






通过对象-运动CNN以及双层卷积LSTM来预测视频显著性(眼部定位点、代码为tensorflow框架)
摘要
在过去几年中,深度神经网络(DNN)在预测图像显著性方面取得了巨大成功。但是,很少有工作可以应用DNN来预测一般的视频的显著性。在本文中,我们提出了一种新的基于DNN的视频显著性预测方法。具体来说,我们建立了一个大规模的视频眼动追踪数据集(LEDOV),它提供了足够的数据来训练DNN模型以预测视频显着性。通过我们的LEDOV数据库的统计分析,我们发现人类的注意力通常被物体吸引,特别是移动物体或物体的运动部分。因此,我们提出了一种物体 - 运动卷积神经网络(OM-CNN),通过探索物体和物体运动的信息来学习用于预测帧内显著性的时空特征。我们从我们的数据库中进一步发现,人类注意力与视频帧之间的平滑显著性转换存在时间相关性。因此,我们使用OM-CNN的提取特征作为输入,在我们基于DNN的方法中开发了一个双层卷积长短期记忆(2C-LSTM)网络。因此,可以生成视频的帧间显着性映射,其考虑跨视频帧的注意力的转变。最后,实验结果表明,我们的方法提高了视频显著性预测的最新技术水平。
解读
1.建立了眼部注视点的大规模数据集——LEDOV。
2.人类的注意力常被运动着的物体所吸引——>提出了对象 - 运动卷积神经网络(OM-CNN),提取对象和对象运动的特征信息。
3.人类注意力与视频帧之间的显著性对象转移存在时间相关性——>提出双层卷积长短时记忆网络(2C-LSTM),考虑跨视频帧的注意力的转变。
写作上,作者从数据集出发,“Through the statistical analysis of our LEDOV database:通过我们的LEDOV数据库的统计分析”、“We further find from our database that there exists:我们从我们的数据库中进一步发现”,提出一些显著规律,再针对这些显著规律设计相应的网络结构,将数据集和网络结构巧妙地结合在了一起,从而自圆其说。这是特别值得学习的一点。
介绍
(以人类视觉系统出发,提到显著性,介绍其应用,简述本文的工作)
人类视觉系统(HVS)中的一个foveated(中心凹)机制[1]表明只有小的中心凹区域以高分辨率捕获大多数视觉注意力,而其他外围区域在低分辨率下几乎没有受到关注。为了预测人类的注意力,近年来已经广泛研究了显著性检测,在对象识别,对象分割,动作识别,图像字幕,图像/视频压缩等方面有多种应用[2]。在本文中,我们专注于预测视频像素级的显著性,它模拟每个视频帧的注意力。
(以往的视频显著性预测方法是怎么做的:两步——1.提取空间和时间特征以获得显著映射 2.融合;考虑时间的特征:运动特征,时间对比度特征,压缩领域特征;融合空间和时间特征的方法:机器学习方法)
在早期,传统的视频显着性预测方法主要遵循整合理论[3] - [7],即视频帧的显着性可以通过两个步骤检测:(1)从视频中提取空间和时间特征以获得显著映射; (2)进行融合策略,将不同特征通道的显著映射组合在一起,生成显着性图。受益于最先进的图像显着性预测,已经结合了大量的空间特征来预测视频显着性[8] - [10]。此外,一些工作专注于设计视频显着性预测的时间特征,主要在三个方面:基于运动的特征[6],[11],[12],时间对比度特征[3],[4],[13]和压缩领域特征[14],[15]。为了融合空间和时间特征,使用了许多机器学习算法,例如支持向量机(SVM)[7],[8],[15],概率模型[13],[16],[17]和相位谱分析[18],[19]。
(深度学习的网络以端到端的方式学习了人类注意力,显著提高了显著预测的准确性。但只有少量的工作。具体说了两种工作的思路。这些以往的基于深度学习的方法的缺点:每一点都对应了这篇论文的一大贡献。)
与集成理论不同,最近提出了基于深度自然网络(DNN)的方法以端到端的方式学习人类注意力,显着提高了图像显着性预测的准确性[20] [26]。然而,只有少数作品设法在视频显着性预测中应用DNN [27] [29]。具体而言,Cagdas等人。 [27]采用双流CNN结构,将RGB帧和运动图作为输入,用于视频显着性预测。 Bazzani等人。 [28]利用深度卷积3D(C3D)网络在16个连续帧上学习人类注意力的表示,然后学习与混合密度网络连接的长短时间存储器(LSTM)网络以生成高斯混合分布中的显着性图。然而,由于以下缺点,上述用于视频显着性预测的基于DNN的方法1仍处于婴儿期:(1)用于训练DNN的眼睛跟踪数据不足; (2)缺乏复杂的网络架构,同时学习将对象和运动的信息结合起来; (3)忽略视频帧中视频显着性的动态像素转换。
(针对于以上缺点,本文提出了一种新的方法。具体来说,有三大贡献:1.数据集,包括几个被测试者,观看了多少视频。2.OM-CNN,用于干什么。3.2C-LSTM,用于干什么。)
为了避免上述缺点,本文提出了一种新的基于DNN的方法,通过时空表示和动态显着性建模来预测视频显着性,这得益于我们的眼动追踪数据库的分析。具体来说,我们首先建立一个大型视频数据库,其中包含32个主题的眼动追踪数据,观看538个不同内容的视频。通过对我们数据库的分析,我们发现人类的注意力通常被视频中的物体吸引,特别是物体中的移动物体或运动部件。鉴于这一发现,构建了一种新颖的物体 - 运动卷积神经网络(OM-CNN),用于学习视频显着性预测的时空特征,同时考虑物体和物体运动信息。对于动态显着性建模,开发了一个双层卷积LSTM(2C-LSTM)网络,用于预测跨帧的视频显着性的像素转换,并输入来自OM-CNN的时空特征。与传统的LSTM网络不同,该结构能够通过卷积连接保持空间信息。
总而言之,我们工作的主要贡献如下:
-
我们建立了一个由538个不同内容的视频组成的眼动追踪数据库,并对我们的数据库进行了全面的分析和发现。
-
我们提出了新颖的OM-CNN结构来预测帧内显着性,它将物体和物体运动整合在一个统一的深层结构中。
-
我们开发了具有贝叶斯dropout的2C-LSTM网络,以便在像素级别上学习跨帧间的显着性转换。
本文的其余部分安排如下。 在第二部分中,我们简要回顾了视频显着性预测的相关工作和眼动追踪数据库。 在第II-B节中,我们建立并分析了我们的大规模眼动追踪数据库。 根据我们数据库的调查结果,我们在第IV节提出了用于视频显着性预测的DNN,包括OM-CNN和2C-LSTM。 第V节显示了验证我们方法性能的实验结果。 第六节总结了本文。
相关工作
在本节中,我们将简要回顾最近的视频显着性预测工作和眼动跟踪数据库。
- 视频显著性检测
(传统的视频显著性:通常依赖于两大步骤的整合理论,先特征提取,再特征融合;首先介绍特征提取,时间特征的提取:运动特征、时间差、压缩域方法。)
大多数传统的视频显着性预测方法[3] [7]依赖于由两个主要步骤组成的整合理论:特征提取和特征融合。在图像显着性预测的任务中,许多有效的空间特征成功地用自上而下[8],[30]或自下而上[9],[31]策略预测人类注意力。然而,视频显着性预测更具挑战性,因为时间特征在吸引人类注意力方面也起着重要作用。为实现这一目标,基于运动的特征[6],[11],[12],时间差[3],[4],[13]和压缩域方法[15],[32]被广泛应用于现有工作中。钟等人以运动作为附加的时间特征,提出了一种基于动态一致性约束的改进光流预测视频显著性的方法。同样,Zhou等人在其显著性预测方法中,通过计算中心运动、前景运动、速度运动和加速度运动来扩展运动特征。[3]、[4]、[13]等方法除了运动外,还利用视频的时间变化,通过计算连续帧之间的对比度来预测显著性。例如Ren等人[4]提出通过寻找相邻帧共定位patch上稀疏表示的最小重构误差来估计每个patch的时间差。同样,在[13]中,通过在连续帧的空间特征上添加预先设计的指数滤波器,得到时间差。利用复杂的视频编码标准,压缩域特征也被探索为视频显着性预测的时空特征[15],[32]。
(传统方法的特征融合。)
除了特征提取,许多研究工作都集中在融合策略上,以生成视频显著性地图。具体地,构建一套概率模型,计算预测视频显著性的后验/先验置信度[16]、特征[13]的联合概率分布和候选转移概率[17]。类似地,Li等人开发了一种概率多任务学习方法,将任务相关的先验知识融入到视频显著性预测中。此外,其他机器学习算法,如SVM和中性网络,也被应用于线性[5]或非线性[7]地结合显著性相关的特征。[18]、[19]等先进方法将相位谱分析应用于融合模型中,弥补特征与视频显著性之间的差距。例如,Guo等人利用四元数傅里叶变换(PQFT)在四个特征通道(两个颜色通道、一个强度通道和一个运动通道)上的相位谱来预测视频的显著性。
(深度学习的方法在图像显著性中的运用。着重介绍了Deepfix网络和SALICON 网络)
最近,DNN在许多计算机视觉任务中取得了成功,例如图像分类[34],动作识别[35]和物体检测[36]。在显着性预测领域,DNN也成功地被合并以自动学习用于预测图像显着性的空间特征[21] [26],[37]。具体而言,作为开创性工作之一,Deepfix [21]在VGG-16 [34]和初始模块[38]上提出了基于DNN的结构,以学习用于显着性预测的多尺度语义表示。在Deppfix中,开发了扩张卷积结构以扩展感受野,然后提出了位置偏置卷积层来学习用于显着性预测的中心偏置模式。同样,SALICON [22]也被提议微调现有的物体识别DNN,并开发了一种有效的损失函数,用于训练DNN模型的显着性预测。后来,提出了一些先进的DNN方法[23] [25],[37]来提高图像显着性预测的性能。
(深度学习的方法在视频中的运用。【提取特征的方法】以往方法中提取动态特征的方式:添加时间信息或者LSTM。添加时间信息的方式:4层CNN、双流、动态网络和静态网络相结合。在本文中,建立了OM-CNN。)
然而,只有少数作品设法在视频显着性预测中应用DNN [27] [29],[39],[40]。在这些DNN中,动态特征以两种方式进行了探索:在CNN结构中添加时间信息[27],[29],[39]或利用LSTM开发动态结构[28],[40]。为了添加时间信息,分别训练[39]中的四层CNN和[27]中的双流CNN,其中RGB帧和运动图都作为输入。类似地,在[29]中,与静态显着性映射(由静态CNN生成)连接的视频帧对被输入到动态CNN用于视频显着性预测,允许CNN通过DNN的表示学习来概括更多时间特征。相反,我们发现人类的注意力更可能被移动的物体或物体的运动部分所吸引。因此,为了探索视频显着性预测的语义时间特征,我们的OM-CNN中的运动子网在对象子网的指导下被训练。
(利用深度学习构建动态结构的方法。以往的方法都是用限制输入输出维度的LSTM,无法端到端获取显著映射,而是通过设置先验信息,来获得最终的显著映射。本文中,建立了具有贝叶斯dropout的2C-LSTM。)
为了开发动态结构,Bazzani等人 [28]和刘等人 [40]应用LSTM网络来预测人类的注意力,依赖于短期记忆和长期记忆。但是,LSTM中的完全连接限制了输入和输出的维度,无法获得端到端显著性映射。因此,需要假设强大的对于显着性的分布的先验知识。更具体地说,在[28]中,假设人的注意力分布为高斯混合模型(GMM),然后构造LSTM以学习GMM的参数。同样,[40]侧重于预测会议视频的显着性,并假设每个面部的显着性是高斯分布。在[40]中,LSTM学习跨视频帧的面部显着性转换,并通过组合视频中所有面部的显着性来生成最终显着性图。在我们的工作中,我们首先探索具有贝叶斯dropout的2C-LSTM,以端到端的方式直接预测显著性图。这样可以学习更复杂的人类注意力分布,而不是预先设定的显着性分布。
- 数据集
(眼动数据集收集了什么内容,怎么收集的,可以代表人们的注意的位置。)
视频的眼动数据集收集每个视频帧上的测试者的眼部定位点,这可以用作视频显着性预测的基础事实。 现有的眼动数据集受益于成熟的眼动追踪技术。 特别是,通过跟踪瞳孔和角膜反射,使用眼动仪来获取视频上的测试者的眼部定位点[41]。 然后通过预定义的校准矩阵将瞳孔位置映射到每一个视频帧。 因此,可以在每个视频帧中定位注视点来代表人们注意的位置。
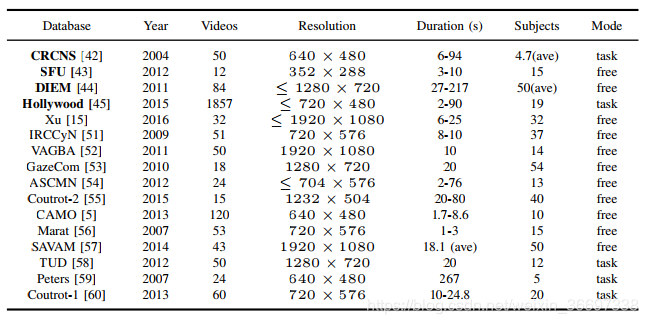
(介绍了数据集的名称、年份、视频的数量、分辨率、时长、受试者、模式)
现在,我们介绍现有的视频眼动数据集。 表I总结了这些数据集的基本属性。 据我们所知,CRCNS [42],SFU [43],DIEM [44]和好莱坞[45]是最受欢迎的数据库,广泛用于最近的视频显着性预测工作[5],[6] ,[14],[17],[19],[32],[39],[46],[47]。 在下文中,将对它们进行更详细的介绍。
(介绍该数据集的地位,常用的应用场景,包括多少个视频,分别有哪些内容,每个视频的时长,分辨率,帧速率,受试者有多少,属于任务驱动还是自由观看。)
CRCNS [42]是由Itti等人建立的最早的视频眼动追踪数据库之一。 在最近的视频显着性预测工作中,它仍然被用作基准,例如[46]。 CRCNS包含50个视频,主要包括户外场景,电视节目和视频游戏。 每个视频的长度范围为5.5到93.9秒,所有视频的帧速率为每秒30帧(fps)。 对于每个视频,要求4到6个主体观看主要演员或动作。 之后,他们被要求描绘视频的主要内容。 因此,CRNS是一个任务驱动的视频眼动追踪数据库。 后来,根据突然的电影剪辑,建立了一个新的数据库[48],通过手动将所有50个CRCNS视频剪切成523个剪辑,持续时间为1-3秒。 招募另外8名受试者观看这些视频剪辑,并在[48]中记录他们的眼动追踪数据。
SFU [43]是一个公共视频数据库,包含12个未压缩YUV视频的眼动追踪数据,这些视频经常被用作视频压缩和处理算法的标准测试集。 每个视频都是CIF分辨率(352 288),帧速率为30 fps时为3-10秒。 收集所有眼动追踪数据,当15名非专业受试者两次免费观看所有12个视频时。
DIEM [44]是另一个广泛使用的数据库,旨在评估不同视觉特征对凝视聚类的贡献。 DIEM包含来自可公开访问的视频的84个视频,包括广告,游戏预告片,电影预告片和新闻剪辑。 这些视频中的大多数都经常进行电影剪辑。 每个视频以30 fps持续27-217秒。 每个视频都跟踪了大约50个主题的自由观看情况。
Hollywood[45]是一个用于视频显著性预测的大型眼球追踪数据库,包含了来自好莱坞-2[49]和UCF sports[50]两个动作识别数据库的所有视频。《好莱坞2》中的1707个视频都是从69部电影中挑选出来的,根据12个动作类,如接电话、吃饭和握手。UCF sports是另一个动作数据库,包括150个视频和9个运动动作类。在自由观看(3名受试者)、动作识别(12名受试者)和上下文识别(4名受试者)三种条件下,对19名受试者的注视进行捕捉。虽然好莱坞的视频数量庞大,但其视频内容并不丰富,受人类行为的制约。此外,它主要关注任务驱动的查看模式,而不是免费查看。
(以上这些数据集的不足之处。以及一个好的数据集应该具备的条件。本文中建立了一个满足该条件的数据集。)
正如第二- b节所讨论的,视频显著性预测可能得益于最近深度学习的发展。遗憾的是,如表一所示,现有的视频显著性预测数据库缺乏足够的眼球跟踪数据来训练DNN。虽然好莱坞[45]有1857个视频,但它主要关注任务驱动的视觉显著性。此外,好莱坞的视频内容是有限的,只涉及电影的人类行为。事实上,一个大型的视频眼动数据库应该具备3个条件:1)视频数量多;2)受试者充足;3)视频内容丰富。在本文中,我们建立了一个大规模的视频眼动数据库,满足了以上三个条件。我们大型数据库的细节将在第三节中讨论。
数据集
在本节中,我们建立了一个新的大型视频眼动数据库(LEDOV),该数据库可以在线使用,方便未来的研究。下面讨论关于我们的LEDOV数据库的更多细节和分析。
- 数据集建立
我们从细节、仪器、参与者和过程等方面介绍了我们的LEDOV数据库。
细节
根据以下四个标准收集了538个视频,总共179,336帧和6,431秒。


1)视频内容多样。具有不同内容的视频来自不同的在线可访问的存储库,例如每日视频博客,纪录片,电影,体育节目,电视节目等。在表II中,我们根据其内容简要地对所有538个视频进行分类。一些例子如图1所示
 .
.
2)包括至少一个对象。只有包含至少一个对象的视频才符合我们的数据库。表III报告了我们数据库中具有不同对象数量的视频数量。
3)高品质。我们通过选择分辨率至少为720p,帧速率为24 Hz的视频,确保了数据库中的高质量视频。为了避免质量下降,在将视频转换为统一的MP4格式时保持了比特率。
4)稳定摄影。 LEDOV中不包括具有不稳定的相机运动和频繁的电影剪辑的视频。具体来说,有212个视频具有稳定的摄像。其他316个视频没有任何摄像机动作。
设备和受试者
为了监测双眼眼球运动,我们的实验使用了眼动仪Tobii TX300[61]。TX300是一个集成的眼睛跟踪与23 TFT显示器屏幕分辨率1920 1080。在实验过程中,TX300捕捉到了300赫兹的凝视数据。根据[61],在理想的工作状态下,凝视精度可以达到0.4视觉度(刺激物在15个像素左右)。有关Tobii TX300的详细信息,请参考[61]。此外,32名参与者(男性18名,女性14名),年龄从20岁开始56名(平均32名)被招募参加眼球追踪实验。所有参与者都是非眼动实验的专家,视力正常/矫正正常。值得指出的是,我们的眼球追踪实验中,只有通过眼动仪校准,且固定物丢失率低于10%的人才被量化。因此,我们的实验选择了60名受试者中的32名。
过程
由于长时间观看视频可能会产生视觉疲劳,因此将LEDOV中的538个视频平均分为6个内容相同的非重叠组(即、人类、动物及人造物品)。在实验过程中,每个受试者都坐在离屏幕65厘米左右的可调节椅子上,然后进行9点校准。然后,受试者被要求随机观看6组视频。在每一组中,视频也随机播放。在连续的两个视频之间,我们插入了一个3秒的休止期和一个2秒的引导图像,其中屏幕中心有一个红色的圆圈。因此,眼睛可以放松,然后初始凝视位置可以重置在中心。在观看一组视频后,受试者被要求休息,直到他/她准备好观看下一组视频。最后,我们的LEDOV数据库从32名受试者的538个视频中记录了5,058,178个注视点(扫视和其他眼球运动已被移除)。
- 数据集分析
(首先,通过图像定性地直观地看出相关性,然后拿数据量化该关系,证明观点。)
在本节中,我们挖掘了我们的数据集来分析人类对视频的注意力。更多细节介绍如下。
-
连续帧上注意力的时间相关性:(注意力存在高度的时间相关性——>前后帧之间是有很大关联的。)

探索连续帧中注意力的时间相关性是很有趣的。在图2中,我们展示了3个选定视频的人类注视图以及一些连续的帧。从图2中可以看出,在连续的视频帧中,注意力存在高度的时间相关性。为了量化这种相关性,我们进一步测量了两个连续帧之间注视图的线性相关系数(CC)。假设Gc和Gp是当前帧和以前帧的固定映射。然后计算出视频中注视图的平均CC值:
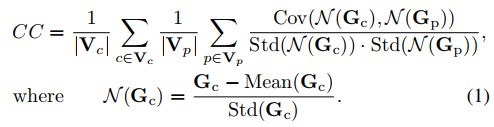
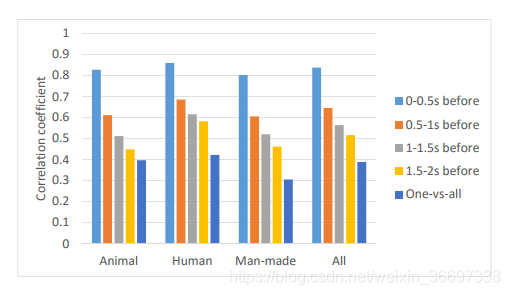
(1)中,Vc是视频中所有帧的集合,Vp是c帧之前连续帧的集合,Cov(·)、Std(·)、Mean(·)是协方差、标准差和均值算子。对于Vp,我们选择4组之前的帧,即, 0-0.5s之前,0.5-1s之前,1-1.5s之前,1.5-2s之前。然后,在图3中,我们绘制了这4组Vp的CC结果,它们在我们的LEDOV数据库中的所有视频中取平均值。我们也在图3中显示了one-vs-all结果,这是一个受试者与其他受试者注视图之间的平均CC基线(表示人之间的注意相关性)。从图中可以看出,时间一致性的CC值远远高于onev -all基线的CC值。这意味着在连续的视频帧之间有很高的时间相关性。我们可以进一步发现,当增加当前帧与前一帧之间的距离时,注意的时间相关性降低。因此,长期和短期的注意力依赖于整个视频帧可以得到验证。 -
对象与人类注意力的关系(人们关注的区域一般都是对象区域,而非背景区域)

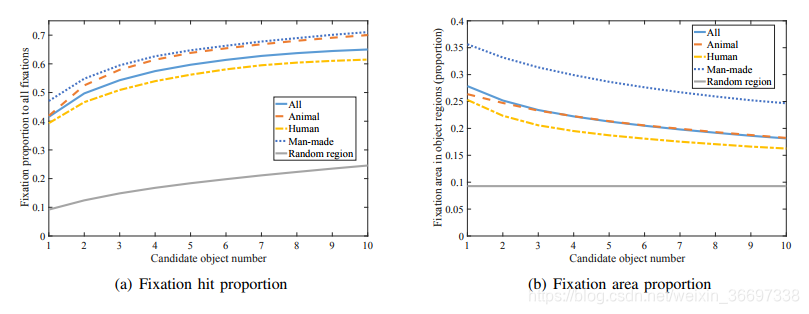
在观看视频时,人们可能会被对象而不是背景所吸引。因此,我们研究了对象区域与关注度之间的关系。首先,我们应用基于CNN的目标检测方法YOLO [36]来检测每个视频帧中的主要对象。在这里,我们通过设置置信概率和非极大值抑制的阈值,在YOLO中生成不同数量的候选对象。图4-(b)显示了检测到一个对象的示例,而图4-(c)显示了多个对象的结果。我们可以从图4-(b)中观察到,人们通常关注的是对象区域。我们还可以从图4-(c)中看到,注视点会随着检测到的候选对象的数量的增加而增加。为了量化人类注意力和对象之间的相关性,我们测量了落入对象区域的注视点与所有注视点区域的比例。在图5-(a)中,我们显示了候选对象数量增加时的固定比例,对LEDOV中的所有视频进行了平均。我们可以从这个图中观察到,对象区域上的固定比例远高于随机区域上的固定比例。这意味着在观看视频时对象性与人类关注度之间存在高度相关性。图5-(a)还显示固定比例与更多候选对象一起增加,这表明人类注意力可能被多个对象吸引。
此外,可以从图4中发现,人类的注意力只关注对象区域的一小部分。因此,我们测量了物体内部固定面积占整个物体面积的比例。图5-(b)显示了在检测到的候选对象数量增加时,这一比例的结果。从图中可以看出,随着候选对象的增多,注视面积所占的比例逐渐减小。
- 运动与人类关注之间的相关性(人们一般关注运动着的物体)


从我们的LEDOV数据库中,我们发现人类关注的趋势集中在移动物体或物体的运动部分。具体而言,如图6的第一行所示,当人类突然快速下降时,人们的注意力转移到大企鹅身上。此外,图6的第二行显示,在具有单个显着对象的场景中,玩家的密集移动部分可能比其他部分吸引更多的注视。有趣的是进一步探索物体区域内运动与人类注意力之间的相互关系。在这里,我们应用FlowNet [63],一种基于CNN的光流方法,来测量所有帧中的运动强度(一些结果如图4-(d)所示)。在每个帧处,根据运动强度的降序对像素进行排序。随后,我们在LEDOV数据库中的所有视频帧上将排序的像素聚类成具有相同像素数的10个组。例如,第一组包括排名前10%的运动强度的像素。落入每组的注视数量如图7所示。从图7中可以看出,44.9%的注视属于具有前10%高值运动强度的组。这意味着物体区域内的运动和人类注意力之间的高度相关性。
提出的方法
模型框架
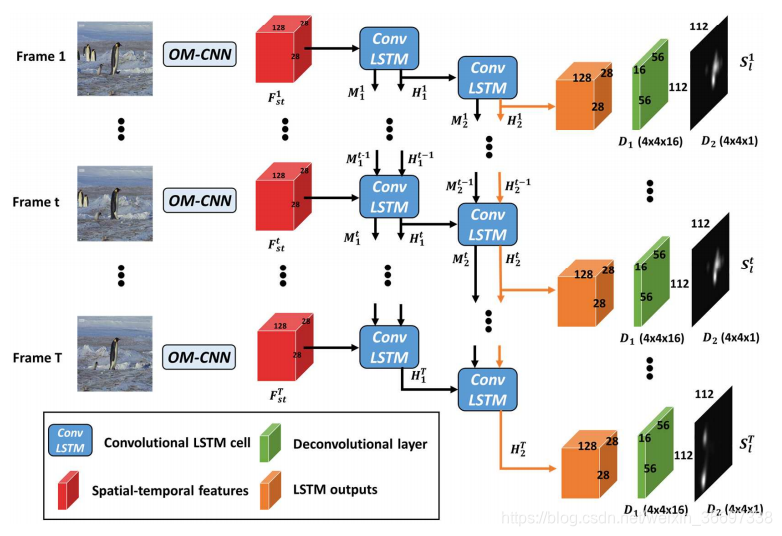
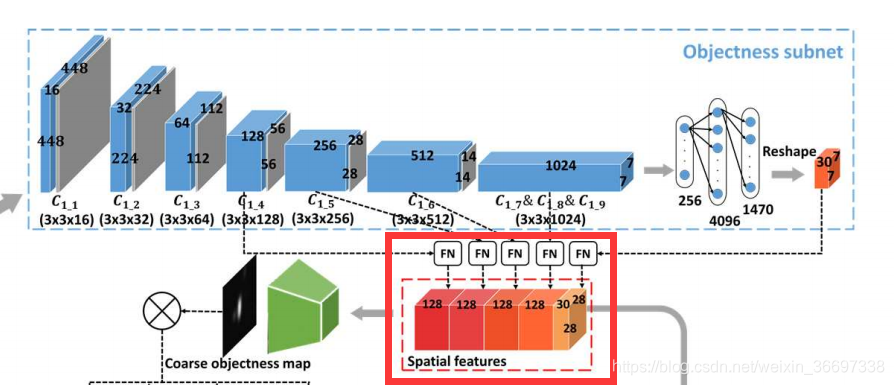
对于视频显着性预测,我们开发了一种新的DNN架构,它将OM-CNN和2C-LSTM结合在一起。受第III-B节的第二和第三个发现的启发,OM-CNN整合了物体的区域和运动,以通过两个子网,即物体和运动的子网来预测视频显着性。在OM-CNN中,对象子网产生粗对象图,其用于屏蔽从运动子网中的卷积层输出的特征。然后,来自对象子网的空间特征和来自运动子网的时间特征被连接以生成OM-CNN的时空特征。 OM-CNN的体系结构如图8所示。根据第III-B节的第一个发现,开发了具有贝叶斯dropout的2C-LSTM,以学习视频片段的动态显着性,其中OM-CNN的时空特征作为输入。最后,每帧的显著映射由2C-LSTM的2个反卷积层产生。 2CLSTM的架构如图9所示。
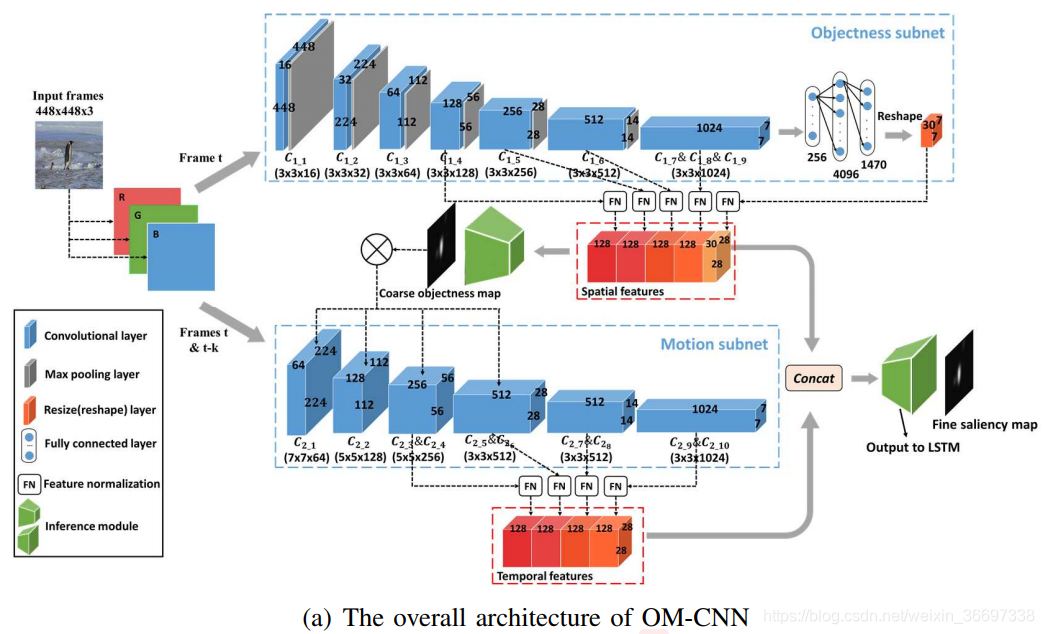

OM-CNN中的对象子网
第三- b节的第二个发现表明,物体在视频中引起广泛注意。因此,OM-CNN包含了一个对象子网,用于提取与对象信息相关的多尺度空间特征。对象子网的基本结构基于预先训练的YOLO [36]。 请注意,YOLO是一种先进的CNN架构,能够高精度地检测视频对象。 在OMCNN中,YOLO结构用于学习输入帧的空间特征以进行显着性预测。 为避免过拟合,在对象子网中运用了YOLO的快速版本,包括9个卷积层,5个池化层和2个完全连接层(FC)。为了进一步避免过拟合,将额外的BN层添加到每个卷积层。 假设P(·)和*是最大池化和卷积运算,对象子网中第k个卷积层的输出可以计算为
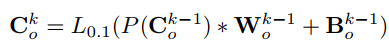
此外,L0.1(·)为系数为0.1的Leacky ReLU激活。
def YOLO_tiny_inference(self,images):
cnnpretrain=True //使用预训练模型
cnntrainable=False //不进行训练
self.batch_size=images.get_shape[0].value //batch_size是图像的数量
conv_1=self.conv_layer('conv1',images,3,16,stride=1, //第一个卷基层,3*3*16,448*448
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_2=self.max_pool('pool2',conv_1,2,stride=2) //第一个池化层,2*2
conv_3=self.conv_layer('conv3',pool_2,3,32,stride=1, //第二个卷基层,3*3*32,224*224
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_4=self.max_pool('pool4',conv_3,2,stride=2) //第二个池化层,2*2
conv_5=self.conv_layer('conv5',pool_4,3,64,stride=1, //第三个卷基层,3*3*64,112*112
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_6=self.max_pool('pool6',conv_5,2,stride=2) //第三个池化层,2*2
conv_7=self.conv_layer('conv7',pool_6,3,128,stride=1, //第四个卷基层,3*3*128,56*56
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_8=self.max_pool('pool8',conv_7,2,stride=2) //第四个池化层,2*2
conv_9=self.conv_layer('conv9',pool_8,3,256,stride=1, //第五个卷基层,3*3*256,28*28
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_10=self.max_pool('pool10',conv_9,2,stride=2) //第五个池化层,2*2
conv_11=self.conv_layer('conv11',pool_10,3,512,stride=1, //第六个卷基层,3*3*512,14*14
pretrain=cnnpretrain,batchnormalization=true,trainable=cnntrainable)
pool_12=self.max_pool('pool12',conv_11,2,stride=2) //第六个池化层,2*2
conv_13=self.conv_layer('conv13',pool_12,3,1024,stride=1, //第七个卷基层,3*3*1024,7*7
pretrain=cnnpretrain,trainable=cnntrainable)
conv_14=self.conv_layer('conv14',conv_13,3,1024,stride=1, //第八个卷基层,3*3*1024,7*7
pretrain=cnnpretrain,trainable=cnntrainable)
conv_15=self.conv_layer('conv15',conv_14,3,1024,stride=1, //第九个卷基层,3*3*1024,7*7
pretrain=cnnpretrain,trainable=cnntrainable)
temp_conv=tf.transpose(conv_15,(0,3,1,2)) //将矩阵进行转置,将通道层放在前面。
fc_16=self.fc_layer('fc16',temp_conv,256,flat=True, //第一个全连接层,将张量拍扁,长为256
pretrain=cnnpretrain,trainable=cnntrainable)
fc_17=self.fc_layer('fc17',fc_16,4096,flat=False, //第二个全连接层,将张量拍扁,长为4096
pretrain=cnnpretrain,trainable=cnntrainable)
fc_18=self.fc_layer('fc18',fc_17,1470,flat=False,linear=True //第三个全连接层,将张量拍扁,长为1470
pretrain=cnnpretrain,trainable=cnntrainable)
highFeature=tf.reshape(fc_18,[fc_18.getshape()[0].value,7,7,-1])
//把拍扁的张量reshape成30*7*7的张量块(30*7*7正好等于1470)
以上代码写的是这一部分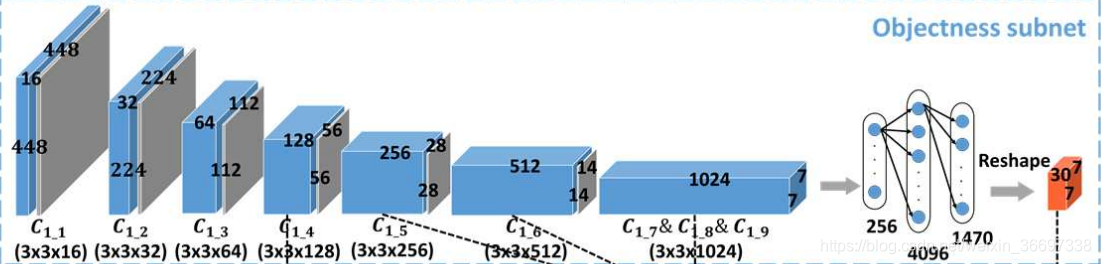
为了利用具有各种感受域的多尺度信息,在OM-CNN中引入特征归一化(FN)操作以对对象子网的某些卷积层进行归一化和连接。如图8-(b)所示,FN包括一个11卷积层和一个双线性层,用于将输入特征标准化为128个通道,大小为2828.具体来说,在对象子网中,第4、5、6和最后一个卷积层的输出通过FN归一化,得到4组空间特征,涉及多个尺度。此外,YOLO中最后一个FC层的输出表示每个网格中候选对象的大小、类概率和置信度。然后,需要将最后一个FC层的输出重新塑造为大小为7730的空间特征(表示大小为77的30个通道)。对7730空间特征进行双线性插值后,得到高阶空间特征FS5,其尺寸为2828*30。最后,通过连接这五个模块,生成最终的空间特征。
conv_15_2=self.conv_layer('conv_15_2',conv_15,1,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//将第九个卷积块(1024层)再次卷积,1*1*128,7*7(主要为了调整层数,卷积核设为了1)
conv_11_2=self.conv_layer('conv_11_2',conv_11,1,128,stride=1, pretrain=cnnpretrain,trainable=cnntrainable)
//将第六个卷积块(512层)再次卷积,1*1*128,14*14(主要为了调整层数,卷积核设为了1)
conv_9_2=self.conv_layer('conv_9_2',conv_9,1,128,stride=1, pretrain=cnnpretrain,trainable=cnntrainable)
//将第五个卷积块(256层)再次卷积,1*1*128,28*28(主要为了调整层数,卷积核设为了1)
tempsize=conv_9.get_shape().as_list() //将第五个卷积块的大小作为后面的标准大小 28*28
newconv_7=tf.image.resize_images(conv_7,[tempsize[1],tempsize[2]])
//将第四个卷积块得到的特征映射的大小调整为28*28.(层数为128)
newconv_9=tf.image.resize_images(conv_9_2,[tempsize[1],tempsize[2]])
//将第五个卷积块得到的特征映射的大小调整为28*28
newconv_11_2=tf.image.resize_images(conv_11_2,[tempsize[1],tempsize[2]])
//将第六个卷积块得到的特征映射的大小调整为28*28
newconv_15_2=tf.image.resize_images(conv_15_2,[tempsize[1],tempsize[2]])
//将第九个卷积块得到的特征映射的大小调整为28*28
highFeature=tf.image.resize_images(highFeature,[tempsize[1],tempsize[2]])
//将全连接层之后得到的卷积块的大小调整为28*28
FeatureMap=tf.concat([newconv_7,newconv_9,newconv_11_2,newconv_15_2,highFeature],axis=3)
//将调整了层数和大小滞后的第四个卷积块、第五个卷积块、第六个卷积块、第九个卷积块、全连接层之后得到的卷积块连接在一起,(1,28,28,128+128+128+128+30)=(1,28,28,542)
weight_mask=tf.constant(self.get_centermask(FeatureMap.get_shape().as_list()),dtype=FeatureMap.dtype)
//tf.constant()用于创建常量,weight_mask是一个(1,28,28,1)的常量
FeatureMap=FeatureMap*weight_mask
//将二者相乘,得到的仍是(1,28,28,542)的特征映射
return FeatureMap
以上代码写的是这一部分
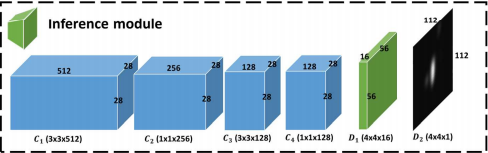
针对以上的空间特征,设计了一个推理模块来生成粗略的目标映射Sc。推理模块是一个CNN结构,由4个卷积层和2个反卷积层组成,步长为2。Ic的架构如图8-(b)所示。
def Coarse_salmap(self,Yolofeature):
cnnpretrain=True
cnntrainable=False
conv_19=self.conv_layer('conv_19',Yolofeature,3,512,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第一个卷积块,3*3*521,28*28
conv_20=self.conv_layer('conv_20',conv_19,1,256,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第二个卷积块,1*1*256,28*28
conv_21=self.conv_layer('conv_21',conv_20,3,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第三个卷积块,3*3*128,28*28
conv_22=self.conv_layer('conv_22',conv_21,1,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第四个卷积块,1*1*128,28*28
deconv_23=self.trainspose_conv_layer('deconv_23',conv_22,4,16,stride=2,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第一个反卷积块,4*4*16,56*56
deconv_24=self.trainspose_conv_layer('deconv_24',deconv_23,4,1,linear=True,stride=2,pretrain=cnnpretrain,trainable=cnntrainable)
//粗略对象估计模块的第二个反卷积块,4*4*1,112*112
以上代码写的是这一部分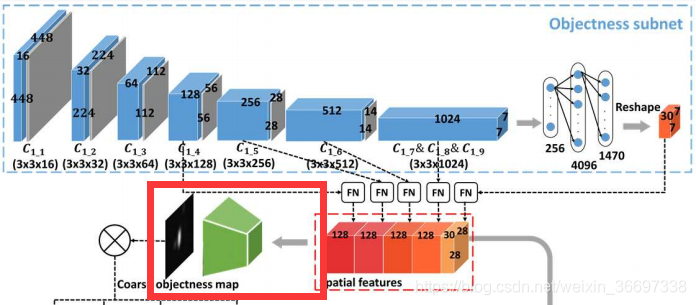
因此,可以得到粗略的目标映射Sc来编码目标信息,这些信息与显著区域大致相关。
OM-CNN中的运动子网
接下来,也在图8-(a)中示出的运动子网被并入OM-CNN中以从相邻帧中提取多尺度时间特征。 根据第III-B节的第三个发现,注意力更可能被移动物体或物体的运动部分所吸引。 因此,在对象子网之后,开发运动子网以提取对象区域内的运动特征。 运动子网基于FlowNet [63],一种用于估计光流的CNN结构。 在运动子网中,仅应用FlowNet的前10个卷积层,以减少参数的数量。为了模拟对象区域中的运动,上一小节的粗略对象映射Sc用于mask运动子网的前6个卷积层的输出。这样,第k个卷积层Ckm的输出可以被计算为
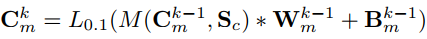
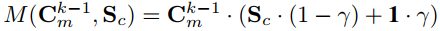
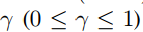 是控制mask程度的可调参数,将Sc的范围从[0,1]映射到[γ,1]。 注意,为了考虑显着性预测中非对象区域的运动,最后4个卷积层没有用粗糙对象图mask。 之后,类似于对象子网,第4,第6,第8和第10卷积层的输出由FN计算,使得4组时间特征的大小调整为2828128。
是控制mask程度的可调参数,将Sc的范围从[0,1]映射到[γ,1]。 注意,为了考虑显着性预测中非对象区域的运动,最后4个卷积层没有用粗糙对象图mask。 之后,类似于对象子网,第4,第6,第8和第10卷积层的输出由FN计算,使得4组时间特征的大小调整为2828128。
def flownet_with_conv(self,x1,x2,mask):
cnnpretrain=True
cnntrainable=False
input=tf.concat([x1,x2],axis=3,name='FNinput') //输入两张图,将两张图连接在一起 448*448*6
conv_1=self.leaky_conv(input,64,7,2,'FNconv1',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第一个卷积块,7*7*64,224*224
conv_1=self.conv_mask(conv_1,mask)
//将mask调整到conv_1的大小,再相乘
conv_2=self.leaky_conv(conv_1,128,5,2,'FNconv2',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第二个卷积块,5*5*128,112*112
conv_2=self.conv_mask(conv_2,mask)
//将mask调整到conv_2的大小,再相乘
conv_3=self.leaky_conv(conv_2,256,5,2,'FNconv3',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第三个卷积块,5*5*256,56*56
conv_3=self.conv_mask(conv_3,mask)
//将mask调整到conv_3的大小,再相乘
conv_3_1=self.leaky_conv(conv_3,256,3,1,'FNconv3_1',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第四个卷积块,3*3*256,56*56
conv_3_1=self.conv_mask(conv_3_1,mask)
//将mask调整到conv_3_1的大小,再相乘
conv_4=self.leaky_conv(conv_3_1,512,3,2,'FNconv4',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第五个卷积块,3*3*512,28*28
conv_4=self.conv_mask(conv_4,mask)
//将mask调整到conv_4的大小,再相乘
conv_4_1=self.leaky_conv(conv_4,512,3,1,'FNconv4_1',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第六个卷积块,3*3*512,28*28
conv_5=self.leaky_conv(conv_4_1,512,3,2,'FNconv5',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第七个卷积块,3*3*512,14*14
conv_5_1=self.leaky_conv(conv_5,512,3,1,'FNconv5_1',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第八个卷积块,3*3*512,14*14
conv_6=self.leaky_conv(conv_5_1,1024,3,2,'FNconv6',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第九个卷积块,3*3*1024,7*7
conv_6_1=self.leaky_conv(conv_6,1024,3,1,'FNconv6_1',pretrain=cnnpretrain,trainable=cnntrainable)
//FlowNet的第十个卷积块,3*3*1024,7*7
以上代码写的是这一部分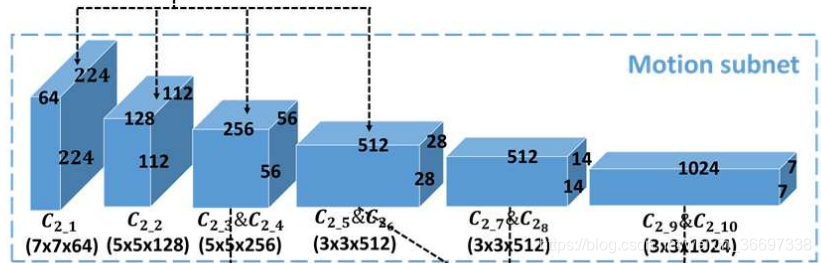
out_cat_size=conv_4.get_shape().as_list()
//将第五个卷积块的大小作为后面的标准大小 28*28
Downconv_6_1=self.conv_layer('FNDownconv_6_1',conv_6_1,3,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//将第十个卷积块(1024层)再次卷积,3*3*128,7*7(主要为了调整层数,卷积核设为了3)
Downconv_5_1=self.conv_layer('FNDownconv_5_1',conv_5_1,3,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//将第八个卷积块(512层)再次卷积,3*3*128,14*14(主要为了调整层数,卷积核设为了3)
Downconv_4_1=self.conv_layer('FNDownconv_4_1',conv_4_1,3,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//将第六个卷积块(512层)再次卷积,3*3*128,28*28(主要为了调整层数,卷积核设为了3)
Downconv_3_1=self.conv_layer('FNDownconv_3_1',conv_3_1,3,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//将第四个卷积块(256层)再次卷积,3*3*128,56*56(主要为了调整层数,卷积核设为了3)
conv_6_1_cat=tf.image.resize_images(Downconv_6_1,[out_cat_size[1],out_cat_size[2]])
//将第十个卷积块得到的特征映射的大小调整为28*28
conv_5_1_cat=tf.image.resize_images(Downconv_5_1,[out_cat_size[1],out_cat_size[2]])
//将第八个卷积块得到的特征映射的大小调整为28*28
conv_4_1_cat=tf.image.resize_images(Downconv_4_1,[out_cat_size[1],out_cat_size[2]])
//将第六个卷积块得到的特征映射的大小调整为28*28
conv_3_1_cat=tf.image.resize_images(Downconv_3_1,[out_cat_size[1],out_cat_size[2]])
//将第四个卷积块得到的特征映射的大小调整为28*28
concat_out=tf.concat([conv_6_1_cat,conv_5_1_cat,conv_4_1_cat,conv_3_1_cat],axis=3,name='FNconcat_out')
//将调整了层数和大小之后的第十个卷积块、第八个卷积块、第六个卷积块、第四个卷积块连接在一起,(1,28,28,128+128+128+128)=(1,28,28,512)
以上代码写的是这一部分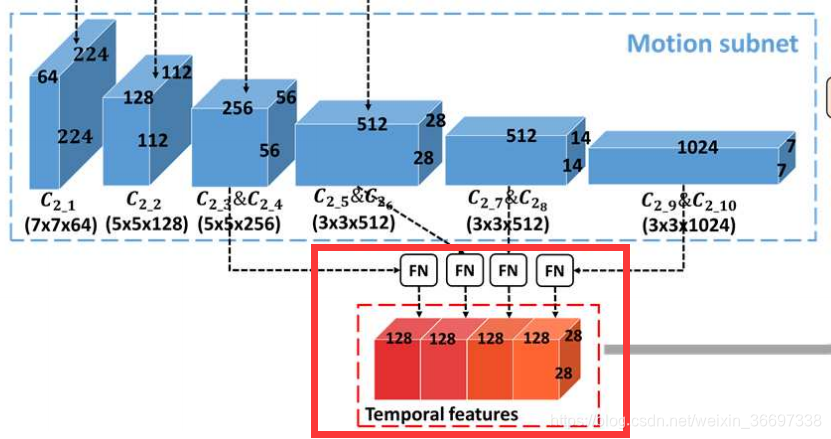
然后,给定从OM-CNN的两个子网提取的对象特征和运动特征,构造另一个推理模块以生成精细显着图Sf,对帧内显著性进行建模。 在数学上,Sf可以计算为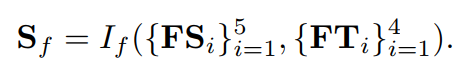
这里,Sf也被用来训练OM-CNN模型,将在IV-E节中讨论。此外,If的结构与Ic相同,如图8-(b)所示,在If中,大小为2828128的卷积层C4的输出被视为最终的时空特征,记为Fst,用来预测帧内显著性。接下来,将Fst输入到2C-LSTM中。
def Final_inference(self,cat1,cat2):
cnnpretrain=True
cnntrainable=False
MyFeature=tf.concat([cat1,cat2],axis=3) //将对象特征和运动特征连接,(28*28*542+512)=(28*28*1054)
Lastconv_1=self.conv_layer('Lastconv_1',MyFeature,3,512,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//对对象-运动特征作用的第一个卷积块,3*3*512,28*28
Lastconv_2=self.conv_layer('Lastconv_2',Lastconv_1,1,512,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//对对象-运动特征作用的第二个卷积块,1*1*512,28*28
Lastconv_3=self.conv_layer('Lastconv_3',Lastconv_2,3,256,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//对对象-运动特征作用的第三个卷积块,3*3*256,28*28
Lastconv_4=self.conv_layer('Lastconv_4',Lastconv_3,1,128,stride=1,pretrain=cnnpretrain,trainable=cnntrainable)
//对对象-运动特征作用的第四个卷积块,1*1*128,28*28
以上代码写的是这一部分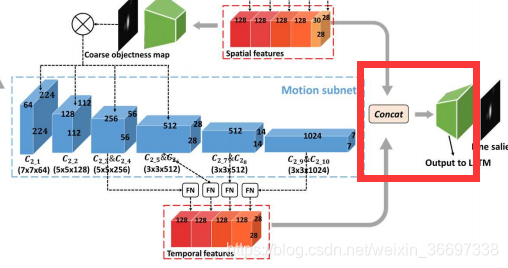
卷积LSTM
在本节中,我们开发了2C-LSTM网络,用于学习预测视频片段的动态显著性,因为第III-B节的第一个发现说明视频帧中存在注意力的动态转换。 在第t帧,将从OM-CNN获得的对象-运动特征Fst作为输入,2CLSTM,通过第一个和第二个LSTM层中的记忆单元和隐藏单元,结合了输入特征的长期和短期相关性。接着,第二个LSTM层中的隐藏状态送入两个反卷积层中,获得最终的显著映射。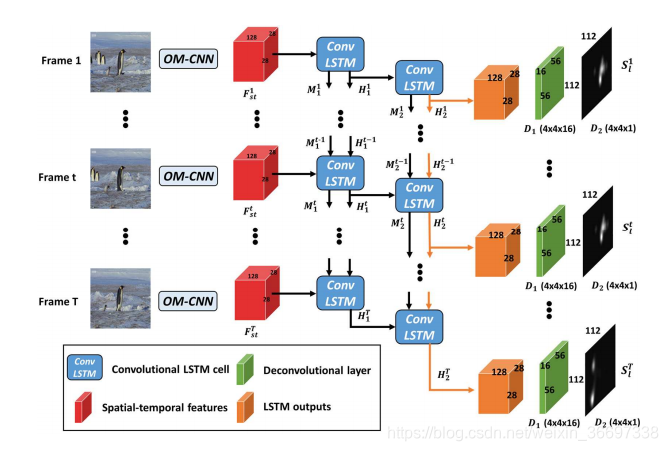
之后,作者介绍了卷积LSTM。
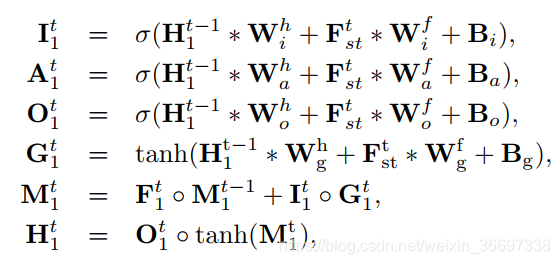
之后,作者介绍了本文的卷积LSTM与传统卷积LSTM的区别:
在我们的方法中,我们采用双层LSTM单元来学习高维特征的时间相关性(28*28 *128)。 另一方面,双层LSTM降低了泛化能力。 因此,为了提高泛化能力,我们在每个卷积LSTM单元中应用了基于贝叶斯推断的dropout[65]。这样,可以将卷积LSTM重写为:
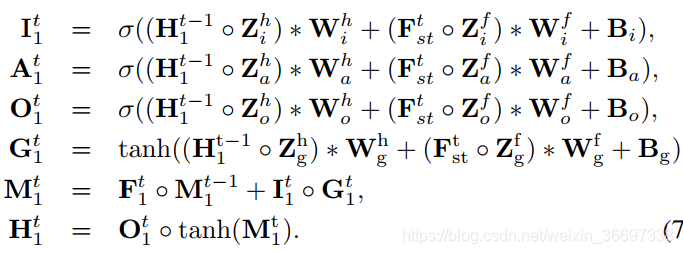
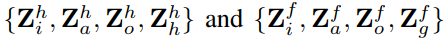 为卷积运算前对隐藏状态和输入特征的2组随机掩码。这些掩码是通过Ltimes蒙特卡罗积分生成的,分别代表隐藏dropout速率ph和特征dropout速率pf。
为卷积运算前对隐藏状态和输入特征的2组随机掩码。这些掩码是通过Ltimes蒙特卡罗积分生成的,分别代表隐藏dropout速率ph和特征dropout速率pf。
训练过程
为了训练OM-CNN,我们利用基于Kullback-Leibler(KL)散度的损失函数来更新参数。 这是因为[22]证明了KL差异在训练DNN预测显著性方面比其他指标更有效。将显著性图视作注意力的概率分布,我们可以测量OM-CNN精细显著性图Sf与人类注视点groundtruth G之间的KL散度DKL如下
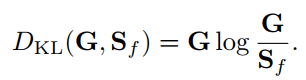
KL散度越小,显著性预测精度越高。此外,还利用OM-CNN的粗略目标映射Sc与groundtruth G之间的KL散度作为辅助函数来训练OM-CNN。这是基于目标区域与显著区域相关的假设。然后,通过最小化以下损失函数训练OM-CNN模型
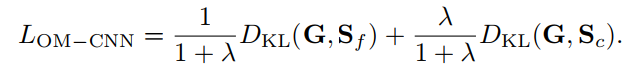
λ是hyper-parameter控制两个KL的重量差异。注意,OM-CNN是在YOLO和FlowNet上预先训练的,其余的OM-CNN参数由Xavier初始化器初始化。
为了训练2C-LSTM,将训练视频切成长度为t的片段,在训练2C-LSTM时,固定OM-CNN的参数,提取每个t帧视频片段的时空特征。然后,将2C-LSTM的损失函数定义为KL在T帧上的平均散度。
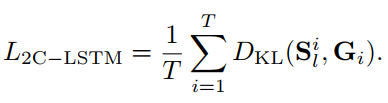
对于每个LSTM单元,内核参数由Xavier初始化器初始化,而内存单元和隐藏状态由零初始化。
实验
实验结果验证了该方法在视频显著性预测中的有效性。第V-A节介绍了我们实验中的设置。V-B节和V-C节分别对LEDOV和其他2个公共数据集的显著性预测精度进行了比较。此外,对照实验的结果在V-D部分进行了讨论,以分析我们的方法中提出的每个单独组件的有效性。
实验设置
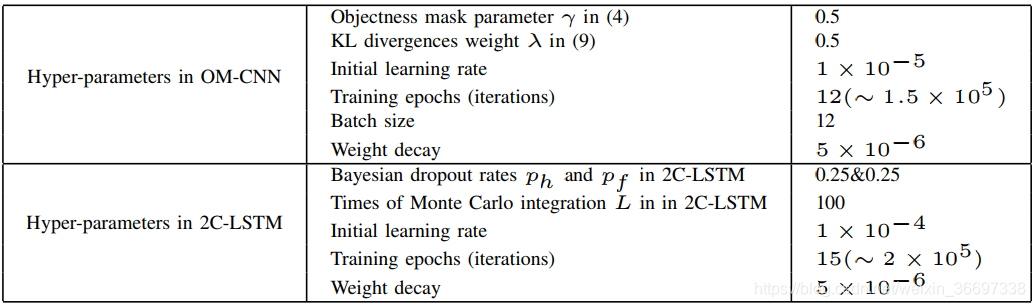
在我们的实验中,LEDOV数据库中的538个视频被随机分为训练(436个视频),验证(41个视频)和测试(41个视频)组。具体来说,为了学习2CLSTM,我们暂时将456个训练视频分成24,685个剪辑,所有剪辑都有T = 16帧。为了数据增强,在剪切视频剪辑时允许10帧的重叠。在输入到OM-CNN之前,每帧的RGB通道被调整为448*448,并减去它们的均值。 在训练OM-CNN和2CLSTM时,我们使用带有Adam优化器的随机梯度下降算法来学习参数[67]。 这里,调整OM-CNN和2C-LSTM的超参数以最小化显着性预测相对于验证集的KL散度。 表IV列出了一些关键超参数的值。 鉴于OM-CNN和2CLSTM的训练模型,我们的方法在LEDOV中的所有41个测试视频上进行了评估,并与其他8种最先进的方法进行了对比。 所有实验均在配备Intel(R)Core(TM)i7-4770 CPU@3.4 GHz,16 GB RAM和Nvidia GeForce GTX 1080单GPU的计算机上进行。受益于GPU的加速,我们的方法可以以30 fps的速度实时预测视频显着性。
在LEDOV上进行评估
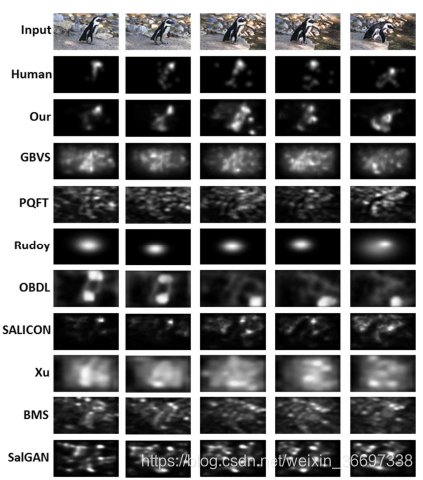
在本节中,我们比较了我们和其他8种最先进的方法,包括GBVS [11], PQFT [18], Rudoy [17], OBDL [14], SALICON [22], Xu [15], BMS[10]和SalGAN[26]预测视频显著性的准确性。其中,[11]、[18]、[17]、[14]和[15]是目前最先进的5种视频显著性预测方法。此外,我们比较了两种基于DNN的方法,[22]和[26]。在我们的实验中,我们使用了四个指标来衡量显著性预测的准确性:接收器工作特性曲线下的面积(AUC)、归一化扫描路径显著性(NSS)、CC和KL散度。AUC、NSS和CC越大,表示显著性预测更准确,KL散度越小,显著性预测越好。表V列出了我们和其他8种方法的AUC,NSS,CC和KL散度的结果,这些方法在LEDOV数据库的41个测试视频中取平均值。

从这个表中我们可以看出,我们的方法在所有4个指标中都比其他方法表现得好得多。更具体地说,我们的方法在AUC、NSS、CC和KL上至少实现了0.03、0.61、0.13和0.40的改进,并且SALICON[22]和SalGAN[26]两种基于DNN的方法优于其他传统方法。这验证了DNN自动学习的显著性相关特性的有效性,比手工提取的特性更好。另一方面,我们的方法明显优于[22]和[26]。主要原因如下:(1)我们的方法嵌入了对象子网,利用客观信息进行显著性预测;(2)在运动子网中探索目标的运动信息,预测视频显著性。(3)利用2C-LSTM网络对视频帧间的显著性转换进行建模。V-D部分对以上三个原因有更详细的说明。
接下来,我们将对视频显著性预测的主观结果进行比较。图10展示了我们等8种方法检测到的测试集中随机选取的8个视频的显著性图。在这个图中,每个视频选择一个帧。从图10可以看出,我们的方法能够很好地定位显著区域,更接近人类注视点的ground-truth图。相比之下,大多数其他方法都不能准确预测出吸引人类注意的区域。此外,图11显示了从一个测试视频中选择的一些帧的显著性映射。从图中可以看出,与其他8种方法相比,我们的方法能够以平稳过渡的方式对人眼注视点进行建模。综上所述,我们的方法在客观和主观结果上都优于其他先进的方法,并在我们的LEDOV数据库中进行了测试。

对其他数据库的评估
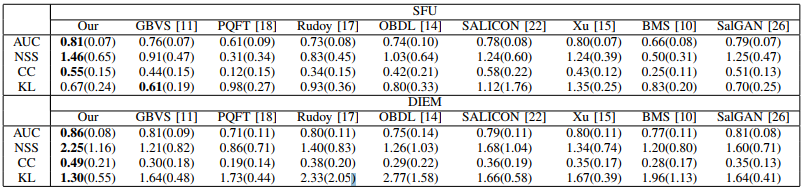
为了评估我们的方法的泛化能力,我们进一步比较了我们和其他8种方法在两个广泛使用的数据库SFU[43]和DIEM[44]上的性能。与[14]相同,对DIEM的20个视频和SFU的所有视频进行测试,以评估显著性预测性能。在我们的实验中,从LEDOV训练集中学习的OMM-CNN和2C-LSTM模型,直接用于预测来自DIEM和SFU数据库的测试视频的显著性。表VI分别给出了我们和其他8种方法在SFU和DIEM上的AUC、NSS、CC和KL的平均值。从这个表中我们可以看到,我们的方法再次优于其他8个方法,尤其是在DIEM数据库中。特别是AUC、NSS、CC和KL至少有0.04、0.44、0.09和0.25的改进,这些改进与我们的LEDOV数据库中的改进相当。这意味着我们的方法在视频显著性预测中的泛化能力。
显著性预测的性能分析
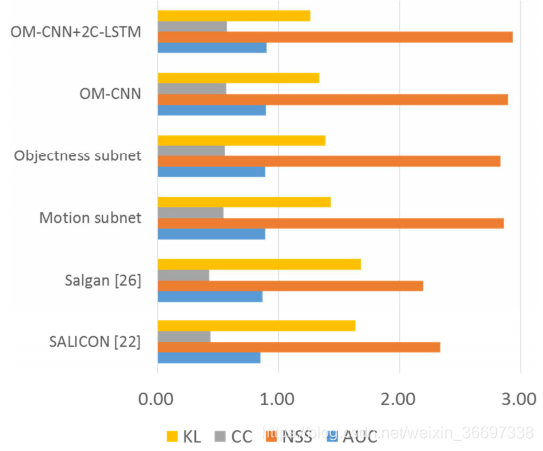
由于我们的方法的OM-CNN体系结构由对象和运动子网组成,我们评估了每个子网的贡献。通过比较训练后的模型与没有训练的模型,进一步分析了2C-LSTM的贡献。具体来说,对象子网、运动子网和OM-CNN都是独立训练的,设置与上面介绍的相同。然后,将它们与我们的方法进行比较,即OM-CNN和2CLSTM的组合。比较结果如图12所示。从图中我们可以看出,OM-CNN的表现优于对象子网,KL散度减少0.05,并且优于运动子网,KL散度减少0.09 。这表明了整合对象和运动子网的有效性。此外,与单个OM-CNN架构相比,OM-CNN和2C-LSTM的组合将KL散度降低了0.09。因此,我们可以得出结论,由于探索了跨视频帧的显着性的时间相关性,2C-LSTM可以进一步改善OM-CNN的性能。
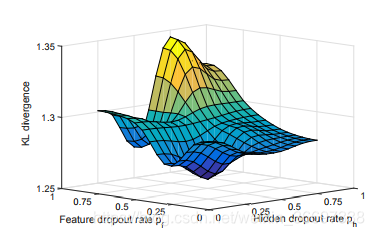
此外,我们分析了2C-LSTM中贝叶斯dropout的性能,旨在避免由2C-LSTM的高维度引起的过度拟合。 通过实验结果,我们发现低dropout率可能导致导致显着性预测的准确性降低。 为了分析dropout率的影响,我们以隐藏dropout率ph和特征dropout率pf的不同值训练2C-LSTM模型。 经过训练的模型在LEDOV的验证集上进行测试,KL散度的平均结果如图13所示。我们可以从图中观察到,当ph和pf都设置为0.25时,贝叶斯dropout可以带来0.03 KL左右的减少。 然而,一旦ph和pf从0.25增加到1,KL散度急剧上升。因此,我们在方法中将ph和pf设置为0.25。 它们可以根据训练数据的数量进行调整。
总结
本文提出了一种基于DNN的视频显著性预测方法。在我们的方法中,我们开发了两个DNN架构,即OM-CNN和2C-LSTM。两种DNN架构都是由本文建立的LEDOV数据集训练的,该数据库由32个主题注视538个视频组成。有趣的是,我们从LEDOV数据集中发现,人类的注视更有可能落在物体上,尤其是运动物体或物体中的运动区域。此外,我们发现,在连续的帧之间,注意力的相关性很高。基于这些研究结果,提出了OM-CNN结构来探索物体和运动的时空特征来预测视频帧内显著性,并开发了2C-LSTM结构来建模视频帧间显著性。最后,实验结果验证了我们基于DNN的方法在AUC、CC、NSS和KL指标上明显优于我们和其他两个公共视频眼球跟踪数据库中其他8种最先进的方法。
未来的工作有两个有希望的方向。 首先,我们的方法主要关注带有对象的视频。 实际上,一些视频是自然场景,没有任何显着的对象。 因此,自然场景视频的显着性预测是未来有趣的研究方向。 第二个未来的工作是我们的方法在感知视频编码中的潜在应用。 特别地,我们的方法能够定位视频中的显着和非显着区域,并且期望通过去除存在于非显着区域中的感知冗余来提高视频的编码效率。 因此,编码和传输视频所需的比特数更少,大大缓解了视频传输中带宽不足的问题。

















 9992
9992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









