






前言
《OmniVec2:A Novel Transformer based Network for Large Scale
Multimodal and Multitask Learning》
研究背景
- 研究问题:这篇文章提出了一种新的多模态多任务网络及其相关的训练算法,旨在处理来自约12种不同模态的数据,包括图像、视频、音频、文本、深度、点云、时间序列、表格、图、X光、红外、IMU和高光谱数据。
- 研究难点:该问题的研究难点包括:如何有效地融合和处理多种模态的数据,如何在多任务学习中实现跨模态的知识共享,以及如何在大规模数据集上实现稳健的学习。
- 相关工作:该问题的研究相关工作包括三类方法:直接处理多种异构模态的方法、使用模态特定编码器的方法以及跨模态知识共享的方法。本文的方法与第三类方法更为接近,同时结合了第一类方法的元素。
研究方法
这篇论文提出了一种基于Transformer架构的多模态多任务网络,具体来说,
- 模态特定的分词器:每个模态使用特定的分词器进行分词,而不是将所有模态的标记合并到一个Transformer中。这种方法借鉴了UniPerceiver模型,但进行了关键修改。
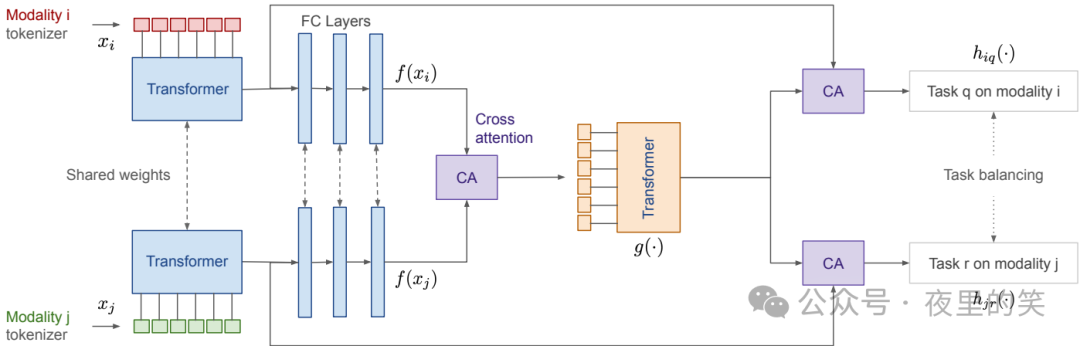
- 共享的Transformer骨干:分词后的数据通过一个基于BERT的Transformer网络进行处理,随后通过全连接层进行降维。
- 特征融合网络:两个模态的特征通过交叉注意力模块进行融合,然后再次通过Transformer网络进行处理。
- 模态和任务特定的头:最终的部分是模态和任务特定的预测头,用于生成任务的最终输出。
- 预训练策略:训练过程包括两个阶段的掩码预训练和全任务基于损失优化。第一阶段是单模态的掩码预训练,第二阶段是两模态的掩码预训练,最后是全任务的有监督训练。
实验设计
- 数据集:实验在25个基准数据集上进行,涵盖了12种不同的模态,包括文本、图像、点云、音频和视频等。
- 预训练数据集:使用AudioSet(音频)、Something-Something v2(视频)、英文维基百科(文本)、ImageNet1K(图像)、SUN RGB-D(深度图)和ModelNet40(3D点云)进行预训练。
- 掩码预训练:在第一阶段,对单个模态进行自监督掩码预训练;在第二阶段,随机选择两个模态进行全网络掩码预训练。
- 有监督训练:最后进行多模态多任务的有监督训练,每次从两个不同的模态中选择一个任务进行训练。
结果与分析
- 图像任务:在iNaturalist-2018数据集上,本文方法取得了94.6%的top-1准确率,超过了其他方法如OmniVec(93.8%)和MetaFormer(87.5%)。
- 视频任务:在Kinetics-400数据集上,本文方法取得了93.6%的top-1准确率,显著优于其他方法。
- 音频任务:在ESC50数据集上,本文方法取得了99.1%的准确率,明显高于其他方法如Audio Spectrogram Transformer(85.7%)和OmniVec(98.4%)。
- 点云任务:在ModelNet40-C数据集上,本文方法取得了0.142的错误率,低于其他方法如OmniVec(0.156)。在S3DIS数据集上,本文方法取得了77.1%的mIoU,是所有方法中最高的。
- 文本任务:在DialogueSUM数据集上,本文方法在所有指标上均优于其他方法。
总体结论
本文提出了一种基于Transformer架构的多模态多任务网络及其相关的训练算法,能够在多个模态上实现稳健的学习。通过两阶段的掩码预训练和多任务的有监督训练,实现了跨模态的知识共享,提升了网络的鲁棒性和泛化能力。实验结果表明,本文方法在多个基准数据集上均取得了优异的性能,接近或达到了现有的最先进技术。
论文评价
优点与创新
- 提出了一种基于Transformer架构的多模态多任务网络,结合了模态特定的分词器、共享的变压器架构和任务特定的头。
- 在25个基准数据集上进行了全面的评估,覆盖了12种不同的模态(如文本、图像、点云、音频和视频等),并应用于X射线、红外、高光谱、IMU、图和表格数据。
- 提出了一种新颖的多模态预训练方法,通过交替使用一对模态来实现跨模态知识共享。
- 提出了一种多模态和多任务监督训练方法,利用模态间的知识共享来实现鲁棒学习,简化了之前工作中提出的模态集成复杂过程。
- 通过双向掩码预训练和全任务基于损失优化,实现了跨模态和任务的知识共享,从而得到一个鲁棒且正则化的网络。
不足与反思
- 论文中提到的模态特定分词器和任务特定头的结合,虽然提高了模型的性能,但也增加了模型的复杂性。未来的工作可以进一步探索如何在不增加模型复杂性的情况下,进一步提高性能。
- 在多模态预训练阶段,尽管采用了双向掩码预训练,但在某些模态(如文本)上仍然使用了随机句子置换,这可能会导致一定的数据浪费。未来的研究可以考虑更高效的掩码策略。
- 论文中提到的方法在处理未见过的模态时表现出色,但在处理未见过的任务时,可能需要更多的任务特定训练数据来达到最佳性能。未来的研究可以探索如何在有限数据的情况下,提高模型在未见过的任务上的泛化能力。
关键问题及回答
问题1:本文提出的基于Transformer架构的多模态多任务网络在预训练策略上有哪些独特之处?
- 单模态掩码预训练:首先,作者对单个模态进行自监督掩码预训练。具体来说,对于输入模态,随机选择一部分标记进行掩盖,然后使用未掩盖的标记进行训练,以学习预测掩盖标记的能力。
- 双模态掩码预训练:其次,作者进行双模态掩码预训练。在这个阶段,作者随机选择两个模态,并将它们一起输入网络,随机掩盖部分标记,然后使用未掩盖的标记进行训练,以学习跨模态的预测能力。
- 全任务有监督训练:最后,作者进行全任务的有监督训练。在这个阶段,作者从两个不同的模态中各选择一个任务进行训练,构建训练批次,半来自每个模态和任务对,以优化相应的任务损失函数(如分类的交叉熵损失和像素级预测的ℓ2损失)。
这种两阶段的预训练策略允许跨模态和任务的知识共享,从而提高网络的稳健性和泛化能力。
问题2:在实验设计中,本文如何在多个基准数据集上验证所提出方法的有效性?
- 数据集选择:实验在25个基准数据集上进行,涵盖了12种不同的模态,包括文本、图像、点云、音频和视频等。这些数据集包括iNaturalist-2018(图像识别)、Places-365(场景识别)、Kinetics-400(视频动作识别)、Moments in Time(视频动作识别)、ESC50(音频事件分类)、S3DIS(3D点云分割)等。
- 预训练数据集:使用AudioSet(音频)、Something-Something v2(视频)、英文维基百科(文本)、ImageNet1K(图像)、SUN RGB-D(深度图)和ModelNet40(3D点云)进行预训练。
- 掩码预训练:在第一阶段,对单个模态进行自监督掩码预训练;在第二阶段,随机选择两个模态进行全网络掩码预训练。
- 有监督训练:最后进行多任务的有监督训练,每次从两个不同的模态中选择一个任务进行训练。
通过在这些多样化的数据集上进行训练和评估,本文方法展示了其在不同模态和任务上的鲁棒性和有效性。
问题3:本文提出的多模态多任务网络在处理不同模态的数据时有哪些优势?
- 模态特定的分词器:每个模态使用特定的分词器进行分词,而不是将所有模态的标记合并到一个Transformer中。这种方法借鉴了UniPerceiver模型,但进行了关键修改,使得每个模态的分词更适合其特性,从而提高了处理效率。
- 共享的Transformer骨干:分词后的数据通过一个基于BERT的Transformer网络进行处理,随后通过全连接层进行降维。共享的Transformer骨干允许网络学习到不同模态之间的共性特征。
- 特征融合网络:两个模态的特征通过交叉注意力模块进行融合,然后再次通过Transformer网络进行处理。这种融合方式使得不同模态的特征可以相互补充,增强了模型的表示能力。
- 模态和任务特定的头:最终的部分是模态和任务特定的预测头,用于输出任务的最终结果。这种设计使得每个任务和模态可以独立地进行优化,提高了模型的灵活性和适应性。
通过这些设计,本文方法能够有效地处理和分析多种模态的数据,并在多个基准数据集上取得了优异的性能。
如何快速掌握大模型技术,享受AI红利?
面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,详尽的全套学习资料,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
无论是初学者,还是希望在某一细分领域深入发展的资深开发者,这样的学习路线图都能够起到事半功倍的效果。它不仅能够节省大量时间,避免无效学习,更能帮助开发者建立系统的知识体系,为职业生涯的长远发展奠定坚实的基础。















 1805
1805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









