






第九章
聚类任务
聚类任务,简而言之就是无监督学习,训练数据没有标签,目的是为了分类。
无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
常用的无监督学习算法主要有主成分分析方法PCA等,等距映射方法、局部线性嵌入方法、拉普拉斯特征映射方法、黑塞局部线性嵌入方法和局部切空间排列方法等。
聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
分类和聚类的区别
分类简单来说,就是根据文本的特征或属性,划分到已有的类别中。也就是说,这些类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类。而聚类的理解更简单,就是你压根不知道数据会分为几类,通过聚类分析将数据或者说用户聚合成几个群体,那就是聚类了。聚类不需要对数据进行训练和学习。分类属于监督学习,聚类属于无监督学习。
聚类的方法
一般来讲,聚类有三种方法:
- 原型聚类
- 密度聚类
- 层次聚类
性能度量
聚类性能度量也称作聚类“有效性指标”,用于评估聚类的好坏。
聚类的性能度量大致有两类,一个是聚类结果与某个参考模型进行比较,称为“外部指标”。另一类直接考察聚类结果而不利用任何参考模型,称为内部指标。
常用的外部指标:
- Jaccard系数
- FM指数
- Rand指数
距离计算
距离计算用于衡量样本间的相似度。与我们常见的距离计算类似。
比较常用的是闵科夫斯基距离。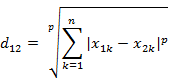
当p=1时 即曼哈顿距离。
当p=2时 即最直观的欧氏距离。
还有一些距离,如内积距离等。
以上这些距离都用于衡量有序属性。对于无序属性需要自行定义,可采用VDM距离。
K-means算法
主要思想
K-means算法的主要思想是,预先定义k个聚类中心,然后训练时对于每个样本,都标定与其最近的那个聚类中心,然后更新每个聚类中心的位置为属于该聚类中心的所有样本点的均值。然后不断迭代,直到聚类均值向量稳定,或者小于一定误差,从而对样本进行聚类。
簇数的选择
部分可以用“肘部法则”,更多的需要根据实际问题,人工地做出选择。
初始均值向量的选择
初始均值向量可以随机选择k个样本点,将这几个样本点作为初始均值向量进行迭代。
如何防止局部最优
选择不同的初始点作为初始均值向量,迭代运行K-means算法,然后在多次运行结果中,选择最好即代价误差最小的结果,作为算法的最终结果。从而找到全局最优解。
算法流程

学习向量量化
LVQ与K-means算法类似,也是试图找到一组原型向量来刻画聚类结构。但不同的是,LVQ可以借助样本的标记来辅助学习。
与K-means类似,LVQ也是不断迭代,最后得到最优的解。
流程如下
LVQ算法同样人为设定一个t值,也就是要划分的类别数。然后初始化t个原型向量——不是像k-means一样随便选,而是根据预先说好了的标记,在随便选。比如预先说好要选3个好瓜,2个坏瓜,就从好瓜中随便选三个,坏瓜中随便选两个。
选好初始原型向量后,开始和k-means一样不断循环计算距离,不过LVQ每次都是随机抽取训练数据集的一个样本,计算抽到的样本和各个原型向量的距离。距离最短的一个原型向量,如果其标记和抽到的标记一样,就“使原型向量向抽到的样本向量靠近”,如果其标记和抽到的标记不同,就“使原型向量向抽到的样本向量远离”——
如此循环往复直到达到最大循环次数,或者原型向量的调整幅度已经小于某个阀值。
密度聚类
基于密度的聚类算法主要的目标是寻找被低密度区域分离的高密度区域。与基于距离的聚类算法不同的是,基于距离的聚类算法的聚类结果是球状的簇,而基于密度的聚类算法可以发现任意形状的聚类,这对于带有噪音点的数据起着重要的作用。
密度聚类算法通常从样本的密度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇以获得最终的结果。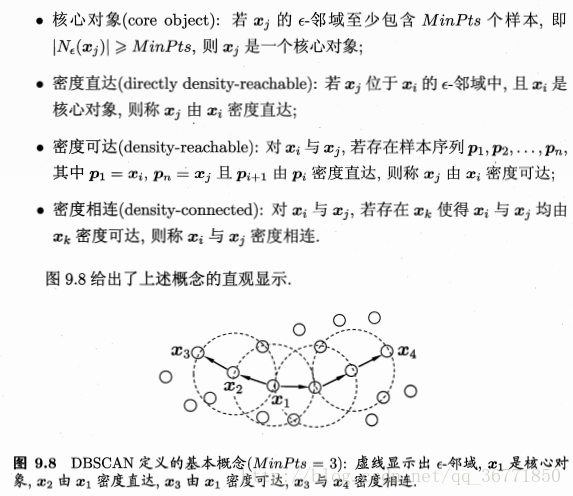
DBSCAN可以获得边界任意形状的簇。
层次聚类
层次聚类方法的基本思想是:通过某种相似性测度计算节点之间的相似性,并按相似度由高到低排序,逐步重新连接个节点。该方法的优点是可随时停止划分,主要步骤如下:
- 移除网络中的所有边,得到有n个孤立节点的初始状态;
- 计算网络中每对节点的相似度;
- 根据相似度从强到弱连接相应节点对,形成树状图;
- 根据实际需求横切树状图,获得社区结构。
AGENS是一种采用自底向上的策略的聚类算法。简单来说,就是不断合并小的聚类簇,直到合并到符合要求的聚类簇为止。
其中,合并的判断依照聚类间的距离来判定。
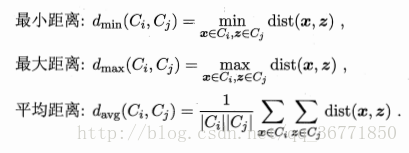
流程如下: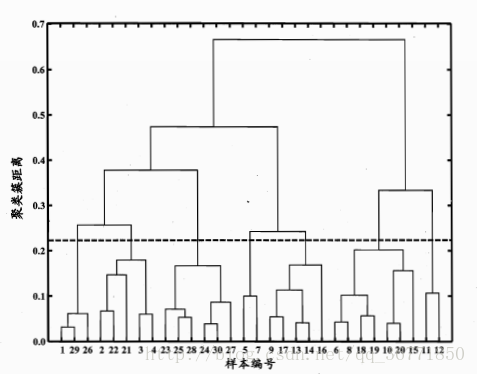














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









