







 本文深入探讨了两种常见的损失函数——交叉熵损失(Categorical Crossentropy)和Hinge损失。交叉熵损失常用于多分类问题,克服了sigmoid激活函数在梯度消失上的问题,能更快地更新权重。Hinge损失则常见于最大间隔分类任务,如SVM。通过实例说明了两种损失函数的计算过程及其在实际应用中的特性。
本文深入探讨了两种常见的损失函数——交叉熵损失(Categorical Crossentropy)和Hinge损失。交叉熵损失常用于多分类问题,克服了sigmoid激活函数在梯度消失上的问题,能更快地更新权重。Hinge损失则常见于最大间隔分类任务,如SVM。通过实例说明了两种损失函数的计算过程及其在实际应用中的特性。
参考 Crossentropy loss与Hinge loss - 云+社区 - 腾讯云
损失函数
在之前写期望风险的时候其实已经提过这个概念了,再补充一下
损失函数
定义:损失函数就一个具体的样本而言,模型预测的值与真实值之间的差距。
对于一个样本(xi,yi)其中yi为真实值,而f(xi)为我们的预测值。使用损失函数L(f(xi),yi)来表示真实值和预测值之间的差距。两者差距越小越好,最理想的情况是预测值刚好等于真实值。
进入正题~
categorical_crossentropy loss(交叉熵损失函数)
讲交叉熵损失函数,我想先从均方差损失函数讲起
均方差损失函数
简单来说,均方误差(MSE)的含义是求一个batch中n个样本的n个输出与期望输出的差的平方的平均值。比如对于一个神经元(单输入单输出,sigmoid函数),定义其代价函数为
(其中y是我们期望的输出,a为神经元的实际输出【 a=σ(z), where z=wx+b 】。):在训练神经网络过程中,我们通过梯度下降算法来更新w和b,因此需要计算损失函数对w和b的导数:
然后更新w、b:
w <—— w - η* ∂C/∂w = w - η * a σ′(z)
b <—— b - η ∂C/∂b = b - η * a * σ′(z)
因为sigmoid函数的性质,导致σ′(z)在z取大部分值时会很小,这样会使得w和b更新非常慢(因为η * a * σ′(z)这一项接近于0)。
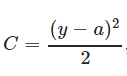
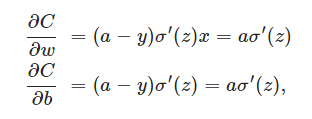
为了克服这个不足,引入了categorical_crossentropy(交叉熵损失函数)
categorical_crossentropy(交叉熵损失函数)
交叉熵是用来评估当前训练得到的概率分布与真实分布的差异情况。
它刻画的是实际输出(概率)与期望输出(概率)的距离,也就是交叉熵的值越小,两个概率分布就越接近。公式如下:
(其中y为期望的输出,a为神经元实际输出)
【a=σ(z), where z=∑Wj * Xj+b】
同样进行求导:
从上图可以看到, 导数中没有σ′(z)这一项,权重的更新是受σ(z)−y这一项影响,即受误差的影响,所以当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。
性质:
a.非负性。(所以我们的目标就是最小化代价函数)
b.当真实输出a与期望输出y接近的时候,代价函数接近于0.(比如y=0,a~0;y=1,a~1时,代价函数都接近0)。这边举一个简单的二分类例子:
预测为猫的p=Pr(y=1)概率是0.8,真实标签y=1;预测不是猫的1-p=Pr(y=0)概率是0.2,真实标签为0。那么 loss=−(1∗log(0.8)+0∗log(0.2))=−log(0.8)。
详细解释--KL散度与交叉熵区别与联系
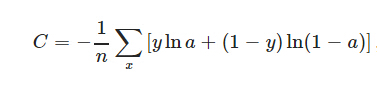
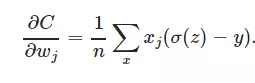
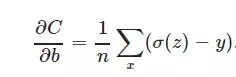

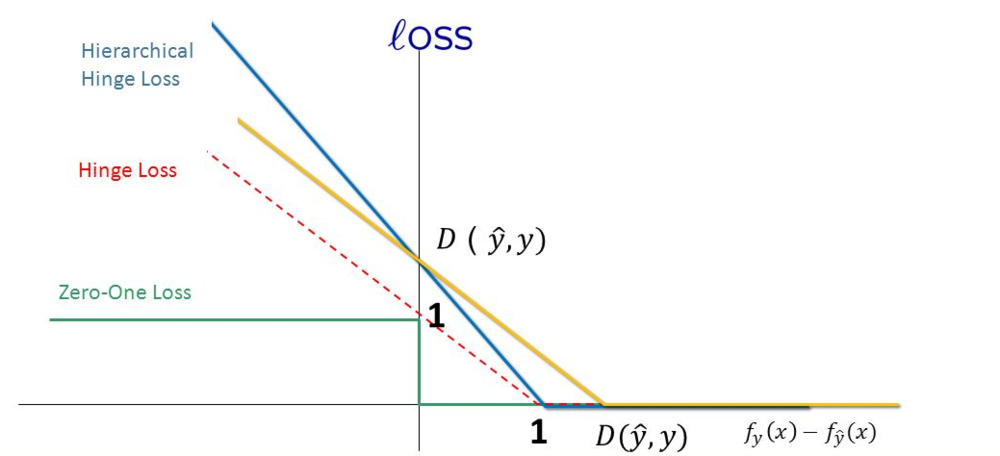
Hinge loss
在网上也有人把hinge loss称为铰链损失函数,它可用于“最大间隔(max-margin)”分类,其最著名的应用是作为SVM的损失函数。
二分类情况下
多分类
扩展到多分类问题上就需要多加一个边界值,然后叠加起来。公式如下:
举例:
栗子① △为1
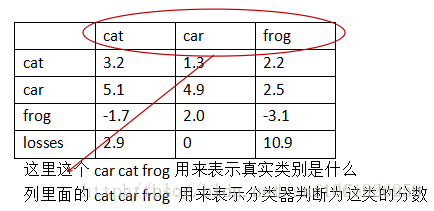
假设有3个类cat、car、frog:
image.png
第一列表示样本真实类别为cat,分类器判断样本为cat的分数为3.2,判断为car的分数为5.1,判断为frog的分数为 -1.7。
hinge loss:
栗子②△取10

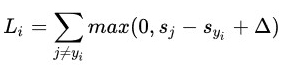
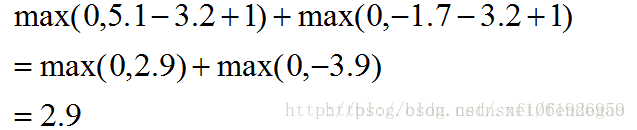



















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











