






原文标题:A New RGB-D SLAM Method with Moving Object Detection for Dynamic Indoor Scenes
作者信息:Runzhi Wang 1,2 , Wenhui Wan 1 , Yongkang Wang 3 and Kaichang Di 1, *
文章提出了一种基于几何约束的动态特征检测方法。光度信息用来检测动态特征点,深度信息用来分割运动物体。根据文章的描述,深度信息的作用主要是在聚类上将物体一一分开,如果有更好的用来聚类的信息,那么不使用深度信息也是可以的。
- 算法流程:
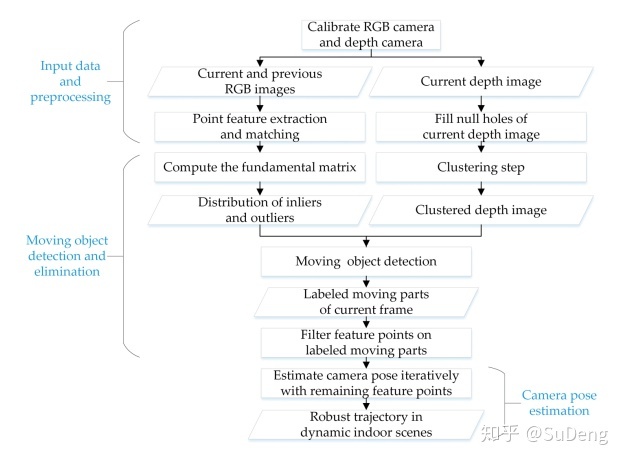
2.设备和信息预处理
(1)设备预处理:相机内参数和相机外参数获取,外参数指深度相机和RGB相机之间的坐标变换参数,两者采集到的图像需要通过这个参数对准。
(2)深度信息预处理:对深度图像进行形态学重构处理,填充空洞。示意图如下,此类空洞会影响深度聚类。

3.算法细节
(1)运动物体检测和剔除:基本原理是,静态特征基于相机的运动在相机图像中的坐标变化满足本质矩阵约束:
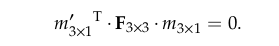
有的翻译成基本矩阵。如果某个特征在相机运动时同时自身存在运动,那么它在前后两个状态下的像素坐标代入上式结果将不为零。那么问题是,本质矩阵F我们事先并不知道,所以也就不存在将一个个特征点的坐标带入上式计算的操作,而且获取本质矩阵一般采用“八点法”,即用八对静态特征点构造八个线性约束求得本质矩阵,倒霉的是我们同样不知道哪些点是静态点,否则相机位子不就直接估计出来了么哈哈。
所以现在我们面临两个问题:a、我们不知道哪些点是静态点,哪些点是动态点,更别说找出八对静态点了;b、既然求不出本质矩阵F,后续怎么根据几何约束来判断动态点呢?
幸运的是我们手头上有匹配好的一堆特征点,虽然不能判断哪些是静态特征,但我们还是可以尝试用它们玩出点花样来:破罐子破摔吧,我们干脆默认所有点都是静态点!然后随机取八对点求本质矩阵F,取多少次八对点呢?这个随意了,你可以按照你的幸运数字来,希望它不要太小,比如1,2,3之类的...
比如说我的幸运数字是88,我求得了88个本质矩阵F,如果我运气好,每次随机选取八对点都是八对静态点,我会发现这88个本质矩阵一模一样,然后去买张彩票...然而极大可能的情况是八对点里混了动态点,然后你痛苦的发现本质矩阵们都不太一样,但是好消息是我们手头上的信息更丰富了!我们有了88个呃...难分善恶的本质矩阵,但是我们肯定,其中存在某个本质矩阵最接近正确的本质矩阵,甚至可能它就是正确的本质矩阵,那么我们怎么把它找出来呢?
对于第i个F,我们随机选取一对点,代入(1)式中,别以为结果会是0!即便是0咱们也不能断定这个F就是我们要找的F,这对点就是静态点,你可以思考一下为什么。我们把代入后的结果取平方:
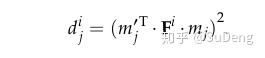
当然我们不会代入一对点后就罢休,我们代入自己幸运数字对点,得到了很多个dj。原文开始对dj采用加权处理了,说实话我不太喜欢加权,感觉这是一种“丰富”算法内容的做法,还会制约算法的普适性。原文采用Sampson distance weight亲密拥抱dj:
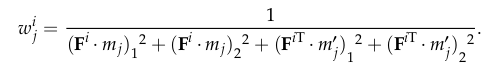
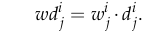
对每个F得到了一组wdj,原文将中位数最小的F当做正确的F(此算法不适用于动态物体占据绝大部分视角的情况),后面判断动态点的操作就常规了。
根据上面的方法判断出了运动特征点,这个时候聚类好的深度信息就派上用场了!我们将动态特征点映射到深度图上,对比剔除动态特征点之前和之后的指标:
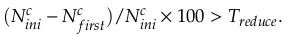
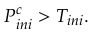
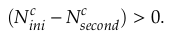
以上三个判断准则基于以下三个事实:(1)动态物体上动态特征点比例肯定会达到某个阈值。(2)动态物体上的动态特征点数量占图片中所有特征点的比例大于某个阈值(此算法不能剔除小型动态物体)(3)动态物体上剔除动态特征点后,其与特征点与图片中所有特征点比例将减小。若某个深度聚类上的特征点满足以上三条,则视其为动态区域,并剔除其上所有特征点。















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









