
自编码器是一种能够通过无监督学习,学到输入数据高效表示的人工神经网络。输入数据的这一高效表示称为编码(codings),其维度一般远小于输入数据,使得自编码器可用于降维。更重要的是,自编码器可作为强大的特征检测器(feature detectors),应用于深度神经网络的预训练。此外,自编码器还可以随机生成与训练数据类似的数据,这被称作生成模型(generative model)。比如,可以用人脸图片训练一个自编码器,它可以生成新的图片。
1、个人对于自动编码器用于无监督学习的理解
通过自己的学习理解,认为自动编码器的实现无监督学习的途径是这样的,首先以图片为例,对于一个图片先压缩,使其变模糊,再根据变模糊的图片去恢复成原来的图片,因为在训练过程中是没有其他的标签的,所以训练的数据既是数据又是标签。
对于一个压缩的过程,可以看作通过神经网路进行特征提取,然后再通过这个提取的特征去恢复成原来的图像,那么训练过程的意义就是为了训练网络中的参数来实现这个过程。
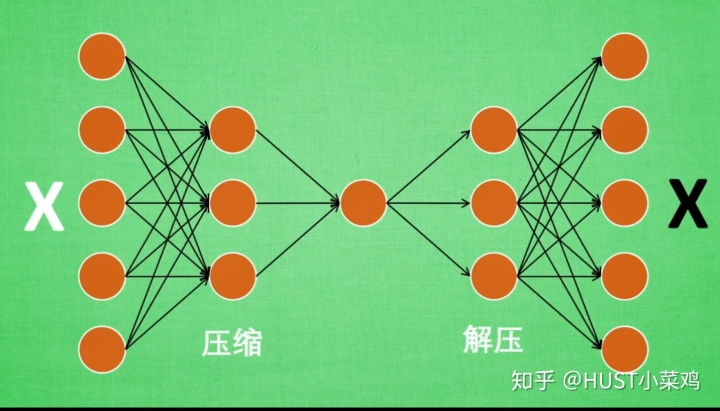
因为原图像可能很大,通过编码的过程可以提取指出图像的主要特征,对原信息进行缩减,在把缩减的信息送入神经网络进行学习,这样可以大幅度降低网络的计算成本。
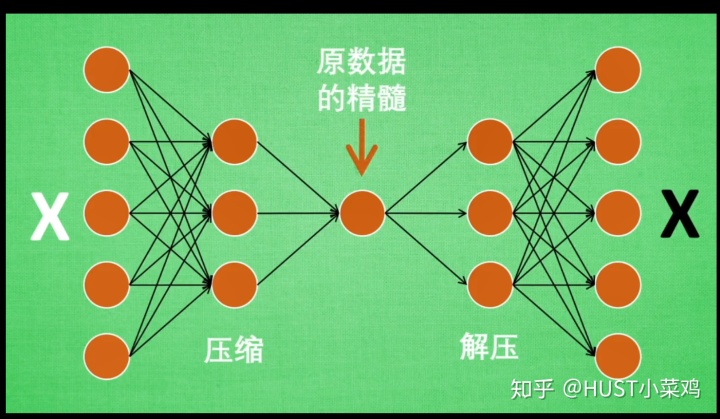
自编码器主要用到网络的前半部分,因此这一部分也被称作是编码器。
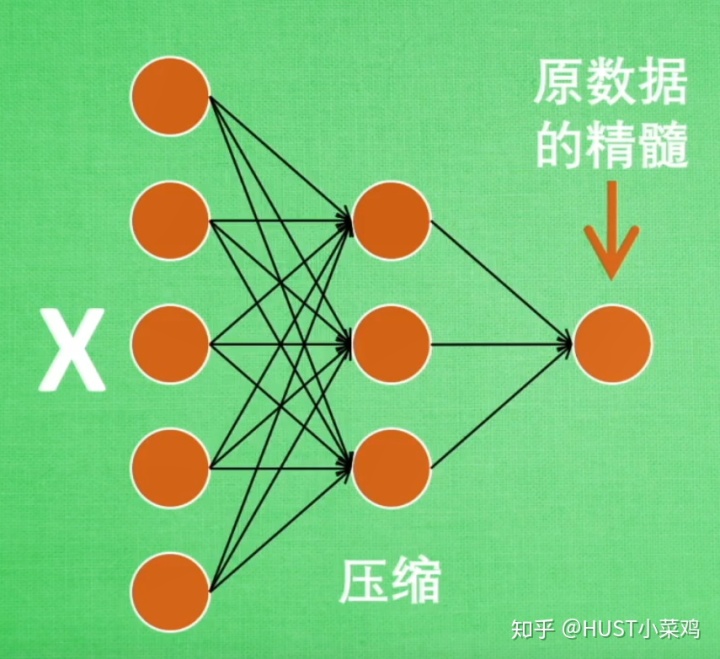
2、自编码器网络的搭建
导包及超参数的设置
import torch
import torchvision
import torch.utils.data as Data
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
import time
starttime = time.time()
torch.manual_seed(1) #为了使用同样的随机初始化种子以形成相同的随机效果
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005
N_TEST_IMG = 5训练集的导入及测试
train_data = torchvision.datasets.MNIST(
root='MINIST',
train=True,
transform=torchvision.transforms.ToTensor(),
download=False
)
loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# print(train_data.train_data.size())
# print(tra 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









